【Database System Concept 7th】Chapter 13 Data Storage Structures 读书笔记
Chapter 13 Data Storage Structures
- 13.2 File Organization
-
- 13.2.0 Introduction
- 13.2.1 Fixed-Length Records
- 13.2.2 Variable-Length Records
- 13.2.3 Storing Large Objects
- 13.3 Organization of Records in Files
-
- 13.3.0 Introduction
- 13.3.1 Heap File Organization
- 13.3.2 Sequential File Organization
- 13.3.3 Multitable Clustering File Organization
- 13.3.4 Partitioning
- 13.4 Data-Dictionary Storage
- 13.5 Database Buffer
-
- 13.5.0 Introduction
- 13.5.1 Buffer Manager
- 13.5.2 Buffer-Replacement Strategies
- 13.5.3 Reordering of Writes and Recovery
- 13.6 Column-Oriented Storage
13.2 File Organization
13.2.0 Introduction
这一节主要介绍数据库中的数据(或者说记录)在文件的最小组成单位,磁盘块中的组织形式,我们学过操作系统的都知道,文件在存储容器(磁盘或硬盘)中以块的形式存在,但是数据库中的记录大小可能很大。为了起到循序渐进的介绍效果,我们先假设所有记录的大小都小于一个块的大小,大小比较大的记录的处理方法会在13.2.2节介绍(大致就是分开来存储,并且增加索引方便重新拼接);同时,我们需要规定,一条记录完整包含于一个块中,就是说一个比块小的记录不会分开存储。
由于每条记录的大小也可能不一,一般有两种组织方式,一种是用多种文件,每一种文件存一种大小的记录;另一种就是支持变长记录的结构化文件;在这里,我们先考虑使用前者存放固定长度的记录,后面再介绍在这种组织方式下如何实现变长记录的存储。
13.2.1 Fixed-Length Records
这一小节主要介绍了固定长度记录存储模型的两个问题以及解决思路。
定长记录存储模型的两个问题:
- 记录长度与块大小不匹配(不整除),可能导致某些记录分开在两个块中存放
- 记录删除时如何处理
第一个问题的解决方法很简单,我们让不整除的块最后的空间浪费即可,具体来说,若每个块长度为X,记录长度为Y,则每个块只存放 ⌊ X / Y ⌋ \lfloor X / Y \rfloor ⌊X/Y⌋条记录。
对于第二个问题,暴力的解决方法是将被删除记录后面的所有记录往前移动,这种做法很影响效率,肯定不行。我们可以将被删除的记录用链表串起来,形成一个空闲块链表,类似下图。

这种链表的做法也有一定的问题,就是如果记录是变长的,那么空闲链表中的空闲块可能没法满足新插入的记录长度或者插入的记录长度比空闲块大小小得多,这个问题在下一节探讨。
13.2.2 Variable-Length Records
这一小节也是解决两个问题:
- 记录存储结构如何设计使得能够简单的提取出每一个字段,即使存在变长字段
- 变长记录在block中的存储结构如何设计使得能够简单的提取出block中的每一条记录
首先看第一个问题,采用的方法是将记录中的变长部分与定长部分分开,一条记录分为两部分,称为定长区与变长区。定长区存放定长字段内容与变长字段的偏移量和长度,变长区则存放变长字段的实际内容,如下图。在定长区与变长区中,会有若干字节存放一个bitmap,用于记录哪些字段是空的。在某些数据库的实现中,bitmap会安排在记录存储位置的最前方,而空字段将不再用另外的空间存储(相当于只用bitmap中的一个位来存储空字段),在某些场景下比较节省空间(如空字段很多的记录)

对于第二个问题,就是若干记录在block中的组织形式,一般采用一种叫slotted-page的结构,大致如下图所示。在block的最前面,会存放一个Header,用于记录一些元数据:
- 头部的Entries数(我理解就是block中当前存放的记录数)
- 空闲区尾部的位置
- Entries数组,每个元素表示一条记录的位置和长度
从下图也可以看出,空闲区被夹在中间,当有新纪录插入时,空闲区尾部会被分配给这个新纪录,同时更新Header;当有某个记录被删除时,在删除记录前面的记录需要被移动,将空闲区合并起来(这里感觉怪怪的,但是书里说因为一个块不会很大,4KB或者8KB,所以这个移动不怎么影响效率)。

13.2.3 Storing Large Objects
这一节讲的不是很细,大概聊了下庞大对象的存储方式,要么以文件形式存储在数据库管理的文件区域,要么以文件结构形式存放在数据库中并由数据库管理。后者用B+树来维护,在14.4.1节会详细介绍。
13.3 Organization of Records in Files
13.3.0 Introduction
本节主要介绍了一些常用的文件组织结构:
- Heap File Organization:堆叠式结构,记录无序,就是随便放
- Sequential file organization:序列结构,记录有序,但是维护效率低
- Multitable clustering file organization:一个文件甚至一个盘块,可以存放多个关系的记录,便于一些关系的join操作
- B±tree file organization:B+树结构,记录有序,维护效率高
- Hashing file organization:哈希结构,和索引结构有关
本节介绍前三个结构,后面两个会在14.4.1和14.5介绍。
13.3.1 Heap File Organization
这种组织方式比较简单,其基本思想就是找到文件中一个能够放得下当前记录的block,将记录放进去。这一小节的重点在于文件中各个block的空闲区大小管理,介绍了一个叫free-space map的结构来管理。
其实就是一个数组,数组大小为文件中的block数量,数组中的每一个元素表示对应block的空闲率,具体来说,假设用3个位表示数组中的每个元素,当前考虑元素的值为x,则当前元素对应的block的空闲率为 x 2 3 \frac{x}{2^3} 23x。比如下图中(也是用3个位来表示数组中的每个元素),第一个元素为4,对应block的空闲率就为 1 。 2 \frac{1}。{2} 。12

在寻找block时,暴力的做法就是遍历整个数组,找到第一个有足够空间的block,将当前记录放进去。进一步提升速率的话,思想就是往上再抽象一层free-space map,相当于把底层的元素分组,上层的每个元素保存组中的最大值。
13.3.2 Sequential File Organization
顺序文件被用于处理一些特殊的记录,这些记录是按照搜索码排序的,如下图所示。其中,搜索码就是某个属性或者某些属性的集合。然而,由于插入和删除一条记录时,维护记录的物理顺序(即在盘块中的真实顺序)是困难的(因为要移动记录,开销太大了),于是使用链表串起来,进行逻辑顺序的维护。

当新记录插入时,如下图所示。首先要找到该记录的插入位置(按照搜索码),然后看插入位置的前一个记录,看它所在的盘块是否还有空闲区,如果有的话,则将新记录放在该盘块中;否则,只能另找一个盘块去放。
那么,如果记录放得很分散的话,假设记录们都分布在不同的盘块中,那么读取的时候开销很大;于是需要进行一定频率的重组行为。
后面14.4.1节会介绍一个B+树文件组织方式,可以避免记录分散。

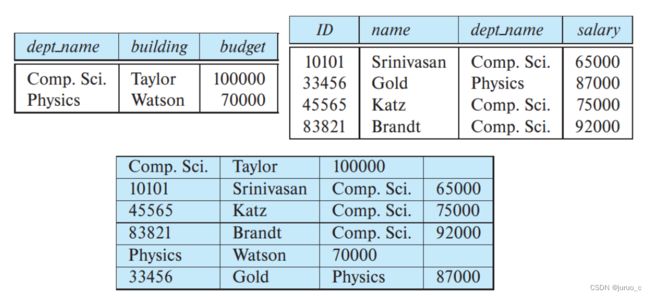
13.3.3 Multitable Clustering File Organization
大多数关系型数据库的设计中,一个文件只属于一个关系(也就是一个表),也就是说每个文件以及每个盘块只存放一个关系的记录。但是在某些情况下,让一个盘块包含多个关系的记录或许会有更好的效果。
比如下图上方的两个表,如果某个SQL查询想要把两个表natual join起来(即按照dept_name元素join起来),那么可以将两个表中相关的记录存放在一起,即多表聚簇文件组织 ,如下图上方的表。
13.3.4 Partitioning
划分方式就是说,可以将某个关系的记录们划分为多个子关系进行存储(比如按照年份)。可能有一些子关系查询频率较低,可以存放在磁盘;查询频率较高的可以存放在SSD。
13.4 Data-Dictionary Storage
13.2~13.3节主要介绍的是relation以及其中的每个tuple的组织形式,这一节介绍了下metadata的组织形式。relation的metadata包含的信息主要有:
- Names of relations
- Names of the attributes of each relation
- Domains and lengths of attributes
- Integrity constraints
- Names of views defined on the database, and definitions of those views
以上是一些基本信息,还有一些额外的信息就不一一列举了。
所有的metadata信息,构成了一个微型数据库,我们可以将他们表示为多个relation,就如下图所示。这些relation通常以非规范的形式进行存储,以便快速访问,如Index_metadata中的index_attributes可能以字符串形式存放多个attributes,比如"dept_name, building"
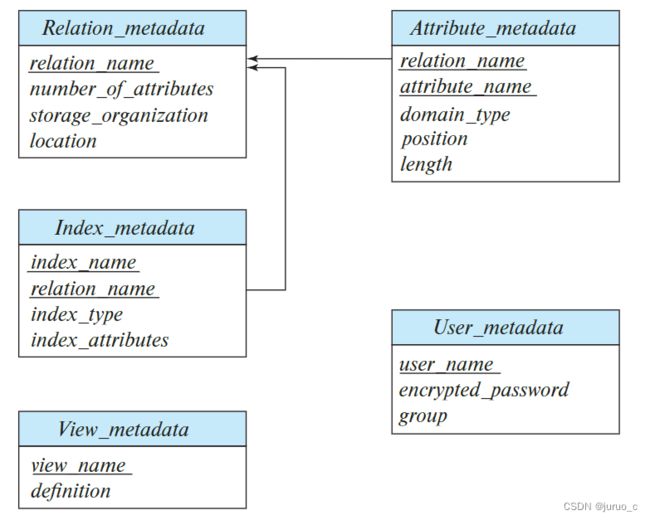
这种把metadata组织成多个relation的组织形式,还有一个问题,就是当用户想要查找某个relationA的记录时,会先通过上图所示的Relation_metadata中的storage_organization字段与location字段定位relationA所在的位置与组织形式,从而获取对应的记录。那Relation_metadata本身也是一个relation,那么它的storage_organization与location应该存放在哪呢?
书里说,可以存放在某些固定的地方,比如说固化在代码里或者在数据库中某个固定的位置。
最后,由于metadata需要经常访问,可以在数据库系统初始化时(进行任何查询之前)加载进内存的数据结构中,以加快访问速度。
13.5 Database Buffer
13.5.0 Introduction
前面13.2~13.4主要介绍的是数据在disk中的管理,13.5整一节主要介绍的是内存缓冲区的管理,即往上一层考虑。由于内存容量往往比disk容量少得多,无法将所有数据库的数据块都放入内存中,所以需要考虑如何更好地提高缓存命中率;同时,也需要确保所有缓冲区中的更新最后都能够写回disk,保证数据的一致性。其中,内存中分配给数据库系统的那部分空间称为buffer,用于管理这部分空间的子系统称为buffer manager,下面几部分将详细介绍。
13.5.1 Buffer Manager
当数据库系统中的查询程序向buffer manager请求一个数据块时,buffer manager首先查看buffer中是否有缓存块命中,若命中,则直接返回缓存块;若未命中,则加载disk中的数据块到buffer中(和文件系统的盘块缓存很类似)。若buffer已经填满了,且当前需要加载新的disk数据块,则需要根据某种策略(如经典的LRU)驱逐一个缓存块。在将disk数据块加载进buffer后,为查询程序返回内存地址。
由于一个数据库系统中可能存在多进程并发访问,为了防止进程A正在读或写的缓存块被进程B驱逐,在进程访问缓存块时,需要进行pin操作,被锁定的缓存块不能驱逐。当然,在进程访问完成后,需要进行unpin操作,解除锁定。一般,可以在缓存块结构体中维护一个pin count,当缓存块的pin count为零时可以进行驱逐。
同时,为了更安全地支持并发访问,buffer manager为数据库查询程序提供两种锁,shared lock与exclusive lock,前者为共享锁,后者为排他锁(与读写锁有点像),获得锁的情况大致为:
- 当查询程序需要写某个缓存块时,需要获得该缓存块的
exclusive lock - 当查询程序需要读某个缓存块时,需要获得该缓存块的
shared lock - 当某个缓存块的
exclusive lock被某个进程持有时,其他进程无法持有该缓存块的任何lock - 当某个缓存块的
shared lock被某个进程持有时,其他进程可以持有该缓存块的shared lock,但无法持有exclusive lock
关于并发控制的其他具体细节将在18节详细讨论。
当某些缓存块被写入最新内容时,需及时同步至disk的相应数据块中,而不是等到他们被驱逐时才去写回disk。大多数数据库都有一个检测更新块并将它们写回disk的进程,同时,为了支持崩溃恢复,将缓存块写回disk这一行为不应该发生在缓存块的更新过程中,于是,系统要求该进程在将缓存块写回disk之前必须获得该缓存块的shared lock。
13.5.2 Buffer-Replacement Strategies
一般应用上,我们使用的缓存块驱逐策略是LRU,这是因为我们无法预测未来的块访问情况,只能根据历史访问情况来做决策。但是对于数据库系统而言,一个特定的查询对块的访问顺序是相对固定的,于是我们可以预测一段未来的块访问情况,从而使用更好的缓存块驱逐策略。
以下图所示查询为例子:

假设上图查询的伪代码如下所示:

我们假设instructor和department这两个relation存放于两个不同的文件中,从伪代码中可以看出,当一个instructor中的记录被处理后,就不需要再使用到了,也就是说,如果已经处理完一个存放instructor记录的block,就可以将该block驱逐出缓存区,这种替换策略叫toss-immediate strategy。
同理,考虑department中记录的处理,假设department的记录数量为 N N N,且当前使用了记录d,那么d要在N次之后才会被再次用到,这种场景与LRU相反,近期使用的盘块被驱逐的优先级更高,这种策略称为Most Resently Use(MRU)。
13.5.3 Reordering of Writes and Recovery
数据库缓冲区允许在内存中执行写操作,并在一段时间后将所有写操作输出到磁盘中,但为了优化磁盘寻道时间(或者SSD找block的时间),往往会对写操作进行重新排序。但是,这种重新排序可能会导致系统崩溃时,磁盘上的数据不一致。
使用日志磁盘或者日志文件系统持久化写操作,当系统崩溃后重启时,查看日志并将未执行的写操作继续执行下去。
13.6 Column-Oriented Storage
面向行的存储在某些特定场景下存在一些问题,比如:
- 当查询只需要访问某些特定属性而不需要所有属性时,行存储依然会把所有属性加载进内存中
- CPU缓存性能差,同上,行存储会加载一些不必要的属性,占用缓存
- 压缩效率低,不同属性间的数据类型或格式往往不同,不方便压缩
- 不适用于向量处理
而面向列的存储正好可以解决以上问题,其思想是将属性分组,关系的每个属性都单独存放在一个文件中,或者一个文件包含多个属性,但是相邻的数据为同一种属性。那么,当查询只需要访问某些特定属性时,就只需要加载特定的属性到内存中,不必加载其余的属性;且压缩效率高,因为相邻的位置上是同一种属性,数据类型和格式一致,方便压缩;也适用于向量处理。
以上这些场景在OLAP(Online Analytical Processing)应用中出现的多,即数据分析领域,也就是说列存储较适用于数据仓库,即不怎么更新的仓库,多用于查询并分析。
而对于OLTP(Online Transaction Processing)应用而言,即事务处理应用,列存储并不适用,因为可能会有以下代价:
- 元组重构代价,事务型应用中,对一整个元组操作的行为较多,也就是要遍历该元组的所有属性,这将使得磁盘IO巨大,因为列存储几乎把所有属性都分开存放了,需要遍历许多个文件进行访问。
- 解压代价,由于列存储通常会按压缩的形式进行存储,则从压缩表示中提取数据需要解压。事务处理查询通常只需要获取少量的记录,而解压会将许多无关记录解压出来。