并发编程实战(一) logback 异步日志打印模型中ArrayBlockingQueue 的使用、Tomcat 的 NIOEndPoint 中 ConcurrentLinkedQueue 的使用
文章目录
-
-
- 一、 ArrayBlockingQueue 的使用
-
- 1、异步日志打印模型概述
- 2、异步日志与具体实现
-
- (1) 异步日志
- (2) 异步日志实现原理
-
- 类图
- ① AsyncAppenderBase 的 start 方法
- ② AsyncAppenderBase 的 append 方法
- ③ AsyncAppenderBase 的 put 方法
- ④ AsyncAppenderBase 的 addAppender 方法
- ⑤ worker 的 run 方法
- 二、Tomcat 的 NIOEndPoint 中 ConcurrentLinkedQueue 的使用
-
- 1、 生产者——Acceptor 线程
- 2、 消费者——Poller 线程
-
一、 ArrayBlockingQueue 的使用
logback 异步日志打印中 ArrayBlockingQueue 的使用:
1、异步日志打印模型概述
在高并发、高流量 并且 响应时间要求比较小的系统中 同步打印日志 已经满足不了需求了,因为 打印日志本身是需要写磁盘的,写磁盘的操作 会暂时阻塞 调用打印日志的业务线程,这会造成调用线程的 rt 【响应时间】增加。

同步日志打印模型的缺点,是将日志写入磁盘的操作 是 业务线程 同步调用完成的,那么 是否可以让 业务线程把要打印的日志任务放入一个队列后 直接返回,然后使用一个线程 专门负责从队列中获取日志任务 并将其写入磁盘 呢? 这样的话,业务线程打印日志 的 耗时 仅仅是把日志任务放入队列的耗时了,这就是 logback 提供的 异步日志打印模型。
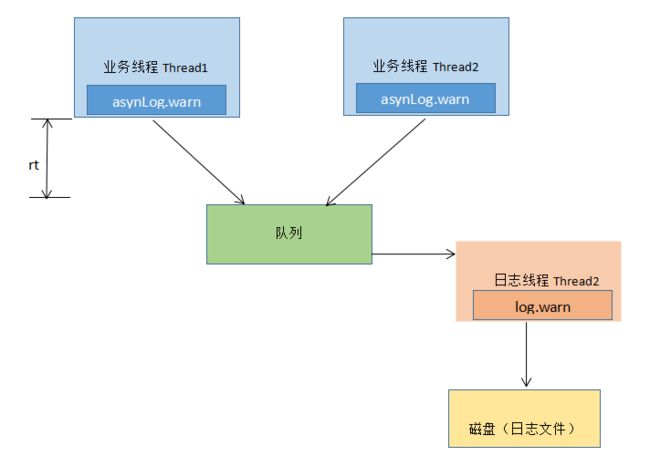
可以看到,logback 的异步日志打印模型是一个 多生产者、单消费者模型,提供队列把 同步日志打印 转换成了异步,业务线程只需要通过调用异步 appender 把日志任务放入日志队列,而 日志线程则负责使用同步的 appender 进行具体的日志打印。日志打印线程只需要负责生产日志 并将其放入队列,而不需要关心消费线程何时把日志具体写入磁盘。
2、异步日志与具体实现
(1) 异步日志
先构建 Maven 项目,在 pom.xml 中导入依赖:
<dependencies>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.25</version>
</dependency>
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-core</artifactId>
<version>1.2.3</version>
</dependency>
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
<version>1.2.3</version>
</dependency>
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-access</artifactId>
<version>1.1.7</version>
</dependency>
</dependencies>
在 resources 包下新建 logback 的 xml 配置文件 logback-test.xml :

%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{50} - %msg%n
${LOG_HOME}/neo4j.%d{yyyy-MM-dd}.log
30
%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{50} - %msg%n
${LOG_HOME}/neo4j_warn.%d{yyyy-MM-dd}.log
30
%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{50} - %msg%n
true
warn
ACCEPT
DENY
${LOG_HOME}/neo4j_error.%d{yyyy-MM-dd}.log
30
%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{50} - %msg%n
ERROR
(这个 XML 的配置参考博客 https://blog.csdn.net/qq_23132561/article/details/100924628)
写 Java 代码:
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class LogTest {
private static Logger logger=LoggerFactory.getLogger("PROJECT_logger");
public static void main(String[] args) {
logger.warn("hello");
logger.warn("ohh");
}
}
运行后可以看到控制台输出:
目录中也生成了日志包:
在相应的 warn 的 log 中生成:

以上代码中,AsyncAppender 是实现异步日志的关键。
(2) 异步日志实现原理
类图
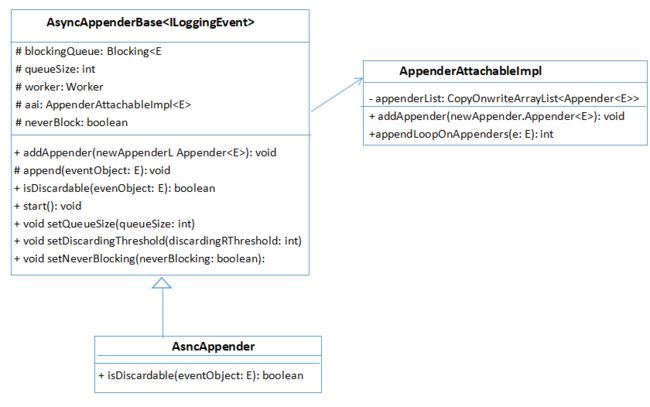
可以看到,AsyncAppender 继承自 AsyncAppebderBase,AsyncAppebderBase 实现了 异步日志模型的功能,而 AsyncAppender 只是重写了其中一些方法。logback 中的 异步日志 是一个阻塞队列,其实就是 有界阻塞队列 ArrayBlockingQueue,其中 queueSize 表示有界队列的
元素个数,默认是 256 个。之所以使用有界队列,是考虑内存溢出问题。在高并发下写日志的 QPS 会很高,如果设置为无界队列,队列本身会占用很大的内存,很可能造成 OOM。
worker 是个线程,也就是 异步日志打印模型中的 单消费者 线程。aai 是一个 appender 的装饰器,里面存放同步日志的 appender ,其中 appenderCount 记录 aai 里附加的 同步 appender 的个数。neverBlock 用来指示 当日志队列满时 是否阻塞打印日志的线程, discardingThreshold 是一个阈值,当 日志队列里的空闲元素个数小于该值时,新来的某些级别的日志会被直接丢弃。
① AsyncAppenderBase 的 start 方法
来看看 AsyncAppenderBase 的 start 方法,何时创建日志队列,以及 何时启动消费线程。 该方法在解析完配置 AsyncAppenderBase 的 xml 节点元素后被调用。
源码:
public void start() {
if (!this.isStarted()) {
if (this.appenderCount == 0) {
this.addError("No attached appenders found.");
} else if (this.queueSize < 1) {
this.addError("Invalid queue size [" + this.queueSize + "]");
} else {
// 日志队列为有界阻塞队列
this.blockingQueue = new ArrayBlockingQueue(this.queueSize);
// 如果没设置阈值 discardingThreshold ,就设置为队列大小的 1/5
if (this.discardingThreshold == -1) {
this.discardingThreshold = this.queueSize / 5;
}
this.addInfo("Setting discardingThreshold to " + this.discardingThreshold);
// 设置线程为守护线程
this.worker.setDaemon(true);
// 设置日志名称
this.worker.setName("AsyncAppender-Worker-" + this.getName());
// 启动消费线程
super.start();
this.worker.start();
}
}
}
worker 线程被设置为 守护线程 ,这意味着 当主线程运行结束 并且 当前没有用户线程时,该 worker 线程会随着 JVM 的退出而终止,而 不管日志队列里是否还有日志任务没有被处理。另外,这里设置了线程的名称,这对于查找问题很有帮助,根据线程名字就可以定位线程。
② AsyncAppenderBase 的 append 方法
既然是有界队列,那么肯定要考虑队列满的问题,是 丢弃老的日志任务,还是 阻塞日志打印线程 直到队列有空余元素呢?
看看 具体进行日志打印的 AsyncAppenderBase 的 append 方法,源码:
protected void append(E eventObject) {
// (一)
if (!this.isQueueBelowDiscardingThreshold() ||
// (二)调用 AsyncAppender 重写的 isDiscardable 方法
!this.isDiscardable(eventObject)) {
this.preprocess(eventObject);
// 将日志任务放入队列
this.put(eventObject);
}
}
(一)isQueueBelowDiscardingThreshold:
private boolean isQueueBelowDiscardingThreshold() {
return this.blockingQueue.remainingCapacity() < this.discardingThreshold;
}
(二)isDiscardable:
protected boolean isDiscardable(ILoggingEvent event) {
Level level = event.getLevel();
return level.toInt() <= 20000;
}
可以看到,如果当前日志的级别 小于等于 INFO_INT (20000),并且 当前队列的剩余容量 小于 discardingThreshold 则会直接丢弃这些日志任务。
③ AsyncAppenderBase 的 put 方法
private void put(E eventObject) {
if (this.neverBlock) {
// (三)
this.blockingQueue.offer(eventObject);
} else {
// (一)
this.putUninterruptibly(eventObject);
}
}
(一)putUninterruptibly:
private void putUninterruptibly(E eventObject) {
boolean interrupted = false;
try {
while(true) {
try {
// (二)
this.blockingQueue.put(eventObject);
return;
} catch (InterruptedException var7) {
// 记录中断标志,并不抛出异常
interrupted = true;
}
}
} finally {
if (interrupted) {
Thread.currentThread().interrupt();
}
}
}
可以看到,如果当前日志打印线程在调用 put 方法时被其他线程中断,则 只是记录中断标志,然后继续 循环调用 blockingQueue.put 方法,尝试把日志任务放入日志队列。这样的话,即使当前任务被中断,日志任务最终也会被放入日志队列的。
(二)put:
public void put(E e) throws InterruptedException {
checkNotNull(e);
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
while (count == items.length)
// 如果队列满,则 调用 await 方法阻塞当前调用线程
notFull.await();
enqueue(e);
} finally {
lock.unlock();
}
}
可以看到,在 put 方法中,如果 neverBlock 被设置为 false(默认是 false),就会调用阻塞队列的 put 方法,而 put 是阻塞的,也就是说,如果当前队列满,则 在调用 put 方法向队列放入一个元素时,调用线程会被阻塞,直到队列有空余空间。而如果 neverBlock 被设置为 true ,则会调用 blockingQueue.offer 方法,而 该方法是非阻塞的,所以 如果当前队列满,则会直接返回,也就是 直接丢弃当前日志任务。
(三)offer:
public boolean offer(E e) {
checkNotNull(e);
final ReentrantLock lock = this.lock;
lock.lock();
try {
if (count == items.length)
return false;
else {
enqueue(e);
return true;
}
} finally {
lock.unlock();
}
④ AsyncAppenderBase 的 addAppender 方法
源码:
public void addAppender(Appender<E> newAppender) {
if (this.appenderCount == 0) {
++this.appenderCount;
this.addInfo("Attaching appender named [" + newAppender.getName() + "] to AsyncAppender.");
this.aai.addAppender(newAppender);
} else {
this.addWarn("One and only one appender may be attached to AsyncAppender.");
this.addWarn("Ignoring additional appender named [" + newAppender.getName() + "]");
}
}
可以看到,一个异步 appender 只能绑定一个同步 appender,这个 appender 会被放到 AppenderAttachableImpl 的 appendList 列表中。
以上是日志生产线程 把 日志任务 放入日志队列的实现,接下来看看 消费线程 如何 从队列中 消费日志任务 并将其写入磁盘。
⑤ worker 的 run 方法
源码:
class Worker extends Thread {
Worker() {
}
public void run() {
AsyncAppenderBase<E> parent = AsyncAppenderBase.this;
AppenderAttachableImpl aai = parent.aai;
// 直到线程被中断才退出循环
while(parent.isStarted()) {
try {
// 从阻塞队列中获取元素
E e = parent.blockingQueue.take();
aai.appendLoopOnAppenders(e);
} catch (InterruptedException var5) {
break;
}
}
AsyncAppenderBase.this.addInfo("Worker thread will flush remaining events before exiting. ");
//走到这里说明线程被中断,则 把队列里的剩余日志任务 刷新到磁盘
Iterator i$ = parent.blockingQueue.iterator();
while(i$.hasNext()) {
E ex = i$.next();
aai.appendLoopOnAppenders(ex);
parent.blockingQueue.remove(ex);
}
aai.detachAndStopAllAppenders();
}
}
可以看到,run 方法中,先使用 take 方法 获取日志任务 ,如果当前队列为空,则 当前线程阻塞,直到队列不为空才返回。获取到日志任务后,调用 AppenderAttachableImpl 的 appendLoopOnAppenders 方法 ,该方法会循环调用通过 addAppender 注入的同步日志,appener 具体实现把日志打印到磁盘。
总结:
以上是 logback 中异步日志的实现,包括并发组件 ArrayBlockingQueue 的使用,包括 put、offer 方法的使用场景 以及 它们之间的区别,take 方法的使用,而且 ArrayBlockingQueue 实现的是 多生产者-单消费者模型。使用 ArrayBlockingQueue 时需要注意合理设置队列的大小 以免造成 OOM,队列满 或者 剩余元素比较少时,要根据具体场景制定一些抛弃策略,以避免队列满时线程被阻塞。
二、Tomcat 的 NIOEndPoint 中 ConcurrentLinkedQueue 的使用
首先介绍 Tomcat 的容器结构 :

其中,Connector 是一个桥梁,它把 Server 和 Engine 连接起来,Connector 的作用是 接受客户端的请求 ,然后 把请求委托给 Engine 容器处理。在Connector 内部 具体使用 EndPoint 进行处理。根据处理方式的不同,EndPoint 分为 NioEndpoint、JIoEndpoint、AprEndpoint。
NioEndpoint 的三大组件的关系:
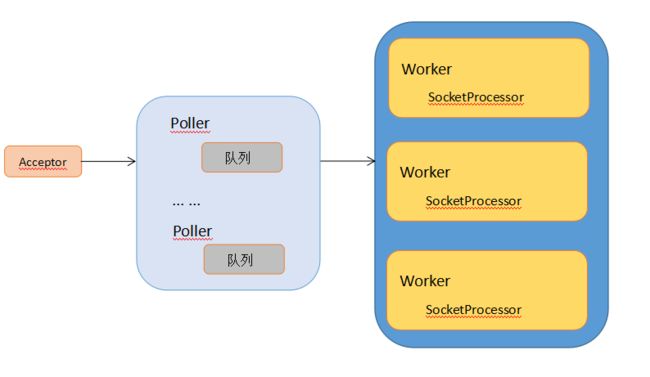
- Acceptor 是套接字接收线程(Socket acceptor thread),用来接受用户的请求,并把请求封装成事件任务 放入 Poller 队列,一个 Connector 里只有一个 Acceptor 。
- Poller 是套接字处理线程(Socker poller thread),每个 poller 内部都有一个独有的队列,Poller 线程从自己的队列里获取具体的事件任务,然后将其交给 Worker 进行处理。Poller 线程的个数 与 处理器的核数有关。
源码:
protected int pollerThreadCount =
Math.min(2,Runtime.getRuntime().availableProcessors());
这里,最多有 2 个 Poller 线程。
- Worker 是实际处理请求的线程,Worker 只是组件名字,真正做事情的是 SocketProcessor,它是 Poller 线程从自己的队列获取任务后的真正任务执行者。
可以看到,Tomcat 使用队列把接受请求 与 处理请求操作进行解耦,实现异步处理,其实 Tomcat 中 每个 Poller 里 都维护了一个 ConcurrentLinkedQueue ,用来缓存请求任务,其本身也是一个 多生产者-但消费者模型。
1、 生产者——Acceptor 线程
Acceptor 线程的作用是接受客户端发来的连接请求 并将其放入 Poller 的事件队列,Acceptor 处理请求的简明时序图:
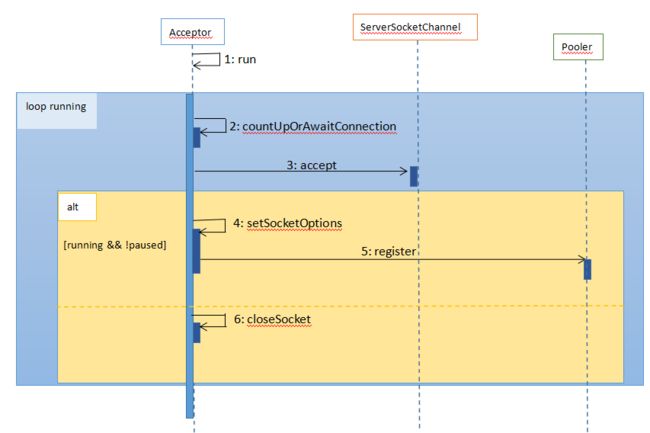
接下来看源码,Accepter 如何把接受的套接字连接放入队列:
protected class Acceptor extends AbstractEndpoint.Acceptor{
@Override
public void run(){
int errorDelay = 0;
// 一直循环直到接收到 shutdown 命令
while(running){
...
if (! running) {
break;
}
state = AcceptorState.RUNNING;
try{
// 如果达到 max connections 个请求 则当前请求被挂起
countUpOrAwaitConnection();
SocketChannel socket = null;
try{
// 从 TCP 缓存获取一个完成三次握手的套接字,没有则阻塞挂起
socket = serverSocket.accept();
} catch (IOException ioe) {
...
}
errorDelay = 0;
if( running && !paused){
// (一)设置套接字参数 并 封装套接字为事件任务,
// 然后放入 Poller 队列
if( ! setSocketOptions(socket)){
countDownConnection();
closeSocket(socket);
}
} else {
countDownConnection();
closeSocket(socket);
}
...
} catch (SocketTimeOutException sx) {
...
}
state = AcceptorState.ENDED;
}
}
(一)setSocketOptions:
protected boolean setSocketOptions(SocketChannel socket){
// 处理来南京
try{
...
// (二)封装连接套接字为 channel 并注册到 poller 队列
getPoller0().register(channel);
} catch (Throwable t){
...
return false;
}
return true;
(二)register:
public void register(final NioChannel socket){
...
PollerEvent r = eventCache.poll();
ka.interestOps(SelectionKey.OP_read);
if(r == null ) r = new PollerEvent(socket,ka,OP_ REGISTER);
else r.reset(socket,ka,OP_ REGISTER);
//(三)
addEvent(r);
}
(三)addEvent:
public void addEvent(Runnable event){
events.offer(event);
...
}
其中,events 的定义:
protected ConcurrentLinkedQueue<Runnable> events = new ConcurrentLinkedQueue<Runnable> ();
可以看到,events 是一个无界队列 ConcurrentLinkedQueue,之前说 异步日志打印时 要注意设置队列大小,否则会导致 OOM,Tomcat 的 NIOEndpoint 也是如此,Tomcat 会让用户配置一个最大连接数 ,超过这个数,请求就会被挂起。
2、 消费者——Poller 线程
Poller 线程的作用是从事件队列中 获取事件并进行处理。先看看它的简明时序图:
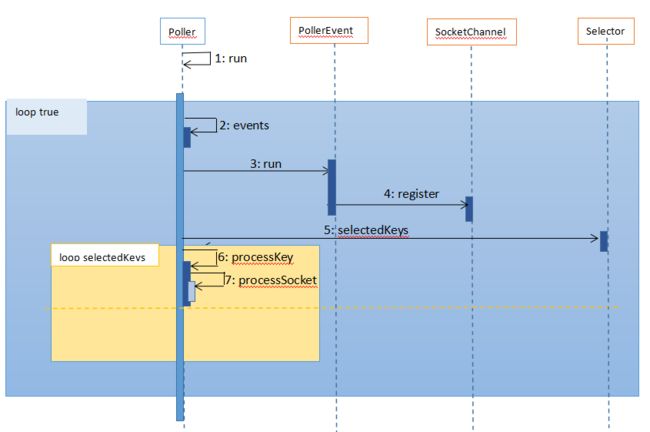
Poller 线程的 run 方法源码:
public void run(){
while(true) {
try {
...
if(close) {
...
} else {
// (一)从事件队列获取事件
hasEvents = events();
}
try{
...
} catch (NullPointerException x){ ...
}
Iterator<SelectionKey> iterator = keyCount > 0? selector.selectedKeys().iterator() : null;
// (二)遍历所有注册的 channel 并对感兴趣的事情进行处理
while( iterator != null && iterator.hasNext()){
SelectionKey sk = iterator.next();
KeyAttachment attachment = (KeyAttachment) sk.attachment();
if(attachment == null) {
iterator.remove();
}else {
attachment.access();
iterator.remove();
// 具体调用 SocketProcessor 进行处理
processKey(sk, attachment);
}
} // while
...
} catch (OutOfMemoryError oom) {
...
}
} // while
...
}
(一)events():
public boolean events(){
boolean result = false;
// 从队列获取任务并执行
Runnable r = null;
while((r = events.poll())!= null) {
result = true;
try{
r.run();
...
} catch (Throwable x){
...
}
}
return result;
(二)processSocket:
public boolean processSocket(NioChannel socket, SocketStatus status,boolean dispatch){
try{
...
SocketProcessor sc = processorCache.poll();
if(sc == null) sc = new SocketProcessor(socket,status);
else sc.reset(socket,status);
if(dispatch && getExecutor() != null) getExecutor().execute(sc);
else sc.run();
} catch(RejectedException rx){
...
} catch(Throwable t){
...
return false;
}
return true;
总结与补充:
Tomcat 使用 Connector 处理连接,一个Tomcat 可以配置多个 Connector,分别监听不同端口,或处理不同协议。
8.5 以后的 Tomcat 的 start 方法中,会自动配置一个 非阻塞 IO 的 connector ,可以 指定 Protocol,初始化相应的 Endpoint,我们分析的是 NioEndpoint:
(1)init 过程:
调用 NioEndpoint 的 bind 监视操作;
在 bind() 中会通过 ServerSocketChannel.open() 开启 ServerSocketChannel,并设置 acceptor 线程数为1 ,poller 线程数为2(单核 CPU 为 1,多核为 2) 。
(2)start 过程:
启动 worker 线程池,启动 1 个 Acceptor 线程 和 2 个 Poller 线程,当然它们都是默认值,可配;
(3)Acceptor
Acceptor 循环调用 ServerSocketChannel 的 accept() 方法获取新的连接,就会创建一个 SocketChannel 实例,然后getPoller0() 获取其中一个 Poller,然后把这个 SocketChannel 注册 register 到 Poller 中;
(4)Poller
Poller 内部有个SynchronizedQueue类型的 events 队列,events() 方法取出当前队列中的 PollerEvent 对象,逐个执行 run() ,run() 方法主要将这个新连接 SocketChannel 注册到该 poller 的 Selector 中,(每个 poller 会关联一个 selector)监听 OP_READ 事件,一旦该 SocketChannel 是 readable 的状态,那么就会进入到 processKey 方法,会创建 SocketProcessor 实例,把实例提交到线程池中。