spark插入动态分区代码报错
现象
SparkSession session = SparkSession.builder()
.config(sparkConf)
.config("hive.exec.dynamic.partition.mode", "nonstrict")//动态分区
//.config("hive.metastore.dml.events","false")
.enableHiveSupport() .getOrCreate();
dataset1.write().mode(SaveMode.Overwrite).insertInto(Constant.RENT_TABLE);
dataset第一次插入分区没有问题,但是第二次重新跑的时候
[load-dynamic-partitions-0] ERROR hive.ql.metadata.Hive - Exception when loading partition with parameters partPath=hdfs://s2cluster/user/hive/warehouse/odszjdata.db/ods_zj_building_area_check_list/.hive-staging_hive_2022-11-07_18-12-45_911_2372413257026787436-1/-ext-10000/period_id=202210, table=ods_zj_building_area_check_list, partSpec={period_id=202210}, replace=true, listBucketingEnabled=false, isAcid=false, hasFollowingStatsTask=false
org.apache.hadoop.hive.ql.metadata.HiveException: org.apache.thrift.TApplicationException: Required field 'filesAdded' is unset! Struct:InsertEventRequestData(filesAdded:null)
at org.apache.hadoop.hive.ql.metadata.Hive.fireInsertEvent(Hive.java:2437)
at org.apache.hadoop.hive.ql.metadata.Hive.loadPartitionInternal(Hive.java:1632)
at org.apache.hadoop.hive.ql.metadata.Hive.lambda$loadDynamicPartitions$4(Hive.java:1974)
at java.base/java.util.concurrent.FutureTask.run(FutureTask.java:264)
at java.base/java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1128)
at java.base/java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:628)
at java.base/java.lang.Thread.run(Thread.java:834)
Caused by: org.apache.thrift.TApplicationException: Required field 'filesAdded' is unset! Struct:InsertEventRequestData(filesAdded:null)
at org.apache.thrift.TApplicationException.read(TApplicationException.java:111)
at org.apache.thrift.TServiceClient.receiveBase(TServiceClient.java:79)
at org.apache.hadoop.hive.metastore.api.ThriftHiveMetastore$Client.recv_fire_listener_event(ThriftHiveMetastore.java:4836)
at org.apache.hadoop.hive.metastore.api.ThriftHiveMetastore$Client.fire_listener_event(ThriftHiveMetastore.java:4823)
at org.apache.hadoop.hive.metastore.HiveMetaStoreClient.fireListenerEvent(HiveMetaStoreClient.java:2531)
at java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at java.base/jdk.internal.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.base/java.lang.reflect.Method.invoke(Method.java:566)
at org.apache.hadoop.hive.metastore.RetryingMetaStoreClient.invoke(RetryingMetaStoreClient.java:154)
at com.sun.proxy.$Proxy29.fireListenerEvent(Unknown Source)
at java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at java.base/jdk.internal.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.base/java.lang.reflect.Method.invoke(Method.java:566)
at org.apache.hadoop.hive.metastore.HiveMetaStoreClient$SynchronizedHandler.invoke(HiveMetaStoreClient.java:2562)
at com.sun.proxy.$Proxy29.fireListenerEvent(Unknown Source)
at org.apache.hadoop.hive.ql.metadata.Hive.fireInsertEvent(Hive.java:2435)
... 6 more
Exception in thread "main" org.apache.spark.sql.AnalysisException: org.apache.hadoop.hive.ql.metadata.HiveException: Exception when loading 1 in table ods_zj_building_area_check_list with loadPath=hdfs://s2cluster/user/hive/warehouse/odszjdata.db/ods_zj_building_area_check_list/.hive-staging_hive_2022-11-07_18-12-45_911_2372413257026787436-1/-ext-10000;
at org.apache.spark.sql.hive.HiveExternalCatalog.withClient(HiveExternalCatalog.scala:108)
at org.apache.spark.sql.hive.HiveExternalCatalog.loadDynamicPartitions(HiveExternalCatalog.scala:924)
at org.apache.spark.sql.catalyst.catalog.ExternalCatalogWithListener.loadDynamicPartitions(ExternalCatalogWithListener.scala:189)
at org.apache.spark.sql.hive.execution.InsertIntoHiveTable.processInsert(InsertIntoHiveTable.scala:205)
at org.apache.spark.sql.hive.execution.InsertIntoHiveTable.run(InsertIntoHiveTable.scala:99)
at org.apache.spark.sql.execution.command.DataWritingCommandExec.sideEffectResult$lzycompute(commands.scala:104)
at org.apache.spark.sql.execution.command.DataWritingCommandExec.sideEffectResult(commands.scala:102)
at org.apache.spark.sql.execution.command.DataWritingCommandExec.doExecute(commands.scala:122)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$execute$1.apply(SparkPlan.scala:131)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$execute$1.apply(SparkPlan.scala:127)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$executeQuery$1.apply(SparkPlan.scala:155)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.sql.execution.SparkPlan.executeQuery(SparkPlan.scala:152)
at org.apache.spark.sql.execution.SparkPlan.execute(SparkPlan.scala:127)
at org.apache.spark.sql.execution.QueryExecution.toRdd$lzycompute(QueryExecution.scala:80)
at org.apache.spark.sql.execution.QueryExecution.toRdd(QueryExecution.scala:80)
at org.apache.spark.sql.DataFrameWriter$$anonfun$runCommand$1.apply(DataFrameWriter.scala:668)
at org.apache.spark.sql.DataFrameWriter$$anonfun$runCommand$1.apply(DataFrameWriter.scala:668)
at org.apache.spark.sql.execution.SQLExecution$$anonfun$withNewExecutionId$1.apply(SQLExecution.scala:78)
at org.apache.spark.sql.execution.SQLExecution$.withSQLConfPropagated(SQLExecution.scala:125)
at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:73)
at org.apache.spark.sql.DataFrameWriter.runCommand(DataFrameWriter.scala:668)
at org.apache.spark.sql.DataFrameWriter.insertInto(DataFrameWriter.scala:325)
at org.apache.spark.sql.DataFrameWriter.insertInto(DataFrameWriter.scala:311)
at com.tencent.s2.HouseRentSparkJob.main(HouseRentSparkJob.java:56)
但是我在服务器跑代码反复测试 都是可以重复插入分区的。。window实在是难搞
百度得到
.config("hive.metastore.dml.events","false") 就好了。。 windows确实好了。
没时间分析原因。
参考文章
Supporthttps://knowledge.informatica.com/s/article/594919?language=en_US
__________________________________________________________________________
回家越想越不对劲,突然意识到可能是我windows的jar包版本太低导致的。
window还是以前的cdh版本
但是服务现在的cdp已经是
hadoop 3.1.1 hive3.1.1 spark2.4.7了,
那么我先调整pom的版本 hadoop为3.1.1 结果报错
Unrecognized Hadoop major version number: 3.1.1
这个错也很简单,我们根据报错,查到这个地方,发现是hive-exec1.2.1里ShimLoader里只判断了hadoop版本是1和2 如果是3就会直接报错。
因为我cdp版本是 3.1.1所以我pom引入3.1.1也合情合理吧

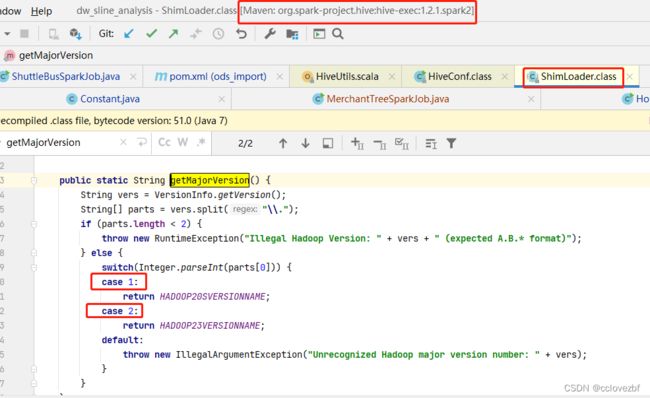
现在的问题是什么?
pom里spark版本2.4.7中的hive-exec:1.2.1里只判断了hadoop1 和hadoop2的版本
但是我hadoop引入的版本是3.1.1
解决办法:
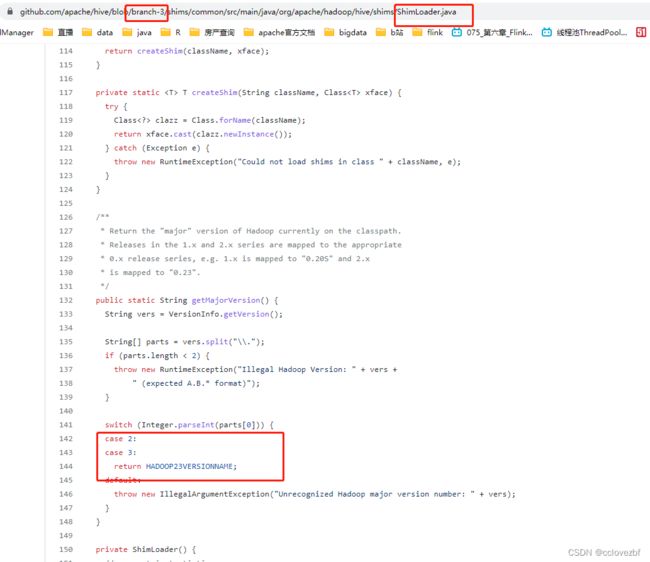
1 找个spark版本高的版本 可能它就有hive-exec2 hive-exec3(因为我服务器本身是hive3,所以往这方面想) 这样就可以支持hive3了。如下图所示
2.改hadoop的低版本,因为我主要是用spark去开发hive的读写。
最终我选择了1。。结果发现走不通。还是说下过程吧。改了pom发现报错
org.apache.spark
spark-hive_2.11
${spark.version}
org.spark-project.hive
hive-exec
org.spark-project.hive
hive-metastore
org.apache.hive
hive-exec
3.1.2
org.apache.hive
hive-metastore
3.1.2
org.apache.hive
hive-jdbc
3.1.2
紧接着又遇到这个错,Exception in thread "main" java.lang.NoSuchFieldError: HIVE_STATS_JDBC_TIMEOUT
at org.apache.spark.sql.hive.HiveUtils$.formatTimeVarsForHiveClient(HiveUtils.scala:204)
遇到这个错其实很简单。我们打开HiveUtils类查看formatTimeVarsForHiveClient这个方法
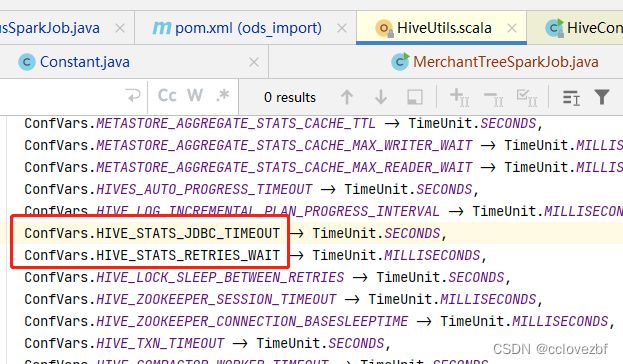
看到这里没 就 HIVE_STATS_JDBC_TIMEOUT 这个枚举和下面的枚举是黑的,代表ConfVars里面没有这个枚举,ConfVars是哪里的?
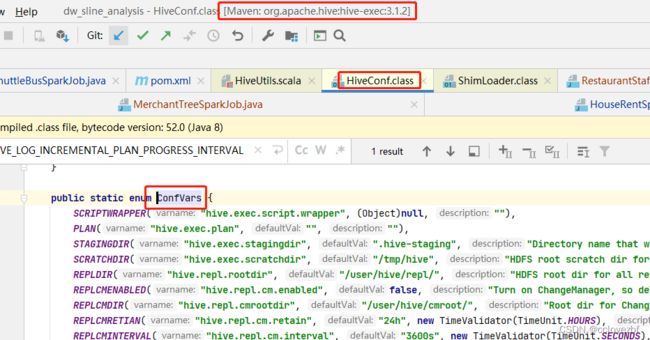
点进去 发现是hive-exec的jar.找了一圈 确实没这个枚举,那现在是什么问题呢?
spark-hive_2.1.1:2.4.1有这个 HIVE_STATS_JDBC_TIMEOUT枚举
hive_3.1.1没有这个枚举
解决办法1 从spark入手找个spark版本没这个枚举的。
2.找个hive版本有这个枚举的。
先从2入手 进入github里找到这个。确实只有1.2的hive-exec版本里有 2.0 3.0都没有
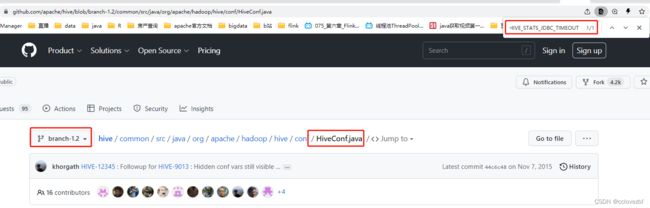
现在的问题是啥 spark2.4.7的hiveUtils里要HIVE_STATS_JDBC_TIMEOUT
hive-exec的1.2有这个,但是hive-exec1.2只支持hadoop1 hadoop2
此时我们好像陷入了循环?那么我们直接用spark2.4.7+hive-exec1.2.1+hadoop2.x是不是就可以了?答案是可以的,但是别忘了我们最开始的目的?
大数据线上问题排查系列 - HIVE 踩坑记- hive.metastore.dml.events - 知乎
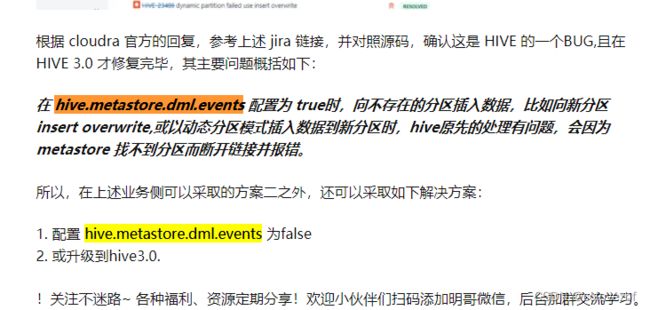
我们反复插入hive分区表会报错,原因在于hive1.2.1这个jar呀,此时我希望的是本地使用hive3的jar。 所以我应该使用更高版本的spark?原因还在于spark的hiveUtils。
经过我看源码发现spark3已经没有这个参数了
 但是spark2.4还是有这个参数。
但是spark2.4还是有这个参数。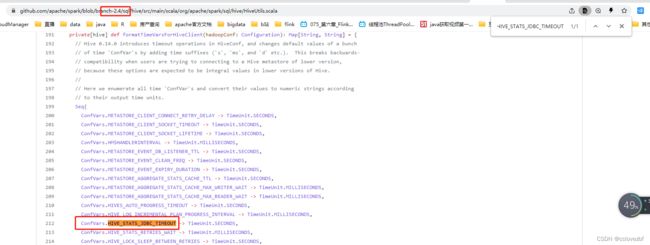
所以感觉这个思路可行
spark3+hive3+hadoop3 一切是那么美好。结果 我真是他妈的吐了。

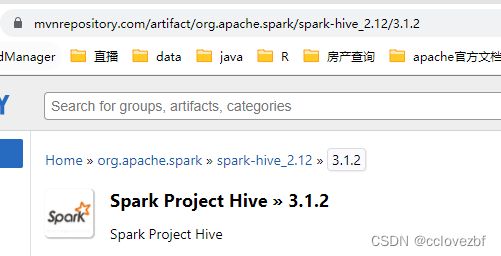
这里的mvn显示有3.1.2的jar,我点进去发现最多只有2.4.8......真是日了狗哟。。。。 仔细看才发现是scala2.12才有3.1.2......
最后也下了spark_hive_2.12_3.1.2的jar 结果运行就报错。。。放弃了。
通过这次醒悟到两个道理。
1.windows也就是本地调试bug太多,jar包各种依赖太深,随便改就会报错。
2.尽量还是打成jar到服务器去跑吧。。。。