无梯度强化学习:使用遗传算法进化代理
一、说明
我想提高我的强化学习技能。由于对这个领域一无所知,我参加了一门课程,接触到了 Q 学习及其“深度”等效项(深度 Q 学习)。在那里我接触到了 OpenAI 的Gym,他们有多种环境可供代理玩耍和学习。
课程仅限于 Deep-Q 学习,所以我自己阅读了更多内容。我意识到现在有更好的算法,例如策略梯度及其变体(例如 Actor-Critic 方法)。如果这是您第一次使用强化学习,我建议您使用以下我认为有助于建立良好直觉的资源:
- Andrej Karpathy 的深度强化学习:Pong from Pixels。这是一个经典教程,激发了人们对强化学习的广泛兴趣。必须阅读。
- 通过 Q-Learning 更深入地研究强化学习。这篇文章以图文并茂的方式概述了最基本的 RL 算法:Q 学习。
- 各种强化学习算法简介。强化学习算法世界的演练。(有趣的是,我们将在这篇文章中讨论的算法——遗传算法——在列表中缺失了。
- 直观强化学习:优势-行动者-批评者 (A2C) 简介。一部非常非常出色的漫画(是的,你没听错),介绍了当前最先进的强化学习算法。
我感到很幸运,作为一个社区,我们分享了如此之多,以至于在对强化学习一无所知的几天内,我能够复制 3 年前最先进的技术:使用像素数据玩 Atari 游戏。这是我的代理(绿色)仅使用像素数据与 AI 玩 Pong 的快速视频。

这感觉就像是个人成就!
二、强化学习的问题
我的代理使用策略梯度算法训练得很好,但这需要在我的笔记本电脑上进行整整两天两夜的训练。即使在那之后,它的表现也并不完美。
我知道从长远来看,2 天并不算多,但我很好奇为什么强化学习的训练如此缓慢。更多地阅读和思考这一点,我意识到强化学习速度慢的原因是梯度(几乎)不存在,因此不是很有用。
梯度通过提供有关如何更改网络参数(权重、偏差)以提高准确性的有用信息,有助于图像分类等监督学习任务。
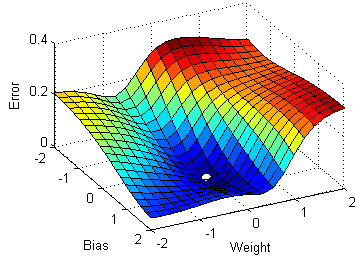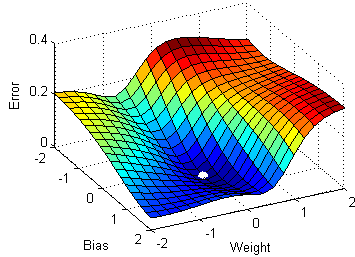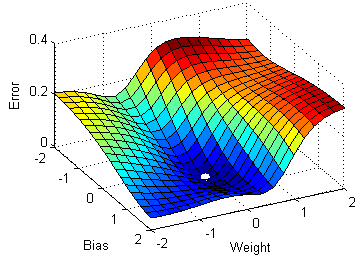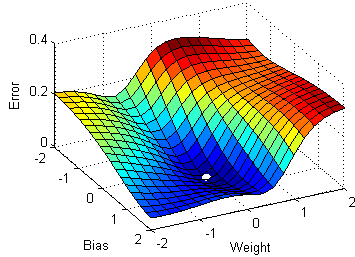
想象一下这个表面代表不同权重和偏差组合的误差(越低越好)。从随机初始化的点(权重和偏差)开始,我们希望找到使误差最小化的值(最低点)。每个点的梯度代表下坡的方向,所以找到最低点就相当于顺着梯度走。(等等,我刚刚描述了随机梯度下降算法吗?)
在图像分类中,在每个小批量训练之后,反向传播为网络中的每个参数提供清晰的梯度(方向)。然而,在强化学习中,梯度信息仅在环境给予奖励(或惩罚)时偶尔出现。大多数时候,我们的代理正在采取行动,但不知道这些行动是否有用。梯度信息的缺乏使得我们的错误景观看起来像这样:

图片来自优秀的博客文章机器学习中的表达性、可训练性和泛化性
奶酪的表面代表我们代理网络的参数,无论代理做什么,环境都不会给予奖励,因此没有梯度(即,由于零错误/奖励信号,我们不知道在哪个方向改变参数以获得更好的结果)下次表演)。表面上的几个孔代表与表现良好的代理对应的参数相对应的低错误/高奖励。
您现在看到政策梯度的问题了吗?随机初始化的代理可能位于平坦的表面(而不是孔)上。如果随机初始化的代理位于平坦的表面上,则很难获得更好的性能,因为没有梯度信息。而且由于(误差)表面是平坦的,随机初始化的智能体或多或少会进行随机游走,并在很长一段时间内坚持不良策略。(这就是为什么我花了几天时间来训练代理。提示:也许策略梯度方法并不比随机搜索更好?)
正如题为“为什么强化学习有缺陷”的文章明确指出的那样:
如果你想学习的棋盘游戏是围棋,你会如何开始学习它?你会阅读规则,学习一些高级策略,回忆你过去如何玩类似的游戏,获得一些建议......对吗?事实上,至少部分是由于 AlphaGo Zero 和 OpenAI 的 Dota 机器人从头开始学习的限制,与人类学习相比,它并不真正令人印象深刻:它们依赖于看到更多数量级的游戏并使用比任何其他游戏更多的原始计算能力。人类永远可以。
我认为这篇文章一语中的。强化学习效率低下,因为它不告诉智能体应该做什么。代理不知道该做什么,开始做随机的事情,并且偶尔环境会给予奖励,现在代理必须找出它所采取的数千个动作中的哪一个导致环境给予奖励。人类不是这样学习的!我们被告知需要做什么,我们发展技能,而奖励在我们的学习中发挥相对较小的作用。

如果我们通过政策梯度来训练孩子,他们总是会对自己做错了什么感到困惑,并且永远不会学到任何东西。(照片来自Pixabay)
三、强化学习的无梯度方法
当我探索基于梯度的强化学习方法的替代方案时,我偶然发现了一篇题为:深度神经进化:遗传算法是训练深度神经网络进行强化学习的竞争性替代方案的论文。这篇论文结合了我正在学习的内容(强化学习)和我一直感兴趣的内容(进化计算),因此我开始实现论文中的算法并进化一个代理。
请注意,严格来说,我们甚至不必实现遗传算法。正如上面所暗示的,同一篇论文发现,即使是完全随机的搜索也能够发现好的代理。这意味着即使你不断随机生成代理,最终你也会发现(有时快点比策略梯度)表现良好的代理。我知道,这很疯狂,但这只是说明了我们最初的观点,即强化学习从根本上来说是有缺陷的,因为它可供我们用来训练算法的信息非常少。
3.1 什么是遗传算法?
这个名字听起来很花哨,但在本质上,它可能是您可以设计的用于探索景观的最简单的算法。考虑通过神经网络实现的环境(如 Pong)中的代理。它获取输入层中的像素并输出可用操作的概率(向上、向下移动桨或不执行任何操作)。
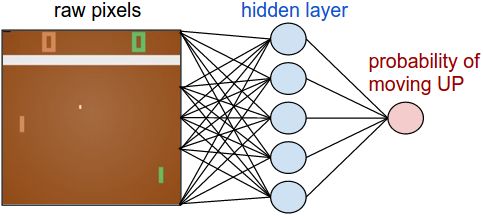
图片来自深度强化学习:Pong from Pixels
我们在强化学习中的任务是找到神经网络(权重和偏差)的参数(权重和偏差),使代理更频繁地获胜,从而获得更多奖励。到目前为止,一切都很好?
遗传算法的伪代码
- 简单地想象代理是一个有机体,
- 参数将是指定其行为(策略)的基因
- 奖励将表明有机体的适应性(即奖励越高,生存的可能性越高)
- 在第一次迭代中,您从X个具有随机初始化参数的代理开始
- 其中一些人纯粹出于偶然会比其他人表现得更好
- 就像现实世界中的自然进化一样,您实现了适者生存:只需选取最适者的 10% 的代理,并在下一次迭代中复制它们,直到您在下一次迭代中再次拥有X代理。杀死最弱的 90%(如果这听起来很病态,你可以将杀死函数重命名为 Give- moksha!)
- 在复制前 10% 最适合的智能体期间,向其参数添加微小的随机高斯噪声,以便在下一次迭代中,您可以探索最佳智能体参数周围的邻域
- 保持性能最佳的代理不变(不添加噪声),以便您始终保留最好的代理,以防止高斯噪声导致性能可能下降
就是这样。您已经了解了遗传算法 (GA) 的核心。遗传算法有很多(奇特的)变体,其中两个代理之间存在各种(肮脏的)性别(性重组),但关于深度神经进化的论文用上面的伪代码实现了普通遗传算法,这也是我在代码中实现的。(您可以使用我的 Github 存储库上的代码访问 Jupyter 笔记本)。
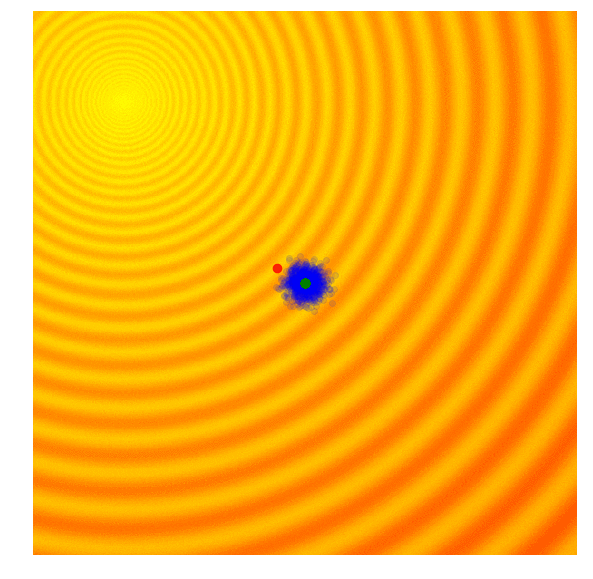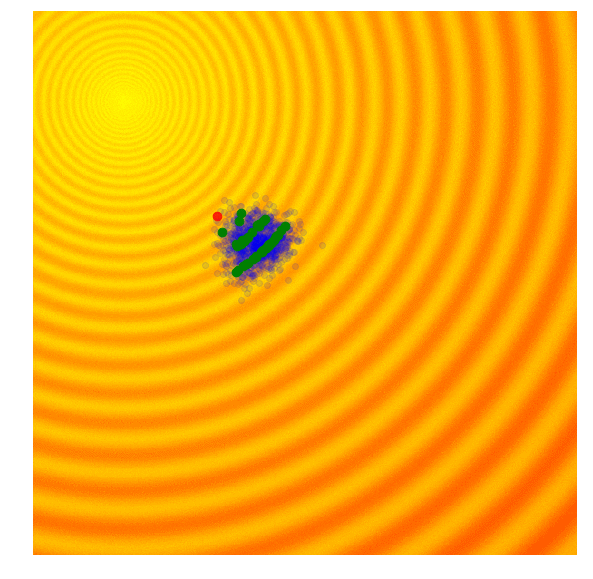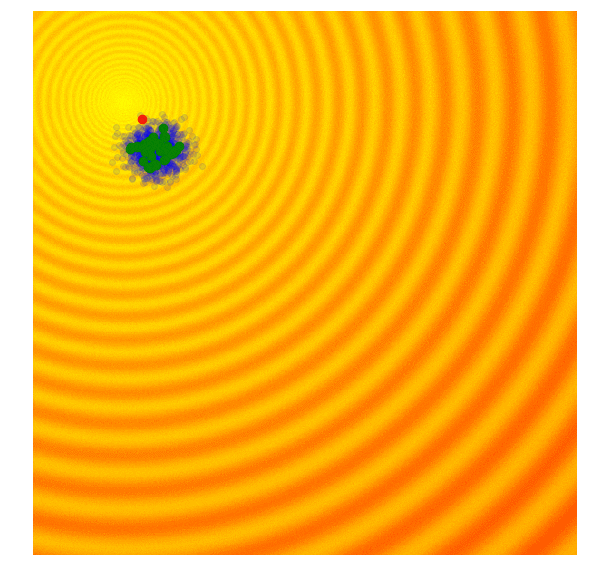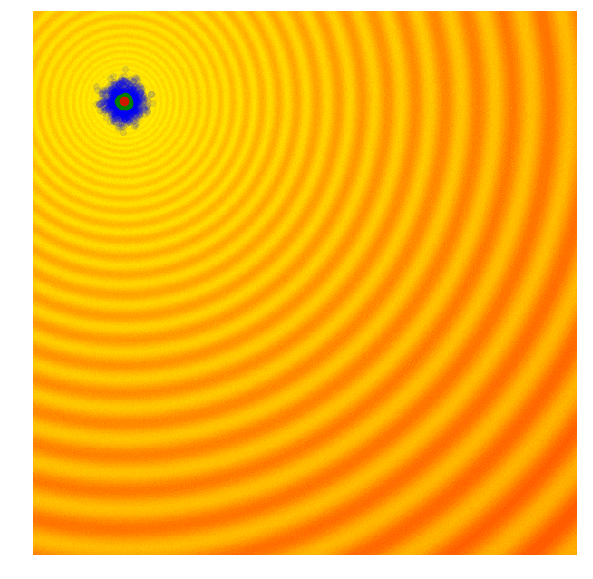
黄色区域是错误率较低的区域(奖励/性能较高)。蓝点都是代理。绿色的是前 10%,红点是最好的。请注意整个群体如何逐渐向误差最低的区域移动。(图片来自进化策略视觉指南)
有关进化算法如何工作的更多可视化信息,我强烈建议您阅读这篇做得非常好的文章:进化策略可视化指南。
3.2 用于实施强化学习深度神经进化的代码
我开发了一个移动推车上的代理平衡杆(又名CartPole-v0)。这是完整的代码: https: //github.com/paraschopra/deepneuroevolution
使用 PyTorch,我们通过 2 个隐藏层神经网络对代理进行参数化(想要保留“深层”部分:),对于 CartPole 来说,一层网络也可能做得很好)。
class CartPoleAI(nn.Module):
def __init__(self):
super().__init__()
self.fc = nn.Sequential(
nn.Linear(4,128, bias=True),
nn.ReLU(),
nn.Linear(128,2, bias=True),
nn.Softmax(dim=1)
)
def forward(self, inputs):
x = self.fc(inputs)
return x这是进化的主要循环:
game_actions = 2 #2 actions possible: left or right
#disable gradients as we will not use them
torch.set_grad_enabled(False)
# initialize N number of agents
num_agents = 500
agents = return_random_agents(num_agents)
# How many top agents to consider as parents
top_limit = 20
# run evolution until X generations
generations = 1000
elite_index = None
for generation in range(generations):
# return rewards of agents
rewards = run_agents_n_times(agents, 3) #return average of 3 runs
# sort by rewards
sorted_parent_indexes = np.argsort(rewards)[::-1][:top_limit] #reverses and gives top values (argsort sorts by ascending by default) https://stackoverflow.com/questions/16486252/is-it-possible-to-use-argsort-in-descending-order
# setup an empty list for containing children agents
children_agents, elite_index = return_children(agents, sorted_parent_indexes, elite_index)
# kill all agents, and replace them with their children
agents = children_agents该代码几乎是不言自明的,并且遵循我在本文前面编写的伪代码。将细节映射到伪代码:
- 我们的人口规模是 500 ( num_agents ),我们在第一次迭代中随机生成代理 ( return_random_agents )
- 在 500 个中,我们只选择前 20 个作为父项 ( top_limit )
- 我们想要运行循环的最大迭代次数是 1000(世代)。虽然通常对于 CartPole 而言,但在几次迭代后就会发现表现良好的代理。
- 在每一代中,我们首先运行所有随机生成的代理,并在 3 次运行中获得它们的平均性能(一旦可能很幸运,所以我们想要平均)。这是通过run_agents_n_times函数完成的。
- 我们按照奖励(绩效)的降序对代理进行排序。排序后的索引存储在sorted_parent_indexes中。
- 然后我们选取前 20 个智能体并在其中随机选择以生成下一次迭代的子代。这发生在return_children函数中(见下文)。该函数在复制代理时向所有参数添加一个小的高斯噪声,但保留一个最好的精英代理(不添加任何噪声)。
- 现在,将子代理作为父代理,我们再次迭代并运行整个循环,直到完成所有 1000 代,或者我们找到性能良好的代理(在 Jupyter 笔记本中,我打印前 5 个代理的平均性能。当性能良好时够了,我手动中断循环)
return_children函数如下所示:
def return_children(agents, sorted_parent_indexes, elite_index):
children_agents = []
#first take selected parents from sorted_parent_indexes and generate N-1 children
for i in range(len(agents)-1):
selected_agent_index = sorted_parent_indexes[np.random.randint(len(sorted_parent_indexes))]
children_agents.append(mutate(agents[selected_agent_index]))
#now add one elite
elite_child = add_elite(agents, sorted_parent_indexes, elite_index)
children_agents.append(elite_child)
elite_index=len(children_agents)-1 #it is the last one
return children_agents, elite_index您会看到,首先,它从前 20 个代理中选择一个随机代理(索引包含在sorted_parents_indexes中),然后调用mutate函数添加随机高斯噪声,然后将其附加到children_agents列表中。在第二部分中,它调用add_elite函数将最佳代理添加到Children_agents列表中。
这是变异函数:
def mutate(agent):
child_agent = copy.deepcopy(agent)
mutation_power = 0.02 #hyper-parameter, set from https://arxiv.org/pdf/1712.06567.pdf
for param in child_agent.parameters():
if(len(param.shape)==4): #weights of Conv2D
for i0 in range(param.shape[0]):
for i1 in range(param.shape[1]):
for i2 in range(param.shape[2]):
for i3 in range(param.shape[3]):
param[i0][i1][i2][i3]+= mutation_power * np.random.randn()
elif(len(param.shape)==2): #weights of linear layer
for i0 in range(param.shape[0]):
for i1 in range(param.shape[1]):
param[i0][i1]+= mutation_power * np.random.randn()
elif(len(param.shape)==1): #biases of linear layer or conv layer
for i0 in range(param.shape[0]):
param[i0]+=mutation_power * np.random.randn()
return child_agent您可以看到,我们迭代所有参数,并简单地添加高斯噪声(通过np.random.randn()),然后乘以一个常数(mutation_power)。乘法因子是一个超参数,大致类似于梯度下降中的学习率。(顺便说一句,这种迭代所有参数的方法速度慢且效率低。如果您知道 PyTorch 中更快的方法,请在评论中告诉我)。
最后函数add_elite如下:
def add_elite(agents, sorted_parent_indexes, elite_index=None, only_consider_top_n=10):
candidate_elite_index = sorted_parent_indexes[:only_consider_top_n]
if(elite_index is not None):
candidate_elite_index = np.append(candidate_elite_index,[elite_index])
top_score = None
top_elite_index = None
for i in candidate_elite_index:
score = return_average_score(agents[i],runs=5)
print("Score for elite i ", i, " is ", score)
if(top_score is None):
top_score = score
top_elite_index = i
elif(score > top_score):
top_score = score
top_elite_index = i
print("Elite selected with index ",top_elite_index, " and score", top_score)
child_agent = copy.deepcopy(agents[top_elite_index])
return child_agent此代码仅获取前 10 个代理并运行它们 5 次,以根据平均性能(通过return_average_score )双重确定哪一个是精英。然后它通过copy.deepcopy复制精英并按原样返回(没有突变)。如前所述,精英确保我们始终拥有之前最好成绩的副本,并防止我们随机漂流(通过突变)进入没有好代理人的区域。
就是这样!让我们看看我们进化后的 CartPole 代理的实际效果。

先生,您是进化的产物。
遗传算法并不完美。例如,没有关于如何在添加高斯噪声时选择乘法因子的指导。您只需尝试一堆数字,看看哪个有效。而且,在很多情况下,它可能会彻底失败。我多次尝试为 Pong 开发代理,但速度非常慢,所以我放弃了。
我联系了深度神经进化论文的作者Felipe Such。他提到,对于某些游戏(包括 Pong),神经进化失败,但对于其他游戏(例如Venture),它比策略梯度快得多。
四、你会进化出什么?
我的存储库中的深度神经进化代码足够通用,可以与 PyTorch 中实现的任何神经网络一起使用。我鼓励您尝试各种不同的任务和架构。
PS:查看之前的实践教程:a)从小型语料库生成哲学和 b)贝叶斯神经网络
帕拉斯·乔普拉