机器学习——四大线性回归模型详解(包含理论讲解+公式推导,非常适合初学者!)
文章目录
- 1 线性回归模型
-
- 1.1 一元线性回归(Simple linear regression)
- 1.2 多元线性回归(Multivariate linear regression)
- 1.3 对数线性回归(Log linear regression)
- 1.4 对数几率回归(Logistic Regression)
1 线性回归模型
线性模型概念:通过数据学习得到一个通过自变量的线性组合来进行预测因变量的函数
y = w 1 x 1 + w 2 x 2 + ⋯ + w n x n + b (1.1) y=w_1x_1+w_2x_2+\cdots +w_nx_n+b\tag{1.1} y=w1x1+w2x2+⋯+wnxn+b(1.1)
大多数所见到的均为向量形式,如下:
y = w T x + b (1.2) y=w^Tx+b\tag{1.2} y=wTx+b(1.2)
1.1 一元线性回归(Simple linear regression)
已知数据集 D = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , ⋯ , ( x n , y n ) } D=\left \{ (x_1,y_1),(x_2,y_2),\cdots ,(x_n,y_n) \right \} D={(x1,y1),(x2,y2),⋯,(xn,yn)},仅存在一个自变量 x x x与一个因变量 y y y。
对于一元线性回归我们试图学得:
f ( x i ) = w x i + b , 使得 f ( x i ) ≈ y i (1.1.1) f(x_i)=\bold{wx_i}+b,使得f(\bold{x_i})\approx y_i\tag{1.1.1} f(xi)=wxi+b,使得f(xi)≈yi(1.1.1)
因此确定 w w w 与 b b b 是主要的问题,并且上式表明 f ( x i ) 与 y f(x_i)与y f(xi)与y之间的差别需要尽可能的小,在回归任务中常用均方误差作为性能度量,故我们可以尝试让均方误差最小:
( w ∗ , b ∗ ) = a r g m i n ( w , b ) ∑ i = 1 m ( f ( x i ) − y i ) 2 = a r g m i n ( w , b ) ∑ i = 1 m ( y i − w x i − b ) 2 (1.1.2) \begin{aligned} (w^*,b^*)&=arg\underset{(w,b)}{min} \sum_{i=1}^{m}(f(x_i) -y_i)^2 \\&=arg\underset{(w,b)}{min} \sum_{i=1}^{m}(y_i-wx_i-b)^2\tag{1.1.2} \end{aligned} (w∗,b∗)=arg(w,b)mini=1∑m(f(xi)−yi)2=arg(w,b)mini=1∑m(yi−wxi−b)2(1.1.2)
注:上式 a r g m i n ( w , b ) arg\underset{(w,b)}{min} arg(w,b)min 的含义就是求得均方误差 ∑ i = 1 m ( f ( x i ) − y i ) 2 \sum_{i=1}^{m}(f(x_i) -y_i)^2 ∑i=1m(f(xi)−yi)2最小值时所对应的 w w w 与 b b b 的值。
这种基于均方误差最小化的模型称为 “最小二乘法” \bold{“最小二乘法”} “最小二乘法”,此处均方误差的公式恰好对应了 欧式距 离 1 \bold{欧式距离^1} 欧式距离1,该算法的目的就是试图找到一条直线,使得样本点欧式距离直线之和最小。
1.欧式距离:假设二维平面存在两点 A ( x 1 , y 1 ) 、 B ( x 2 , y 2 ) A(x_1,y_1)、B(x_2,y_2) A(x1,y1)、B(x2,y2),两点之间的欧式距离为
d = ( x 1 − x 2 ) 2 + ( y 1 − y 2 ) 2 (1.1.3) d=\sqrt{(x_1-x_2)^2+(y_1-y_2)^2} \tag{1.1.3} d=(x1−x2)2+(y1−y2)2(1.1.3)
三维空间下的欧式距离为:
d = ( x 1 − y 1 ) 2 + ( x 2 − y 2 ) 2 + ⋯ + ( x n − y 2 ) 2 (1.1.4) d=\sqrt{(x_1-y_1)^2+(x_2-y_2)^2+\cdots+(x_n-y_2)^2} \tag{1.1.4} d=(x1−y1)2+(x2−y2)2+⋯+(xn−y2)2(1.1.4)
推广到N维空间下,如下式:
d = ( x 2 − x 1 ) 2 + ( y 2 − y 2 ) 2 + ( z 2 − z 1 ) 2 (1.1.5) d=\sqrt{(x_2-x_1)^2+(y_2-y_2)^2+(z_2-z_1)^2}\tag{1.1.5} d=(x2−x1)2+(y2−y2)2+(z2−z1)2(1.1.5)
求解 w w w与 b b b的过程,实际上是求函数 E ( w , b ) = ∑ i = 1 m ( y i − w x i − b ) 2 E(w,b)=\sum_{i=1}^{m}(y_i-wx_i-b)^2 E(w,b)=∑i=1m(yi−wxi−b)2最小化的过程,该过程称为最小线性回归的最小二乘参数估计(Parameter Estimation)。
根据高等数学的知识我们可以知道,对于一个多元函数求最值,是对参数求偏导,并令其偏导为0,故有以下的数学过程:
∂ E ( w , b ) ∂ w = ∂ ∂ x [ ∑ i = 1 m ( y i − w x i − b ) 2 ] = 2 ∗ ( − x i ) [ ∑ i = 1 m ( y i − w x i − b ) 2 − 1 ] = ∑ i = 1 m − 2 x i y i + 2 w x i 2 + 2 b x i = 2 [ w ∑ i = 1 m x i 2 − ∑ i = 1 m ( y i − b ) x i ] (1.1.6) \begin{aligned} \frac{\partial E(w,b)}{\partial w}&=\frac{\partial }{\partial x}[\sum_{i=1}^{m}(y_i-wx_i-b)^2] \\&=2*(-x_i)[\sum_{i=1}^{m}(y_i-wx_i-b)^{2-1}] \\&=\sum_{i=1}^{m}-2x_iy_i+2wx_i^{2} +2bx_i \\&=2[w\sum_{i=1}^{m}x_i^2-\sum_{i=1}^{m}(y_i-b)x_i]\tag{1.1.6} \end{aligned} ∂w∂E(w,b)=∂x∂[i=1∑m(yi−wxi−b)2]=2∗(−xi)[i=1∑m(yi−wxi−b)2−1]=i=1∑m−2xiyi+2wxi2+2bxi=2[wi=1∑mxi2−i=1∑m(yi−b)xi](1.1.6)
∂ E ( w , b ) ∂ b = ∂ ∂ x [ ∑ i = 1 m ( y i − w x i − b ) 2 ] = 2 ∗ ( − 1 ) [ ∑ i = 1 m ( y i − w x i − b ) 2 − 1 ] = ∑ i = 1 m [ 2 ∗ ( b − y i + w x i ) ] = 2 [ ∑ i = 1 m b − ∑ i = 1 m y i + ∑ i = 1 m w x i ] = 2 [ m b − ∑ i = 1 m ( y i − w x i ) ] (1.1.7) \begin{aligned} \frac{\partial E(w,b)}{\partial b}&=\frac{\partial }{\partial x}[\sum_{i=1}^{m}(y_i-wx_i-b)^2] \\&=2*(-1)[\sum_{i=1}^{m}(y_i-wx_i-b)^{2-1}] \\&=\sum_{i=1}^{m}[2*(b-y_i+wx_i)] \\&=2[\sum_{i=1}^{m}b-\sum_{i=1}^{m}y_i+\sum_{i=1}^mwx_i] \\&=2[mb-\sum_{i=1}^m(y_i-wx_i)]\tag{1.1.7} \end{aligned} ∂b∂E(w,b)=∂x∂[i=1∑m(yi−wxi−b)2]=2∗(−1)[i=1∑m(yi−wxi−b)2−1]=i=1∑m[2∗(b−yi+wxi)]=2[i=1∑mb−i=1∑myi+i=1∑mwxi]=2[mb−i=1∑m(yi−wxi)](1.1.7)
最终得到对于 w w w、 b b b偏导为:
∂ E ( w , b ) ∂ w = 2 [ w ∑ i = 1 m x i 2 − ∑ i = 1 m ( y i − b ) x i ] (1.1.8) \frac{\partial E(w,b)}{\partial w}=2[w\sum_{i=1}^{m}x_i^2-\sum_{i=1}^{m}(y_i-b)x_i]\tag{1.1.8} ∂w∂E(w,b)=2[wi=1∑mxi2−i=1∑m(yi−b)xi](1.1.8)
∂ E ( w , b ) ∂ b = 2 [ m b − ∑ i = 1 m ( y i − w x i ) ] (1.1.9) \frac{\partial E(w,b)}{\partial b}=2[mb-\sum_{i=1}^m(y_i-wx_i)]\tag{1.1.9} ∂b∂E(w,b)=2[mb−i=1∑m(yi−wxi)](1.1.9)
分别令: ∂ E ( w , b ) ∂ w = 0 , ∂ E ( w , b ) ∂ b = 0 \frac{\partial E(w,b)}{\partial w}=0,\frac{\partial E(w,b)}{\partial b}=0 ∂w∂E(w,b)=0,∂b∂E(w,b)=0
解得:
b = 1 m ∑ i = 1 m ( y i − w x i ) , w = ∑ i = 1 m y i ( x i − x ˉ ) ∑ i = 1 m x i 2 − 1 m ( ∑ i = 1 m x i ) 2 (1.1.10) \begin{aligned} b&=\frac{1}{m}\sum_{i=1}^m(y_i-wx_i) ,w=\frac{\sum_{i=1}^my_i(x_i-\bar{x})}{\sum_{i=1}^mx_i^2-\frac{1}{m}(\sum_{i=1}^mx_i)^2}\tag{1.1.10} \end{aligned} b=m1i=1∑m(yi−wxi),w=∑i=1mxi2−m1(∑i=1mxi)2∑i=1myi(xi−xˉ)(1.1.10)
就此,我们得到了一元线性回归模型的解。
1.2 多元线性回归(Multivariate linear regression)
已知数据集 D = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , ⋯ , ( x n , y n ) } D=\left \{ (x_1,y_1),(x_2,y_2),\cdots ,(x_n,y_n) \right \} D={(x1,y1),(x2,y2),⋯,(xn,yn)},其中 x i = ( x i 1 , x i 2 , ⋯ , x i d ) x_i={(x_{i1},x_{i2},\cdots ,x_{id})} xi=(xi1,xi2,⋯,xid)
更多情况下,数据集并非单个属性,而是由多个属性构成,此时称为多元线性回归。
对于多元线性回归我们试图学得:
f ( x i ) = w T x i + b , 使得 f ( x i ) ≈ y i f(x_i)=\bold{w^Tx_i}+b,使得f(\bold{x_i})\approx y_i f(xi)=wTxi+b,使得f(xi)≈yi
其中 X X X 为 ( N × d ) (N\times d) (N×d)维向量,而由于常数项的存在导致 W W W 维度为 ( N + 1 ) × 1 (N+1)\times 1 (N+1)×1
X = ( x 11 ⋯ x 1 d x 21 ⋯ x 2 d ⋯ ⋯ ⋯ ⋯ ⋯ ⋯ x n 1 ⋯ x 1 d ) w = ( w 0 w 1 ⋯ w n − 1 w n ) X=\begin{pmatrix} x_{11}& \cdots& x_{1d}& \\ x_{21}& \cdots& x_{2d}& \\ \cdots& \cdots& \cdots& \\ \cdots& \cdots& \cdots& \\ x_{n1}& \cdots& x_{1d}& \end{pmatrix} w=\begin{pmatrix} w_0\\ w_1\\\cdots \\w_{n-1} \\w_n \end{pmatrix} X=⎝ ⎛x11x21⋯⋯xn1⋯⋯⋯⋯⋯x1dx2d⋯⋯x1d⎠ ⎞w=⎝ ⎛w0w1⋯wn−1wn⎠ ⎞
为了方便运算,我们在 X X X后增加一列,其值均为1,得到
X = ( x 11 ⋯ x 1 d 1 x 21 ⋯ x 2 d 1 ⋯ ⋯ ⋯ ⋯ ⋯ ⋯ ⋯ ⋯ x n 1 ⋯ x 1 d 1 ) X=\begin{pmatrix} x_{11}& \cdots& x_{1d}&1 \\ x_{21}& \cdots& x_{2d}& 1\\ \cdots& \cdots& \cdots&\cdots \\ \cdots& \cdots& \cdots& \cdots\\ x_{n1}& \cdots& x_{1d}&1 \end{pmatrix} X=⎝ ⎛x11x21⋯⋯xn1⋯⋯⋯⋯⋯x1dx2d⋯⋯x1d11⋯⋯1⎠ ⎞
该步骤的目的是为了将偏置 b b b合并至 w w w,便于后续的求解运算。
与此同时,我们将 y y y写成向量的形式 y = ( y 1 ; y 2 ; y 3 ; … ; y n ) y=(y_1;y_2;y_3;\dots;y_n) y=(y1;y2;y3;…;yn),类似于式(1.1.2),我们得到
w ^ ∗ = arg min w ^ ( y − X w ^ ) T ( y − X w ^ ) \bold{\hat{w}}^*=\arg \underset{\hat{w}}{\min} (\bold{y-X\hat{w})^T(y-X\hat{w})} w^∗=argw^min(y−Xw^)T(y−Xw^)
令 E ( w ^ ) = ( y − X w ^ ) T ( y − X w ^ ) E(\hat{w})=\bold{(y-X\hat{w})^T(y-X\hat{w})} E(w^)=(y−Xw^)T(y−Xw^),对 w ^ \hat{w} w^求偏导:
∂ E ( w ) ∂ x = 2 X T ( X w ^ − y ) \frac{\partial E(w)}{\partial x} =2\bold{X^T(X\hat{w}-y)} ∂x∂E(w)=2XT(Xw^−y)
令上式=0,最终得到 w w w的解为:
w = ( X T X ) − 1 X T y \bold{w=(X^TX)^{-1}X^Ty} w=(XTX)−1XTy
注意,该解只适用于满秩矩阵,但实际我们往往遇到的不是满秩矩阵,遇到的变量数目超过样本量,导致 X X X的列数大于行数,此时就需要引入正则项。
1.3 对数线性回归(Log linear regression)
基本形式: l n y = w T x + b (1.3.1) 基本形式 :lny=w^Tx+b \tag{1.3.1} 基本形式:lny=wTx+b(1.3.1)
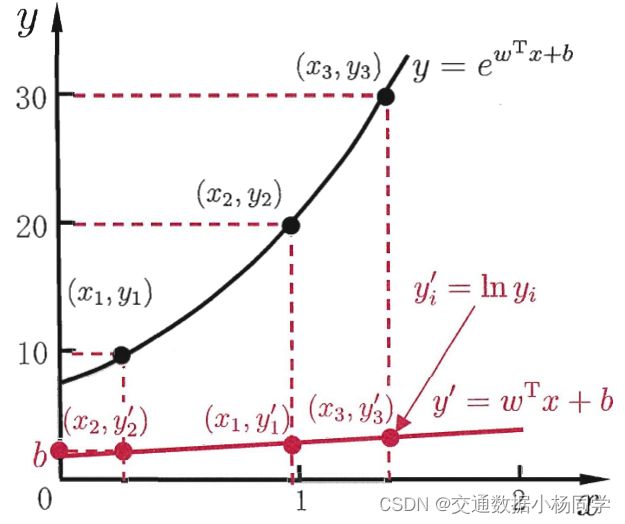
该形式实际上是使得 e w T x + b e^{w^Tx+b} ewTx+b 逼近 y y y,更一般的情况我们可以考虑单调可微函数 g ( ⋅ ) g(\cdot) g(⋅),令
y = g − 1 ( w T x + b ) (1.3.2) y=g^{-1}(w^Tx+b)\tag{1.3.2} y=g−1(wTx+b)(1.3.2)
这样得到的模型称为“广义线性模型”(generalized linear model),其中 g ( ⋅ ) g(\cdot) g(⋅)称为联系函数,模型中的 g − 1 g^{-1} g−1 为 g ( ⋅ ) g(\cdot) g(⋅) 的反函数,此处要注意的是 w T x + b w^Tx+b wTx+b为函数的自变量,而并非 g − 1 g^{-1} g−1与 w T x + b w^Tx+b wTx+b的乘积
1.4 对数几率回归(Logistic Regression)
对数几率回归也称逻辑回归,是用于处理二分类任务的,其输出值 y ∈ { 0 , 1 } y\in \left \{ 0,1 \right \} y∈{0,1}
一般线性回归模型 y = w T x + b y=w^Tx+b y=wTx+b 的输出值为实值,因此我们需要考虑将这些实值转化为0-1值,此处就需要用到对数几率函数(Logistic function):
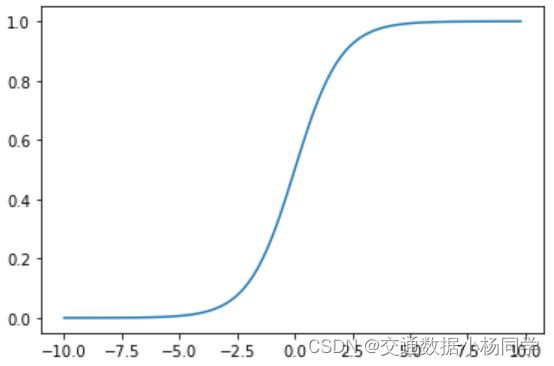
y = 1 1 + e − z (1.4.1) y=\frac{1}{1+e^{-z}}\tag{1.4.1} y=1+e−z1(1.4.1)
该函数是一种 S i g m o i d Sigmoid Sigmoid函数,它能够很好地将输出值转化为[0,1]间的值,该函数具有如下的特性:当 x x x趋近于负无穷时, y y y趋近于 0 0 0;当 x x x趋近于正无穷时, y y y趋近于1;当 x = 0 x=0 x=0时, y = 1 / 2 y=1/2 y=1/2
其函数如下图:
为了满足二分类任务的要求,我们将对数几率函数作为 g ( ⋅ ) − 1 g(\cdot)^{-1} g(⋅)−1代入广义线性模型中得到对数几率回归模型:
y = 1 1 + e − ( w T x + b ) (1.4.2) y=\frac{1}{1+e^{-(w^Tx+b)}}\tag{1.4.2} y=1+e−(wTx+b)1(1.4.2)
此处为了便于计算,类似于章节1.2中的处理方法,令 β = ( w ; b ) , x ^ = ( x ; 1 ) \beta=(w;b),\hat{x}=(x;1) β=(w;b),x^=(x;1)将偏置项 b b b 合并至 w w w 中,则 w T x + b w^Tx+b wTx+b 可写为 β T x \beta^Tx βTx。
故模型变化为:
y = 1 1 + e − β T x (1.4.3) y=\frac{1}{1+e^{-\beta^Tx}}\tag{1.4.3} y=1+e−βTx1(1.4.3)
像对数线性回归一样,我们对两边同时取对数:
ln y = ln 1 1 + e − β T x ln y = ln e β T x 1 + e β T x ln y = ln e β T x − ln ( 1 + e β T x ) β T x = ln y + ln ( 1 + e β T x ) (1.4.4) \begin{aligned} \ln y&=\ln \frac{1}{1+e^{-\beta^Tx}}\tag{1.4.4}\\ \ln y&=\ln {\frac{e^{\beta^Tx}}{1+e^{\beta^Tx}}}\\ \ln y&=\ln e^{\beta^Tx}-\ln (1+e^{\beta^Tx})\\ \beta^Tx&=\ln y+\ln (1+e^{\beta^Tx}) \end{aligned} lnylnylnyβTx=ln1+e−βTx1=ln1+eβTxeβTx=lneβTx−ln(1+eβTx)=lny+ln(1+eβTx)(1.4.4)
接下来对公式(1.4.4)进行化简,已知:
y = 1 1 + e − β T x = e β T x 1 + e β T x \begin{aligned} y&=\frac{1}{1+e^{-\beta^Tx}}\\ &=\frac{e^{\beta^Tx}}{1+e^{\beta^Tx}} \end{aligned} y=1+e−βTx1=1+eβTxeβTx
容易得到:
1 − y = 1 − 1 1 + e − β T x = 1 + e − β T x 1 + e − β T x − 1 1 + e − β T x = e − β T x 1 + e − β T x = 1 1 + e β T x = ( 1 + e β T x ) − 1 \begin{aligned} 1-y&=1-\frac{1}{1+e^{-\beta^Tx}}\\ &=\frac{1+e^{-\beta^Tx}}{1+e^{-\beta^Tx}}-\frac{1}{1+e^{-\beta^Tx}}\\ &=\frac{e^{-\beta^Tx}}{1+e^{-\beta^Tx}}\\ &=\frac{1}{1+e^{\beta^Tx}}=(1+e^{\beta^Tx})^{-1} \end{aligned} 1−y=1−1+e−βTx1=1+e−βTx1+e−βTx−1+e−βTx1=1+e−βTxe−βTx=1+eβTx1=(1+eβTx)−1
同时对两边取对数:
ln ( 1 − y ) = ln ( 1 + e β T x ) − 1 ln ( 1 − y ) = − ln ( 1 + e β T x ) − ln ( 1 − y ) = ln ( 1 + e β T x ) (1.4.5) \begin{aligned} \ln (1-y)&=\ln (1+e^{\beta^Tx})^{-1}\\ \ln (1-y)&=-\ln (1+e^{\beta^Tx})\\ -\ln(1-y)&=\ln (1+e^{\beta^Tx})\tag{1.4.5} \end{aligned} ln(1−y)ln(1−y)−ln(1−y)=ln(1+eβTx)−1=−ln(1+eβTx)=ln(1+eβTx)(1.4.5)
回到公式(1.4.4),将公式(1.4.5)代入得到:
β T x = ln y + ln ( 1 + e β T x ) β T x = ln y − ln ( 1 − y ) (1.4.6) \begin{aligned} \beta^Tx&=\ln y+\ln (1+e^{\beta^Tx})\\ \beta^Tx&=\ln y -\ln (1-y)\\ \tag{1.4.6} \end{aligned} βTxβTx=lny+ln(1+eβTx)=lny−ln(1−y)(1.4.6)
最终通过化简得到:
β T x = ln y 1 − y (1.4.7) \beta^Tx=\ln {\frac{y}{1-y}}\tag{1.4.7} βTx=ln1−yy(1.4.7)
若将 y y y 视为正实例 ( y = 1 ) (y=1) (y=1)的概率,那么 1 − y 1-y 1−y即为负实例 ( y = 0 ) (y=0) (y=0)的概率,此处 y 1 − y \frac{y}{1-y} 1−yy 称为几率;自然地, l n y 1 − y ln\frac{y}{1-y} ln1−yy称为对数几率。
通过式(1.4.7)我们可以观察得到,该模型是通过线性回归模型的预测值逼近真实标记的对数几率,因此称为对数几率回归,确定式中的 β \bold{\beta} β 是核心问题:
在概率统计中我们知道,对于两个独立事件 A A A 与 B B B 有: P ( A ∣ B ) = P ( A ) P(A|B)=P(A) P(A∣B)=P(A)
故得到:
y = 1 的概率 : P ( y = 1 丨 x ) = y y = 0 的概率 : P ( y = 0 丨 x ) = 1 − y \begin{aligned} y=1的概率&:P(y=1丨\bold{x})=y\\ y=0的概率&:P(y=0丨\bold{x})=1-y \end{aligned} y=1的概率y=0的概率:P(y=1丨x)=y:P(y=0丨x)=1−y
将公式(1.4.3)代入容易得到,
P ( y = 1 丨 x ) = 1 1 + e − β T x = e β T x 1 + e β T x = h ( β T x ) P ( y = 0 丨 x ) = 1 − 1 1 + e − β T x = 1 1 + e β T x = 1 − h ( β T x ) (1.4.8) \begin{aligned} P(y=1丨\bold{x})&=\frac{1}{1+e^{-\beta^T\bold{x}}}=\frac{e^{\beta^T\bold{x}}}{1+e^{\beta^T\bold{x}}}=h({\beta^Tx)} \\P(y=0丨\bold{x})&=1-\frac{1}{1+e^{-\beta^T\bold{x}}}=\frac{1}{1+e^{\beta^T\bold{x}}}=1-h({\beta^Tx)}\tag{1.4.8} \end{aligned} P(y=1丨x)P(y=0丨x)=1+e−βTx1=1+eβTxeβTx=h(βTx)=1−1+e−βTx1=1+eβTx1=1−h(βTx)(1.4.8)
根据 0 − 1 分布 0-1分布 0−1分布的公式,我们将上式合并得到:
P ( y = y i 丨 x ) = h ( β T x ) y i [ 1 − h ( β T x ) ] 1 − y i P(y=y_i丨\bold{x})=h({\beta^Tx)}^{y_i}[1-h({\beta^Tx)}]^{1-y_i} P(y=yi丨x)=h(βTx)yi[1−h(βTx)]1−yi
为了求解 w w w 与 b b b,我们采用极大似然估计法来对参数 w w w 与 b b b 进行估计:
1. 写出似然函数
L ( β ) = ∏ i = 1 n p ( y i 丨 x i , w , b ) = ∏ i = 1 n h ( β T x ) y i [ 1 − h ( β T x ) ] 1 − y i (1.4.9) \begin{aligned} L(\beta)&=\prod_{i=1}^{n}p(y_i丨x_i,w,b)\\ &=\prod_{i=1}^{n}h({\beta^Tx)}^{y_i}[1-h({\beta^Tx)}]^{1-y_i}\tag{1.4.9} \end{aligned} L(β)=i=1∏np(yi丨xi,w,b)=i=1∏nh(βTx)yi[1−h(βTx)]1−yi(1.4.9)
2. 写出对数似然函数
l n [ L ( β ) ] = ∑ i = 1 n l n h ( β T x ) y i { [ 1 − h ( β T x ) ] 1 − y i } = ∑ i = 1 n l n h ( β T x ) y i + l n [ 1 − h ( β T x ) ] 1 − y i = y i ∑ i = 1 n l n h ( β T x ) + ( 1 − y i ) ∑ i = 1 n l n [ 1 − h ( β T x ) ] = y i ∑ i = 1 n l n e β T x i 1 + e β T x i + ( 1 − y i ) ∑ i = 1 n l n 1 1 + e β T x i = y i ∑ i = 1 n [ l n e β T x i − l n ( 1 + e β T x i ) ] + ( 1 − y i ) ( − 1 ) ∑ i = 1 n l n ( 1 + e β T x i ) = y i ∑ i = 1 n l n e β T x i − y i ∑ i = 1 n l n ( 1 + e β T x i ) − ∑ i = 1 n l n ( 1 + e β T x i ) + y i ∑ i = 1 n l n ( 1 + e β T x i ) = y i ∑ i = 1 n l n e β T x i + y i ∑ i = 1 n l n ( 1 + e β T x i ) = y i ( β T x i ) − ∑ i = 1 n ln ( 1 + e β T x i ) (1.4.10) \begin{aligned} ln[L(\beta)]&=\sum_{i=1}^{n}lnh({\beta^Tx)}^{y_i}\left \{ [1-h({\beta^Tx)}]^{1-y_i} \right \}\\ &=\sum_{i=1}^{n}lnh({\beta^Tx)}^{y_i}+ln[1-h({\beta^Tx)}]^{1-y_i}\\ &=y_i\sum_{i=1}^{n}lnh(\beta^Tx)+(1-y_i)\sum_{i=1}^{n}ln[1-h({\beta^Tx)}]\\ &=y_i\sum_{i=1}^{n}ln\frac{e^{\beta^Tx_i}}{1+e^{\beta^Tx_i}}+(1-y_i)\sum _{i=1}^{n}ln\frac{1}{1+e^{\beta^Tx_i}}\\ &=y_i\sum_{i=1}^{n}[lne^{\beta^T\bold{x_i}}-ln(1+e^{\beta^T\bold{x_i}})]+(1-y_i)(-1)\sum _{i=1}^{n}ln(1+e^{\beta^Tx_i})\\ &=y_i\sum_{i=1}^{n}lne^{\beta^Tx_i}-y_i\sum _{i=1}^{n}ln(1+e^{\beta^Tx_i})-\sum _{i=1}^{n}ln(1+e^{\beta^Tx_i})+y_i\sum _{i=1}^{n}ln(1+e^{\beta^Tx_i})\\ &=y_i\sum_{i=1}^{n}lne^{\beta^Tx_i}+y_i\sum _{i=1}^{n}ln(1+e^{\beta^Tx_i})\\ &=y_i(\beta^Tx_i)-\sum _{i=1}^{n}\ln(1+e^{\beta^Tx_i})\tag{1.4.10} \end{aligned} ln[L(β)]=i=1∑nlnh(βTx)yi{[1−h(βTx)]1−yi}=i=1∑nlnh(βTx)yi+ln[1−h(βTx)]1−yi=yii=1∑nlnh(βTx)+(1−yi)i=1∑nln[1−h(βTx)]=yii=1∑nln1+eβTxieβTxi+(1−yi)i=1∑nln1+eβTxi1=yii=1∑n[lneβTxi−ln(1+eβTxi)]+(1−yi)(−1)i=1∑nln(1+eβTxi)=yii=1∑nlneβTxi−yii=1∑nln(1+eβTxi)−i=1∑nln(1+eβTxi)+yii=1∑nln(1+eβTxi)=yii=1∑nlneβTxi+yii=1∑nln(1+eβTxi)=yi(βTxi)−i=1∑nln(1+eβTxi)(1.4.10)
3. 最大化对数似然函数
max l n [ L ( β ) ] = max { y i ( β T x i ) − ∑ i = 1 n ln ( 1 + e β T x i ) } (1.4.11) \begin{aligned}\max ln[L(\beta)]=\max \left \{{y_i(\beta^Tx_i)-\sum _{i=1}^{n}\ln(1+e^{\beta^Tx_i})} \right \}\tag{1.4.11} \end{aligned} maxln[L(β)]=max{yi(βTxi)−i=1∑nln(1+eβTxi)}(1.4.11)
进而,我们对原问题进行转化,将最大化问题转换为最小化问题
max l n [ L ( β ) ] ⟹ min { − l n [ L ( β ) ] } \max ln[L(\beta)]\Longrightarrow \min \left \{ -ln[L(\beta)] \right \} maxln[L(β)]⟹min{−ln[L(β)]}
令:
ℓ ( β ) = − l n [ L ( β ) ] = − y i ( β T x i ) + ∑ i = 1 n ln ( 1 + e β T x i ) (1.4.12) \begin{aligned} \ell (\beta)&=-ln[L(\beta)]\\ &=-y_i(\beta^Tx_i)+\sum _{i=1}^{n}\ln(1+e^{\beta^Tx_i})\tag{1.4.12} \end{aligned} ℓ(β)=−ln[L(β)]=−yi(βTxi)+i=1∑nln(1+eβTxi)(1.4.12)
于是得到:
β ∗ = arg min β ℓ ( β ) (1.4.13) \beta ^*=\arg \underset{\beta}{\min}\ell(\beta)\tag{1.4.13} β∗=argβminℓ(β)(1.4.13)
接下来的任务就是利用最优化理论求解其最优解,经典的数值优化算法有牛顿法(Newton method)、梯度下降法(gradient descent method)。
如果内容对各位有帮助的话,麻烦点个赞与关注,后续会不断更新机器学习理论推导与代码实战的相关内容,十分感谢!