【总结记录】《MySQL必知必会》读后笔记,结合 leetcode 例题理解
文章目录
- 一. 《MySQL知会》读后笔记
-
-
- 1. 零散的前文知识
- 2. 连接数据库
- 3. 检索数据(重点开始了)
- 4. 排序、过滤数据
- 5. 通配符、正则表达式
- 6. 汇总数据
- 7. 分组数据
-
-
- (1)GROUP BY(数据分组)
- (2)HAVING (过滤分组)
- (3)GROUP BY 和 ORDER BY 的区别
-
- 8. 子查询 && 联结
-
-
- (1)子查询
- (2)联结
- (3)高级联结
-
- 9. 组合查询
-
- 二. leetcode 实战
这篇文章主要是为了学习查询的 sql 语句~
主要是《MySQL必知必会》的笔记,也可能会加入其他额外查询的知识
结合 leetcode 的 sql 例题理解
一. 《MySQL知会》读后笔记
1. 零散的前文知识
-
数据库表名唯一
-
主键(一列、或一组列):唯一区分表中各行,需要满足条件:
- 任意两行都不具有相同主键值
- 每个行都要有主键(主键列不允许NULL值)
-
主键的好习惯:(主要就是保持主键值稳定啦)
- 不更新主键列中的值
- 不重用主键列的值
- 不在主键列中使用可能会更改的值
-
为什么用 MySQL?
- 开源,免费
- 性能好,执行快
- 可信赖、简单
2. 连接数据库
安装、开启 MySQL 之类的内容,可以去其他博客看看,我这里就不造轮子了= =
- 选择数据库
USE databaseName;
- 查看数据库
SHOW DATABASES;
- 查看数据库中的表
SHOW TABLES;
tips:自动增量 auto_increment,用于订单编号、用户ID等地方。这个属性会让 MySQL 自动地为每个行分配下一个可用编号。
3. 检索数据(重点开始了)
- SQL 语句的结束:用分号‘;'结束
- 大小写:不区分,但是建议关键字大写,列和表名小写(可读性高)
- 空格和换行:被省略,但是可以用来增加可读性
- 检索多个列:用逗号 ‘,’
SELECT id, name, price FROM products;
- 检索所有列:用 * 通配符(不必要就不用,会降低检索和应用程序的性能)
SELECT * FROM products;
- 检索不同的行:用 DISTINCT 关键字
注意:DISTINCT 应用于所有列,而非只是前置列(见下列代码)
SELECT DISTINCT id FROM products;
SELECT DISTINCT id, price; # (1,100)和 (1,200)都会显示,即使 id 一样
- 限制结果:LIMIT 子句,只返回第一行或前几行(也可以选定开始行)
SELECT name FROM products LIMIT 5; # 只要前 5 行
SELECT name FROM products LIMIT 3, 5; # 从行 3 开始的 5 行
# 行数不够时,有几行返几行
- 使用完全限定的表名:可以完全限定表名来引用列
SELECT product.name FROM products;
4. 排序、过滤数据
- ORDER BY 子句:默认升序,可以通过 DESC 关键字变成降序
SELECT name FROM products ORDER BY id; # 默认升序
SELECT name FROM products ORDER BY price, id; # 按多个列排序,从左到右(后面的可能用不到)
SELECT name FROM products ORDER BY id DESC; # 变成降序
SELECT name FROM products ORDER BY price DESC, id; # 可以部分降序,在需要降序的列后面加 DESC 即可
注意:ORDER BY 子句必须在 FROM 子句之后
- 过滤数据 WHERE:
# = != < <= > >= 等于、不等于、大于小于
SELECT name FROM products WHERE name = 'fuses'; # 字符串用单引号
# BETWEEN 指定值,双闭区间
SELECT name FROM products WHERE price BETWEEN 5 AND 10 # 用 AND,范围[5, 10]
- 空值检查:对于 NULL,需要用 IS NULL,而 = NULL 是不行的。(IS NOT NULL同理)
SELECT name FROM products WHERE name != NULL # 无效
SELECT name FROM products WHERE name IS NOT NULL # 有效
- NULL 与不匹配:过滤时,NULL 一定会被过滤,因为数据库不知道它们是否匹配,所以匹配过滤、不匹配过滤时都不会返回它们
- AND、OR 操作法:用法见代码,注意 AND 优先级比 OR 高,建议用括号
SELECT id FROM products WHERE id > 5 AND id < 10;
SELECT id FROM products WHERE id > 5 OR id % 2 = 0;
SELECT id FROM products WHERE (id = 2 OR id = 3) AND price >= 100; # 括号优先级最高
SELECT id FROM products WHERE id = 2 OR id = 3 AND price >= 100; # 不加括号,则等同于 id = 2 OR (id = 3 AND price >= 100),意义不同了
- IN 操作符:指定范围,等同于 OR,优点:
- 对于长的合法清单,IN 的语法更清楚
- 一般比 OR 更快
- 最大的优点是可以包含其他 SELECT 语句,更加动态地建立 WHERE 子句(后面讲)
SELECT id FROM products WHERE id IN (1, 2, 5);
SELECT id FROM products WHERE id = 1 OR id = 2 OR id = 5; # 等同
- NOT 操作符:唯一功能,否定之后跟的所有条件。对于复杂子句很有用。
SELECT id FROM products WHERE id NOT IN (1, 2, 5);
5. 通配符、正则表达式
这块感觉用得不多,简单写写吧
- LIKE 操作符:后跟通配符(百分号通配符、下划线通配符)
- 百分号通配符:% 表示任何字符出现任意次数
SELECT id FROM products WHERE name LIKE 'jet%'; # 寻找 jet 开头的产品
SELECT id FROM products WHERE name LIKE '%jet%'; # 可以在任意位置使用多个
# 可以修改配置,选择【区分大小写】。不能匹配 NULL
- 下划线通配符:_ 只能匹配单个字符,而不是多个字符
SELECT id FROM products WHERE name LIKE '_ jojo';
# 得到 '1 jojo' 和 '2 jojo',以此类推
- 注意:使用通配符所花时间更长,不要过度使用
- 正则表达式:用于匹配文本的特殊的串,可用于查找、替换、提取等功能的一种特殊语言
# 用 REGEXP 关键字开头(regular expression),不区分大小写
# 和 LIKE 的重要区别:匹配整个列(LIKE),还是匹配部分列值 (REGEXP)
# . 任一字符
SELECT id FROM products WHERE name REGEXP '.000'; # 得到 JetPack 1000 和 JetPack 2000
# | 或
SELECT id FROM products WHERE name REGEXP '1000|2000'; # 得到 JetPack 1000 和 JetPack
# [123] 括号内的任一字符
SELECT id FROM products WHERE name REGEXP '[123] Ton'; # 得到 '1 Ton a' 和 '2 Ton b'
# 可以用 [0-9] 来代替 [0123456789],字母同理
# // 匹配特殊字符,如 //.
SELECT id FROM products WHERE name REGEXP '\\.'; # 得到 'Ball.'
# 也用来引用元字符,如 //f(换页)、//n(换行)等
# 匹配多个实例
SELECT id FROM products WHERE name REGEXP '\\([0-9] sticks?\\)'; # 得到'(1 sticks)'、'(9 stick)'等内容,?使得前一个字符可选(此处为 s)
6. 汇总数据
- 有平均值、计数、最大值、最小值、总和等
# AVG:只能用于单个列(获取多个列,则需多个AVG函数),忽略列值为 NULL 的行
SELECT AVG(price) AS avg_price # 用 AS 来重命名获取的新列
FROM products WHERE id = 3;
# COUNT():不一定忽略 NULL 值
SELECT COUNT(*) FROM customers; # 不忽略 NULL 值
SELECT COUNT(name) FROM customers; # 忽略 NULL 值
# MAX()、MIN():忽略 NULL 值,允许对非数值数据使用(如文本等)
# SUM() 忽略 NULL 值
# 聚集不同值:通过 DISTINCT 实现(必须用列名)
SELECT AVG(DISTINCT price) FROM products # 忽略重复价格,计算平均值
7. 分组数据
注意 GROUP BY 和 HAVING 的作用区别噢!
(1)GROUP BY(数据分组)
- 必须出现在 WHERE 子句之后,ORDER BY 子句之前
- 代码示例:
SELECT id, COUNT(*) FROM products
GROUP BY id; # 通过供应商 id 分组,获取各个供应商提供的商品种类数量
(2)HAVING (过滤分组)
- WHERE 过滤的是行,而不是分组,因此我们需要引入 HAVING 来进行分组的过滤。
- 也就是说:WHERE 与 HAVING 的区别在于过滤对象(行 or 分组)
- HAVING 支持所有的 WHERE 操作符
- 代码示例(引用上面 GROUP BY 的例子):
SELECT id, COUNT(*) FROM products GROUP BY id
HAVING COUNT(*) >= 2; # 过滤种类小于 2 的分组
(3)GROUP BY 和 ORDER BY 的区别
- ORDER BY 是排序的唯一方法
| ORDER BY | GROUP BY | |
|---|---|---|
| 作用 | 排序产生的输出 | 分组行,但输出可能不是分组的顺序 |
| 不一定 | 必须使用每个选择列表达式 |
8. 子查询 && 联结
一般来说子查询更好理解,联结效率更高
(1)子查询
- 总是从内向外处理。
- 并不总是最有效方法
- 最常见的使用是WHERE子句的 IN 操作符中。
- 代码例子
SELECT order_num FROM orderitems WHERE prod_id = 'TNT2'; # 得到 5、7
SELECT cust_id FROM orders WHERE order_num IN (5, 7) # 由上面查询得到的5、7继续检索
# 其实上面的两个 sql 语句,可以通过一个子查询完成
SELECT cust_id FROM orders WHERE order_num IN (
SELECT order_num FROM orderitems WHERE prod_id = 'TNT2'
);
- 可以由此写出功能强、且灵活的 SQL 语句
- 对于嵌套个数没有限制,但是由于性能限制,不能嵌套太多的子查询。
(2)联结
- 这是 SQL 最强大的功能之一噢~
- 外键:某个表中的一列,包含另一个表的主键值,定义了两个表之间的关系。好处如下:
- 信息不重复,不浪费时间、空间
- 外键对应表格的信息变动,只需改变其表的值,以它为外键的表则不被干扰(因为其他表只管外键嘛!而外键是对应表格的主键,因此不会改变)
- 因为数据无重复,因此可以保证数据一致性
- 总之,关系数据可以有效地存储和方便地处理。因此关系型数据库的可伸缩性远比非关系型数据库要好。
可伸缩性:能够适应不断增加的工作量而不失败(资本家狂喜)
- 为什么要使用联结?:
为了使用单条 SELECT 语句,检索出存储在多个表中的数据 - 创建方法:规定要联结的所有表,以及它们如何联结即可。
SELECT vend_name, prod_name, prod_price
FROM vendors, products
WHERE vendors.vend_id = products.vend_id
ORDER BY vend_name, prod_name;
- 笛卡尔积:由没有联结条件的表关系返回的结果(检索出的行的数目的表1行数 * 表2行数
- 目前为止所用的联结称为等值联结,也称为内部联结,可以使用这样的语法实现
# 和上面的句子效果相同,规范首选 INNER JOIN ... ON
SELECT vend_name, prod_name, prod_price
FROM vendors INNER JOIN products
ON vendors.vend_id = products.vend_id
- 联结多个表:联结表的数目无限制,但是越多越耗费资源,下降性能
- 多做实验:为实现任一SQL操作,一般存在不止一种方法。性能可能会受操作类型、表中数据量、是否存在索引或键,以及其他一些条件的影响。
(3)高级联结
- 使用表别名:主要理由有两个:
- 缩短 SQL 语句
- 允许在单条 SELECT 语句中,多次使用相同的表
SELECT cust_name, cust_contact
FROM customers AS c, orders AS o, orderitems AS oi
WHERE c.cust_id = o.cust_id
AND oi.order_num = o.order_num
AND prod_id = 'TNT2';
- 自联结:同表子查询,用自联结替代会更好。(见下两SQL语句对比)
# 子查询
SELECT id, name FROM products WHERE v_id = (
SELECT v_id FROM products WHERE id = 'DTNTR'
);
# 自联结
SELECT p1.id, p1.name FROM products p1, products p2
WHERE p1.v_id = p2.v_id # 保证每行的供应商都相同
AND p2.id = 'DTNTP'
- 外部联结:联结包括了相关表中没有关联行的行。
某些场景需要使用,比如列出所有产品,以及订购数量,包括 没有人订购的产品 - 用 OUTER JOIN。需要指定左联、还是右联(LEFT、RIGHT)
SELECT customers.cust_id, orders.order_num
FROM customers LEFT OUTER JOIN orders # OUTER 应该是可以省略的
ON customers.cust_id = orders.cust_id;
9. 组合查询
没咋用过,简单写写= =
- 需要使用组合查询的两种情况:
- 在单个查询中,从不同的表返回类似结构的数据
- 对单个表执行多个查询,按单个查询返回数据
- 用 UNION,可以组合多个 SELECT 语句,将它们的结果组合成单个结果集
- 使用方法:很简单,在 SELECT 语句之间放上 UNION 即可
SELECT vend_id, prod_id, prod_price
FROM products WHERE prod_price <= 5
UNION # 来了!联结起来!!
SELECT vend_id, prod_id, prod_price
FROM products WHERE vend_id IN (1001, 1002);
- 列数据类型必须兼容,但不必完全相同
- UNION 会自动去除重复行
- 如果不想去除重复行,可以用 UNION ALL
- 对 UNION 组合查询,只能用一条 ORDER BY 子句,必须出现在最后一条 SELECT 语句之后
二. leetcode 实战
175. 组合两个表
- 考察外联结性质:可以包括没有关联的行。

SELECT FirstName, LastName, City, State
FROM Person p LEFT JOIN Address a # 因为无论 person 是否有地址信息,都要提供
ON p.PersonID = a.PersonID; # 因此使用 LEFT JOIN ON 外联结,可以包括相关表中没有关联行的行
176. 第二高的薪水
- 子查询,先找出第一高的薪水,再依此作 WHERE 条件筛数据

# Write your MySQL query statement below
SELECT MAX(Salary) AS SecondHighestSalary FROM Employee
WHERE Salary < (SELECT MAX(Salary) FROM Employee) # 先找最高值
181.超过经理收入的员工
- 自联结!组合成 < 员工信息 + 对应经理信息> 的行即可
(经理:你礼貌吗?)

# 自联结
SELECT e1.Name AS Employee
FROM Employee e1, Employee e2
WHERE e2.ID = e1.ManagerID
AND e2.Salary < e1.Salary;
182. 查找重复的电子邮箱
- 考察数据分组、分组筛选(思路见注释)

# 先按照 Email 分组,然后找出所有 COUNT > 1 的分组即可
SELECT Email FROM Person
GROUP BY Email Having COUNT(ID) > 1;
183. 从不订购的客户
- 考察外联结保持 NULL 值的性质
- 以及 IS NULL 进行空值判断

SELECT Name AS Customers
FROM Customers c LEFT JOIN Orders o ON c.ID = o.CustomerID # 外联结,保留 NULL
WHERE o.ID IS NULL; # 通过 IS NULL 进行筛选
184. 部门工资最高的员工
- 第一道 medium 题出现了!
- 考察了内联结、子查询、分组以及聚合函数,比较全面的题。难点在于理清思路。
- 关键思路:找出 <部门最高工资 - 部门> 的“键值对”

# 总体思路:先找到 <部门 - 部门最多工资>,然后再进行 部门&&工资 的匹配即可
SELECT
d.name AS Department,
e.name AS Employee,
e.Salary
FROM
Employee e, Department d # 两个表之间的内联结,获取部门名
WHERE
e.departmentID = d.ID
AND
(e.salary, e.departmentID) IN # 这边需要加上部门ID,限定不同部门的 MAX_salary
(SELECT MAX(salary), departmentID FROM Employee GROUP BY DepartmentID);
# 通过部门ID进行数据分组,然后再通过 MAX 选取出分组的 MAX 值
596. 超过5名学生的课
- 虽然是 easy,但是也不错的一道题
- 关键点在于:学生在同一门课中不应被重复计算(可能重修,需要去重)
- 考察了 DISTINCT 和聚合函数的结合使用噢!
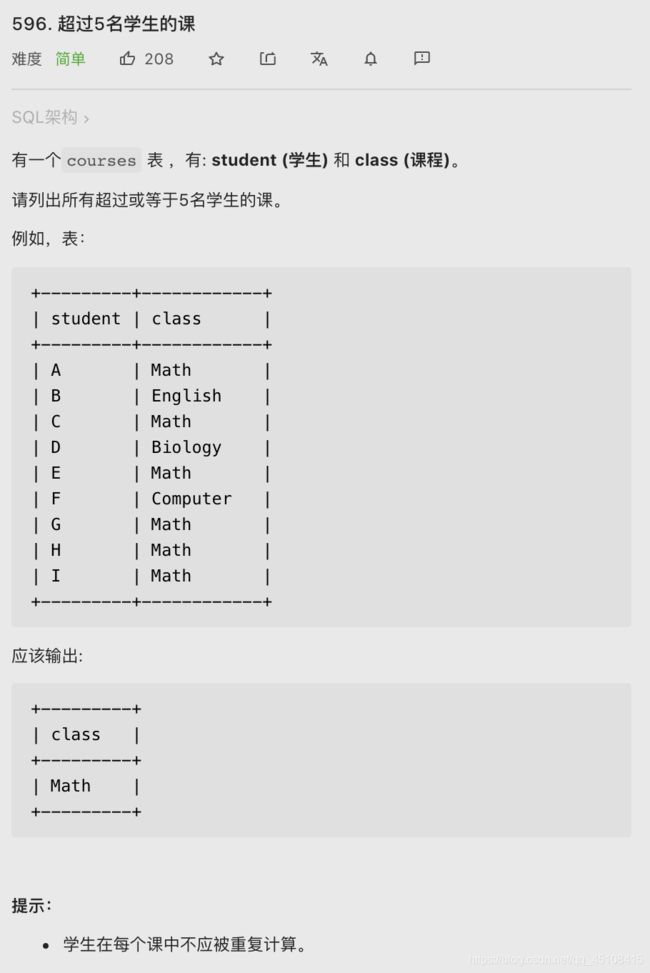
SELECT class FROM courses
GROUP BY class # 通过 class 进行分组
Having COUNT(DISTINCT student) >= 5; # 通过 DISTINCT 进行去重
620. 有趣的电影
- 诶,也还不错的一道题
- 考察了 ORDER BY、DESC 的使用

SELECT * FROM cinema
WHERE description != 'boring' AND id % 2 = 1
ORDER BY rating DESC; # 排序,用到 ORDER BY; 降序,用到 DESC.
结尾:
爆肝了属于是…没想到一边看一边写笔记,还是花了一天的时间才整完这篇博客= =
sql 语句得好好记得用法呀~