舍弃99%的参数,还能达到相同的性能!阿里团队发现大模型「合二为一」的黑魔法!而且不用GPU,不需重新训练
动漫《龙珠》里,构想了一种“美达摩星人融合术”,通过融合术舞步就可以让譬如悟空与贝吉塔合体,成为“究极超强合体战士”悟吉塔。在《X战警:天启》中,反派大 Boss 也拥有吸收他人能力化为己用的强大能力。哪怕在《超级马里奥》中,马里奥也拥有吃下蘑菇和花朵获得投掷火球的能力的设定。

那么一种“奇思妙想”就是,在不同领域数据集上进行微调而获得如“数学”、“代码”、“翻译”等能力的不同大模型,能否通过“吸收同化”而实现模型合并,进而一步到位拥有不同的能力?
来自阿里团队的研究者们放飞了这一畅想:无需重新训练,无需 GPU,通过非常简单的运算就可以成功实现让模型 1 + 1 = 2。通过让语言模型吸收在数学数据集上预训练的模型,其数学能力一跃从 2.2 飞升至 66.3!让我们一起来看看这篇论文吧!
论文题目:
Language Models are Super Mario: Absorbing Abilities from Homologous Models as a Free Lunch
论文链接:
https://arxiv.org/pdf/2311.03099.pdf
1. Drop And REscale?
首先,说到有监督微调(Supervised Fine-Tuning,SFT)大家肯定都不陌生。对于在无监督语料中大量训练获得先天知识的大模型而言,有监督微调是一种获得垂直领域的特定知识最为行之有效的一种方法。在有监督微调中,往往只有部分模型参数发生了变化,对于领域知识而言,正是发生变化的这部分参数赋予了大模型新的知识和能力。如果记大模型原始预训练参数为,经过有监督微调后的参数为,其中上标 指不同的领域任务,我们将发生变化的参数叫做 Delta 参数,即:
Delta 参数反映了模型在微调过程中的变化情况。显然,对于分析模型在有监督微调中“发生了什么”,Delta 参数显得至关重要。在过去的不少研究中,学者们已经发现,在有监督微调过程中,Delta 参数往往是大量冗余的。那么一种很自然的想法,借鉴 Dropout 的思路,可否将部分冗余参数随机删除,得到体量更小的 Delta 参数呢?
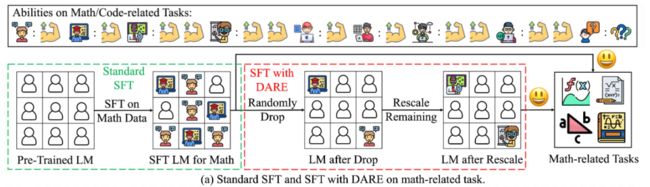
沿着这个想法,论文作者提出了一种名为 DARE(Drop And REscale)的削减冗余参数的方法。顾名思义,Drop 和 Rescale,DARE 的思想非常简单,分两步走,首先给定一个随机的删除率 ,以 为概率随机删除 Delta 参数(置为 0),即 Drop 的过程,而后以 为概率等比例扩大剩余保留的参数,就完成了 DARE 的过程,流程图如下图所示:
如果形式化的定义 DARE,即为:
最终,得到后,与 相加,即 ,从而完成 DARE。在实验中,论文作者惊讶的发现,采用 DARE,可以在舍弃大量冗余参数的同时,维持模型的性能。
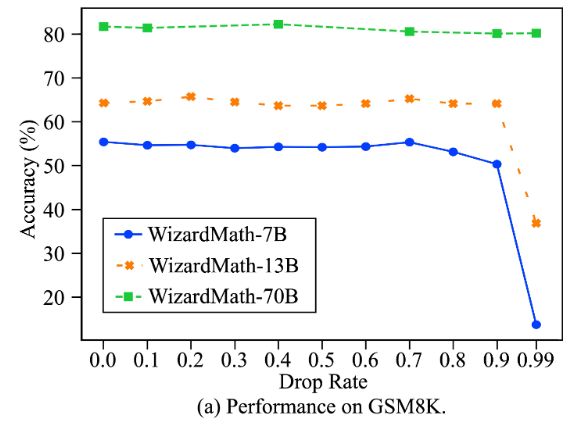
从图中可以看到,随着 Drop rate 的上升(舍弃的参数越来越多),模型的性能仍然可以维持不错的水平。同时,模型的参数量越大,在不影响精度的情况下其最大 Drop rate 的值也在上升,甚至可以达到 99% !这意味着 DARE 可以在几乎删除 99% 的参数的基础上仍然维持模型的性能,这一发现不仅表明,有监督微调确实是如何 LoRA 那样在学习一种“低秩结构”,并且也进一步说明了Delta 参数确实是大量冗余的。
2. 合体!基于 DARE 的模型融合
OK,说了这么多,那么 DARE 和模型融合的关系是什么呢?让我们首先来考虑一下模型融合(Model Merging)这一任务,给定任务集 和 个微调模型 ,那么模型融合旨在合并这 个模型的参数以使得合并后的模型可以同时拥有这 个不同模型的能力。
模型融合在过去的研究中有很多方法,那么困扰这些方法最大的难点在于什么呢?很自然的,害怕这些模型的参数在简单的平均、加权平均的运算中交叉影响,导致融合后的模型反而不如融合前的模型。那么如何消除模型参数间的交叉影响呢!其实这篇论文给出的答案呼之欲出——那就使用 DARE 消除模型参数本身!如下图所示,基于 DARE 的模型融合方法即使用经过 DARE 后的预训练模型替代原始基于预训练微调的模型,再通过传统的模型融合方法(如直接平均)获得融合后的新模型。

显然,这种基于 DARE 的模型融合方式并不局限于某一种特定的模型融合方法,传统上的 Average Merging、Task Arithmetic、Fisher Merging、RegMean、TIES-Merging 都可以使用这一方法得到增强,以类似加权平均的 Task Arithmetic 为例形式化的定义这一过程,即为:
非常简洁高效的加强了模型融合的过程,在实验中可以看到,融合后的模型显著的增强了原始模型在各个领域的能力,尤其在数学数据集 GSM8K 之上,融合后的模型性能一跃从 2.2 飞升至 66.3! 此外,最为重要的是,这种融合方式不用 GPU,不用重新训练,一切都可以在 CPU 中完成!

3. 实验结果
使用这两种技术,作者团队做了大量的实验验证方法的有效性,譬如对于 DARE:
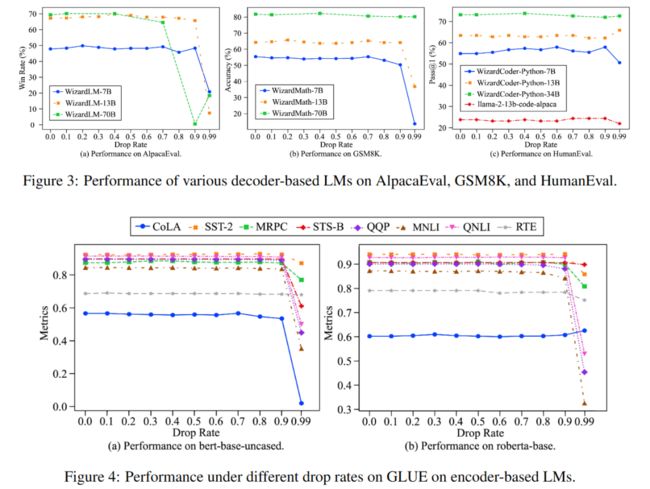
不同规模、不同类型的模型在使用 DARE 后都在消除了冗余参数的同时维持了自身的能力。其中值得注意的是在第一幅图中,WizardLM-70B 在 AlpacaEval 数据集下当删除率为 0.9 时出现了巨幅下降,作者猜测原因可能在于这一任务比较困难,需要更多的 delta 参数才能有效的完成任务,而当删除率上升时,其删除了重要参数导致参数间的依赖关系被破坏,从而出现性能巨幅下降。
对于模型融合,作者实验了 DARE 方法在不同模型融合技术中的应用:

在Average Merging、Task Arithmetic、Fisher Merging、RegMean、以及TIES Merging方法中,DARE 都不同程度的带来了0.58%,0.36%, 0.37%,-0.03%,and 0.84%的平均提升。
此外,作者也进行了 DARE 的消融实验,证明了第二步即 Rescale 这一步是 DARE 的核心:

受启发于 WizardLM-70B 在 AlpacaEval 数据集下性能在 drop rate 为 0.9 时的突然下降,作者研究了“在何时应该使用 DARE”,通过对比 delta 参数的变化范围,作者团队首先发现,对比预训练中参数的变化范围,有监督微调下 delta 参数的变化范围往往在 0.5% 以内,这似乎表明,有监督微调不是“向大模型引入新的能力”,而是在“释放大模型本身的能力”。同时,对比 delta 参数的变化范围以及 DARE 的效果可以发现,当在 delta 参数变化范围相对较小(0.5%)时,DARE 可以维持较高的性能水平,而一旦 delta 参数发生了更大程度的变化,DARE 就有可能失效。

4. 总结与讨论
最后,来一个小小的总结,这篇论文沿着一条“预训练微调存在大量冗余参数”结论出发,提出了一个简洁有效的参数缩减方法,并将这个方法应用于模型融合任务之中,获得了非常漂亮的结果。
同时,这种方式也暗示了语言模型的一种非常有趣的新的能力,即其可以吸收同源的模型而获得新能力,实现将多样化的垂直领域模型合并为一个三头六臂拥有多样能力的新模型。或许不仅在模型融合领域,在联邦学习领域这一方法可能也大有可为!