SpringCloud全面学习笔记之进阶篇
目录
- 前言
- 微服务保护
-
- 初识Sentinel
-
- 雪崩问题及解决方案
-
- 雪崩问题
- 超时处理
- 仓壁模式
- 熔断降级
- 流量控制
- 总结
- 服务保护技术对比
- Sentinel介绍和安装
- 微服务整合Sentinel
- 流量控制
-
- 快速入门
- 流控模式
-
- 关联模式
- 链路模式
- 小结
- 流控效果
-
- warm up
- 排队等待
- 热点参数限流
-
- 全局参数限流
- 热点参数限流
- 案例demo
- 隔离和降级
-
- FeignClient整合Sentinel
- 线程隔离
- 熔断降级
-
- 慢调用
- 异常比例 异常数
- 授权规则
-
- 授权基本规则
- 自定义异常结果
- 规则持久化
- 分布式事务
-
- 分布式事务问题
-
- 本地事务
- 分布式事务
- 分布式事务问题示例
- 理论基础
-
- CAP定理
- BASE理论
- 解决分布式事务的思路
- 小结
- 初识Seata架构
-
- Seata的架构
- 部署Seata的tc-server
- 微服务集成Seata
- 代码实践
-
- XA模式
- AT模式
- TCC模式
- SAGA模式
- 四种模式的对比
- 高可用
-
- 高可用架构模型
- 实现高可用
- 分布式缓存
-
- 单点缓存的弊端
- Redis持久化
-
- RDB持久化
- AOF持久化
- RDB与AOF对比
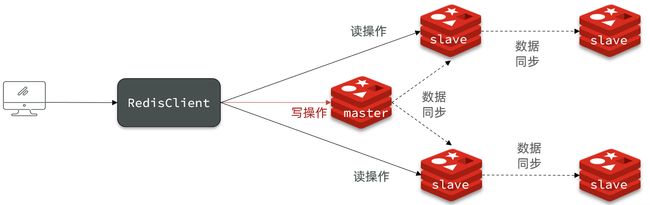
- Redis主从
-
- 搭建主从架构
- 主从数据同步原理
- 主从同步优化
- 总结
- Redis哨兵
-
- 哨兵原理
- 搭建哨兵集群
- RedisTemplate哨兵模式
- Redis分片集群
-
- 搭建分片集群
- 散列插槽
- 集群伸缩
- 故障转移
- RedisTemplate访问分片集群
- 集群最终结构
前言
本篇是学习微服务进阶篇的一些心得和学习笔记,学习资源来自B站黑马,愿我们共同进步!感谢您的阅览。
微服务保护
初识Sentinel
雪崩问题及解决方案
雪崩问题
一个服务故障导致依赖它的服务也发生故障
故障部分如下图
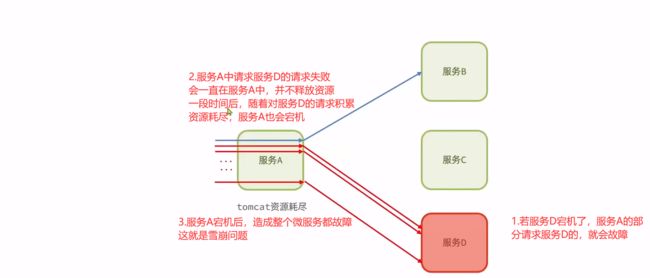
而上面故障对于整个微服务架构而言

微服务调用链路中的某个服务故障,引起整个链路中的所有微服务都不可用,这就是雪崩。
超时处理
超时处理:设定超时时间,请求超过一定时间没有响应就返回错误信息,不会无休止等待
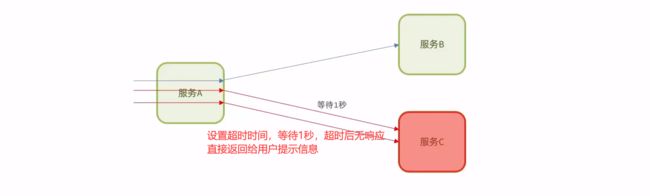
但是它并没有解决雪崩问题,只是缓解雪崩,一旦访问请求速度超过等待并返回速度,就会再次积累请求,有可能再次发生雪崩。
仓壁模式
仓壁模式来源于船舱的设计:船舱都会被隔板分离为多个独立空间,当船体破损时,只会导致部分空间进入,将故障控制在一定范围内,避免整个船体都被淹没。
于此类似,我们可以限定每个业务能使用的线程数,避免耗尽整个tomcat的资源,因此也叫线程隔离。

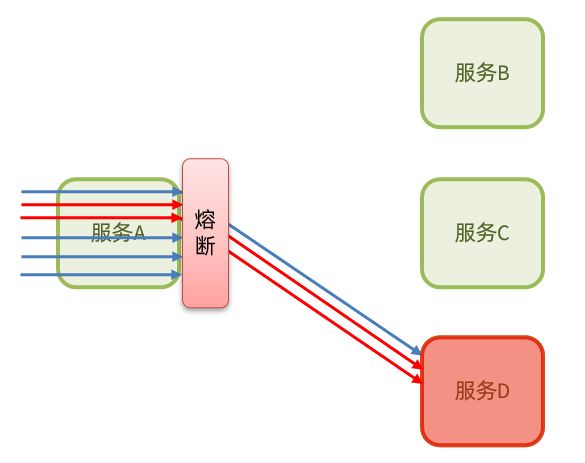
熔断降级
断路器模式:由断路器统计业务执行的异常比例,如果超出阈值则会熔断该业务,拦截访问该业务的一切请求。
断路器会统计访问某个服务的请求数量,异常比例。
当发现访问服务D的请求异常比例过高时,认为服务D有导致雪崩的风险,会拦截访问服务D的一切请求,形成熔断:

流量控制
流量控制:限制业务访问的QPS(每秒钟服务处理请求的数量),避免服务因流量的突增而故障。

前面三种方式是应对,已经出现故障了,如何避免故障传递
而此处是为了防止出现故障,主要防止的是DOS攻击,是一种预防的措施
总结
什么是雪崩问题?
- 微服务之间相互调用,因为调用链中的一个服务故障,引起整个链路都无法访问的情况。
处理方案
限流是对服务的保护,避免因瞬间高并发流量而导致服务故障,进而避免雪崩。是一种预防措施。
超时处理、线程隔离、降级熔断是在部分服务故障时,将故障控制在一定范围,避免雪崩。是一种补救措施。
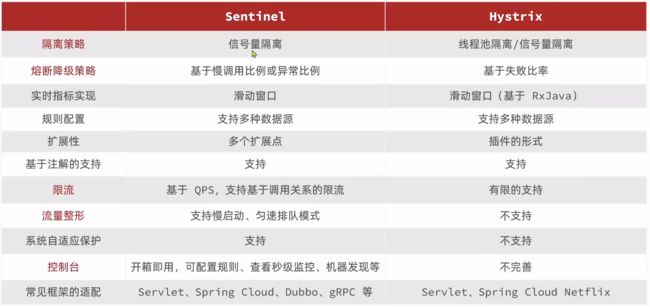
服务保护技术对比
早期比较流行的是Hystrix框架,但目前国内实用最广泛的还是阿里巴巴的Sentinel框架,这里我们做下对比:
Sentinel介绍和安装
初识Sentinel
Sentinel是阿里巴巴开源的一款微服务流量控制组件。官网地址:https://sentinelguard.io/zh-cn/index.html
Sentinel 具有以下特征:
•丰富的应用场景:Sentinel 承接了阿里巴巴近 10 年的双十一大促流量的核心场景,例如秒杀(即突发流量控制在系统容量可以承受的范围)、消息削峰填谷、集群流量控制、实时熔断下游不可用应用等。
•完备的实时监控:Sentinel 同时提供实时的监控功能。您可以在控制台中看到接入应用的单台机器秒级数据,甚至 500 台以下规模的集群的汇总运行情况。
•广泛的开源生态:Sentinel 提供开箱即用的与其它开源框架/库的整合模块,例如与 Spring Cloud、Dubbo、gRPC 的整合。您只需要引入相应的依赖并进行简单的配置即可快速地接入 Sentinel。
•完善的 SPI 扩展点:Sentinel 提供简单易用、完善的 SPI 扩展接口。您可以通过实现扩展接口来快速地定制逻辑。例如定制规则管理、适配动态数据源等。
安装Sentinel
1)下载
sentinel官方提供了UI控制台,方便我们对系统做限流设置。大家可以在GitHub下载。
2)运行
将jar包放到任意非中文目录,执行命令:
java -jar sentinel-dashboard-1.8.1.jar
如果要修改Sentinel的默认端口、账户、密码,可以通过下列配置:
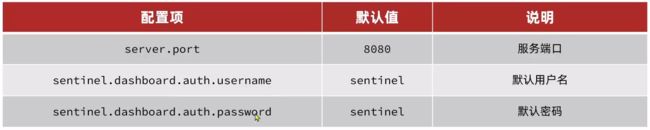
例如,修改端口:
java -Dserver.port=8090 -jar sentinel-dashboard-1.8.1.jar
3)访问
访问http://localhost:8080页面,就可以看到sentinel的控制台了:

需要输入账号和密码,默认都是:sentinel
登录后,发现一片空白,什么都没有:
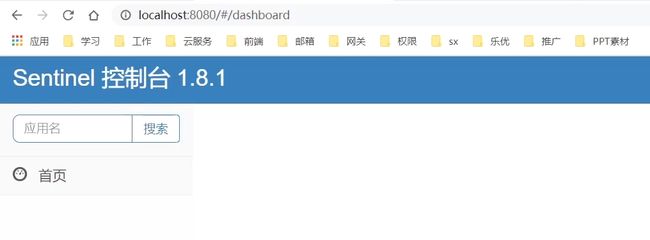
这是因为我们还没有与微服务整合。
微服务整合Sentinel
还是前面的那个cloud-demo工程中
项目结构

order-service中整合sentinel,并连接sentinel的控制台,步骤如下:
1)引入sentinel依赖
<dependency>
<groupId>com.alibaba.cloudgroupId>
<artifactId>spring-cloud-starter-alibaba-sentinelartifactId>
dependency>
2)配置yml文件
修改application.yaml文件,添加下面内容:
主要是添加sentinel的配置信息
server:
port: 8088
spring:
cloud:
sentinel:
transport:
dashboard: localhost:8080
3)访问order-service的任意端点
注意:服务启动前需要先启动 nacos,Sentinel
nacos启动方式
找到nacos的安装目录
在下面路径中键入cmd
![]()
然后控制台中输入
startup.cmd -m standalone

Sentinel启动方式
在以下路径中键入cmd
命令行中输入
java -jar sentinel-dashboard-1.8.1.jar
然后启动成功

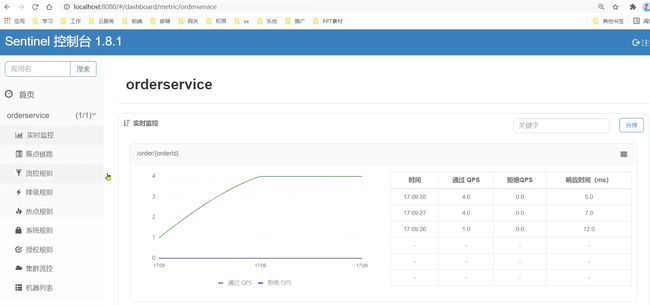
打开浏览器,访问http://localhost:8088/order/101,这样才能触发sentinel的监控。
然后再访问sentinel的控制台,查看效果:
流量控制
雪崩问题虽然有四种方案,但是限流是避免服务因突发的流量而发生故障,是对微服务雪崩问题的预防。
快速入门
启动cloud-demo服务
访问http://localhost:8080,进入Sentinel监控界面

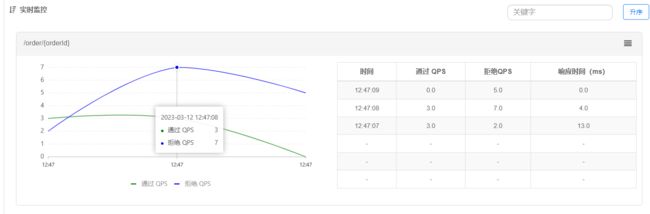
使用jmeter来测试结果,如果手速够快也可以自己手动发送3个请求
狂点刷新

每秒只通过三个请求

最后回到Sentinel监控界面,可以看到监控情况变化
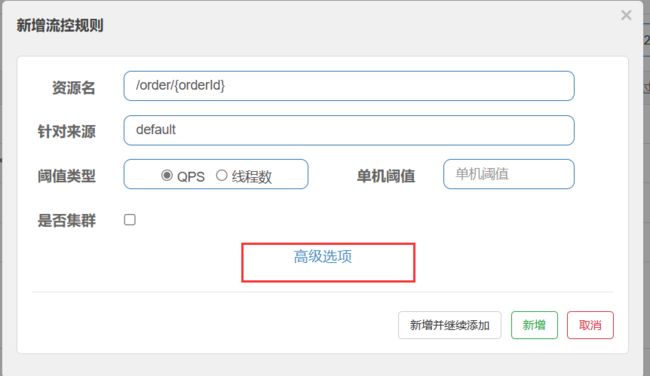
流控模式
在添加限流规则时,点击高级选项,可以选择三种流控模式:
- 直接:统计当前资源的请求,触发阈值时对当前资源直接限流,也是默认的模式
- 关联:统计与当前资源相关的另一个资源,触发阈值时,对当前资源限流
- 链路:统计从指定链路访问到本资源的请求,触发阈值时,对指定链路限流
快速入门测试的就是直接模式。

关联模式
关联模式:统计与当前资源相关的另一个资源,触发阈值时,对当前资源限流
配置规则:

语法说明:当/write资源访问量触发阈值时,就会对/read资源限流,避免影响/write资源。
因为在修改业务中,write优先级高于read,所以就会对read进行限流
使用场景:比如用户支付时需要修改订单状态,同时用户要查询订单。查询和修改操作会争抢数据库锁,产生竞争。业务需求是优先支付和更新订单的业务,因此当修改订单业务触发阈值时,需要对查询订单业务限流。
需求说明:
-
在OrderController新建两个端点:/order/query和/order/update,无需实现业务
-
配置流控规则,当/order/ update资源被访问的QPS超过5时,对/order/query请求限流
1)定义/order/query端点,模拟订单查询
@GetMapping("/query")
public String queryOrder() {
return "查询订单成功";
}
2)定义/order/update端点,模拟订单更新
@GetMapping("/update")
public String updateOrder() {
return "更新订单成功";
}
重启服务,查看sentinel控制台的簇点链路:

3)配置流控规则
对哪个端点限流,就点击哪个端点后面的按钮。我们是对订单查询/order/query限流,因此点击它后面的按钮:

在表单中填写流控规则:

4)在Jmeter测试
选择《流控模式-关联》:
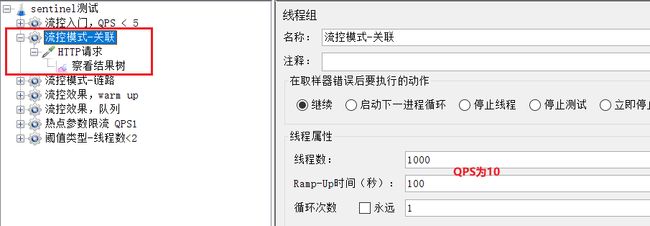
可以看到1000个用户,100秒,因此QPS为10,超过了我们设定的阈值:5
查看http请求:

请求的目标是/order/update,这样这个断点就会触发阈值。
但限流的目标是/order/query,我们在浏览器访问,可以发现:

确实被限流了。
5)总结

链路模式
链路模式:只针对从指定链路访问到本资源的请求做统计,判断是否超过阈值。
配置示例:
例如有两条请求链路:
-
/test1 --> /common
-
/test2 --> /common
如果只希望统计从/test2进入到/common的请求,则可以这样配置:

实战案例
购买优先,询问稍后(真实)
需求:有查询订单和创建订单业务,两者都需要查询商品。针对从查询订单进入到查询商品的请求统计,并设置限流。
步骤:
-
在OrderService中添加一个queryGoods方法,不用实现业务
-
在OrderController中,改造/order/query端点,调用OrderService中的queryGoods方法
-
在OrderController中添加一个/order/save的端点,调用OrderService的queryGoods方法
-
给queryGoods设置限流规则,从/order/query进入queryGoods的方法限制QPS必须小于2
实现:
1)添加查询商品方法
在order-service服务中,给OrderService类添加一个queryGoods方法:
public void queryGoods(){
System.err.println("查询商品");
}
2)查询订单时,查询商品
在order-service的OrderController中,修改/order/query端点的业务逻辑:
@GetMapping("/query")
public String queryOrder() {
// 查询商品
orderService.queryGoods();
// 查询订单
System.out.println("查询订单");
return "查询订单成功";
}
3)新增订单,查询商品
在order-service的OrderController中,修改/order/save端点,模拟新增订单:
@GetMapping("/save")
public String saveOrder() {
// 查询商品
orderService.queryGoods();
// 查询订单
System.err.println("新增订单");
return "新增订单成功";
}
4)给查询商品添加资源标记
默认情况下,OrderService中的方法是不被Sentinel监控的,需要我们自己通过注解来标记要监控的方法。
给OrderService的queryGoods方法添加@SentinelResource注解:
@SentinelResource("goods")
public void queryGoods(){
System.err.println("查询商品");
}
链路模式中,是对不同来源的两个链路做监控。但是sentinel默认会给进入SpringMVC的所有请求设置同一个root资源,会导致链路模式失效。
我们需要关闭这种对SpringMVC的资源聚合,修改order-service服务的application.yml文件:
spring:
cloud:
sentinel:
web-context-unify: false # 关闭context整合
重启服务,访问/order/query和/order/save,可以查看到sentinel的簇点链路规则中,出现了新的资源:

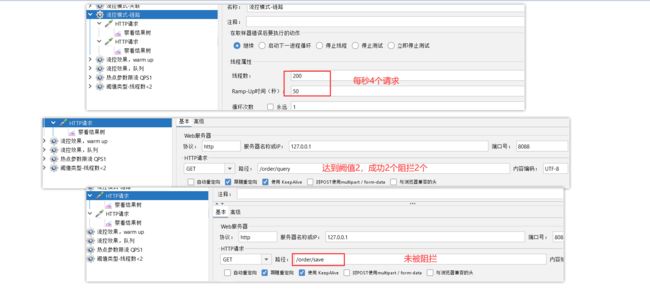
5)添加流控规则
点击goods资源后面的流控按钮,在弹出的表单中填写下面信息:


只统计从/order/query进入/goods的资源,QPS阈值为2,超出则被限流。
结果如下图所示

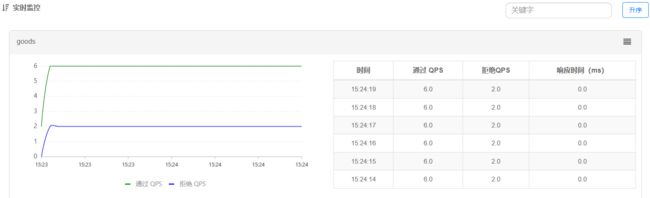
小结
流控模式有哪些?
•直接:对当前资源限流
•关联:高优先级资源触发阈值,对低优先级资源限流。
•链路:阈值统计时,只统计从指定资源进入当前资源的请求,是对请求来源的限流
流控效果
在流控的高级选项中,还有一个流控效果选项:

流控效果是指请求达到流控阈值时应该采取的措施,包括三种:
-
快速失败:达到阈值后,新的请求会被立即拒绝并抛出FlowException异常。是默认的处理方式。
-
warm up:预热模式,对超出阈值的请求同样是拒绝并抛出异常。但这种模式阈值会动态变化,从一个较小值逐渐增加到最大阈值。
-
排队等待:让所有的请求按照先后次序排队执行,两个请求的间隔不能小于指定时长
warm up
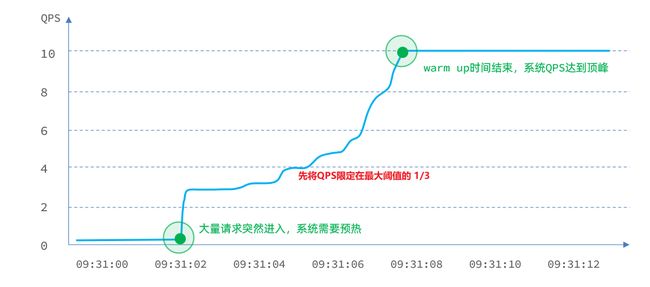
阈值一般是一个微服务能承担的最大QPS,但是一个服务刚刚启动时,一切资源尚未初始化(冷启动),如果直接将QPS跑到最大值,可能导致服务瞬间宕机。
warm up也叫预热模式,是应对服务冷启动的一种方案。请求阈值初始值是 maxThreshold / coldFactor,持续指定时长后,逐渐提高到maxThreshold值。而coldFactor的默认值是3.
例如,我设置QPS的maxThreshold为10,预热时间为5秒,那么初始阈值就是 10 / 3 ,也就是3,然后在5秒后逐渐增长到10.
案例
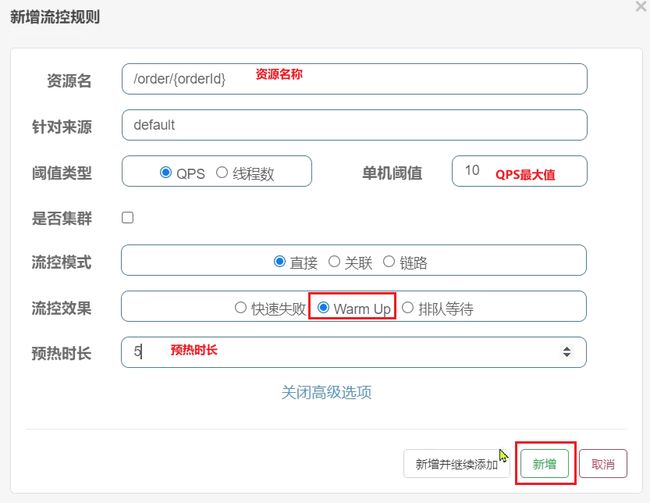
需求:给/order/{orderId}这个资源设置限流,最大QPS为10,利用warm up效果,预热时长为5秒
1)配置流控规则:
2)Jmeter测试
QPS为10.
刚刚启动时,大部分请求失败,成功的只有3个,说明QPS被限定在3:
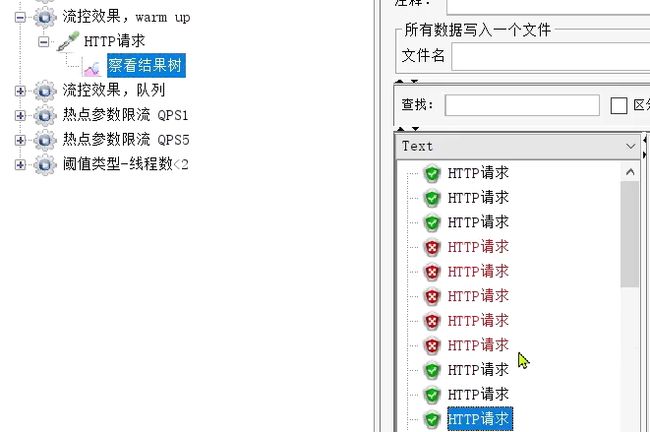
随着时间推移,成功比例越来越高:

最后监控界面可以看到,拒绝越来越少,通过逐渐变多,完成服务的预热

排队等待
当请求超过QPS阈值时,快速失败和warm up 会拒绝新的请求并抛出异常。
而排队等待则是让所有请求进入一个队列中,然后按照阈值允许的时间间隔依次执行。后来的请求必须等待前面执行完成,如果请求预期的等待时间超出最大时长,则会被拒绝。
工作原理
例如:QPS = 5(每秒处理5个请求),意味着每200ms处理一个队列中的请求;timeout = 2000,意味着预期等待时长超过2000ms的请求会被拒绝并抛出异常。
那什么叫做预期等待时长呢?
比如现在一下子来了12 个请求,因为每200ms执行一个请求,那么:
- 第6个请求的预期等待时长 = 200 * (6 - 1) = 1000ms
- 第12个请求的预期等待时长 = 200 * (12-1) = 2200ms
如果使用队列模式做流控,所有进入的请求都要排队,以固定的200ms的间隔执行,QPS会变的很平滑:
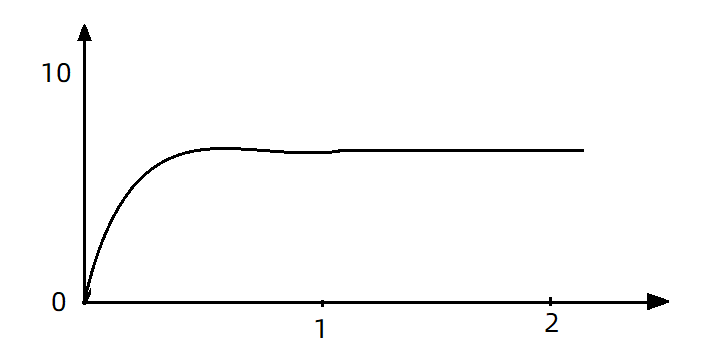
也是实现流量削峰的原理,平滑的QPS曲线,对于服务器来说是更友好的。
案例
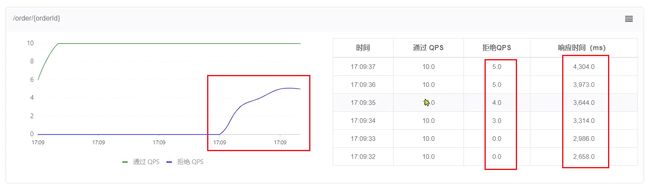
需求:给/order/{orderId}这个资源设置限流,最大QPS为10,利用排队的流控效果,超时时长设置为5s
1)添加流控规则

2)Jmeter测试

QPS为15,已经超过了我们设定的10。
如果是之前的 快速失败、warmup模式,超出的请求应该会直接报错。
但是我们看看队列模式的运行结果:
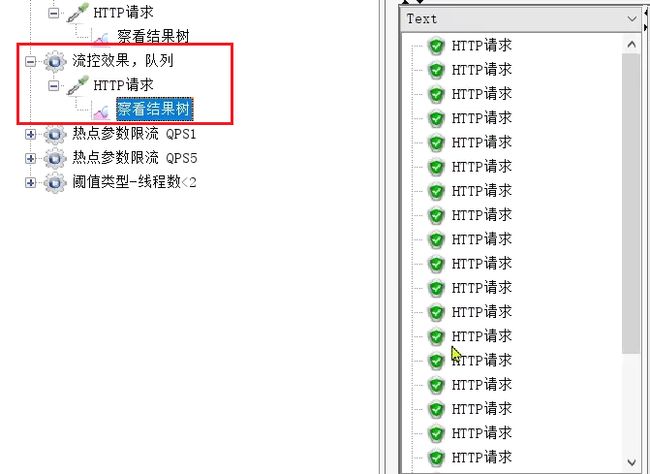
全部都通过了。
再去sentinel查看实时监控的QPS曲线:
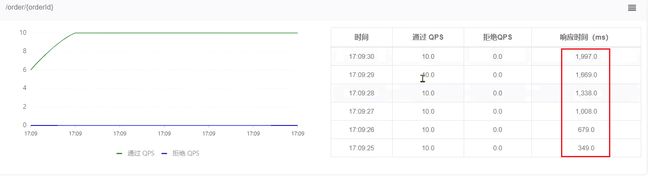
QPS非常平滑,一致保持在10,但是超出的请求没有被拒绝,而是放入队列。因此响应时间(等待时间)会越来越长。
当队列满了以后,才会有部分请求失败:
小结
流控效果有哪些?
-
快速失败:QPS超过阈值时,拒绝新的请求
-
warm up: QPS超过阈值时,拒绝新的请求;QPS阈值是逐渐提升的,可以避免冷启动时高并发导致服务宕机。
-
排队等待:请求会进入队列,按照阈值允许的时间间隔依次执行请求;如果请求预期等待时长大于超时时间,直接拒绝
热点参数限流
全局参数限流
之前的限流是统计访问某个资源的所有请求,判断是否超过QPS阈值。而热点参数限流是分别统计参数值相同的请求,判断是否超过QPS阈值。
例如,一个根据id查询商品的接口:

访问/goods/{id}的请求中,id参数值会有变化,热点参数限流会根据参数值分别统计QPS,统计结果:

当id=1的请求触发阈值被限流时,id值不为1的请求不受影响。
配置示例:


代表的含义是:对hot这个资源的0号参数(第一个参数)做统计,每1秒相同参数值的请求数不能超过5
热点参数限流
刚才的配置中,对查询商品这个接口的所有商品一视同仁,QPS都会被限定为5.
而在实际开发中,可能部分商品是热点商品,例如秒杀商品,我们希望这部分商品的QPS限制与其它商品不一样,高一些。那就需要配置热点参数限流的高级选项了:
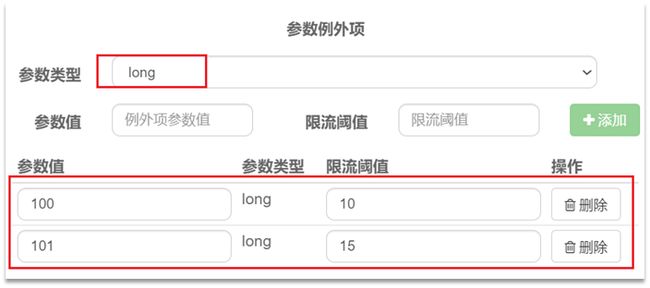
结合上一个配置,这里的含义是对0号的long类型参数限流,每1秒相同参数的QPS不能超过5,有两个例外:
•如果参数值是100,则每1秒允许的QPS为10
•如果参数值是101,则每1秒允许的QPS为15
案例demo
案例需求:给/order/{orderId}这个资源添加热点参数限流,规则如下:
•默认的热点参数规则是每1秒请求量不超过2
•给102这个参数设置例外:每1秒请求量不超过4
•给103这个参数设置例外:每1秒请求量不超过10
注意事项:热点参数限流对默认的SpringMVC资源无效,需要利用@SentinelResource注解标记资源
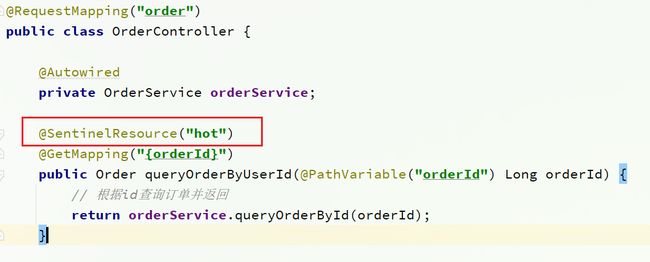
1)标记资源
给order-service中的OrderController中的/order/{orderId}资源添加注解:
2)热点参数限流规则
访问该接口,可以看到标记的hot资源出现了

这时添加热点规则需要在下面位置添加
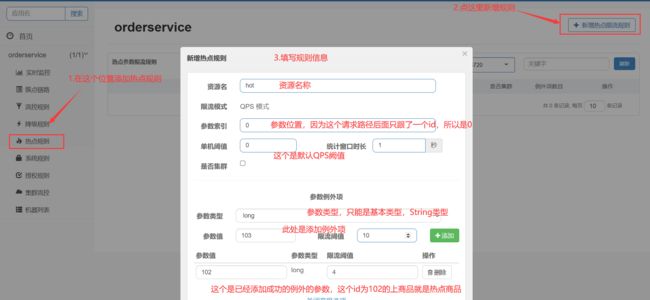
默认单机阈值要设置为2,符合上面案例的需求
3)Jmeter测试
分别对默认hot项,和设置的两个例外项来压测,做比较
默认的参数
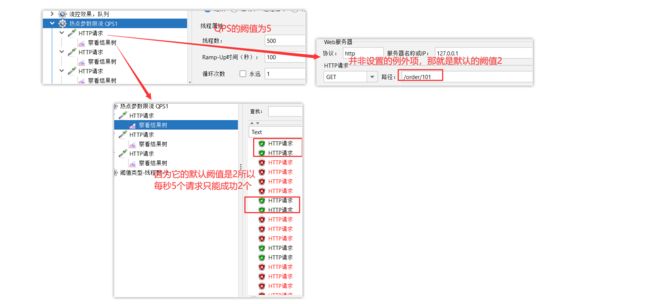
设置的例外项参数102
102的参数,QPS阈值为4


设置的例外项参数103
例外项,QPS阈值为10


它的阙值15,而测试模拟的QPS为5,所以它处理的绰绰有余,不会拒绝并返回异常
隔离和降级
限流是一种预防措施,虽然限流可以尽量避免因高并发而引起的服务故障,但服务还会因为其它原因而故障。
而要将这些故障控制在一定范围,避免雪崩,就要靠线程隔离(舱壁模式)和熔断降级手段了。
线程隔离之前讲到过:调用者在调用服务提供者时,给每个调用的请求分配独立线程池,出现故障时,最多消耗这个线程池内资源,避免把调用者的所有资源耗尽。
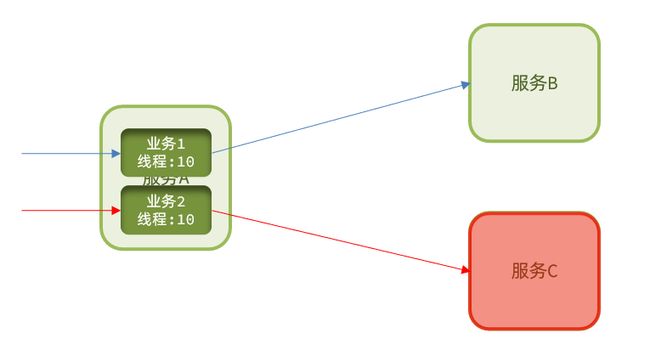
熔断降级:是在调用方这边加入断路器,统计对服务提供者的调用,如果调用的失败比例过高,则熔断该业务,不允许访问该服务的提供者了。
不管是线程隔离还是熔断降级,都是对客户端(调用方)的保护。需要在调用方 发起远程调用时做线程隔离、或者服务熔断。
而微服务远程调用都是基于Feign来完成的,因此我们需要将Feign与Sentinel整合,在Feign里面实现线程隔离和服务熔断。
FeignClient整合Sentinel
SpringCloud中,微服务调用都是通过Feign来实现的,因此做客户端保护必须整合Feign和Sentinel。
修改配置,开启sentinel功能
feign:
sentinel:
enabled: true # 开启feign对sentinel的支持
编写失败降级逻辑
以前业务失败就是直接拒绝并抛出异常
业务失败后,不能直接报错,而应该返回用户一个友好提示或者默认结果,这个就是失败降级逻辑。
给FeignClient编写失败后的降级逻辑
①方式一:FallbackClass,无法对远程调用的异常做处理
②方式二:FallbackFactory,可以对远程调用的异常做处理,我们选择这种
这里演示方式二的失败降级处理。
步骤一:在feing-api项目中定义类,实现FallbackFactory:

@Slf4j
public class UserClientFallbackFactory implements FallbackFactory<UserClient> {
@Override
public UserClient create(Throwable throwable) {
return new UserClient() {
@Override
public User findById(Long id) {
log.error("查询用户异常", throwable);
return new User();
}
};
}
}
步骤二:在feing-api项目中的DefaultFeignConfiguration类中将UserClientFallbackFactory注册为一个Bean:
@Bean
public UserClientFallbackFactory userClientFallbackFactory(){
return new UserClientFallbackFactory();
}
步骤三:在feing-api项目中的UserClient接口中使用UserClientFallbackFactory:
import cn.itcast.feign.clients.fallback.UserClientFallbackFactory;
import cn.itcast.feign.pojo.User;
import org.springframework.cloud.openfeign.FeignClient;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
@FeignClient(value = "userservice", fallbackFactory = UserClientFallbackFactory.class)
public interface UserClient {
@GetMapping("/user/{id}")
User findById(@PathVariable("id") Long id);
}
重启order服务后,访问一次订单查询业务(比如http://localhost:8088/order/102),然后查看sentinel控制台,可以看到新的簇点链路:

总结
Sentinel支持的雪崩解决方案:
- 线程隔离(仓壁模式)
- 降级熔断
Feign整合Sentinel的步骤:
- 在application.yml中配置:feign.sentienl.enable=true
- 给FeignClient编写FallbackFactory并注册为Bean
- 将FallbackFactory配置到FeignClient
线程隔离

线程池隔离:给每个服务调用业务分配一个线程池,利用线程池本身实现隔离效果
信号量隔离:不创建线程池,而是计数器模式,记录业务使用的线程数量,达到信号量上限时,禁止新的请求。
两者的优缺点:

主动超时:对于线程池隔离来说,请求向下是各个独立的线程池,如果该线程耗时很久没返回就可以通过线程池来控制,把线程终止掉
异步调用:线程池隔离是不使用请求本身的线程,它会把请求放到自己的线程池里面去调用其他服务,对于每个服务都有独立的线程,所以就是异步调用。
高扇出意味着 【A服务器】会调用很多服务,如果使用线程隔离,意味着【A服务器】要给每个调用的服务器开辟一个线程池,进而导致资源大量消耗
sentinel的线程隔离
用法说明:
在添加限流规则时,可以选择两种阈值类型:

-
QPS:就是每秒的请求数,在快速入门中已经演示过
-
线程数:是该资源能使用用的tomcat线程数的最大值。也就是通过限制线程数量,实现线程隔离(舱壁模式)。
案例需求:给 order-service服务中的UserClient的查询用户接口设置流控规则,线程数不能超过 2。然后利用jemeter测试。
1)配置隔离规则
选择feign接口后面的流控按钮:

填写表单:

2)Jmeter测试
选择《阈值类型-线程数<2》:

一次发生10个请求,有较大概率并发线程数超过2,而超出的请求会走之前定义的失败降级逻辑。
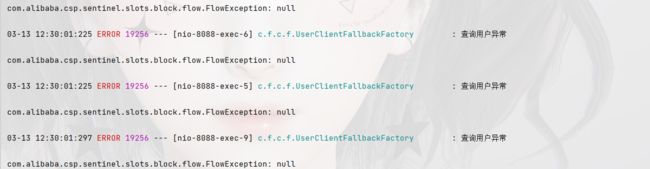
发现虽然结果都是通过了,不过部分请求得到的响应是降级返回的null信息。

总结
线程隔离的两种手段是?
-
信号量隔离
-
线程池隔离
信号量隔离的特点是?
- 基于计数器模式,简单,开销小
线程池隔离的特点是?
- 基于线程池模式,有额外开销,但隔离控制更强
熔断降级
熔断降级是解决雪崩问题的重要手段。其思路是由断路器统计服务调用的异常比例、慢请求比例,如果超出阈值则会熔断该服务。即拦截访问该服务的一切请求;而当服务恢复时,断路器会放行访问该服务的请求。
断路器控制熔断和放行是通过状态机来完成的:

状态机包括三个状态:
- closed:关闭状态,断路器放行所有请求,并开始统计异常比例、慢请求比例。超过阈值则切换到open状态
- open:打开状态,服务调用被熔断,访问被熔断服务的请求会被拒绝,快速失败,直接走降级逻辑。Open状态5秒后会进入half-open状态
- half-open:半开状态,放行一次请求,根据执行结果来判断接下来的操作。
- 请求成功:则切换到closed状态
- 请求失败:则切换到open状态
断路器熔断策略有三种:慢调用、异常比例、异常数
慢调用
慢调用:业务的响应时长(RT)大于指定时长的请求认定为慢调用请求。在指定时间内,如果请求数量超过设定的最小数量,慢调用比例大于设定的阈值,则触发熔断。
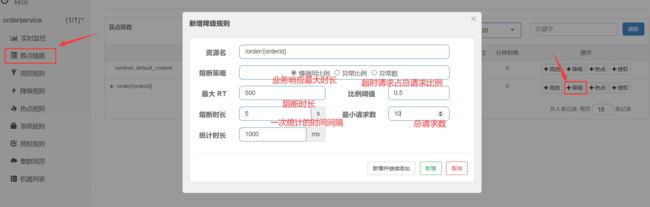
解读:RT超过500ms的调用是慢调用,统计最近10000ms内的请求,如果请求量超过10次,并且慢调用比例不低于0.5,则触发熔断,熔断时长为5秒。然后进入half-open状态,放行一次请求做测试。
案例
需求:给 UserClient的查询用户接口设置降级规则,慢调用的RT阈值为50ms,统计时间为1秒,最小请求数量为5,失败阈值比例为0.4,熔断时长为5
1)设置慢调用
修改user-service中的/user/{id}这个接口的业务。通过休眠模拟一个延迟时间:

此时,orderId=101的订单,关联的是id为1的用户,调用时长超过60ms:

2)设置熔断规则
下面,给feign接口设置降级规则:


超过50ms的请求都会被认为是慢请求
3)测试
在浏览器访问:http://localhost:8088/order/101,快速刷新5次,可以发现:

触发了熔断,请求时长缩短至5ms,快速失败了,并且走降级逻辑,返回的null
异常比例 异常数
异常比例或异常数:统计指定时间内的调用,如果调用次数超过指定请求数,并且出现异常的比例达到设定的比例阈值(或超过指定异常数),则触发熔断。
例如,一个异常比例设置:
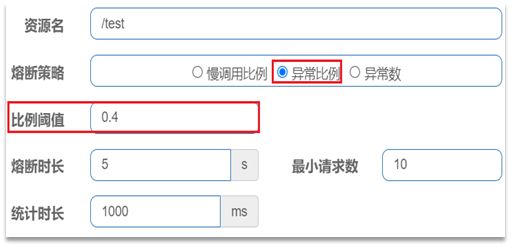
解读:统计最近1000ms内的请求,如果请求量超过10次,并且异常比例不低于0.4,则触发熔断。
例如,一个异常数设置:
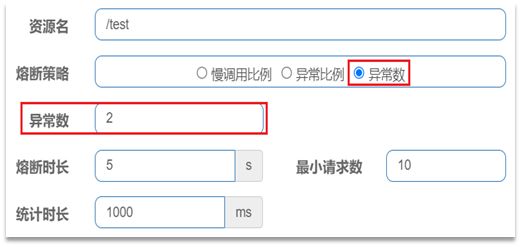
解读:统计最近1000ms内的请求,如果请求量超过10次,并且异常比例不低于2次,则触发熔断。
案例
需求:给 UserClient的查询用户接口设置降级规则,统计时间为1秒,最小请求数量为5,失败阈值比例为0.4,熔断时长为5s
1)设置异常请求
首先,修改user-service中的/user/{id}这个接口的业务。手动抛出异常,以触发异常比例的熔断:

也就是说,id 为 2时,就会触发异常
3)测试
在浏览器快速访问:http://localhost:8088/order/102,快速刷新5次,触发熔断:

服务熔断后,此时,我们再去访问本来应该正常的103:

由结果可以看出服务确实熔断不可调用了
授权规则
授权规则可以对请求方来源做判断和控制。
授权基本规则
授权规则可以对调用方的来源做控制,来保护微服务,有白名单和黑名单两种方式。
白名单:来源(origin)在白名单内的调用者允许访问
黑名单:来源(origin)在黑名单内的调用者不允许访问
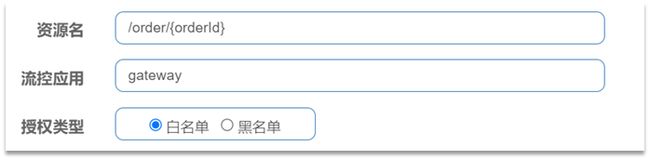
点击左侧菜单的授权,可以看到授权规则:

-
资源名:就是受保护的资源,例如/order/{orderId}
-
流控应用:是来源者的名单,
- 如果是勾选白名单,则名单中的来源被许可访问。
- 如果是勾选黑名单,则名单中的来源被禁止访问。

比如:

我们允许请求从gateway到order-service,不允许浏览器访问order-service,那么白名单中就要填写网关的来源名称(origin)。
如何获取origin
Sentinel是通过RequestOriginParser这个接口的parseOrigin来获取请求的来源的。
public interface RequestOriginParser {
/**
* 从请求request对象中获取origin,获取方式自定义
*/
String parseOrigin(HttpServletRequest request);
}
这个方法的作用就是从request对象中,获取请求者的origin值并返回。
默认情况下,sentinel不管请求者从哪里来,返回值永远是default,也就是说一切请求的来源都被认为是一样的值default。
因此,我们需要自定义这个接口的实现类,让不同的请求,返回不同的origin。
例如order-service服务中,我们定义一个RequestOriginParser的实现类:
@Component
public class HeaderOriginParser implements RequestOriginParser {
@Override
public String parseOrigin(HttpServletRequest httpServletRequest) {
//获取请求头
String orgin = httpServletRequest.getHeader("orgin");
//非空判断
if(StringUtils.isEmpty(orgin)){
orgin = "blank";
}
return orgin;
}
}
我们尝试从request-header中获取origin值。
给网关添加请求头
既然获取请求origin的方式是从reques-header中获取origin值,我们必须让所有从gateway路由到微服务的请求都带上origin头。
这个需要利用之前学习的一个GatewayFilter来实现,AddRequestHeaderGatewayFilter。
修改gateway服务中的application.yml,添加一个defaultFilter:
spring:
cloud:
gateway:
default-filters:
- AddRequestHeader=origin,gateway
这样,从gateway路由的所有请求都会带上origin头,值为gateway。而从其它地方到达微服务的请求则没有这个头。
配置授权规则
接下来,我们添加一个授权规则,放行origin值为gateway的请求。

配置如下:
现在,我们直接跳过网关,访问order-service服务:
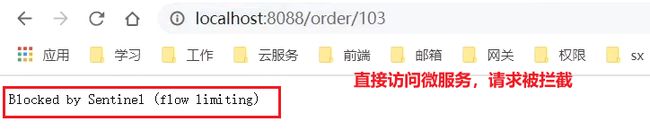
通过网关访问:
自定义异常结果
默认情况下,发生限流、降级、授权拦截时,都会抛出异常到调用方。异常结果都是flow limmiting(限流)。这样不够友好,无法得知是限流还是降级还是授权拦截。
自定义异常类型
而如果要自定义异常时的返回结果,需要实现BlockExceptionHandler接口:
public interface BlockExceptionHandler {
/**
* 处理请求被限流、降级、授权拦截时抛出的异常:BlockException
*/
void handle(HttpServletRequest request, HttpServletResponse response, BlockException e) throws Exception;
}
这个方法有三个参数:
- HttpServletRequest request:request对象
- HttpServletResponse response:response对象
- BlockException e:被sentinel拦截时抛出的异常
BlockException包含多个不同的子类:

自定义异常处理
在order-service定义一个自定义异常处理类:
@Component
public class SentinelExceptionHandler implements BlockExceptionHandler {
@Override
public void handle(HttpServletRequest httpServletRequest, HttpServletResponse httpServletResponse, BlockException e) throws Exception {
String msg = "未知异常";
int status = 429;
if (e instanceof FlowException){
msg = "请求被限流了";
} else if (e instanceof ParamFlowException) {
msg = "请求被热点参数限流";
} else if (e instanceof DegradeException) {
msg = "请求被降级了";
} else if (e instanceof AuthorityException) {
msg = "没有权限访问";
status = 401;
}
httpServletResponse.setContentType("application/json;charset=utf-8");
httpServletResponse.setStatus(status);
httpServletResponse.getWriter().println("{\"msg\":" + msg + ",\"status\":" + status + "}");
}
}
重启测试,在不同场景下,会返回不同的异常消息.
限流:

授权拦截时:

规则持久化
现在,sentinel的所有规则都是内存存储,重启后所有规则都会丢失。在生产环境下,我们必须确保这些规则的持久化,避免丢失。
规则管理模式
规则是否能持久化,取决于规则管理模式,sentinel支持三种规则管理模式:
- 原始模式:Sentinel的默认模式,将规则保存在内存,重启服务会丢失。
- pull模式:保存在本地文件或数据库,定时去读取
- push模式:保存在nacos,监听变更实时更新
pull模式

弊端:不能实时更新,时效性差,会导致数据不一致的问题
push模式

微服务都会监听nacos,一旦发现nacos的配置中心发生变化,本地的规则就会跟着变化,保证规则同步。是比较推荐的一种数据更新和持久化方式
分布式事务
分布式事务问题
本地事务
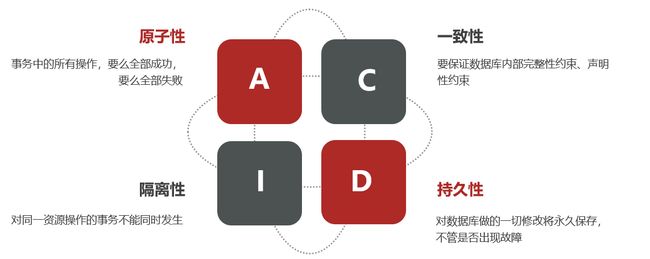
本地事务,也就是传统的单机事务。在传统数据库事务中,必须要满足四个原则:ACID
正如下图所示
对于一个单体架构的项目来说,实现事务是很简单的
分布式事务
分布式事务,就是指不是在单个服务或单个数据库架构下,产生的事务,例如:
- 跨数据源的分布式事务
- 跨服务的分布式事务
- 综合情况
以购物订单模块业务为例
在数据库水平拆分、服务垂直拆分之后,一个业务操作通常要跨多个数据库、服务才能完成。例如电商行业中比较常见的下单付款案例,包括下面几个行为:
- 创建新订单
- 扣减商品库存
- 从用户账户余额扣除金额
完成上面的操作需要访问三个不同的微服务和三个不同的数据库。
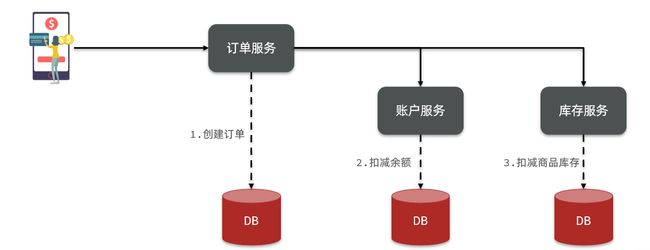
订单的创建、库存的扣减、账户扣款在每一个服务和数据库内是一个本地事务,可以保证ACID原则。
但是当我们把三件事情看做一个"业务",要满足保证“业务”的原子性,要么所有操作全部成功,要么全部失败,不允许出现部分成功部分失败的现象,这就是分布式系统下的事务了。
此时ACID难以满足,这是分布式事务要解决的问题
分布式事务问题示例
用一个基本的购物订单服务调用来演示分布式事务问题所在

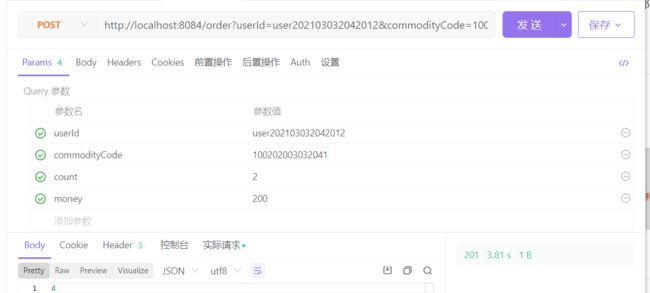
用apifox来模拟请求,当传入count超过库存最大值时,storage服务会失败,按道理说,应该整个业务都失败,但是到account的数据库查看,发现account的余额还是扣除了,没有做到同成功同失败,这也就是分布式下的微服务问题


那么在微服务架构这三个基本动作如何放入一个事务中,又如何保证同成功同失败的呢
理论基础
CAP定理
分布式系统有三个指标
- Consistency(一致性)
- Availability(可用性)
- Partition tolerance (分区容错性)

它们的第一个字母分别是 C、A、P。
这三个指标不可能同时做到,只能实现其中两个指标。这个结论就叫做 CAP 定理。
一致性
Consistency(一致性):用户访问分布式系统中的任意节点,得到的数据必须一致。
比如现在包含两个节点,其中的初始数据是一致的,当我们修改其中一个节点的数据时,两者的数据产生了差异:
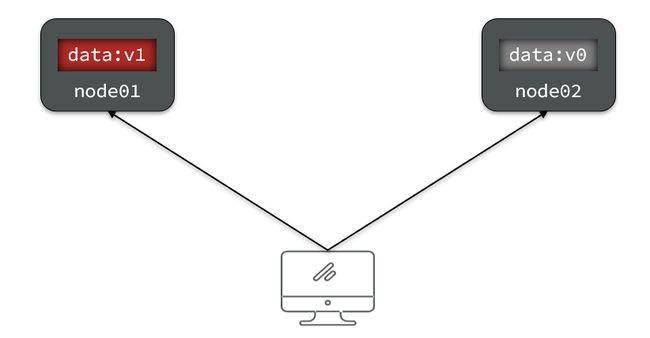
要想保住一致性,就必须实现node01 到 node02的数据 同步:

可用性
Availability (可用性):用户访问集群中的任意健康节点,必须能得到响应,而不是超时或拒绝。
如图,有三个节点的集群,访问任何一个都可以及时得到响应;当有部分节点因为网络故障或其它原因无法访问时,代表节点不可用:

分区容错
Partition(分区):因为网络故障或其它原因导致分布式系统中的部分节点与其它节点失去连接,形成独立分区。

Tolerance(容错):在集群出现分区时,整个系统也要持续对外提供服务
矛盾之处
在分布式系统中,系统间的网络不能100%保证健康,一定会有故障的时候,而服务有必须对外保证服务。因此Partition Tolerance不可避免。所以P是在所难免了,基于CAP定理,剩下一个指标就要从一致性和可用性中抉择了
当节点接收到新的数据变更时,就会出现问题了:

如果此时要保证一致性,就必须等待网络恢复,完成数据同步后,整个集群才对外提供服务,服务处于阻塞状态,不可用。
如果此时要保证可用性,就不能等待网络恢复,那node01、node02与node03之间就会出现数据不一致。
也就是说,在P一定会出现的情况下,A和C之间只能实现一个。
BASE理论
BASE理论是对CAP的一种解决思路,包含三个思想:
- Basically Available (基本可用):分布式系统在出现故障时,允许损失部分可用性,即保证核心可用。
- **Soft State(软状态):**在一定时间内,允许出现中间状态,比如临时的不一致状态。
- Eventually Consistent(最终一致性):虽然无法保证强一致性,但是在软状态结束后,最终达到数据一致。
BASE是上面三个思想首字母的缩写,它是对CAP理论中的A和P做了一些选择和调和
解决分布式事务的思路
分布式事务最大的问题是各个子事务的一致性问题,因此可以借鉴CAP定理和BASE理论,有两种解决思路:
-
AP模式:各子事务分别执行和提交,允许出现结果不一致,然后采用弥补措施恢复数据即可,实现最终一致。
-
CP模式:各个子事务执行后互相等待,同时提交,同时回滚,达成强一致。但事务等待过程中,处于弱可用状态。
但不管是哪一种模式,都需要在子系统事务之间互相通讯,协调事务状态,来感知彼此的状态,也就是需要一个事务协调者(TC):
如下图,服务要将自己的执行结果告诉协调者,如果哪个服务失败了,就会通知事务协调者,事务协调者就会通知所有事务做回滚。

这里的子系统事务,称为分支事务;有关联的各个分支事务在一起称为全局事务。
小结
简述BASE理论三个思想:
基本可用,软状态,最终一致
解决分布式事务的思想和模型:
全局事务:整个分布式事务
分支事务:分布式事务中包含的每个子系统的事务
最终一致思想:各分支事务分别执行并提交,如果有不一致的情况,再想办法恢复数据
强一致思想:各分支事务执行完业务不要提交,等待彼此结果。而后统一提交或回滚
初识Seata架构
Seata是 2019 年 1 月份蚂蚁金服和阿里巴巴共同开源的分布式事务解决方案。致力于提供高性能和简单易用的分布式事务服务,为用户打造一站式的分布式解决方案。
官网地址:http://seata.io/,其中的文档、博客中提供了大量的使用说明、源码分析。
Seata的架构
Seata事务管理中有三个重要的角色:
-
TC (Transaction Coordinator) -
事务协调者:维护全局和分支事务的状态,协调全局事务提交或回滚。 -
TM (Transaction Manager) -
事务管理器:定义全局事务的范围、开始全局事务、提交或回滚全局事务。 -
RM (Resource Manager) -
资源管理器:管理分支事务处理的资源,与TC交谈以注册分支事务和报告分支事务的状态,并驱动分支事务提交或回滚。

Seata基于上述架构提供了四种不同的分布式事务解决方案:
- XA模式:强一致性分阶段事务模式,牺牲了一定的可用性,无业务侵入
- TCC模式:最终一致的分阶段事务模式,
有业务侵入 - AT模式:最终一致的分阶段事务模式,
无业务侵入,也是Seata的默认模式 - SAGA模式:长事务模式,有业务侵入
无论哪种方案,都离不开TC,也就是事务的协调者。
部署Seata的tc-server
1.首先下载Seata
下载seata-server包,地址在http/seata.io/zh-cn/blog/download.html
当然,这里也放一个百度云的压缩包下载地址:seata-server包-1.4.2下载
提取码:wr5i
下载后解压即可
2.修改配置文件信息

修改后内容如下:
registry {
# tc服务的注册中心类,这里选择nacos,也可以是eureka、zookeeper等
type = "nacos"
nacos {
# seata tc 服务注册到 nacos的服务名称,可以自定义
application = "seata-tc-server"
serverAddr = "127.0.0.1:8848"
group = "DEFAULT_GROUP"
namespace = ""
cluster = "SH"
username = "nacos"
password = "nacos"
}
}
config {
# 读取tc服务端的配置文件的方式,这里是从nacos配置中心读取,这样如果tc是集群,可以共享配置
type = "nacos"
# 配置nacos地址等信息
nacos {
serverAddr = "127.0.0.1:8848"
namespace = ""
group = "SEATA_GROUP"
username = "nacos"
password = "nacos"
dataId = "seataServer.properties"
}
}
3.在nacos中添加配置
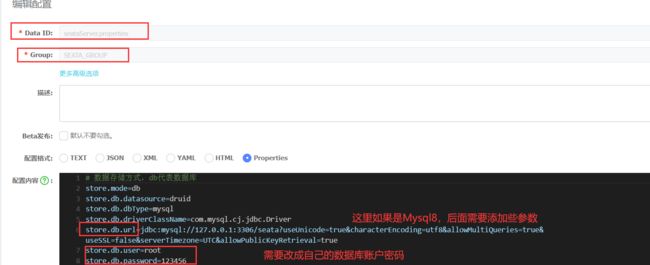
# 数据存储方式,db代表数据库
store.mode=db
store.db.datasource=druid
store.db.dbType=mysql
store.db.driverClassName=com.mysql.cj.jdbc.Driver
store.db.url=jdbc:mysql://127.0.0.1:3306/seata?useUnicode=true&characterEncoding=utf8&allowMultiQueries=true&useSSL=false&serverTimezone=UTC&allowPublicKeyRetrieval=true
store.db.user=root
store.db.password=123456
store.db.minConn=5
store.db.maxConn=30
store.db.globalTable=global_table
store.db.branchTable=branch_table
store.db.queryLimit=100
store.db.lockTable=lock_table
store.db.maxWait=5000
# 事务、日志等配置
server.recovery.committingRetryPeriod=1000
server.recovery.asynCommittingRetryPeriod=1000
server.recovery.rollbackingRetryPeriod=1000
server.recovery.timeoutRetryPeriod=1000
server.maxCommitRetryTimeout=-1
server.maxRollbackRetryTimeout=-1
server.rollbackRetryTimeoutUnlockEnable=false
server.undo.logSaveDays=7
server.undo.logDeletePeriod=86400000
# 客户端与服务端传输方式
transport.serialization=seata
transport.compressor=none
# 关闭metrics功能,提高性能
metrics.enabled=false
metrics.registryType=compact
metrics.exporterList=prometheus
metrics.exporterPrometheusPort=9898
4.创建数据库表
特别注意:tc服务在管理分布式事务时,需要记录事务相关数据到数据库中,需要提前创建好这些表。新建查询,复制粘贴下面内容后,直接运行
新建一个名为seata的数据库,这些表主要记录全局事务、分支事务、全局锁信息:
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;
-- ----------------------------
-- 分支事务表
-- ----------------------------
DROP TABLE IF EXISTS `branch_table`;
CREATE TABLE `branch_table` (
`branch_id` bigint(20) NOT NULL,
`xid` varchar(128) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`transaction_id` bigint(20) NULL DEFAULT NULL,
`resource_group_id` varchar(32) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`resource_id` varchar(256) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`branch_type` varchar(8) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`status` tinyint(4) NULL DEFAULT NULL,
`client_id` varchar(64) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`application_data` varchar(2000) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`gmt_create` datetime(6) NULL DEFAULT NULL,
`gmt_modified` datetime(6) NULL DEFAULT NULL,
PRIMARY KEY (`branch_id`) USING BTREE,
INDEX `idx_xid`(`xid`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Compact;
-- ----------------------------
-- 全局事务表
-- ----------------------------
DROP TABLE IF EXISTS `global_table`;
CREATE TABLE `global_table` (
`xid` varchar(128) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`transaction_id` bigint(20) NULL DEFAULT NULL,
`status` tinyint(4) NOT NULL,
`application_id` varchar(32) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`transaction_service_group` varchar(32) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`transaction_name` varchar(128) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`timeout` int(11) NULL DEFAULT NULL,
`begin_time` bigint(20) NULL DEFAULT NULL,
`application_data` varchar(2000) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`gmt_create` datetime NULL DEFAULT NULL,
`gmt_modified` datetime NULL DEFAULT NULL,
PRIMARY KEY (`xid`) USING BTREE,
INDEX `idx_gmt_modified_status`(`gmt_modified`, `status`) USING BTREE,
INDEX `idx_transaction_id`(`transaction_id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Compact;
SET FOREIGN_KEY_CHECKS = 1;
5.启动seata-server
如果nacos没有启动,先启动nacos,在nacos的bin目录中打开cmd

在命令行中输入以下代码
startup.cmd -m standalone
nacos就启动成功了
进入bin目录,运行其中的seata-server.bat即可:

启动成功后,seata-server应该已经注册到nacos注册中心了
打开浏览器,访问nacos地址:http://localhost:8848,然后进入服务列表页面,可以看到seata-tc-server的信息:

微服务集成Seata
1.引入Seata的依赖
seata-demo工程中的order, account, storage三个服务都需要引入Seata的依赖,由于它集成的版本较低,需要换为1.4.2的版本
查看原来依赖的版本是1.3

<!--seata-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-seata</artifactId>
<exclusions>
<!--版本较低,1.3.0,因此排除-->
<exclusion>
<artifactId>seata-spring-boot-starter</artifactId>
<groupId>io.seata</groupId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>io.seata</groupId>
<artifactId>seata-spring-boot-starter</artifactId>
<!--seata starter 采用1.4.2版本-->
<version>${seata.version}</version>
</dependency>
2.配置TC地址
需要在seata-dmeo工程中的各个微服务中的yml里配置TC的服务信息,主要就是告知它tc服务的四个信息如下
- namespace:命名空间
- group:分组
- application:服务名
- cluster:集群名
便于微服务去nacos中结合yml中配置的地址信息获取到tc服务
seata:
registry: # TC服务注册中心的配置,微服务根据这些信息去注册中心获取tc服务地址
type: nacos # 注册中心类型 nacos
nacos:
server-addr: 127.0.0.1:8848 # nacos地址
namespace: "" # namespace,默认为空
group: DEFAULT_GROUP # 分组,默认是DEFAULT_GROUP
application: seata-tc-server # seata服务名称
username: nacos
password: nacos
tx-service-group: seata-demo # 事务组名称
service:
vgroup-mapping: # 事务组与cluster的映射关系
seata-demo: SH
微服务如何根据这些配置寻找TC的地址呢?
注册到Nacos中的微服务,确定一个具体实例需要四个信息:namespace:命名空间,group:分组,application:服务名,cluster:集群名
以上四个信息,在yaml文件中都能找到:

namespace为空,就是默认的public
结合起来,TC服务的信息就是:public@DEFAULT_GROUP@seata-tc-server@SH
这样就能确定TC服务集群了,然后就可以去Nacos拉取对应的实例信息了。
代码实践
下面是Seata的四种不同的事务模式
XA模式
几乎所有主流的数据库都对 XA 规范 提供了支持。
XA的特性就是基于数据库本身的特性来去实现分布式事务,是一种强一致性的事务
XA是规范,目前主流数据库都实现了这种规范,实现的原理都是基于两阶段提交。
正常情况:

异常情况

一阶段:
- 事务协调者通知每个事物参与者执行本地事务
- 本地事务执行完成后报告事务执行状态给事务协调者,此时事务不提交,继续持有数据库锁
二阶段:
- 事务协调者基于一阶段的报告来判断下一步操作
- 如果一阶段都成功,则通知所有事务参与者,提交事务
- 如果一阶段任意一个参与者失败,则通知所有事务参与者回滚事务
Seata的XA模型
Seata对原始的XA模式做了简单的封装和改造,以适应自己的事务模型,基本架构如图:
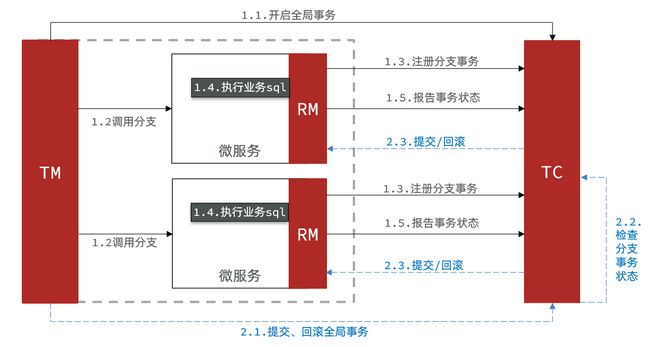
RM一阶段的工作:
① 注册分支事务到TC
② 执行分支业务sql但不提交
③ 报告执行状态到TC
TC二阶段的工作:
-
TC检测各分支事务执行状态
a.如果都成功,通知所有RM提交事务
b.如果有失败,通知所有RM回滚事务
RM二阶段的工作:
- 接收TC指令,提交或回滚事务
Seata和XA模式差不多,只不过多了全局事务的注册和管理,变得更加健壮
优缺点
XA模式的优点是什么?
- 事务的强一致性,满足ACID原则。
- 常用数据库都支持,实现简单,并且没有代码侵入
XA模式的缺点是什么?
- 因为一阶段需要锁定数据库资源,等待二阶段结束才释放,性能较差
- 依赖关系型数据库实现事务
实现XA模式
Seata的starter已经完成了XA模式的自动装配,实现非常简单,步骤如下:
1)修改application.yml文件(每个参与事务的微服务),开启XA模式:
seata:
data-source-proxy-mode: XA
2)给发起全局事务的入口方法添加@GlobalTransactional注解:
本例中是OrderServiceImpl中的create方法.

3)重启服务并测试
重启order-service,再次测试,发现无论怎样,三个微服务都能成功回滚。

AT模式
工作流程
阶段一RM的工作:
- 注册分支事务
- 记录undo-log(数据快照)
- 执行业务sql并提交
- 报告事务状态
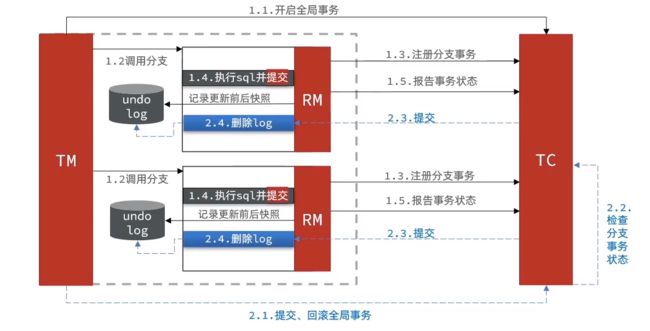
阶段二提交时RM的工作:
- 删除undo-log即可
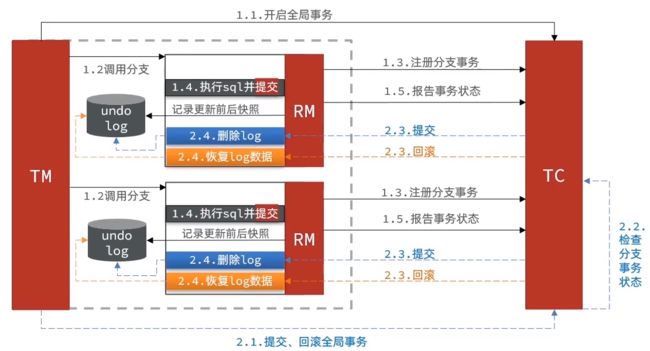
阶段二回滚时RM的工作:
- 根据undo-log恢复数据到更新前
第一阶段
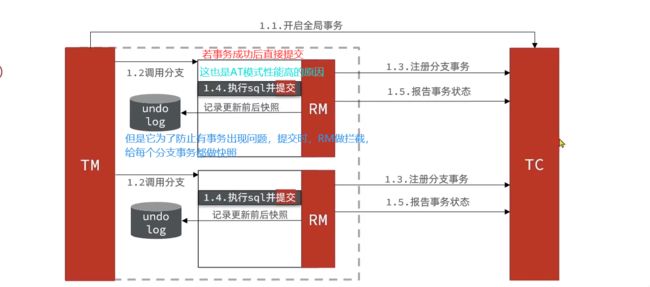
第二阶段
二阶段正常情况
所有事务都正常,删除分支事务的快照,这个删快照是通过异步调用的,所以不影响主线程的性能
二阶段异常情况
有事务执行失败,所有事务回到快照位置,然后异步删除快照
AT模式原理
例如,一个分支业务的SQL是这样的:update tb_account set money = money - 10 where id = 1
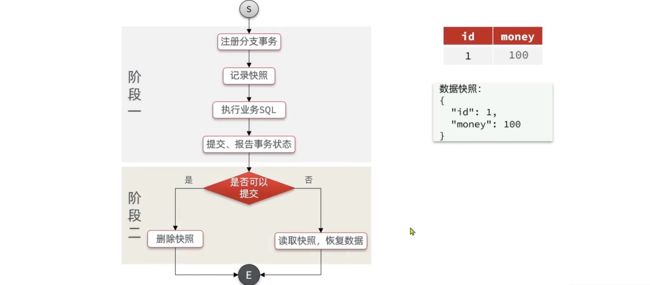
AT与XA的区别
- XA模式一阶段不提交事务,锁定资源;AT模式一阶段直接提交,不锁定资源。
- XA模式依赖数据库机制实现回滚;AT模式利用数据快照实现数据回滚。
- XA模式强一致;AT模式最终一致
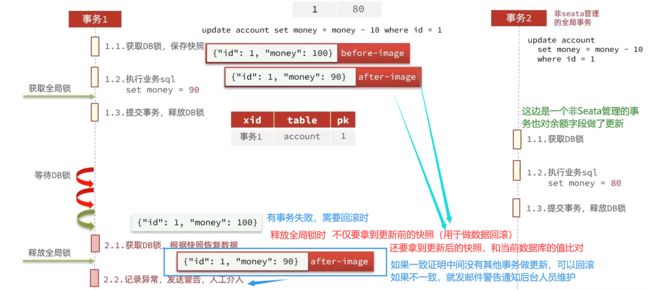
AT模式的脏读问题
由于AT模式是执行成功后直接提交事务,释放资源,没有去做锁,导致它在并发情况下,会出现脏读问题。

解决方案
解决思路就是引入了全局锁的概念。在释放DB锁之前,先拿到全局锁。避免同一时刻有另外一个事务来操作当前数据。用全局锁实现了隔离机制。

这里就会看出来,AT模式和XA模式一样,都是锁定事务,执行完后才允许其他事务执行,但实际上并非如此
数据库(DB)锁的话,任何其他事务都进不来;但是全局锁,只锁定操作账户余额的相关事务(seata管理),其他事物(非seata管理的事务)仍可以进来,例如修改账户名称等
全局锁比数据库锁所控制的范围小的多,所以AT模式对性能的影响也远低于XA模式。
最后补充一个小概率事件:
当事务2也是非seata管理的事务,但是事务2也是对账户余额字段做修改更新操作时,虽然概率很低,但仍要防止
防范措施为添加自旋锁
优缺点
AT模式的优点:
- 一阶段完成直接提交事务,释放数据库资源,性能比较好
- 利用全局锁实现读写隔离
- 没有代码侵入,框架自动完成回滚和提交
AT模式的缺点:
- 两阶段之间属于软状态,属于最终一致
- 框架的快照功能会影响性能,但比XA模式要好很多
实现AT模式
AT模式中的快照生成、回滚等动作都是由框架自动完成,没有任何代码侵入,因此实现非常简单。
只不过,AT模式需要一个表来记录全局锁、另一张表来记录数据快照undo_log。
注意:数据库连接池如果使用的是druid要使用druid-starter,不要使用druid。否则不生成undolog 无法回滚
1)导入数据库表,记录全局锁和快照表;其中lock_table导入到TC服务关联的数据库,undo_log表导入到微服务关联的数据库

lock_table全局锁的表
DROP TABLE IF EXISTS `lock_table`;
CREATE TABLE `lock_table` (
`row_key` varchar(128) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`xid` varchar(96) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`transaction_id` bigint(20) NULL DEFAULT NULL,
`branch_id` bigint(20) NOT NULL,
`resource_id` varchar(256) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`table_name` varchar(32) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`pk` varchar(36) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`gmt_create` datetime NULL DEFAULT NULL,
`gmt_modified` datetime NULL DEFAULT NULL,
PRIMARY KEY (`row_key`) USING BTREE,
INDEX `idx_branch_id`(`branch_id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Compact;
快照表
DROP TABLE IF EXISTS `undo_log`;
CREATE TABLE `undo_log` (
`branch_id` bigint(20) NOT NULL COMMENT 'branch transaction id',
`xid` varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT 'global transaction id',
`context` varchar(128) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT 'undo_log context,such as serialization',
`rollback_info` longblob NOT NULL COMMENT 'rollback info',
`log_status` int(11) NOT NULL COMMENT '0:normal status,1:defense status',
`log_created` datetime(6) NOT NULL COMMENT 'create datetime',
`log_modified` datetime(6) NOT NULL COMMENT 'modify datetime',
UNIQUE INDEX `ux_undo_log`(`xid`, `branch_id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci COMMENT = 'AT transaction mode undo table' ROW_FORMAT = Compact;
2)修改application.yml文件,将事务模式修改为AT模式即可:
不写默认就是AT
seata:
data-source-proxy-mode: AT # 默认就是AT
把前面的XA换成AT即可
3)重启服务并测试
TCC模式
TCC模式与AT模式非常相似,每阶段都是独立事务,不同的是TCC通过人工编码来实现数据恢复。需要实现三个方法:
-
Try:资源的检测和预留;
-
Confirm:完成资源操作业务;要求 Try 成功 Confirm 一定要能成功。
-
Cancel:预留资源释放,可以理解为try的反向操作。
流程分析
举例,一个扣减用户余额的业务。假设账户A原来余额是100,需要余额扣减30元。
- 阶段一( Try ):检查余额是否充足,如果充足则冻结金额增加30元,可用余额扣除30
初始余额:

余额充足,可以冻结:

此时,总金额 = 冻结金额 + 可用金额,数量依然是100不变。事务直接提交无需等待其它事务。
- 阶段二(Confirm):假如要提交(Confirm),则冻结金额扣减30
确认可以提交,不过之前可用金额已经扣减过了,这里只要清除冻结金额就好了:

此时,总金额 = 冻结金额 + 可用金额 = 0 + 70 = 70元
- 阶段二(Canncel):如果要回滚(Cancel),则冻结金额扣减30,可用余额增加30
需要回滚,那么就要释放冻结金额,恢复可用金额:


Seata的TCC模型
Seata中的TCC模型依然延续之前的事务架构

优缺点
TCC模式的每个阶段是做什么的?
- Try:资源检查和预留
- Confirm:业务执行和提交
- Cancel:预留资源的释放
TCC的优点是什么?
- 一阶段完成直接提交事务,释放数据库资源,性能好
- 相比AT模型,无需生成快照,无需使用全局锁,性能最强
- 不依赖数据库事务,而是依赖补偿操作,可以用于非事务型数据库
TCC的缺点是什么?
- 有代码侵入,需要人为编写try、Confirm和Cancel接口,太麻烦
- 软状态,事务是最终一致
- 需要考虑Confirm和Cancel的失败情况,做好幂等处理
事务悬挂和空回滚
1)空回滚
当某分支事务的try阶段阻塞时,可能导致全局事务超时而触发二阶段的cancel操作。在未执行try操作时先执行了cancel操作,这时cancel不能做回滚,就是空回滚。

执行cancel操作时,应当判断try是否已经执行,如果尚未执行,则应该空回滚。
2)业务悬挂
对于已经空回滚的业务,之前被阻塞的try操作恢复,继续执行try去冻结资源,但第二阶段已经执行完了,永远不可能confirm或cancel ,事务一直处于中间状态,这就是业务悬挂。
执行try操作时,应当判断cancel是否已经执行过了,如果已经执行,应当阻止空回滚后的try操作,避免悬挂
实现TCC模式
业务分析

方法模板

SAGA模式
Saga 模式是 Seata 即将开源的长事务解决方案,将由蚂蚁金服主要贡献。
其理论基础是Hector & Kenneth 在1987年发表的论文Sagas。
Seata官网对于Saga的指南:https://seata.io/zh-cn/docs/user/saga.html
原理
在 Saga 模式下,分布式事务内有多个参与者,每一个参与者都是一个冲正补偿服务,需要用户根据业务场景实现其正向操作和逆向回滚操作。
分布式事务执行过程中,依次执行各参与者的正向操作,如果所有正向操作均执行成功,那么分布式事务提交。如果任何一个正向操作执行失败,那么分布式事务会去退回去执行前面各参与者的逆向回滚操作,回滚已提交的参与者,使分布式事务回到初始状态。

四种模式的对比

高可用
Seata的TC服务作为分布式事务核心,一定要保证集群的高可用性。
高可用架构模型
搭建TC服务集群实现高可用,启动多个TC服务,注册到nacos即可。
但集群并不能确保100%安全,万一集群所在机房故障怎么办?所以如果要求较高,一般都会做异地多机房容灾。
比如一个TC集群在上海,另一个TC集群在杭州:
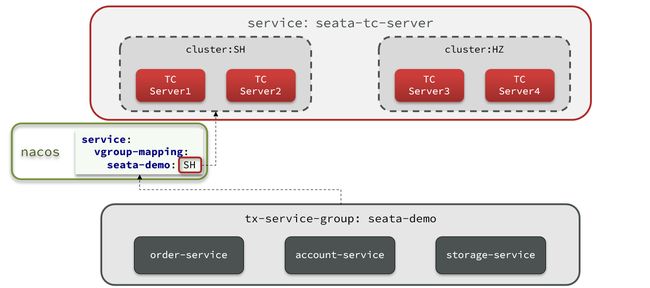
微服务基于事务组(tx-service-group)与TC集群的映射关系,来查找当前应该使用哪个TC集群。当SH集群故障时,只需要将vgroup-mapping中的映射关系改成HZ。则所有微服务就会切换到HZ的TC集群了。
实现高可用
模拟异地容灾的TC集群
计划启动两台seata的tc服务节点:
| 节点名称 | ip地址 | 端口号 | 集群名称 |
|---|---|---|---|
| seata | 127.0.0.1 | 8091 | SH |
| seata2 | 127.0.0.1 | 8092 | HZ |
之前我们已经启动了一台seata服务,端口是8091,集群名为SH。
现在,将seata目录复制一份,起名为seata2
修改seata2/conf/registry.conf内容如下:
registry {
# tc服务的注册中心类,这里选择nacos,也可以是eureka、zookeeper等
type = "nacos"
nacos {
# seata tc 服务注册到 nacos的服务名称,可以自定义
application = "seata-tc-server"
serverAddr = "127.0.0.1:8848"
group = "DEFAULT_GROUP"
namespace = ""
cluster = "HZ"
username = "nacos"
password = "nacos"
}
}
config {
# 读取tc服务端的配置文件的方式,这里是从nacos配置中心读取,这样如果tc是集群,可以共享配置
type = "nacos"
# 配置nacos地址等信息
nacos {
serverAddr = "127.0.0.1:8848"
namespace = ""
group = "SEATA_GROUP"
username = "nacos"
password = "nacos"
dataId = "seataServer.properties"
}
}
进入seata2/bin目录,然后运行命令:
seata-server.bat -p 8092
打开nacos控制台,查看服务列表:

点进详情查看:
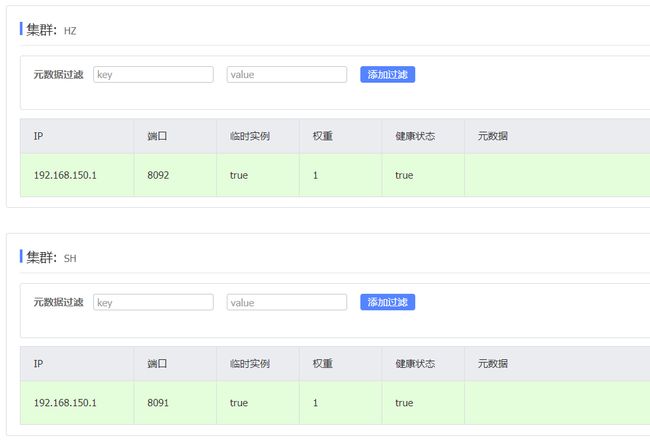
将事务组映射配置到nacos
接下来,我们需要将tx-service-group与cluster的映射关系都配置到nacos配置中心。
新建一个配置:

配置的内容如下:
# 事务组映射关系
service.vgroupMapping.seata-demo=SH
service.enableDegrade=false
service.disableGlobalTransaction=false
# 与TC服务的通信配置
transport.type=TCP
transport.server=NIO
transport.heartbeat=true
transport.enableClientBatchSendRequest=false
transport.threadFactory.bossThreadPrefix=NettyBoss
transport.threadFactory.workerThreadPrefix=NettyServerNIOWorker
transport.threadFactory.serverExecutorThreadPrefix=NettyServerBizHandler
transport.threadFactory.shareBossWorker=false
transport.threadFactory.clientSelectorThreadPrefix=NettyClientSelector
transport.threadFactory.clientSelectorThreadSize=1
transport.threadFactory.clientWorkerThreadPrefix=NettyClientWorkerThread
transport.threadFactory.bossThreadSize=1
transport.threadFactory.workerThreadSize=default
transport.shutdown.wait=3
# RM配置
client.rm.asyncCommitBufferLimit=10000
client.rm.lock.retryInterval=10
client.rm.lock.retryTimes=30
client.rm.lock.retryPolicyBranchRollbackOnConflict=true
client.rm.reportRetryCount=5
client.rm.tableMetaCheckEnable=false
client.rm.tableMetaCheckerInterval=60000
client.rm.sqlParserType=druid
client.rm.reportSuccessEnable=false
client.rm.sagaBranchRegisterEnable=false
# TM配置
client.tm.commitRetryCount=5
client.tm.rollbackRetryCount=5
client.tm.defaultGlobalTransactionTimeout=60000
client.tm.degradeCheck=false
client.tm.degradeCheckAllowTimes=10
client.tm.degradeCheckPeriod=2000
# undo日志配置
client.undo.dataValidation=true
client.undo.logSerialization=jackson
client.undo.onlyCareUpdateColumns=true
client.undo.logTable=undo_log
client.undo.compress.enable=true
client.undo.compress.type=zip
client.undo.compress.threshold=64k
client.log.exceptionRate=100
微服务读取nacos配置
接下来,需要修改每一个微服务的application.yml文件,让微服务读取nacos中的client.properties文件
seata:
config:
type: nacos
nacos:
server-addr: 127.0.0.1:8848
username: nacos
password: nacos
group: SEATA_GROUP
data-id: client.properties
重启微服务,现在微服务到底是连接tc的SH集群,还是tc的HZ集群,都统一由nacos的client.properties来决定了。
分布式缓存
单点缓存的弊端
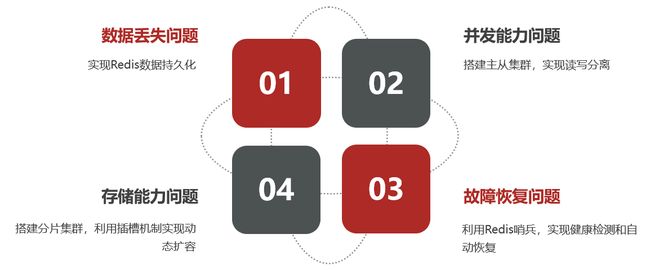
单机的Redis存在四大问题:
①数据丢失问题
Redis是内存存储,服务重启可能会丢失数据
②并发能力问题
单节点Redis并发能力虽然不错,但也无法满足如双十一和618这样的高并发场景
③故障恢复问题
如果Redis宕机,则服务不可用,需要一种自动的故障恢复手段
⑤存储能力问题
Redis基于内存,单节点能存储的数据量难以满足海量数据需求
Redis持久化
持久化是解决上面四大问题中的数据丢失问题,因为redis的数据是基于内存存储的,当服务重启会丢失数据,所以来做持久化策略来避免重启导致数据丢失问题
Redis有两种持久化方案:
- RDB持久化
- AOF持久化
RDB持久化
RDB全称Redis Database Backup file(Redis数据备份文件),也被叫做Redis数据快照。简单来说就是把内存中的所有数据都记录到磁盘中。当Redis实例故障重启后,从磁盘读取快照文件,恢复数据。快照文件称为RDB文件,默认是保存在当前运行目录。
执行时机
RDB持久化在四种情况下会执行:
- ①执行save命令
- ②执行bgsave命令
- ③Redis停机时
- ④触发RDB条件时
1)save命令
执行下面的命令,可以立即执行一次RDB:

save命令会导致主进程执行RDB,这个过程中其它所有命令都会被阻塞。只有在数据迁移时可能用到。
2)bgsave命令
下面的命令可以异步执行RDB:

这个命令执行后会开启独立进程完成RDB,主进程可以持续处理用户请求,不受影响。
3)停机时
Redis停机时会执行一次save命令,实现RDB持久化。
我们来启动redis来测试一下
先启动redis的服务端,前台霸屏模式启动
redis-server
再启动redis的客户端,命令如下
redis-cli
如果有密码先密码登录

如果忘记密码,就到redis安装目录中的 redis.conf查找密码

vim redis.conf

最后测试客户端登陆后,是否连通

最后ctrl + c停止redis服务,可以看到命令行的显示信息

4)触发RDB条件
Redis内部有触发RDB的机制,可以在redis.conf文件中找到,格式如下:
# 900秒内,如果至少有1个key被修改,则执行bgsave , 如果是save "" 则表示禁用RDB
save 900 1
save 300 10
save 60 10000
比如上面第二条的含义就是,在300秒内,如果有10次或者以上的修改就执行bgsave命令来做持久化
RDB的其它配置也可以在redis.conf文件中设置:
# 是否压缩 ,建议不开启,压缩也会消耗cpu,磁盘空间不值钱,所以推荐不压缩,以空间换性能
rdbcompression yes
# RDB文件名称
dbfilename dump.rdb
# 文件保存的路径目录
dir ./
bgsave适合多读少写的场景,如果你的业务场景是多写多读,或多写少读,那么建议使用save!
RDB原理
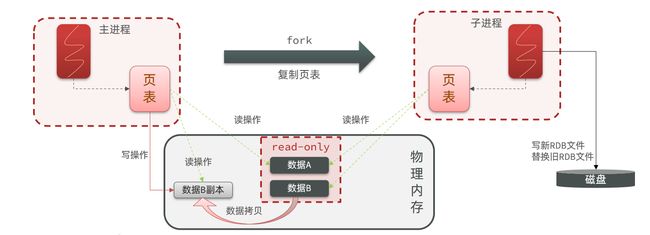
异步的调用做持久化,对主进程几乎零阻塞,只有在fork的过程中阻塞,得到子进程后就无阻塞了
bgsave开始时会fork主进程得到子进程,子进程共享主进程的内存数据。完成fork后读取内存数据并写入 RDB 文件。
fork采用的是copy-on-write技术:
- 当主进程执行读操作时,访问共享内存;
- 当主进程执行写操作时,则会拷贝一份数据,执行写操作。
小结
RDB方式bgsave的基本流程?
- fork主进程得到一个子进程,共享内存空间
- 子进程读取内存数据并写入新的RDB文件
- 用新RDB文件替换旧的RDB文件
RDB会在什么时候执行?save 60 1000代表什么含义?
- 默认是服务停止时
- 代表60秒内至少执行1000次修改则触发RDB
RDB的缺点?
- RDB执行间隔时间长,两次RDB之间写入数据有丢失的风险
- fork子进程、压缩、写出RDB文件都比较耗时
AOF持久化
AOF全称为Append Only File(追加文件)。Redis处理的每一个写命令都会记录在AOF文件,可以看做是命令日志文件。大大提高数据安全性弥补RDB的缺陷。

AOF配置

AOF默认是关闭的,需要修改redis.conf配置文件来开启AOF:
# 是否开启AOF功能,默认是no,这里改成yes开启
appendonly yes
# AOF文件的名称
appendfilename "appendonly.aof"
AOF的命令记录的频率也可以通过redis.conf文件来配:
# 表示每执行一次写命令,立即记录到AOF文件
appendfsync always
# 写命令执行完先放入AOF缓冲区,然后表示每隔1秒将缓冲区数据写到AOF文件,是默认方案
appendfsync everysec
# 写命令执行完先放入AOF缓冲区,由操作系统决定何时将缓冲区内容写回磁盘
appendfsync no
三种记录频率的策略对比:

默认的记录策略everysec,性能较好的原因
原因在于主线程只负责将命令先写入缓冲区中,(主进程依然是内存中读写,性能损耗极低),然后子进程每秒钟一股脑的将缓冲区中命令写入磁盘中
测试结果
AOF文件重写
因为是记录命令,AOF文件会比RDB文件大的多。而且AOF会记录对同一个key的多次写操作,但只有最后一次写操作才有意义。通过执行bgrewriteaof命令,可以让AOF文件执行重写功能,用最少的命令达到相同效果。
![]()

如图,AOF原本有三个命令,但是set num 123 和 set num 666都是对num的操作,第二次会覆盖第一次的值,因此第一个命令记录下来没有意义。
所以重写命令后,AOF文件内容就是:mset name jack num 666
Redis也会在触发阈值时自动去重写AOF文件。阈值也可以在redis.conf中配置:
# AOF文件比上次文件 增长超过多少百分比则触发重写
auto-aof-rewrite-percentage 100
# AOF文件体积最小多大以上才触发重写
auto-aof-rewrite-min-size 64mb
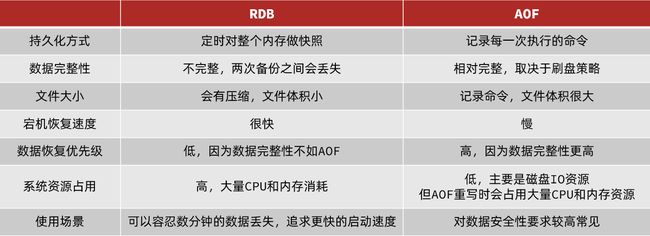
RDB与AOF对比
RDB和AOF各有自己的优缺点,如果对数据安全性要求较高,在实际开发中往往会结合两者来使用。
Redis主从
搭建主从架构
集群结构

从节点既可以叫slave也可以叫replica,在5.0以前是叫slave,后来改成replica
准备实例和配置
要在同一台虚拟机开启3个实例,必须准备三份不同的配置文件和目录,配置文件所在目录也就是工作目录。为准备三份不同的配置文件需再开一台虚拟机来配置,所以大抵需要4台虚拟机
需要在第四台虚拟机中做如下配置
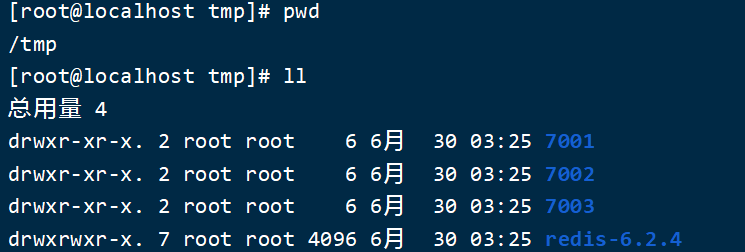
1)创建目录
我们创建三个文件夹,名字分别叫7001、7002、7003:
# 进入/tmp目录
cd /tmp
# 创建目录
mkdir 7001 7002 7003
如图:
2)恢复原始配置
如果修改过持久化策略,这里需要更改回RDB模式
修改redis-6.2.4/redis.conf文件,将其中的持久化模式改为默认的RDB模式,AOF保持关闭状态。
# 开启RDB
# save ""
save 3600 1
save 300 100
save 60 10000
# 关闭AOF
appendonly no
操作如下图

3)拷贝配置文件到每个实例目录
将第四台已经配置好的redis.conf配置文件拷贝到创建的目录中
然后将redis-6.2.4/redis.conf文件拷贝到三个目录中(在/tmp目录执行下列命令):
# 方式一:逐个拷贝
cp redis-6.2.4/redis.conf 7001
cp redis-6.2.4/redis.conf 7002
cp redis-6.2.4/redis.conf 7003
# 方式二:管道组合命令,一键拷贝
echo 7001 7002 7003 | xargs -t -n 1 cp redis-6.2.4/redis.conf
4)修改每个实例的端口、工作目录
修改每个文件夹内的配置文件,将redis端口分别修改为7001、7002、7003,将rdb文件保存位置都修改为自己所在目录(在/tmp目录执行下列命令):
sed -i -e 's/6379/7001/g' -e 's/dir .\//dir \/tmp\/7001\//g' 7001/redis.conf
sed -i -e 's/6379/7002/g' -e 's/dir .\//dir \/tmp\/7002\//g' 7002/redis.conf
sed -i -e 's/6379/7003/g' -e 's/dir .\//dir \/tmp\/7003\//g' 7003/redis.conf
5)修改每个实例的声明IP
虚拟机本身有多个IP,为了避免将来混乱,我们需要在redis.conf文件中指定每一个实例的绑定ip信息,格式如下:
每个目录都要改,我们一键完成修改(在/tmp目录执行下列命令):
# 逐一执行
sed -i '1a replica-announce-ip 这里换成你虚拟机的IP,下面也是一样' 7001/redis.conf
sed -i '1a replica-announce-ip 虚拟机的IP' 7002/redis.conf
sed -i '1a replica-announce-ip 虚拟机的IP' 7003/redis.conf
如下图

启动
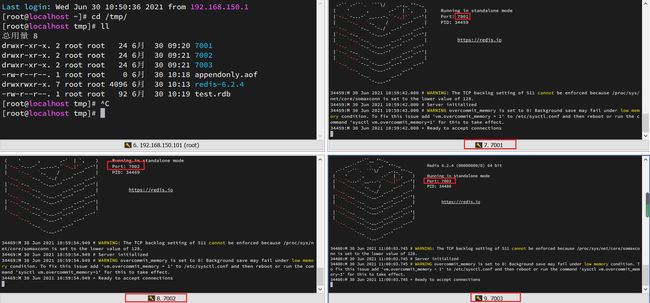
为了方便查看日志,我们打开3个ssh窗口,分别启动3个redis实例,启动命令:
# 第1个
redis-server 7001/redis.conf
# 第2个
redis-server 7002/redis.conf
# 第3个
redis-server 7003/redis.conf

启动后:
如果要一键停止,可以运行下面命令:
printf '%s\n' 7001 7002 7003 | xargs -I{} -t redis-cli -p {} shutdown
开启主从关系
现在三个实例还没有任何关系,要配置主从可以使用replicaof 或者slaveof(5.0以前)命令。
有临时和永久两种模式:
-
修改配置文件(永久生效)
- 在redis.conf中添加一行配置:
slaveof
- 在redis.conf中添加一行配置:
-
使用redis-cli客户端连接到redis服务,执行slaveof命令(重启后失效):
slaveof <主节点ip> <主节点端口>
代码如下
通过redis-cli命令连接7002,执行下面命令:
# 连接 7002
redis-cli -p 7002
# 执行slaveof
slaveof 192.168.150.101 7001
通过redis-cli命令连接7003,执行下面命令:
# 连接 7003
redis-cli -p 7003
# 执行slaveof
slaveof 192.168.150.101 7001
注:连接拒绝可能是因为你三个配置文件里设置了requirepass那个属性(密码),可以直接注释掉那个属性
master设置密码的情况下同步数据,其实很简单,我们只要让slave能连上master就可以了,我们在slave的配置文件中加一句话即可。
master 服务器设置了密码,所以slave 还需要加上
masterauth 123456 (验证master的密码,此密码为master的密码
requirepass 123456 (给slave设置密码,可设置可不设置,自己选择)
重启redis服务器(先杀死进程,在加载配置文件启动)
# 连接 7001
redis-cli -p 7001
# 查看状态
info replication
结果:

测试

可以发现,只有在7001这个master节点上可以执行写操作,7002和7003这两个slave节点只能执行读操作。
主从数据同步原理
全量同步
主从第一次建立连接时,会执行全量同步,将master节点的所有数据都拷贝给slave节点,流程:

但是全量同步对性能的影响是极大的
这里有一个问题,master如何得知salve是第一次来连接呢?
有几个概念,可以作为判断依据:
- Replication Id:简称replid,是数据集的标记,id一致则说明是同一数据集。
每一个master都有唯一的replid,slave则会继承master节点的replid - offset:偏移量,随着记录在repl_baklog中的数据增多而逐渐增大。slave完成同步时也会记录当前同步的offset。如果slave的offset小于master的offset,说明slave数据落后于master,需要更新。
思路分析如下
因此slave做数据同步,必须向master声明自己的replication id 和offset,master才可以判断到底需要同步哪些数据。
因为slave原本也是一个master,有自己的replid和offset,当第一次变成slave,与master建立连接时,发送的replid和offset是自己的replid和offset。
master判断发现slave发送来的replid与自己的不一致,说明这是一个全新的slave,就知道要做全量同步了。
master会将自己的replid和offset都发送给这个slave,slave保存这些信息。以后slave的replid就与master一致了。
因此,master判断一个节点是否是第一次同步的依据,就是看replid是否一致。

完整流程描述:
- slave节点请求增量同步
- master节点判断replid,发现不一致,拒绝增量同步
- master将完整内存数据生成RDB,发送RDB到slave
- slave清空本地数据,加载master的RDB
- master将RDB期间的命令记录在repl_baklog,并持续将log中的命令发送给slave
- slave执行接收到的命令,保持与master之间的同步
增量同步
主从第一次同步是全量同步,但如果slave重启后同步,则执行增量同步
全量同步需要先做RDB,然后将RDB文件通过网络传输个slave,成本太高了。因此除了第一次做全量同步,其它大多数时候slave与master都是做增量同步。只更新slave与master存在差异的部分数据。

repl_backlog原理
repl_backlog有点类似于循环队列的结构
全量同步时的repl_baklog文件是一个固定大小的数组,只不过数组是环形,也就是说角标到达数组末尾后,会再次从0开始读写,这样数组头部的数据就会被覆盖。
repl_baklog中会记录Redis处理过的命令日志及offset,包括master当前的offset,和slave已经拷贝到的offset:
slave与master的offset之间的差异,就是salve需要增量拷贝的数据了。
随着不断有数据写入,master的offset逐渐变大,slave也不断的拷贝,追赶master的offset:
直到数组被填满:
此时,如果有新的数据写入,就会覆盖数组中的旧数据。不过,旧的数据只要是绿色的,说明是已经被同步到slave的数据,即便被覆盖了也没什么影响。因为未同步的仅仅是红色部分。
repl_baklog同步会出现的问题
但是,如果slave出现网络阻塞,导致master的offset远远超过了slave的offset:
如果master继续写入新数据,其offset就会覆盖旧的数据,直到将slave现在的offset也覆盖:

棕色框中的红色部分,就是尚未同步,但是却已经被覆盖的数据。此时如果slave恢复,需要同步,却发现自己的offset都没有了,无法完成增量同步了。只能做全量同步。

主从同步优化
可以从以下几个方面来优化Redis主从就集群:
- 在master中配置repl-diskless-sync yes启用无磁盘复制,避免全量同步时的磁盘IO。(只适合在带宽特别高的情况才适合)
- Redis单节点上的内存占用不要太大(留余内存来生成RDB文件),减少RDB导致的过多磁盘IO
- 适当提高repl_baklog的大小,发现slave宕机时尽快实现故障恢复,尽可能避免全量同步
- 限制一个master上的slave节点数量,如果实在是太多slave,则可以采用主-从-从链式结构,减少master压力
主从从架构图:
简言之就是发展下线,减轻总部压力,不然所有从节点都找主节点同步数据,主节点压力巨大
总结
简述全量同步和增量同步区别?
- 全量同步:master将完整内存数据生成RDB,发送RDB到slave。后续命令则记录在repl_baklog,逐个发送给slave。
- 增量同步:slave提交自己的offset到master,master获取repl_baklog中从offset之后的命令给slave
什么时候执行全量同步?
- slave节点第一次连接master节点时
- slave节点断开时间太久,repl_baklog中的offset已经被覆盖时
什么时候执行增量同步?
- slave节点断开又恢复,并且在repl_baklog中能找到offset时
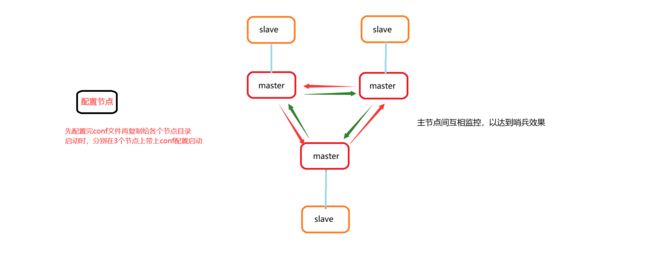
Redis哨兵
slave节点宕机恢复后可以找master节点同步数据,那master节点宕机怎么办?
如果master做了持久化,即使它宕机了,重启仍然是主节点,但是在它宕机恢复阶段,整个服务是无法访问的,导致可用性降低
因为slave一直在和master做数据同步,所以当主节点发生故障时,立即选出slave来当master,保证服务的可用
当master恢复后,直接做slave就好了
然而,这个集群的健康检测和重启是由谁来完成的呢?
就是由下面的哨兵机制来完成的
哨兵原理
集群结构和作用
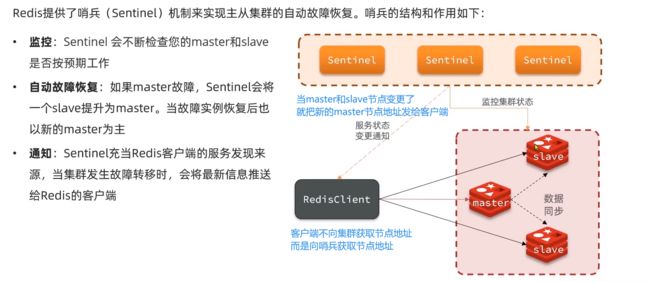
集群监控原理
Sentinel基于心跳机制监测服务状态,每隔1秒向集群的每个实例发送ping命令:
•主观下线:如果某sentinel节点发现某实例未在规定时间响应,则认为该实例主观下线。
•客观下线:若超过指定数量(quorum)的sentinel都认为该实例主观下线,则该实例客观下线。quorum值最好超过Sentinel实例数量的一半。
就是有一半的sentinel检测到节点主观下线,就是客观下线,真的下线了,就要选主了

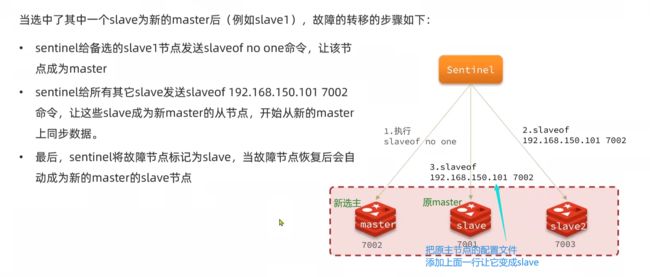
集群故障恢复原理
一旦发现master故障,sentinel需要在salve中选择一个作为新的master,选择依据是这样的:
- 首先会判断slave节点与master节点断开时间长短,如果超过指定值(down-after-milliseconds * 10)则会排除该slave节点
- 然后判断slave节点的slave-priority值,越小优先级越高,如果是0则永不参与选举(默认大家都一样)
- 如果slave-prority一样,则判断slave节点的offset值,越大说明数据越新,优先级越高
- 最后是判断slave节点的运行id大小,越小优先级越高。(
这个不重要,因为offset一样那它们的数据同步都差不多,选哪个都行,这里就按id大小来选了)
小结
Sentinel的三个作用是什么?
- 监控
- 故障转移
- 通知
Sentinel如何判断一个redis实例是否健康?
- 每隔1秒发送一次ping命令,如果超过一定时间没有相向则认为是主观下线
- 如果大多数sentinel都认为实例主观下线,则判定服务下线
故障转移步骤有哪些?
- 首先选定一个slave作为新的master,执行slaveof no one
- 然后让所有节点都执行slaveof 新master
- 修改故障节点配置,添加slaveof 新master
搭建哨兵集群
搭建一个三节点形成的Sentinel集群,来监管之前的Redis主从集群

三个sentinel实例信息如下:
| 节点 | IP | PORT |
|---|---|---|
| s1 | 192.168.150.101 | 27001 |
| s2 | 192.168.150.101 | 27002 |
| s3 | 192.168.150.101 | 27003 |
准备实例和配置
要在同一台虚拟机开启3个实例,必须准备三份不同的配置文件和目录,配置文件所在目录也就是工作目录。
我们创建三个文件夹,名字分别叫s1、s2、s3:
# 进入/tmp目录
cd /tmp
# 创建目录
mkdir s1 s2 s3

然后我们在s1目录创建一个sentinel.conf文件,添加下面的内容:
port 27001
sentinel announce-ip 192.168.150.101
sentinel monitor mymaster 192.168.150.101 7001 2
sentinel down-after-milliseconds mymaster 5000
sentinel failover-timeout mymaster 60000
dir "/tmp/s1"
命令解读:
port 27001:是当前sentinel实例的端口sentinel monitor mymaster 192.168.150.101 7001 2:指定主节点信息mymaster:主节点名称,自定义,任意写192.168.150.101 7001:主节点的ip和端口2:选举master时的quorum值
然后将s1/sentinel.conf文件拷贝到s2、s3两个目录中(在/tmp目录执行下列命令):
# 方式一:逐个拷贝
cp s1/sentinel.conf s2
cp s1/sentinel.conf s3
# 方式二:管道组合命令,一键拷贝
echo s2 s3 | xargs -t -n 1 cp s1/sentinel.conf
如果是s2或者s3,那么port就要修改(27002,27003),dir也要修改
修改s2、s3两个文件夹内的配置文件,将端口分别修改为27002、27003 ,dir工作目录改为对应的:
sed -i -e 's/27001/27002/g' -e 's/s1/s2/g' s2/sentinel.conf
sed -i -e 's/27001/27003/g' -e 's/s1/s3/g' s3/sentinel.conf
启动
为了方便查看日志,我们打开3个ssh窗口,分别启动3个redis实例,启动命令:
# 第1个
redis-sentinel s1/sentinel.conf
# 第2个
redis-sentinel s2/sentinel.conf
# 第3个
redis-sentinel s3/sentinel.conf
启动后:

最终测试结果
尝试让master节点7001宕机,查看sentinel日志:

查看新选主7003的日志:

查看从节点7002的日志:

RedisTemplate哨兵模式
在Sentinel集群监管下的Redis主从集群,其节点会因为自动故障转移而发生变化,Redis的客户端必须感知这种变化,及时更新连接信息。Spring的RedisTemplate底层利用lettuce实现了节点的感知和自动切换。
下面,我们通过一个测试来实现RedisTemplate集成哨兵机制。
导入Demo工程
导入redis-demo工程,其中就只有一个controller的get和set方法(这个不重要)只是用来测试服务是否正常运行,以及查看服务控制台中找哪个主节点信息的

引入依赖
在项目的pom文件中引入依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
配置Redis地址
然后在配置文件application.yml中指定redis的sentinel相关信息:
由于主从地址是有可能变更的,所以这里是配置redis的哨兵集群地址,让sentinel做地址的发现
spring:
redis:
sentinel:
master: mymaster #这个是指定master节点的名称
nodes: #指定redis-sentinel集群信息,就是前面配置哨兵集群的ip和端口
- 192.168.150.101:27001
- 192.168.150.101:27002
- 192.168.150.101:27003
配置读写分离
在项目的启动类中,添加一个新的bean:
@Bean
public LettuceClientConfigurationBuilderCustomizer clientConfigurationBuilderCustomizer(){
return clientConfigurationBuilder -> clientConfigurationBuilder.readFrom(ReadFrom.REPLICA_PREFERRED);
}
这个bean中配置的就是读写策略,包括四种:
- MASTER:从主节点读取
- MASTER_PREFERRED:优先从master节点读取,master不可用才读取replica
- REPLICA:从slave(replica)节点读取
- REPLICA _PREFERRED:优先从slave(replica)节点读取,所有的slave都不可用才读取master
Redis分片集群
主从和哨兵可以解决高可用、高并发读的问题。但是依然有两个问题没有解决:
-
海量数据存储问题
-
高并发写的问题
使用分片集群可以解决上述问题,如图:

搭建分片集群
集群结构
分片集群需要的节点数量较多,这里我们搭建一个最小的分片集群,包含3个master节点,每个master包含一个slave节点,结构如下:
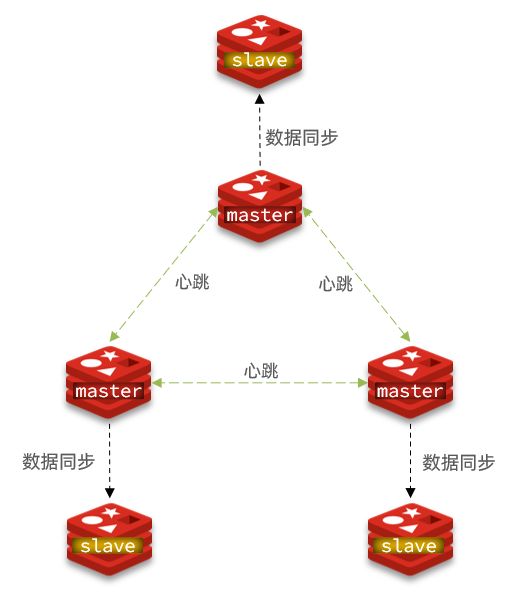
这里我们会在同一台虚拟机中开启6个redis实例,模拟分片集群,信息如下:
| IP | PORT | 角色 |
|---|---|---|
| 192.168.150.101 | 7001 | master |
| 192.168.150.101 | 7002 | master |
| 192.168.150.101 | 7003 | master |
| 192.168.150.101 | 8001 | slave |
| 192.168.150.101 | 8002 | slave |
| 192.168.150.101 | 8003 | slave |
准备实例和配置
删除之前搭建哨兵集群的7001、7002、7003这几个目录,重新创建出7001、7002、7003、8001、8002、8003目录:
# 进入/tmp目录
cd /tmp
# 删除旧的,避免配置干扰
rm -rf 7001 7002 7003
# 创建目录
mkdir 7001 7002 7003 8001 8002 8003
在/tmp下创建一个新的redis.conf文件,内容如下:
port 6379
# 开启集群功能
cluster-enabled yes
# 集群的配置文件名称,不需要我们创建,由redis自己维护
cluster-config-file /tmp/6379/nodes.conf
# 节点心跳失败的超时时间
cluster-node-timeout 5000
# 持久化文件存放目录
dir /tmp/6379
# 绑定地址
bind 0.0.0.0
# 让redis后台运行
daemonize yes
# 注册的实例ip
replica-announce-ip 192.168.150.101
# 保护模式
protected-mode no
# 数据库数量
databases 1
# 日志
logfile /tmp/6379/run.log
将这个文件拷贝到每个目录下:
# 进入/tmp目录
cd /tmp
# 执行拷贝
echo 7001 7002 7003 8001 8002 8003 | xargs -t -n 1 cp redis.conf
修改每个目录下的redis.conf,将其中的6379修改为与所在目录一致(就是把端口改为7001,7002等等):
# 进入/tmp目录
cd /tmp
# 修改配置文件
printf '%s\n' 7001 7002 7003 8001 8002 8003 | xargs -I{} -t sed -i 's/6379/{}/g' {}/redis.conf
启动
因为已经配置了后台启动模式,所以可以直接启动服务:
# 进入/tmp目录
cd /tmp
# 一键启动所有服务
printf '%s\n' 7001 7002 7003 8001 8002 8003 | xargs -I{} -t redis-server {}/redis.conf
通过ps查看状态:
ps -ef | grep redis
发现服务都已经正常启动:

如果要关闭所有进程,可以执行命令:
ps -ef | grep redis | awk '{print $2}' | xargs kill
或者(推荐这种方式):
printf '%s\n' 7001 7002 7003 8001 8002 8003 | xargs -I{} -t redis-cli -p {} shutdown
创建集群
虽然服务启动了,但是目前每个服务之间都是独立的,没有任何关联。
我们需要执行命令来创建集群,在Redis5.0之前创建集群比较麻烦,5.0之后集群管理命令都集成到了redis-cli中。
1)Redis5.0之前
Redis5.0之前集群命令都是用redis安装包下的src/redis-trib.rb来实现的。因为redis-trib.rb是有ruby语言编写的所以需要安装ruby环境。
# 安装依赖
yum -y install zlib ruby rubygems
gem install redis
然后通过命令来管理集群:
# 进入redis的src目录
cd /tmp/redis-6.2.4/src
# 创建集群
./redis-trib.rb create --replicas 1 192.168.150.101:7001 192.168.150.101:7002 192.168.150.101:7003 192.168.150.101:8001 192.168.150.101:8002 192.168.150.101:8003
2)Redis5.0以后
我们使用的是Redis6.2.4版本,集群管理以及集成到了redis-cli中,格式如下:
前3个是主,后三个是从
redis-cli --cluster create --cluster-replicas 1 192.168.150.101:7001 192.168.150.101:7002 192.168.150.101:7003 192.168.150.101:8001 192.168.150.101:8002 192.168.150.101:8003
命令说明:
redis-cli --cluster或者./redis-trib.rb:代表集群操作命令create:代表是创建集群--replicas 1或者--cluster-replicas 1:指定集群中每个master的副本个数为1,此时节点总数 ÷ (replicas + 1)得到的就是master的数量。因此节点列表中的前n个就是master,其它节点都是slave节点,随机分配到不同master
运行后的样子:

这里输入yes,则集群开始创建:

通过命令可以查看集群状态:
redis-cli -p 7001 cluster nodes

测试
尝试连接7001节点,存储一个数据:
# 连接
redis-cli -p 7001
# 存储数据
set num 123
# 读取数据
get num
# 再次存储
set a 1
结果就会报错
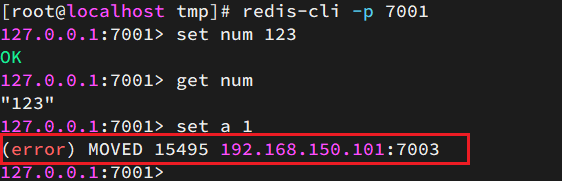
集群操作时,需要给redis-cli加上-c参数才可以:
redis-cli -c -p 7001

散列插槽
插槽原理
Redis会把每一个master节点映射到0~16383共16384个插槽(hash slot)上,查看集群信息时就能看到:
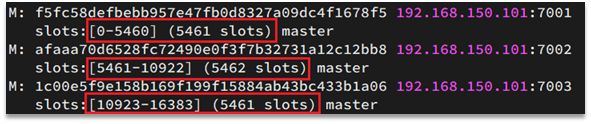
数据key不是与节点绑定,而是与插槽绑定。redis会根据key的有效部分计算插槽值,分两种情况:
- key中包含"{}",且“{}”中至少包含1个字符,“{}”中的部分是有效部分
- key中不包含“{}”,整个key都是有效部分
例如:key是num,那么就根据num计算,如果是{itcast}num,则根据itcast计算。计算方式是利用CRC16算法得到一个hash值,然后对16384取余,得到的结果就是slot值。

每个节点有一定的插槽范围,根据数据的插槽值(slot)来判断,该值应该放在哪个节点上,查找时也方便去哪个节点上找,这也是请求路由到正确节点的原因
数据与插槽绑定而不与节点绑定的原因是:节点可能会扩容或下线,但插槽一直是不变的,无论何时,都额可以根据插槽来找到对应的节点,访问该值,不受节点扩容或宕机的影响(节点宕机其插槽范围就交由其他节点,扩容类似)
小结
Redis如何判断某个key应该在哪个实例?
- 将16384个插槽分配到不同的实例
- 根据key的有效部分计算哈希值,对16384取余
- 余数作为插槽,寻找插槽所在实例即可
如何将同一类数据固定的保存在同一个Redis实例(比如手机商品信息放同一个节点,空调放一个节点)?
- 这一类数据使用相同的有效部分,例如key都以{typeId}为前缀
集群伸缩
redis-cli --cluster提供了很多操作集群的命令,可以通过下面方式查看:

需求分析
需求:向集群中添加一个新的master节点,并向其中存储 num = 10
- 启动一个新的redis实例,端口为7004
- 添加7004到之前的集群,并作为一个master节点
- 给7004节点分配插槽,使得num这个key可以存储到7004实例
难点在于插槽的分配,因为num是在7001的插槽范围中
这里需要两个新的功能:
- 添加一个节点到集群中
- 将部分插槽分配到新插槽
创建新的redis实例
创建一个文件夹:
mkdir 7004
拷贝配置文件:
cp redis.conf /7004
修改配置文件:
sed -i /s/6379/7004/g 7004/redis.conf


但现在还没有成为集群中的节点,只是把7004启动起来了
添加新节点到redis
添加节点的语法如下:
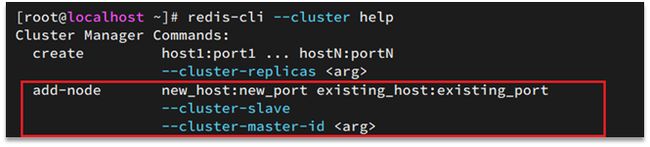
执行命令:
第一个是要新添加的ip和端口,第二个是指定一个集群中存在的ip和端口(这里不是配置它出生即奴,配置成奴的参数不一样)
redis-cli --cluster add-node 192.168.150.101:7004 192.168.150.101:7001
通过命令查看集群状态:
redis-cli -p 7001 cluster nodes
如图,7004加入了集群,并且默认是一个master节点:

但是,可以看到7004节点的插槽数量为0,因此没有任何数据可以存储到7004上
转移插槽
我们要将num存储到7004节点,因此需要先看看num的插槽是多少:

如上图所示,num的插槽为2765.如此我们移动0~3000的插槽即可
我们可以将0~3000的插槽从7001转移到7004,命令格式如下:

具体命令如下:
![]()
接下里就会让你输入转移插槽的相关配置

通过命令查看集群状态:
redis-cli -p 7001 cluster nodes
从而找到7004和7001的节点对应的id

移动完毕后再通过以下命令查看结果
![]()
可以看到:

目的达成。
注:如果要删除7004节点 需要先移除7004节点上的插槽 然后才可以移除7004节点
故障转移
集群初始状态是这样的:

其中7001、7002、7003都是master,我们计划让7002宕机。
自动故障转移
当集群中有一个master宕机会发生什么呢?
直接停止一个redis实例,例如7002:
redis-cli -p 7002 shutdown
1)首先是该实例与其它实例失去连接
![]()
2)然后是疑似宕机:

3)最后是确定下线,自动提升一个slave为新的master:

4)当7002再次启动,就会变为一个slave节点了:

手动故障转移
利用cluster failover命令可以手动让集群中的某个master宕机,切换到执行cluster failover命令的这个slave节点,实现无感知的数据迁移。其流程如下:
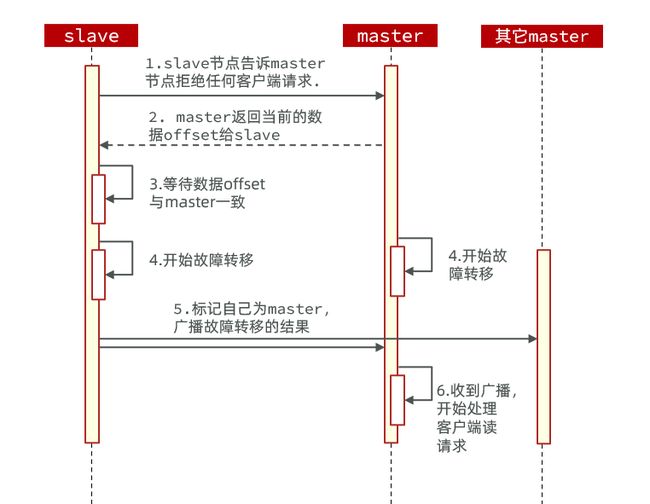
这种failover命令可以指定三种模式:
- 缺省:默认的流程,如图1~6歩
- force:省略了对offset的一致性校验,就是省略2,3步
- takeover:直接执行第5歩,忽略数据一致性、忽略master状态和其它master的意见
案例需求:在7002这个slave节点执行手动故障转移,重新夺回master地位
步骤如下:
1)利用redis-cli连接7002这个节点
2)执行cluster failover命令


RedisTemplate访问分片集群
RedisTemplate底层同样基于lettuce实现了分片集群的支持,而使用的步骤与哨兵模式基本一致:
1)引入redis的starter依赖
2)配置分片集群地址
3)配置读写分离
与哨兵模式相比,其中只有分片集群的配置方式略有差异,如下:
spring:
redis:
cluster:
nodes: #哨兵模式配置的是哨兵集群的地址,而集群配置的就是每个主从节点的地址
- 192.168.150.101:7001
- 192.168.150.101:7002
- 192.168.150.101:7003
- 192.168.150.101:8001
- 192.168.150.101:8002
- 192.168.150.101:8003
集群最终结构
redis集群自动具备这种主从故障切换