视觉大模型DINOv2:自我监督学习的新领域
1 DINOv2
1.1 DINOv2特点
前段时间,Meta AI 高调发布了 Segment Anything(SAM),SAM 以交互式方式快速生成 Mask,并可以对从未训练过的图片进行精准分割,可以根据文字提示或使用者点击进而圈出图像中的特定物体,其灵活性在图像分割领域内属首创。
但是,归根到底 SAM 是一个promptable segmentation system,主要应用于各种分割任务,对其他的视觉任务(e.g. Classification, Retrieval,VQA...)的帮助没有那么直接。
于是,在继[分割一切],Meta AI 再次发布重量级开源项目——DINOv2,DINOv2 可以抽取到强大的图像特征,且在下游任务上不需要微调,这使得它适合作为许多不同的应用中新的 BackBone。
Meta开源DINOv2视觉大模型,无需微调,效果惊人!在人工智能研究领域,Meta再次引发了轰动!DINOv2,全称为”Dual-Stage Implicit Object-Oriented Network”,是一种基于Transformer的视觉模型。它采用了全新的双阶段训练方法,有效地将图像分类和对象检测任务结合起来。与以往的视觉模型相比,DINOv2具有更高的准确性和更快的推理速度。
无需微调就能达到卓越性能,使得DINOv2在易用性和灵活性方面具有巨大优势。在大多数情况下,模型一经训练,就能直接应用于各种实际场景。这不仅降低了模型的运行成本,同时也大大缩短了开发周期。对于那些需要处理海量图像和视频的应用领域,比如自动驾驶、智能监控和人脸识别等,DINOv2无疑将成为强大的解决方案。
与之前发布的 Segment Anything 相比,DINOv2 在应用领域和适用范围上更加广泛,文中的实验也涵盖了多个 CV中经典的下游任务。
在 Meta AI 官方的Blog中,将 DINOv2 的特性总结如下:
- DINOv2 是一种训练高性能计算机视觉模型的新方法。
- DINOv2 提供了强大的性能,并且不需要微调。
- 由于是自监督( self-supervision),DINOv2 可以从任何图像集合中学习。同时,它还可以学习到当现有方法无法学习的某些特征,例如深度估计。
DINOv2 是一种新的高性能计算机视觉模型训练方法,使用自监督学习来实现与该领域中使用的标准方法相匹配或超越结果。与其他自监督系统一样,使用 DINOv2 方法的模型可以在不需要任何相关元数据的情况下对任何图像集合进行训练。这意味着它可以从它所接收到的所有图像中学习,而不仅仅是那些包含特定一组标签或 alt 文本或标题的图像。DINOv2 提供了可直接用作简单线性分类器输入的高性能特征。这种灵活性意味着 DINOv2 可用于创建许多不同计算机视觉任务的多用途骨干。
文中的实验展示了 DINOv2 在下游任务上的出色能力,例如分类、分割和图像检索等应用领域。其中,最令人惊讶的是,在深度估计方面,DINOv2 的结果明显优于 in-domain 与 out-of-domain 的 SOTA 的 pipeline。作者认为这种强大的域外表现是自监督特征学习和轻量级任务特定模块(例如线性分类器)相结合的结果。
最后,由于不采用 fine-tuning,骨干保持通用,同一特征可以同时用于许多不同任务。
论文地址:https://arxiv.org/pdf/2304.07193.pdf
代码地址:https://github.com/facebookresearch/dinov2
Demo地址:https://dinov2.metademolab.com/
1.2 DINOv2创建了一个新的高质量数据集
在如今的大模型时代,为了进一步提高性能,往往更大的模型需要更多的数据进行训练。由于没有足够大的高质量数据集来满足 DINOv2 的训练需求,Meta AI 通过从大量未经整理的数据池中检索与几个经过整理的数据集中的图像相近的图像,来组建一个新的数据集。具体流程如下所示:

下面我们来具体看一看数据集构建的 pipeline,主要有数据源(Data sources.),去重(Deduplication.)与自监督图像检索(Self-supervised image retrieval.)三个部分。
1.2.1 数据源(Data sources.)
首先,LVD-142M 数据集的来源共包含两部分,即公开数据集和网络数据集。
- 公开数据集
如下表所示,包含 ImageNet-22k、ImageNet-1k、Google Landmarks 和几个细粒度数据集的训练拆分:
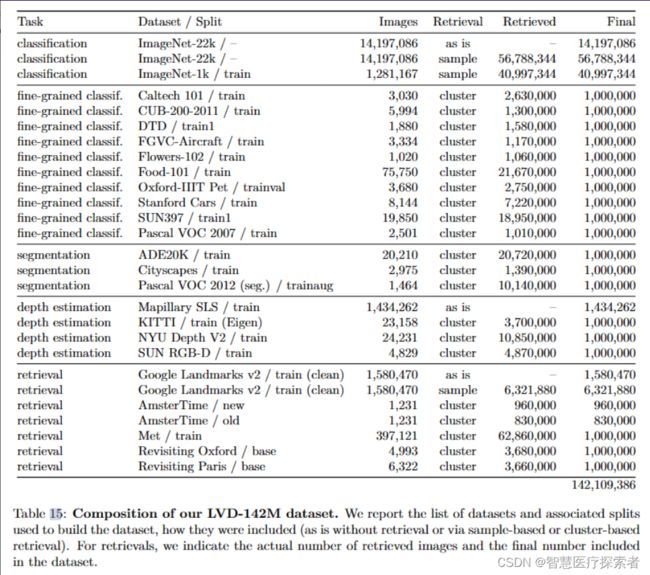
- 网络数据集
网络数据集简单理解就是通过从公开可用的爬取网络数据存储库中收集原始未过滤的图像数据集,再对这些数据分三步清洗:
- 首先,针对每个感兴趣的网页,从标签中提取出图像的 URL 链接;
- 其次,排除掉具有安全问题或受限于域名的 URL 链接;
- 最后,对下载的图像进行后处理,包括 PCA 哈希去重、NSFW 过滤和模糊可识别的人脸;
由此就得到了 1.2 亿张独一无二的图像。
1.2.2 去重(Deduplication.)
为了进一步减少冗余并增加图像之间的多样性,DINOv2 使用了《A self-supervised descriptor for image copy detection》论文提出的 copy detection pipeline 进行图像查重。这个方法基于深度学习计算图像之间的相似度。
论文链接:
https://arxiv.org/abs/2202.10261
另外,DINOv2 还删除了使用任何基准的测试或验证集中包含的重复图像,以确保数据集的纯净度。
1.2.3 自监督图像检索(Self-supervised image retrieval.)
接下来是自监督图像检索的过程。为了从大量未标注的数据中检索出与经过精心整理的数据集中存在相似度很高的图像,首先需要对这些未筛选图像进行聚类,以便在检索时能快速找到与查询图像相似的图像。聚类算法会将视觉上非常相似的图像分组到同一组内。
为了顺利进行聚类过程,需要先计算每个图像的嵌入(Embeddings)。DINOv2 使用了在 ImageNet-22k上 进行预训练过的 ViT-H/16 自监督神经网络来计算每个图像的嵌入。
计算出每个图像的嵌入向量后,DINOv2 采用了 k-means 聚类算法将嵌入向量相似的图像放到同一聚类中。接下来,给定一个查询图像,DINOv2 从与查询图像所在的聚类中检索 N(通常为 4)个最相似的图像。如果查询图像所在的聚类太小,DINOv2 会从聚类中抽样 M 张图像(M 是由视觉检查结果后决定的)。最后,将这些相似的图像和查询图像一起用于预训练,以获得一个更优质、精心筛选过的大规模预训练数据集。
LVD-142M
通过上述流程,Meta AI 从 12亿 张图片中得到了经过整理的 1.42 亿张图像,命名为 LVD-142M 数据集。这一过程中,通过采用自监督图像检索技术,大大提高了数据集的质量和多样性,为后面 DINOv2 的训练提供了更加丰富的数据资源。
1.3 训练方法与技术的改进
1.3.1 训练方法:Discriminative Self-supervised Pre-training
DINOv2 采用了一种区分性自监督方法(Discriminative Self-supervised Pre-training)来学习特征,这种方法可以看作是 DINO 和 iBOT 损失以及 SwAV 中心化的组合)。
简单来说,DINOv2 使用了两种目标函数来训练网络。第一种是 Image-level 的目标函数,其使用 ViT 的 cls token 的特征,通过比较从同一图像的不同部分得到的学生网络和教师网络的 cls token 输出来计算交叉熵损失。第二种是 Patch-level 的目标函数,它通过随机屏蔽学生网络输入的一些 patch(不是教师网络),并对每个被屏蔽的 patch 的特征进行交叉熵损失的计算。这两种目标函数的权重需要单独调整,以便在不同尺度上获得更好的性能。
同时,为了更好地训练网络,作者还采用了一些技巧。例如,解除两个目标函数之间的权重绑定,以解决模型在不同尺度下的欠拟合和过拟合问题。此外,作者使用了 Sinkhorn-Knopp centering 来规范化数据,并使用 KoLeo regularizer 鼓励批次内特征的均匀分布。最后,为了提高像素级下游任务(如分割或检测)的准确性,作者采用了逐步增加图像分辨率的技术,进一步提高了模型的表现。
具体而言,作者们实现了以下几种方法:
- Image-level objective:利用一种交叉熵损失函数来比较从学生和教师网络中提取出的特征。这些特征都来自于ViT的cls token,通过对同一图像的不同裁剪图像进行提取得到。作者们使用指数移动平均法(EMA)来构建教师模型,学生模型的参数则通过训练得到。
- Patch-level objective:随机遮盖一些输入patch,然后对学生网络和教师网络在遮盖的 patch上的特征进行交叉熵损失函数的比较。这种损失函数与图像级别的损失函数相结合。
- Untying head weights between both objectives:作者们发现,将两种目标的权重绑定在一起会导致模型在 Patch-level 欠拟合,在 Image-level 过拟合。分离这些权重可以解决这个问题,并提高两种尺度上的性能。
- Sinkhorn-Knopp centering: 这个方法是对 DINO 和 iBOT 两种方法中的一些步骤进行改进,具体可见这篇论文: Unsupervised Learning of Visual Features by Contrasting Cluster Assignments (arxiv.org)
- KoLeo regularizer:KoLeo regularizer 是一种正则化方法,它通过计算特征向量之间的差异来确保它们在批次内均匀分布,其源自于 Kozachenko-Leonenko 微分熵估计器,并鼓励批次内特征的均匀跨度。具体见: Spreading vectors for similarity search (arxiv.org)
- Adapting the resolution:这一步主要是涉及在预训练的最后一段时间内,将图像的分辨率提高到 518×518 ,便在下游任务中更好地处理像素级别的信息,例如分割或检测任务。高分辨率的图像通常需要更多的计算资源和存储空间,因此只在预训练的最后阶段使用这种方法,以减少时间和资源成本。
1.3.2 训练技术的工程改进
同时,DINOv2 也利用了一系列的工程化改进,以便在更大的范围内训练模型。通过利用最新的 Pytorch 2.0 的数据并行、分布式训练、混合精度训练与 variable-length memory-efficient attention 等技术,在同等硬件的情况下,新的代码运行速度大约是之前的两倍,而内存使用量只有原来的三分之一,这可以帮助 DINOv2 在数据、模型大小和硬件方面进行更加高效的扩展。
1.3.3 蒸馏得到好的轻量模型
我们也要注意到,大模型虽好,但其硬件和算力的要求太高,我们总是希望着出现门槛没那么高的 Strong, lightweight models 的出现。
因此,Meta AI 通过模型蒸馏的方法,将大模型的知识压缩到较小的模型中,使后续跟进的研究者只需付出最小的准确性代价,就能大大降低推理成本。同时,得到的 ViT-Small、ViT-Base 和 ViT-Large 模型也在下游任务上展现出不错的泛化性能,具体可见后面的实验结果。
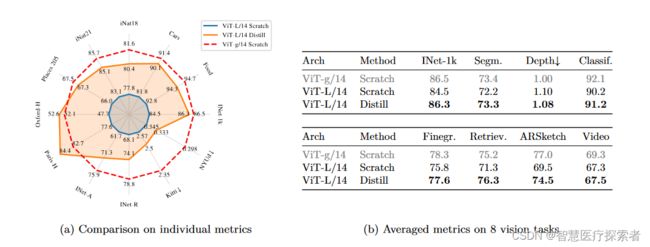
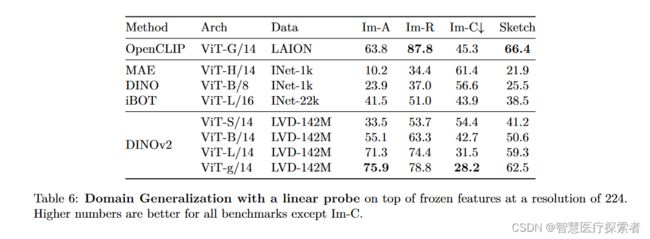
1.4 预训练模型的评估结果
首先是必须要有的 ImageNet-1k 上的结果,可以看到 DINOv2 在 linear evaluation 上比以前的 SOTA(在 ImageNet-22k 上训练的 iBOT ViT-L/16)有非常明显的改进(+4.2%)。

其次是图像和视频分类与细粒度分类的结果:

作为经典的 Downsteam task,分割必不可少:
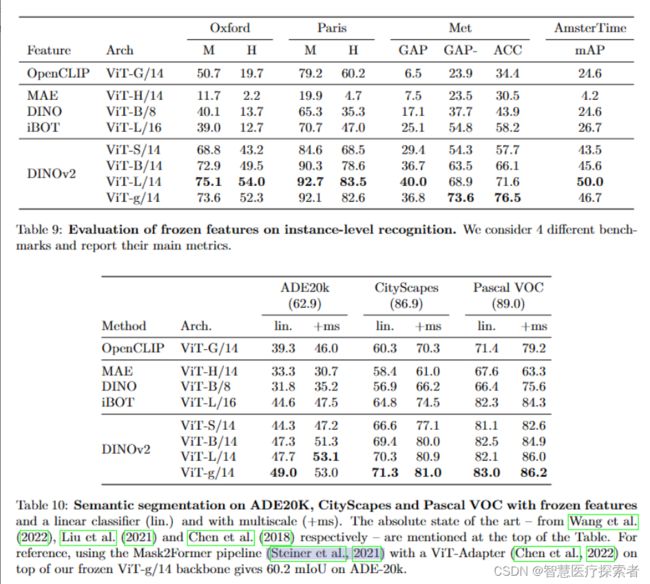
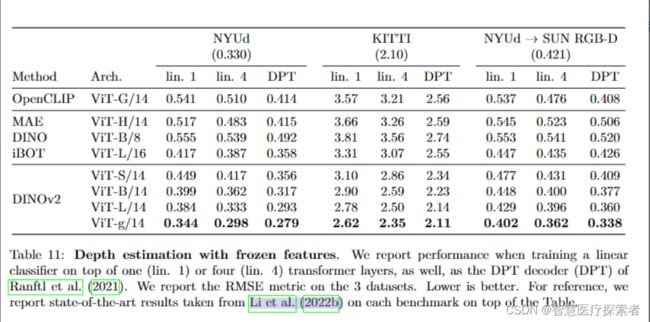
还有不太常见的,单目深度估计的结果:
1.5 发布了一系列高性能的预训练模型
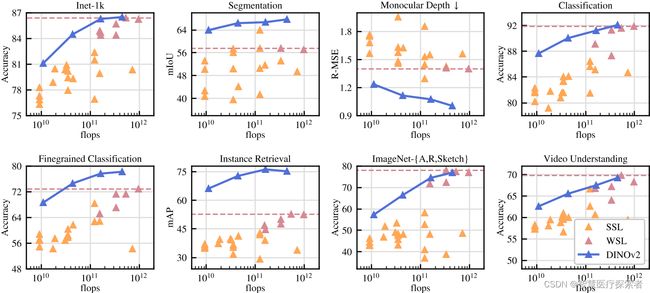
在这里,Meta AI 也向社区发布了一系列 DINOv2 预训练模型。DINOv2 作为特征提取器可以开箱即用,无需微调就能在多个下游任务上取得相当好的结果(在 ImageNet-1k 上,linear evaluation 比 Fine-tuning 只有 2% 内的差距),如下图所示:
1.6 效果展示
1.6.1 深度估计(Depth Estimation)
一般很少有预训练模型展示自己在深度估计方面的能力,这也说明了 DINOv2 模型表现出强大的分布外泛化能力(strong out-of-distribution performance)。
这里,特意选取了一直非自然光照条件下的夜景作为测试,得到的结果还是非常惊艳的!

1.6.2 语义分割(Semantic Segmentation)
DINOv2 的冻结特征(frozen features)可以很容易地用于语义分割任务。

这里就是简单的语义分割,没有 SAM 在分割任务上的可玩性那么强。
1.6.3 实例检索(Instance Retrieval)
这是我认为很有意思的一个Demo,它是从大量的艺术图片集合中找到与给定图片相似的艺术作品。这里上传了一张黄鹤楼的图片作为 Query:

这是 Dinov2 给出的结果,感觉在语义上还是十分接近的(都有一个高耸的塔或楼 )
1.6.4 其他效果展示与比较





2 使用DINOv2实现图像的特征提取
DINOv2四种size的模型:
"small": "dinov2_vits14",
"base": "dinov2_vitb14",
"large": "dinov2_vitl14",
"largest": "dinov2_vitg14",原始图片:

import torch
import torchvision.transforms as T
import matplotlib.pyplot as plt
import numpy as np
import matplotlib.image as mpimg
from PIL import Image
from sklearn.decomposition import PCA
import matplotlib
patch_h = 28
patch_w = 28
feat_dim = 384 # vits14
transform = T.Compose([
T.GaussianBlur(9, sigma=(0.1, 2.0)),
T.Resize((patch_h * 14, patch_w * 14)),
T.CenterCrop((patch_h * 14, patch_w * 14)),
T.ToTensor(),
T.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)),
])
dinov2_vits14 = torch.hub.load('facebookresearch/dinov2', 'dinov2_vits14', source='github')
features = torch.zeros(4, patch_h * patch_w, feat_dim)
imgs_tensor = torch.zeros(4, 3, patch_h * 14, patch_w * 14)
img_path = f'../data/cat_dog.jpg'
img = Image.open(img_path).convert('RGB')
imgs_tensor[0] = transform(img)[:3]
with torch.no_grad():
features_dict = dinov2_vits14.forward_features(imgs_tensor)
features = features_dict['x_norm_patchtokens']
features = features.reshape(4 * patch_h * patch_w, feat_dim).cpu()
pca = PCA(n_components=3)
pca.fit(features)
pca_features = pca.transform(features)
pca_features[:, 0] = (pca_features[:, 0] - pca_features[:, 0].min()) / (
pca_features[:, 0].max() - pca_features[:, 0].min())
pca_features_fg = pca_features[:, 0] > 0.3
pca_features_bg = ~pca_features_fg
b = np.where(pca_features_bg)
## 前景
pca.fit(features[pca_features_fg])
pca_features_rem = pca.transform(features[pca_features_fg])
for i in range(3):
pca_features_rem[:, i] = (pca_features_rem[:, i] - pca_features_rem[:, i].min()) / (
pca_features_rem[:, i].max() - pca_features_rem[:, i].min())
# 使用平均值和标准差进行变换,个人发现这种变换可以提供更好的可视化效果
# pca_features_rem[:, i] = (pca_features_rem[:, i] - pca_features_rem[:, i].mean()) / (pca_features_rem[:, i].std() ** 2) + 0.5
pca_features_rgb = pca_features.copy()
pca_features_rgb[pca_features_fg] = pca_features_rem
pca_features_rgb[b] = 0
pca_features_rgb = pca_features_rgb.reshape(4, patch_h, patch_w, 3)
plt.imshow(pca_features_rgb[0][..., ::-1])
plt.savefig('features_s14.png')
plt.show()
plt.close()运行结果显示:
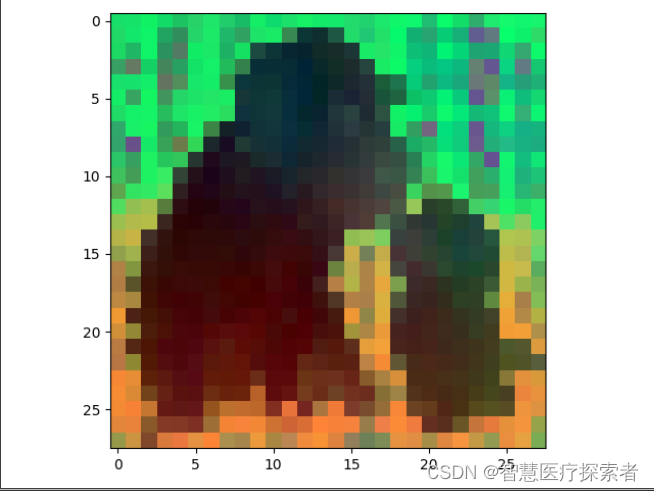
可以尝试不同的size模型,模型越大,效果越好。
3 总结
DINOv2的开源,无疑将进一步推动人工智能领域的发展。借助这个工具,科研人员可以更深入地研究图像和视频的理解机理,开发出更为先进的AI应用。同时,广大开发者和企业也将从这项技术中获益,加速各类智能化应用的落地。
DINOv2 作为一种无需 fine-tuning 的自监督方法,在提取图像特征方面表现出色,适用于许多不同的视觉任务。它的开源也为广大研究者和工程师提供了一种新的选择,有望为计算机视觉领域带来更多的突破,可以期待更多基于 DINOv2 的研究工作出现。
值得注意的是,DINOv2虽然在图像分类和对象检测方面取得了显著成果,但还存在一些局限性。例如,它对计算资源的消耗相对较大,可能需要高配置的硬件设施才能实现最佳性能。此外,对于某些复杂的应用场景,可能仍需要进行一定的微调。
尽管如此,DINOv2仍然为人工智能领域带来了巨大的进步。它的双阶段训练方法为解决视觉任务提供了新的思路,其无需微调的特点也将大大降低开发成本。随着研究的深入,我们有理由相信,DINOv2在未来将不断得到优化和改进,为各类智能化应用提供更强大、更灵活的支持。
总之,Meta开源DINOv2视觉大模型是一项重磅举措。这不仅为全球AI研究者和开发人员提供了新的强大工具,还有望推动人工智能领域的进一步发展。我们期待着DINOv2在未来的更多应用和突破,为人类社会带来更多惊喜和可能性。