Spark类库----PySpark(本地开发环境配置&&远程SSH解释器配置)
我们前面使用过bin/pyspark 程序,要注意,这个只是一个应用程序,提供一个Python解释器执行环境来运行Spark任务。
我们现在说的PySpark,指的是Python的运行类库,是可以在Python代码中:import pyspark
PySpark 是Spark官方提供的一个Python类库,内置了完全的Spark API,可以通过PySpark类库来编写Spark应用程序,并将其提交到Spark集群中运行.
下图是,PySpark类库和标准Spark框架的简单对比

简单的说,你要写程序到spark上去运行,如果使用python写代码,那么你就需要导入PySpark的类库。如果你使用其他语言,例如java,那么就需要导入java对应的类库。
前提:Anaconda安装
Anaconda是Python语言的一个发行版.
内置了非常多的数据科学相关的Python类库, 同时可以提供虚拟环境来供不同的程序使用。
PySpark是Python标准类库, 可以通过Python自带的pip程序进行安装
或者Anaconda的库安装(conda)
pip install pyspark -i https://pypi.tuna.tsinghua.edu.cn/simple
-i https://pypi.tuna.tsinghua.edu.cn/simple 指定国内源
或者
conda install pyspark
推荐使用pip,官方提供的更加稳定。
先切换到pyspark的虚拟环境。

安装完成之后进行校验。就和Java,你使用maven,需要下载依赖是一样的。之前使用的pip管理类库,现在使用Anaconda管理类库。通过pip下载类库,然后交由Anaconda管理。我不知道这样理解对不对啊,这是我自己理解的。
根据教程,剩下三台也需要安装,这让我有点不理解,可能是因为集群在跑python程序时,各自都需要类库支持。

该教程的Python运行环境由什么来提供?
由Anaconda提供,并使用虚拟环境, 环境名称叫做: pyspark。你切换到pyspark的虚拟环境中,那么Anaconda就给你把spark相关的类库全都给你准备好了,并且之间不会有冲突什么的。
Anaconda,中文大蟒蛇,是一个开源的Anaconda是专注于数据分析的Python发行版本,包含了conda、Python等190多个科学包及其依赖项。
Anaconda就是可以便捷获取包且对包能够进行管理,包括了python和很多常见的软件库和一个包管理器conda。常见的科学计算类的库都包含在里面了,使得安装比常规python安装要容易,同时对环境可以统一管理的发行版本
本机PySpark环境配置
配置Hadoop DDL ,只针对windows系统,mac可以忽略。
配置这些的原因:hadoop设计用于Linux运行,我们写spark程序的时候,在Windows上开发,不可避免的会用到部分hadoop功能,为了避免在Windows上报错,我们给windows打补丁。
我已经将补丁资源上传。
1、将资源存储到自己的路径中,比如 E:\softs\hadoop-3.3.0
2、将该文件夹的 hadoop.dll 文件复制到 C:\Windows\System32 里面去
3、配置HADOOP_HOME 环境变量,指向 E:\softs\hadoop-3.3.0(看你怎么存放的,指向bin的上一级目录)
本机windows的Anaconda和PySpark安装
直接安装包安装即可,安装包没法上传,需要的可以私信博主获取。
修改一下自己的安装地址就行,其他的全部默认选项。

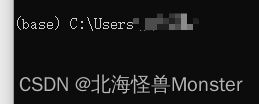
控制台有base前缀则安装成功。
然后再C盘的用户目录下,找到自己用户,创建一个 .condarc.txt的文件,将以下内容复制进去。配置国内源
channels:
- defaults
show_channel_urls: true
default_channels:
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/r
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/msys2
custom_channels:
conda-forge: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
msys2: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
bioconda: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
menpo: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
pytorch: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
simpleitk: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
配置完成之后,重启Anaconda控制台,依次输入以下命令
# 创建虚拟环境 pyspark, 基于Python 3.8
# 输入python 查看版本,即安装成功
conda create -n pyspark python=3.8
# 切换到虚拟环境内
conda activate pyspark
# 在虚拟环境内安装包
pip install pyhive pyspark jieba pymysql -i https://pypi.tuna.tsinghua.edu.cn/simple
本机PyCharm本地和远程解释器配置
1、创建一个项目,选择解释器。因为之前配置过解释器,但是我们需要选择Anaconda的解释器

选择你刚才安装Anaconda的路径,里面的envs下的pyspark(这个conda create -n pyspark python=3.8 命令创建的虚拟环境)

配置完成,勾选按钮,表示将这个解释器给所有工程共享。后面你创建项目就可以直接使用,就不用再配置上面一步。PyCharm自动识别。

配置测试,说明环境OK

最后我们检查包:
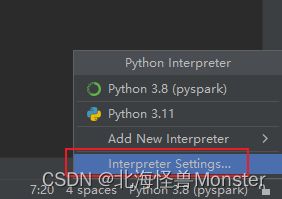
刚才安装的几个包都在这个环境中。

注意!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
有一个大坑啊,兄弟们!!!!!!!!!!!!!!!!!!!!!!!
我之前使用的是2021的社区版本学习python基础的,后来没法设置远程,就下载了一个最新的版本 2022.3专业版
这个版本在配置conda的时候,和之前版本不一样!!!!!!!!!!!!!!!
在选择 Conda executable 的时候,不是选Scripts下的conda.exe,选的是 安装目录下的_conda.exe
卧槽,我他妈的网上找半天解决方法都不可行,结果自己手贱多试了几个才发现!

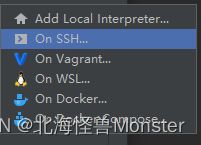
远程解释器配置
我们在 PyCharm写的代码,点击执行,可以直接在Linux的spark集群中运行。因为Spark和Linux兼容性更好。
当然实际开发中肯定是不行,一般会有测试服务器。
现在学习,我们直接配置到虚拟机中。
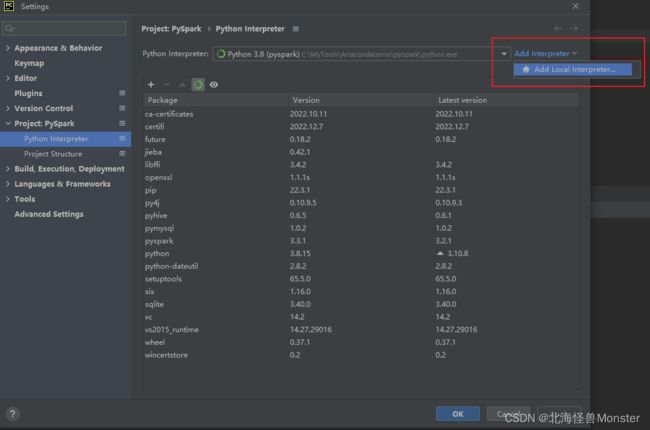
Host这儿,因为我在本地windows中配置了hosts文件,要是你没配置需要写完整的ip地址

然后一路下一步,到这个界面

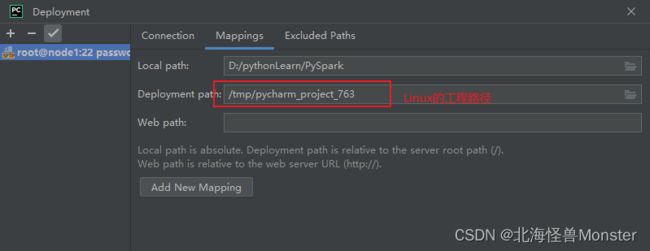
选择Existing,我这个版本可以点右边的三个小点选择Linux的路径,要是你的版本不一样,就自己去Linux找路径,找你pyspark的虚拟路径。

配置成功,你可以看见包列表

远程解释器原理就是,把你本地工程同步到Linux中。然后使用Linux的环境跑程序,至于为什么我们还需要在本机配置呢?
是因为,我们在写代码的时候,环境还是本地的,不配置上面的环境,那么我们本地写代码就会报错。所以本地环境和Linux环境一致很重要。我们在本地写,跑程序在Linux
Spark程序入门
Spark Application程序入口为:SparkContext,任何一个应用首先需要构建SparkContext对象,如下两步构建:
- 第一步、创建SparkConf对象
- 设置Spark Application基本信息,比如应用的名称AppName和应用运行Master
- 第二步、基于SparkConf对象,创建SparkContext对象
# coding:utf8
from pyspark import SparkConf, SparkContext
if __name__ == '__main__':
# setMaster("local[*]") 实际上在Linux上Spark单机环境跑的,并没有在yarn集群上
# 当master和控制台参数冲突时,代码优先级更高
conf = SparkConf().setMaster("local[*]").setAppName("WordCountHelloWorld")
# 通过SparkConf对象构建SparkContext
sc = SparkContext(conf=conf)
# 需求: wordcount单词计数,读取HDFS上的word.txt文件,对其内部的单词统计出现 的数量
# 可以读取HDFS文件,也可以读取工程的本地路径文件(就是Linux的文件,因为会同步到Linux中),但是提交到集群运行时,只能时HDFS的文件
file_rdd = sc.textFile("hdfs://node1:8020/input/words.txt")
# 将单词进行切割,得到一个存储全部单词的集合对象
word_rdd = file_rdd.flatMap(lambda line: line.split(" "))
# 将单词转换为元组,key是单词,value是数字1
word_with_one_rdd = word_rdd.map(lambda x: (x , 1))
# 将元组的value 按照key分组,对所有value执行聚合操作(相加)
result_rdd = word_with_one_rdd.reduceByKey(lambda a, b: a + b)
# 通过collect方法收集RDD的数据,打印输出结果
print(result_rdd.collect())

代码流程分析
上面的API不重要,后面根据教程持续学习。
对象构建就不用分析了
从file_rdd = sc.textFile(“hdfs://node1:8020/input/words.txt”) 开始分析
最重要的是体会分布式程序,文件存储在HDFS中,将文件进行分片,分成三份,由三台服务器进行并行数据处理。最后 Shuffle进行数据汇总,这样大大提高了性能
在执行任务时,资源申请,阶段划分都是由 driver 执行,driver 将阶段划分为多个task,然后又executor执行,executor只是干活儿的。
1、driver将SparkContext 对象构建
2、将SparkContext对象以序列化的方式发送给executor
3、executor获取到SparkContext对象,到HDFS读取数据,一个executor并不是读取全部数据,只是读取自己任务的那一部分。然后进行逻辑运算,最后进行shuffle汇总
4、调用collect方法,executor将运行结果发送回driver
这份python代码,有driver运行部分,有executor部分,executor部分由多台机器执行。这是分布式程序执行的关键。
driver执行:
conf = SparkConf().setMaster("local[*]").setAppName("WordCountHelloWorld")
sc = SparkContext(conf=conf)
print(result_rdd.collect())
Executor执行:
file_rdd = sc.textFile("hdfs://node1:8020/input/words.txt")
word_rdd = file_rdd.flatMap(lambda line: line.split(" "))
word_with_one_rdd = word_rdd.map(lambda x: (x , 1))
result_rdd = word_with_one_rdd.reduceByKey(lambda a, b: a + b)

如果想要将上面代码提交到yarn中运行,需要删除setMaster(“local[*]”)
然后在Linux中,使用 spark-submit --master yarn 文件路径
显示提交到yarn中运行更慢,那是因为构建容器耗费时间,实际代码运行时间还是很短的。要是数据量很大,构建容器时间就可以忽略不计了,当然构建容器时间也和我虚拟机拉跨有原因。
![]()
Python On Spark 执行原理
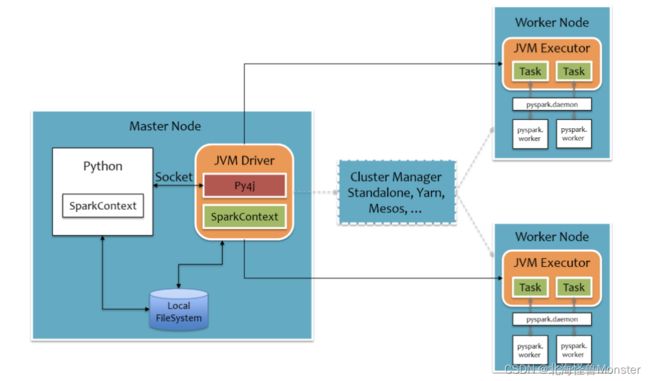
1、spark是由Scala语言编写的,运行在JVM平台上
2、如何将python代码运行在这个平台上?
3、python 的 Driver 通过 Socket和 JVM Driver进行沟通,可以理解为将python代码转换成java代码。这一步通过 Py4j这个模块实现
4、在spark编程方面,executor 的代码,java有自己特有的api,python也有自己特有的api,这些无法进行翻译。但是Dirver执行的代码比较少,可以将这些代码完全兼容的转换为java代码。
5、JVMDriver 和 JVM Executor 通过RPC通讯,在executor端,会启动一个pyspark.damon的守护进程,起中转站作用。实际执行流程时 JVM Driver 通过 RPC通讯将干活执行发送给 JVM Executor,Executor将指令交给中转站,中转站再命令python进程干活。所以Executor本质上,是python进程在干活儿
最后总结:
- Driver端是将python代码翻译为java代码,由JVM Driver运行
- Executor端,通过中转站,最后还是由Python运行
- 所以在python on spark中有两套语言在运行,spark支持的其他语言,比如R语言也是这个原理。
- 为什么底层不单独使用python再开发一套spark,这有点浪费。通过体系中转可以支持多种语言,不用每种语言都去重新开发。节约成本。
总结
Python语言开发Spark程序步骤?
- 主要是获取SparkContext对象,基于SparkContext对象作为执行环境入口
如何提交Spark应用?
- 将程序代码上传到服务器上, 通过spark-submit客户端工具进行提交
- 注意:在代码中不要设置master,如果设置,以代码为准,spark-submit工具的设置就无效了。
- 提交到集群中的时候,读取的文件一定时各个机器都能访问到的地址,比如:HDFS,如果读取本地文件,需要每台机器都要有对应文件才行
分布式代码执行的重要特征是什么?
- 代码在集群上运行, 是被分布式运行的.
- 在Spark中, 非任务处理部分由Driver执行(非RDD代码)
- 任务处理部分由Executor执行(RDD代码).
- Executor的数量可以很多,所以任务的计算是分布式在运行的.
简述PySpark的架构体系
- Python On Spark Driver端由JVM执行, Executor端由JVM做命令转发, 底层由Python解释器进行工作