GPU CUDA 使用shared memory 运行速度不升反降原因与解决方案
写了两张图像相加,以及图像滤波的的几个算子,分别采用shared memory 进行优化。
#include > > (pIn, pIn2, pOut, nW, nH);
//vectorAdditionOptimized << > > (pIn, pIn2, pOut, nW, nH);
sdkStartTimer(&sw);
cudaEventRecord(start);
for (int i = 0; i < 100; i++)
{
//filter5x5 << > > (pIn, pOut, nW, nH);
//vectorAdditionOptimized << > > (pIn, pIn2, pOut, nW, nH);
vectorAddition << <blocksPerGrid2, threadsPerBlock2 >> > (pIn, pIn2, pOut, nW * nH);
}
cudaEventRecord(stop);
cudaDeviceSynchronize();
sdkStopTimer(&sw);
float ms1 = sdkGetTimerValue(&sw);
float elapsedTime;
cudaEventElapsedTime(&elapsedTime, start, stop);
std::cout << "Elapsed Time: " << elapsedTime << " milliseconds\n";
sdkResetTimer(&sw);
//vectorAddition << > > (pIn, pIn2, pOut2, nW, nH);
//vectorAdditionOptimized << > > (pIn, pIn2, pOut, nW, nH);
sdkStartTimer(&sw);
cudaEvent_t start1, stop1;
cudaEventRecord(start);
for (int i = 0; i < 100; i++)
{
//filter5x5shared << > > (pIn, pOut2, nW, nH);
//vectorAddition << > > (pIn, pIn2, pOut2, nW , nH);
vectorAdditionOptimized << <blocksPerGrid2, threadsPerBlock2 >> > (pIn, pIn2, pOut2, nW * nH);
}
cudaEventRecord(stop);
cudaDeviceSynchronize();
sdkStopTimer(&sw);
float ms2 = sdkGetTimerValue(&sw);
cudaEventElapsedTime(&elapsedTime, start, stop);
std::cout << "Elapsed Time: " << elapsedTime << " milliseconds\n";
std::cout << "ms1:" << ms1 << ",ms2:" << ms2 << std::endl;
cudaMemcpy(pHOut, pOut, nW * nH * sizeof(float), cudaMemcpyDeviceToHost);
cudaMemcpy(pHOut2, pOut2, nW * nH * sizeof(float), cudaMemcpyDeviceToHost);
for (int y = 0; y < nW; y++)
{
for (int x = 0; x < nH; x++)
{
if (abs(pHOut[x + y * nW] - pHOut2[x + y * nW]) > 0.01)
std::cout << "error" << std::endl;
}
}
cudaFree(pIn);
cudaFree(pOut);
return 0;
}
实际运行发现
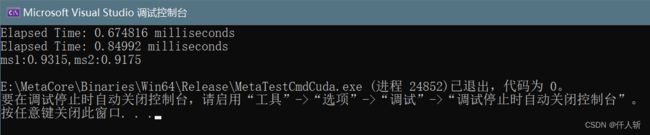
使用shared memory的效率反而下降了,实现结果是一致的。