【OpenVINO】基于 OpenVINO C++ API 部署 RT-DETR 模型
基于 OpenVINO C++ API 部署 RT-DETR 模型
- 1. RT-DETR
- 2. OpenVINO
- 3. 环境配置
- 4. 模型下载与转换
-
- 4.1 模型导出
- 4.2 模型信息对比
- 5. C++代码实现
-
- 5.1 模型推理类实现
- 5.2 模型数据处理类RTDETRProcess
- 6. 预测结果展示
- 7. 总结
RT-DETR是在DETR模型基础上进行改进的,一种基于 DETR 架构的实时端到端检测器,它通过使用一系列新的技术和算法,实现了更高效的训练和推理,在前文我们发表了《基于 OpenVINO™ Python API 部署 RT-DETR 模型 | 开发者实战》,在该文章中,我们基于OpenVINO™ Python API 向大家展示了包含后处理的RT-DETR模型的部署流程,但在实际工业应用中,我们为了与当前软件平台集成更多会采用C++平台,因此在本文中,我们将基于OpenVINO™ C++ API 向大家展示了不包含后处理的RT-DETR模型的部署流程,并向大家展示如何导出不包含后处理的RT-DETR模型。
该项目所使用的全部代码已经在GitHub上开源,并且收藏在OpenVINO-CSharp-API项目里,项目所在目录链接为:
https://github.com/guojin-yan/OpenVINO-CSharp-API/tree/csharp3.0/tutorial_examples
也可以直接访问该项目,项目链接为:
https://github.com/guojin-yan/RT-DETR-OpenVINO.git
项目首发网址为:基于 OpenVINO™ C++ API 部署 RT-DETR 模型 | 开发者实战
1. RT-DETR
飞桨在去年 3 月份推出了高精度通用目标检测模型 PP-YOLOE ,同年在 PP-YOLOE 的基础上提出了 PP-YOLOE+。而继 PP-YOLOE 提出后,MT-YOLOv6、YOLOv7、DAMO-YOLO、RTMDet 等模型先后被提出,一直迭代到今年开年的 YOLOv8。

YOLO 检测器有个较大的待改进点是需要 NMS 后处理,其通常难以优化且不够鲁棒,因此检测器的速度存在延迟。DETR是一种不需要 NMS 后处理、基于 Transformer 的端到端目标检测器。百度飞桨正式推出了——RT-DETR (Real-Time DEtection TRansformer) ,一种基于 DETR 架构的实时端到端检测器,其在速度和精度上取得了 SOTA 性能。

RT-DETR是在DETR模型基础上进行改进的,它通过使用一系列新的技术和算法,实现了更高效的训练和推理。具体来说,RT-DETR具有以下优势:
- 1、实时性能更佳:RT-DETR采用了一种新的注意力机制,能够更好地捕获物体之间的关系,并减少计算量。此外,RT-DETR还引入了一种基于时间的注意力机制,能够更好地处理视频数据。
- 2、精度更高:RT-DETR在保证实时性能的同时,还能够保持较高的检测精度。这主要得益于RT-DETR引入的一种新的多任务学习机制,能够更好地利用训练数据。
- 3、更易于训练和调参:RT-DETR采用了一种新的损失函数,能够更好地进行训练和调参。此外,RT-DETR还引入了一种新的数据增强技术,能够更好地利用训练数据。

2. OpenVINO
英特尔发行版 OpenVINO™工具套件基于oneAPI 而开发,可以加快高性能计算机视觉和深度学习视觉应用开发速度工具套件,适用于从边缘到云的各种英特尔平台上,帮助用户更快地将更准确的真实世界结果部署到生产系统中。通过简化的开发工作流程, OpenVINO™可赋能开发者在现实世界中部署高性能应用程序和算法。

OpenVINO™ 2023.1于2023年9月18日发布,该工具包带来了挖掘生成人工智能全部潜力的新功能。生成人工智能的覆盖范围得到了扩展,通过PyTorch*等框架增强了体验,您可以在其中自动导入和转换模型。大型语言模型(LLM)在运行时性能和内存优化方面得到了提升。聊天机器人、代码生成等的模型已启用。OpenVINO更便携,性能更高,可以在任何需要的地方运行:在边缘、云中或本地。
3. 环境配置
在上一篇文章中我们以已经向大家提供了RT-DETR模型导出苏需要的环境,此处不再多做展示,为了大家更好的复现该项目代码,此处向大家提供本次开发所使用的C++环境:
openvino: 2023.1.0
opencv: 4.5.5
大家在复现代码时可以使用相同的环境或者与作者所使用环境发布较为接近的环境进行开发,防止使用时出现不必要的错误;此外该项目提供了两种编译方式,大家可以使用Visual Studio进行编译以及CMake进行编译。
4. 模型下载与转换
在上一篇文章中我们已经向大家展示了RT-DETR预训练模型的导出方式,该模型是默认包含后处理的;因此在本文中,我们将向大家展示不包含后处理的RT-DETR模型导出方式以及两种模型的差异。
4.1 模型导出
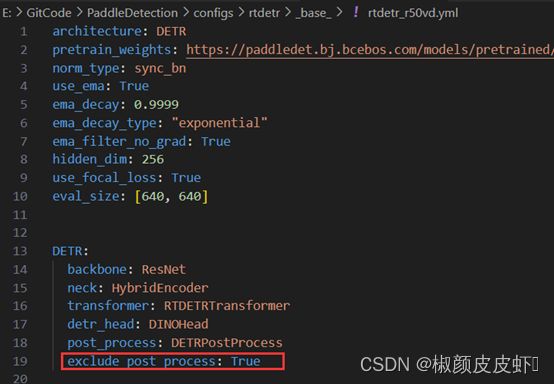
PaddleDetection官方库向我们提供了十分友好API接口,因此导出不包含后处理的RT-DETR模型也是十分容易的。首先修改配置文件,主要是修改RT-DETR模型的配置文件,配置文件路径为:.\PaddleDetection\configs\rtdetr\_base_\rtdetr_r50vd.yml,在配置文件DETR项目下增加exclude_post_process: True语句,如下图所示:
然后重新运行模型导出指令,便可以获取不包含后处理的模型:
python tools/export_model.py -c configs/rtdetr/rtdetr_r50vd_6x_coco.yml -o weights=https://bj.bcebos.com/v1/paddledet/models/rtdetr_r50vd_6x_coco.pdparams trt=True --output_dir=output_inference
在模型导出后,我们可以转换成ONNX格式以及IR格式,可参考上一篇文章中的模型转换内容。
4.2 模型信息对比
通过下表我们可以看出,裁剪后的模型,只包含一个输入节点,其输出节点也发生了变化,原本模型输出为处理后的预测输出,经过裁剪后,模型输出节点输出内容发生了较大变化。其中:
stack_7.tmp_0.slice_0:该节点表示300种预测结果的预测框信息;stack_8.tmp_0.slice_0:该节点表示300种预测结果的80种分类信息置信度,后续再处理时,需要根据预测结果获取最终的预测分类信息。



5. C++代码实现
为了更系统地实现RT-DETR模型的推理流程,我们采用C++特性,封装了RTDETRPredictor模型推理类以及RTDETRProcess模型数据处理类,下面我们将对这两个类中的关键代码进行讲解。
5.1 模型推理类实现
C++代码中我们定义的RTDETRPredictor模型推理类如下所示:
class RTDETRPredictor
{
public:
RTDETRPredictor(std::string model_path, std::string label_path,
std::string device_name = "CPU", bool postprcoess = true);
cv::Mat predict(cv::Mat image);
private:
void pritf_model_info(std::shared_ptr<ov::Model> model);
void fill_tensor_data_image(ov::Tensor& input_tensor, const cv::Mat& input_image);
void fill_tensor_data_float(ov::Tensor& input_tensor, float* input_data, int data_size);
private:
RTDETRProcess rtdetr_process;
bool post_flag;
ov::Core core;
std::shared_ptr<ov::Model> model;
ov::CompiledModel compiled_model;
ov::InferRequest infer_request;
};
-
- 模型推理类初始化
首先我们需要初始化模型推理类,初始化相关信息:
- 模型推理类初始化
RTDETRPredictor::RTDETRPredictor(std::string model_path, std::string label_path,
std::string device_name, bool post_flag)
:post_flag(post_flag){
INFO("Model path: " + model_path);
INFO("Device name: " + device_name);
model = core.read_model(model_path);
pritf_model_info(model);
compiled_model = core.compile_model(model, device_name);
infer_request = compiled_model.create_infer_request();
rtdetr_process = RTDETRProcess(cv::Size(640, 640), label_path, 0.5);
}
在该方法中主要包含以下几个输入:
model_path:推理模型地址;label_path:模型预测类别文件;device_name:推理设备名称;post_flag:模型是否包含后处理,当post_flag = true时,包含后处理,当post_flag = false时,不包含后处理。-
- 图片预测API
这一步中主要是对输入图片进行预测,并将模型预测结果会知道输入图片上,下面是这阶段的主要代码:
- 图片预测API
cv::Mat RTDETRPredictor::predict(cv::Mat image){
cv::Mat blob_image = rtdetr_process.preprocess(image);
if (post_flag) {
ov::Tensor image_tensor = infer_request.get_tensor("image");
ov::Tensor shape_tensor = infer_request.get_tensor("im_shape");
ov::Tensor scale_tensor = infer_request.get_tensor("scale_factor");
image_tensor.set_shape({ 1,3,640,640 });
shape_tensor.set_shape({ 1,2 });
scale_tensor.set_shape({ 1,2 });
fill_tensor_data_image(image_tensor, blob_image);
fill_tensor_data_float(shape_tensor, rtdetr_process.get_input_shape().data(), 2);
fill_tensor_data_float(scale_tensor, rtdetr_process.get_scale_factor().data(), 2);
} else {
ov::Tensor image_tensor = infer_request.get_input_tensor();
fill_tensor_data_image(image_tensor, blob_image);
}
infer_request.infer();
ResultData results;
if (post_flag) {
ov::Tensor output_tensor = infer_request.get_tensor("reshape2_95.tmp_0");
float result[6 * 300] = {0};
for (int i = 0; i < 6 * 300; ++i) {
result[i] = output_tensor.data<float>()[i];
}
results = rtdetr_process.postprocess(result, nullptr, true);
} else {
ov::Tensor score_tensor = infer_request.get_tensor(model->outputs()[1].get_any_name());
ov::Tensor bbox_tensor = infer_request.get_tensor(model->outputs()[0].get_any_name());
float score[300 * 80] = {0};
float bbox[300 * 4] = {0};
for (int i = 0; i < 300; ++i) {
for (int j = 0; j < 80; ++j) {
score[80 * i + j] = score_tensor.data<float>()[80 * i + j];
}
for (int j = 0; j < 4; ++j) {
bbox[4 * i + j] = bbox_tensor.data<float>()[4 * i + j];
}
}
results = rtdetr_process.postprocess(score, bbox, false);
}
return rtdetr_process.draw_box(image, results);
}
上述代码的主要逻辑如下:首先是处理输入图片,调用定义的数据处理类,将输入图片处理成指定的数据类型;然后根据模型的输入节点情况配置模型输入数据,如果使用的是动态模型输入,需要设置输入形状;接下来就是进行模型推理;最后就是对推理结果进行处理,并将结果绘制到输入图片上。
5.2 模型数据处理类RTDETRProcess
-
- 定义RTDETRProcess
class RTDETRProcess
{
public:
RTDETRProcess() {}
RTDETRProcess(cv::Size target_size, std::string label_path = NULL, float threshold = 0.5,
cv::InterpolationFlags interpf = cv::INTER_LINEAR);
cv::Mat preprocess(cv::Mat image);
ResultData postprocess(float* score, float* bboxs, bool post_flag);
std::vector<float> get_im_shape() { return im_shape; }
std::vector<float> get_input_shape() { return { (float)target_size.width ,(float)target_size.height }; }
std::vector<float> get_scale_factor() { return scale_factor; }
cv::Mat draw_box(cv::Mat image, ResultData results);
private:
void read_labels(std::string label_path);
template<class T>
float sigmoid(T data) { return 1.0f / (1 + std::exp(-data));}
template<class T>
int argmax(T* data, int length) {
std::vector<T> arr(data, data + length);
return (int)(std::max_element(arr.begin(), arr.end()) - arr.begin());
}
private:
cv::Size target_size; // The model input size.
std::vector<std::string> labels; // The model classification label.
float threshold; // The threshold parameter.
cv::InterpolationFlags interpf; // The image scaling method.
std::vector<float> im_shape;
std::vector<float> scale_factor;
};
-
- 输入数据处理方法
cv::Mat RTDETRProcess::preprocess(cv::Mat image){
im_shape = { (float)image.rows, (float)image.cols };
scale_factor = { 640.0f / (float)image.rows, 640.0f / (float)image.cols};
cv::Mat blob_image;
cv::cvtColor(image, blob_image, cv::COLOR_BGR2RGB);
cv::resize(blob_image, blob_image, target_size, 0, 0, cv::INTER_LINEAR);
std::vector<cv::Mat> rgb_channels(3);
cv::split(blob_image, rgb_channels);
for (auto i = 0; i < rgb_channels.size(); i++) {
rgb_channels[i].convertTo(rgb_channels[i], CV_32FC1, 1.0 / 255.0);
}
cv::merge(rgb_channels, blob_image);
return blob_image;
}
-
- 预测结果数据处理方法
ResultData RTDETRProcess::postprocess(float* score, float* bbox, bool post_flag)
{
ResultData result;
if (post_flag) {
for (int i = 0; i < 300; ++i) {
if (score[6 * i + 1] > threshold) {
result.clsids.push_back((int)score[6 * i ]);
result.labels.push_back(labels[(int)score[6 * i]]);
result.bboxs.push_back(cv::Rect(score[6 * i + 2], score[6 * i + 3],
score[6 * i + 4] - score[6 * i + 2],
score[6 * i + 5] - score[6 * i + 3]));
result.scores.push_back(score[6 * i + 1]);
}
}
} else {
for (int i = 0; i < 300; ++i) {
float s[80];
for (int j = 0; j < 80; ++j) {
s[j] = score[80 * i + j];
}
int clsid = argmax<float>(s, 80);
float max_score = sigmoid<float>(s[clsid]);
if (max_score > threshold) {
result.clsids.push_back(clsid);
result.labels.push_back(labels[clsid]);
float cx = bbox[4 * i] * 640.0 / scale_factor[1];
float cy = bbox[4 * i + 1] * 640.0 / scale_factor[0];
float w = bbox[4 * i + 2] * 640.0 / scale_factor[1];
float h = bbox[4 * i + 3] * 640.0 / scale_factor[0];
result.bboxs.push_back(cv::Rect((int)(cx - w / 2), (int)(cy - h / 2), w, h));
result.scores.push_back(max_score);
}
}
}
return result;
}
此处对输出结果做一个解释,由于我们提供了两种模型的输出,此处提供了两种模型的输出数据处理方式,主要区别在于是否对预测框进行还原以及对预测类别进行提取,具体区别大家可以查看上述代码。
6. 预测结果展示
最后通过上述代码,我们最终可以直接实现RT-DETR模型的推理部署,RT-DETR与训练模型采用的是COCO数据集,最终我们可以获取预测后的图像结果,如图所示:

上图中展示了RT-DETR模型预测结果,同时,我们对模型图里过程中的关键信息以及推理结果进行了打印:
[INFO] This is an RT-DETR model deployment case using C++!
[INFO] Model path: E:\\Model\\RT-DETR\\RTDETR_cropping\\rtdetr_r50vd_6x_coco.onnx
[INFO] Device name: CPU
[INFO] Inference Model
[INFO] Model name: Model from PaddlePaddle.
[INFO] Input:
[INFO] name: image
[INFO] type: float
[INFO] shape: [?,3,640,640]
[INFO] Output:
[INFO] name: stack_7.tmp_0_slice_0
[INFO] type: float
[INFO] shape: [?,300,4]
[INFO] name: stack_8.tmp_0_slice_0
[INFO] type: float
[INFO] shape: [?,300,80]
[INFO] Infer result:
[INFO] class_id : 0, label : person, confidence : 0.928, left_top : [215, 327], right_bottom: [259, 468]
[INFO] class_id : 0, label : person, confidence : 0.923, left_top : [260, 343], right_bottom: [309, 460]
[INFO] class_id : 0, label : person, confidence : 0.893, left_top : [402, 346], right_bottom: [451, 478]
[INFO] class_id : 0, label : person, confidence : 0.796, left_top : [456, 369], right_bottom: [507, 479]
[INFO] class_id : 0, label : person, confidence : 0.830, left_top : [519, 360], right_bottom: [583, 479]
[INFO] class_id : 33, label : kite, confidence : 0.836, left_top : [323, 159], right_bottom: [465, 213]
[INFO] class_id : 33, label : kite, confidence : 0.805, left_top : [329, 64], right_bottom: [388, 85]
[INFO] class_id : 33, label : kite, confidence : 0.822, left_top : [282, 217], right_bottom: [419, 267]
[INFO] class_id : 0, label : person, confidence : 0.834, left_top : [294, 384], right_bottom: [354, 443]
[INFO] class_id : 33, label : kite, confidence : 0.793, left_top : [504, 195], right_bottom: [522, 214]
[INFO] class_id : 33, label : kite, confidence : 0.524, left_top : [233, 22], right_bottom: [242, 29]
[INFO] class_id : 33, label : kite, confidence : 0.763, left_top : [116, 178], right_bottom: [136, 190]
[INFO] class_id : 0, label : person, confidence : 0.601, left_top : [497, 380], right_bottom: [529, 479]
[INFO] class_id : 33, label : kite, confidence : 0.764, left_top : [460, 251], right_bottom: [478, 268]
[INFO] class_id : 33, label : kite, confidence : 0.605, left_top : [176, 236], right_bottom: [256, 257]
[INFO] class_id : 0, label : person, confidence : 0.732, left_top : [154, 380], right_bottom: [210, 420]
[INFO] class_id : 33, label : kite, confidence : 0.574, left_top : [221, 264], right_bottom: [342, 312]
[INFO] class_id : 33, label : kite, confidence : 0.588, left_top : [97, 316], right_bottom: [155, 359]
[INFO] class_id : 33, label : kite, confidence : 0.523, left_top : [171, 317], right_bottom: [227, 357]
[INFO] class_id : 33, label : kite, confidence : 0.657, left_top : [363, 120], right_bottom: [375, 129]
[INFO] class_id : 0, label : person, confidence : 0.698, left_top : [26, 341], right_bottom: [57, 425]
[INFO] class_id : 33, label : kite, confidence : 0.798, left_top : [242, 124], right_bottom: [263, 135]
[INFO] class_id : 33, label : kite, confidence : 0.528, left_top : [218, 178], right_bottom: [451, 241]
[INFO] class_id : 33, label : kite, confidence : 0.685, left_top : [430, 29], right_bottom: [449, 43]
[INFO] class_id : 33, label : kite, confidence : 0.640, left_top : [363, 120], right_bottom: [375, 129]
[INFO] class_id : 33, label : kite, confidence : 0.559, left_top : [161, 193], right_bottom: [171, 199]
7. 总结
在本项目中,我们介绍了OpenVINO C++ API 部署自带后处理的RT-DETR模型的案例,并结合该模型的处理方式封装完整的代码案例,实现了在 Intel 平台使用OpenVINO 加速深度学习模型,有助于大家以后落地RT-DETR模型在工业上的应用。
在下一篇文章《基于 OpenVINO Python C# 部署 RT-DETR 模型》中,我们将基于C# API接口,实现RT-DETR 模型的部署,并且基于开发的代码,对比不同平台的推理速度。如果大家有兴趣,可以先关注本项目代码仓库,获取项目实现源码。