基于YOLO的弓网系统接触火花识别检测算法
1.1 任务目标
针对地铁车辆受电弓与接触网偶发性出现的接触火花,拟通过物体检测机器视觉算法YOLO,进行接触火花的识别、定位。
车辆运行期间,通过设置于地铁车辆车体顶部的摄像系统,车载机器视觉系统将不间断采集弓网接触视频数据,获得受电弓与接触网相互位置、接触点和接触火花情况。所采集视频流数据分解为图像信息后,通过本文提出的基于YOLO的神经网络进行接触火花的识别与定位,并给出相应的置信度。
对于弓网接触火花的机器视觉问题,主要存在以下几个难点。首先,接触火花并非存在于所有采集图像中,出现的位置也是相对随机不固定的;其次,接触火花是相对较小的目标,需要识别算法也具有对于小目标物体检测的能力;最后,车辆运行环境复杂,不同工况下弓网系统的环境光以及接触网支撑定位装置等,都会成为影响识别的背景“噪声”,且客观上无法消除,因此识别算法应当在多运行工况下均具有鲁棒性。
传统机器视觉算法,往往基于特征选取、提取与匹配,且检测目标单一、运行速度较慢。在特征选取和提取的步骤中,用户要分析与检测相关属性的机器学习算法,然后才能将其训练为可以检测相应特性的物体。
基于深度学习的方法能让机器视觉应用更加具有适应性,与传统方法相比,这样可省去特征选取和提取的步骤,可以在训练过程中独立地学习相关属性。并且,深度网络具有更好的鲁棒性,经过适当训练的神经网络可以很好地识别出变量环境(如变化的背景、不同的分辨率或光源条件)中的物体,无需针对每个可能的特性进行专门训练。
本文借助于近年来深度神经网络在机器视觉领域的发展,提出了基于深度学习的弓网火花检测算法。
1.2 基于深度神经网络的目标识别算法
目前,学界与工业界有下列几种用于目标检测的技术,包括R-CNN、You Look Only Once(YOLO)和Single Shot MultiBox Detector(SSD)等。主流的算法根据识别步骤主要分为两个类型,即Two-stage方法与One-stage方法。
R-CNN、Faster R-CNN等算法采用的是Two-stage方法,其主要思路是先通过启发式方法(Selective Search)或者CNN网络产生一系列稀疏的候选框,然后对这些候选框进行分类与回归,Two-stage方法的优势是准确度高;Yolo和SSD等采用的是One-stage方法,其主要思路是均匀地在图片的不同位置进行密集抽样,抽样时可以采用不同尺度和长宽比,然后利用CNN提取特征后直接进行分类与回归,整个过程只需要一步,其优势是速度快。
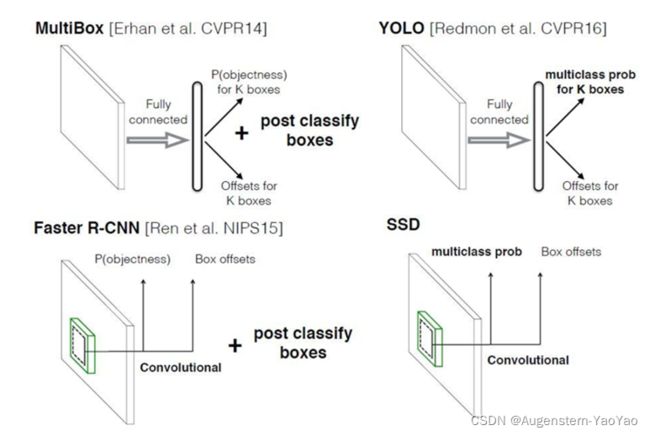
下面将具体介绍应用最为广泛的三类基于深度神经网络的机器视觉目标检测算法:
(a) Faster R-CNN
经过R-CNN和Fast R-CNN的积淀,Girshick在2016年提出了新的Faster R-CNN。在结构上,Faster R-CNN已经将特征抽取(Feature Extraction),区域提取(Region Proposals)、边界框回归(Bounding Box Regression)、分类(Classification)都整合在了一个网络中,使得综合性能有较大提高,在检测速度方面尤为明显。

图2 Faster R-CNN基本结构
Faster R-CNN采用了“卷积层-Relu层-池化层”的特征图(Feature Map)结构,同时将该特征图共享用于后续的Region Proposal Networks(RPN)网络。其采用RPN网络生成目标在图像中的待提取位置,该层通过Softmax激活函数判断目标的参考框是否存在,再使用Bounding Box Regression修正参考框位置,以锁定物体所在区域。ROI(Region of Interest)Pooling层收集输入的特征图与参考框选位置,提取目标特征图后送入全连接层判定目标类别,并再次运行Bounding Box Regression以获得检测框最终的精确位置。
(b) SSD
SSD算法,全称为Single Shot MultiBox Detector,其属于多框预测One-stage方法。SSD采用CNN来直接进行检测,并提取了不同尺度的特征图来做检测,大尺度特征图(较靠前的特征图)可以用来检测小物体,而小尺度特征图(较靠后的特征图)用来检测大物体。相比于Faster R-CNN,SSD提出了一个彻底的端到端(End-to-end)的训练网络,保证了精度的同时大幅度提高了检测速度。
SSD在基础网络(VGG)后添加了辅助层进行多尺度卷积图的预测结果融合,提出了Default Boxes,即为特征图每个小格上一系列固定大小的单元,解决了输入图像目标大小尺寸不同的问题。
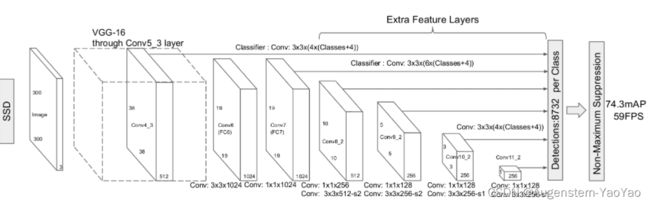
图3 SSD基本结构
(c) YOLO
Yolo算法采用一个单独的CNN模型实现端到端的目标检测,整个系统如图4所示。首先将输入图片尺寸修改(Resize Image),然后送入CNN网络,最后处理网络预测结果得到检测的目标。相比R-CNN算法,YOLO为统一框架,速度更快。
MATLAB中集成的YOLO的神经网络架构基于SqueezeNet。SqueezeNet是Han等提出的一种轻量且高效的CNN模型,它远小于著名的AlexNet,但模型性能与AlexNet接近。在可接受的性能下,小模型相比大模型,具有很多优势:(a)更高效的分布式训练,小模型参数小,网络通信量减少;(b)便于模型更新,模型小;(c)利于部署在如FPGA等的特定边缘计算硬件上,因为其内存受限,暂时无法部署更大规模的神经网络。
YOLO在SqueezeNet中使用特征提取网络(Feature Extraction Network),并附加了两组检测网络,其中第二组检测网络的层数是第一组检测网络的两倍,因此能够更好地探测小物体。YOLO使用训练数据估计的锚定框(Anchor Box),以获得与数据集类型相对应的更好初始优先级,并帮助网络学习准确预测定位。YOLO v3网络如下图所示。
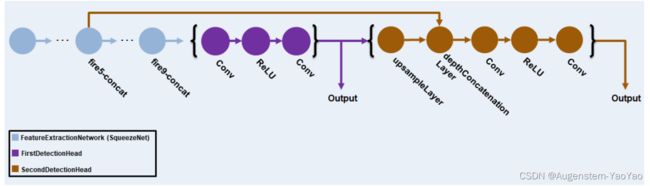
图5 YOLO神经网络架构
1.3 基于YOLO的弓网接触火花识别
本文采用的第三代YOLO目标识别算法YOLO v3,编程平台为MATLAB,主要参考为MATLAB的官方案例。
YOLO v3在YOLO v2的基础上进行了改进,增加了多尺度目标识别功能,可以适用于更小目标的检测。此外,用于训练的损失函数还改进为由两部分组成,以帮助提高检测精度:(a)边界框回归的均方误差;(b)用于目标分类的二元交叉熵(Binary Cross-entropy)。
1.3.1 创建数据集
本文首先建立了一个包含353个图像的标注数据集。数据集采集于真实地铁车辆运行的车载监控视频记录,使用MATLAB Video Labeler对于视频中部分有火花和无火花的帧进行了标注。其中无火花的弓网接触区用蓝色框选,标记为“Safe”,有火花的弓网接触区用黄色框选,标记为“Spark”。如图6所示。
(图片已删除)
(a)“Spark”标记框
(图片已删除)
(b)“Safe”标记框
图6 Video Labeler视频帧标注
标注后将产生寄生于视频的数据标注文件,包括被标注“Spark”或“Safe”的帧在视频中的位置、标记框的标签名称、标记框的矩形四顶点坐标等信息。
经代码提取后可生成图7所示的图片数据集,计有195张标记为无火花的“Safe”数据图像与158张标记为有火花的“Spark”图像。每个图像包含一个或两个(例如接触网转换区)标记的目标检测实例。
(a)“Safe”图像数据集

(b)“Spark”图像数据集
图7 弓网接触火花图像数据集
1.3.2 数据集处理
将数据集拆分为用于训练网络的训练集和用于评估网络的测试集,将70%的数据用于训练集,其余数据用于测试集。
首先进行数据集清洗,包括如下步骤:
(a)创建用于加载图像的图像数据存储变量;
(b)将图像和框标签数据存储结合起来生成统一变量;
(c)检测无效图像、边界框或标签,包括无效的图像格式、零/非数/空的边界框矩阵、缺少或非分类的标签数据类型、超过正高度与正宽度图像边界的边界框矩阵;
(d)删除数据集的无效样本。
为提高YOLO神经网络的鲁棒性,提高深度网络学习效率,进一步需要对于数据集进行数据增强(Data Augmentation)。数据增强是通过在训练期间随机变换原始图像数据集来提高网络精度。通过使用数据增强,可以向训练数据添加更多变化场景与合理的数据扩充,而无需实际增加标记训练样本的数量。
本文应用了以下三种数据增强方法:
(a)在HSV图像空间中,针对亮度(Brightness)、对比度(Contrast)、饱和度(Saturation)和色调(Hue)等特性进行随机变换;
(b)随机水平方向翻转;
(c)随机缩放15%。
三种图像数据增强方法及原图如图8所示。
(图片已删除)
图8 数据集增强
为适应后续神经网络的输入特性,还需要对增强后的训练数据图像集进行尺寸变换预处理过程,将原图像尺寸的1920×1080缩放为1080×1080的正方形图像,图9显示了经过水平翻转水平增强后的图片进一步被压缩为正方形图像的结果,其标注框也对应发生了尺寸变换。
(图片已删除)
图9 数据集预处理
1.3.3 YOLO神经网络定义
在选择网络输入大小时,考虑运行网络本身所需的最小大小、训练图像的大小以及在选定大小上处理数据所产生的计算成本。在可行的情况下,选择一个接近训练图像大小、大于网络所需输入大小的网络输入大小。最终将神经网络的输入大小指定为[1080 1080 3],其中第一个“1080”表示图像输入为1080行,第二个“1080”表示图像输入为1080列,“3”表示图像为RGB三维空间图像模型。
定义YOLO网络还需要指定对象类的名称、要检测的对象类的数量以及每个锚定框的预测元素的数量。每个锚定框的预测数设置为5加上对象类数。“5”表示4个边界框属性和1个对象置信度,由于本文定义了两种弓网接触区模型(Safe/Spark),故预测输出为7。
YOLO的神经网络共计有70层,78个连接数,是以SqueezeNet为基础,添加了特征提取网络与目标检测网络。由于SqueezeNet在“fire9 concat”之后的层只适用于分类任务,而对于目标检测没有帮助,故使用squeezenetFeatureExtractor辅助函数进行了删除。进一步地,将检测网络添加到特征提取网络。每个探测网络用于预测各个锚定边界框的坐标、对象置信度和类别概率。最后,通过将第一层检测网络连接到特征提取层,将第二层检测网络连接到第一层检测网络的输出。此外,将第二层检测网络中的采样特征与“fire5 concat”层中的特征合并,以加强第二层检测网络的信息输出。YOLO的神经网络架构如图10所示。
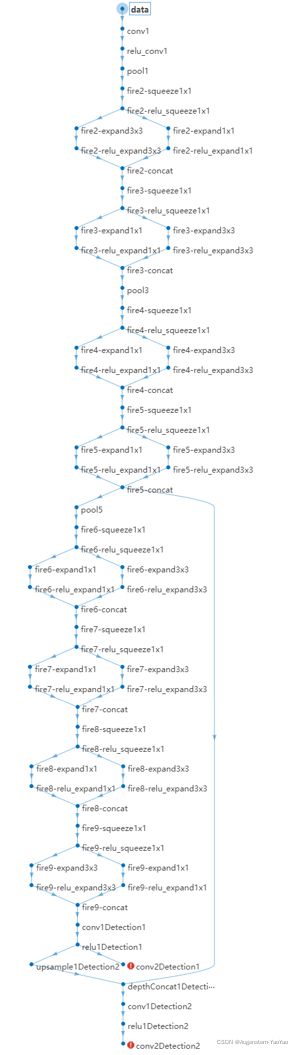
图10 神经网络架构定义
1.3.4神经网络训练
YOLO神经网络的训练参数表如表1所示。
表1 YOLO神经网络的训练参数表
| 训练参数 |
取 值 |
| 最大训练回合数(Number of Epochs) |
100 |
| 批大小(Mini Batch) |
8 |
| 学习率(Learning Rate, LR) |
0.001 |
| Warmup Period |
1000 |
| L2 正则化系数(L2 Regularization Factor) |
0.0005 |
| 惩罚阈值(Penalty Threshold) |
0.5 |
本例采用RTX 2070 SUPER显卡硬件加速训练,对于训练过程中的每个迭代,依次进行下列步骤:
S1:从待训练批次中读取数据,如果没有更多数据即重置本Batch;
S2:使用dlfeval和modelGradients函数评估模型梯度;
S3:将权重衰减因子应用于梯度下降,以进行更鲁棒的训练;
S4:使用sgdmupdate函数更新网络参数;
S5:用移动平均算法,更新网络的状态参数;
S6:显示每次迭代学习率、总损失函数和单个损失函数(Box损失函数、对象损失函数和类别损失函数);
S7:更新训练进度图。
经1900次迭代后,神经网络的训练获得收敛,其学习率随迭代次数的曲线如图11所示。
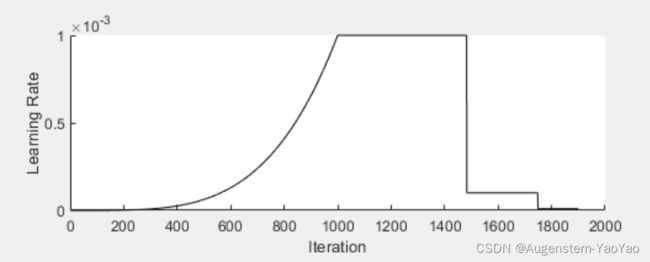
图11 神经网络训练学习率变化曲线
1.4目标识别实测
通过上述神经网络训练获得的网络参数,封装为函数调用,并针对车载监控视频进行逐帧识别,输出识别视频,如图12所示。由图可知,基于YOLO的深度神经网络机器视觉火花识别算法工作正常,对于接触火花与安全接触等两种情况均能够可靠识别,并对于环境光、背景物体等具有一定鲁棒性。
(图片已删除)
(图片已删除)
图12 训练获得的神经网络进行逐帧识别
总结
本例为针对MATLAB内置yolo函数的简单应用,对于Spark的检测很可能是过拟合的。