一文读懂ElasticSearch中字符串keyword和text类型区别
1. 背景
ES2.*版本里面是没有这两个字段,只有string字段。
ES5.*及以后的版本,把string字段设置为了过时字段,引入text,keyword字段。
2.文本类型(text)关键字类型(keyword)区别
一切文本类型的字符串可以定义成 text文本类型或keyword关键字类型两种类型。
区别在于,text类型(文本类型)会使用默认分词器分词,也就是存入的数据会先进行分词,然后将分完词的词组存入索引,当然你也可以为他指定特定的分词器。
text类型检索不是直接给出是否匹配,而是检索出相似度,并按照相似度由高到低返回结果。这样会导致本来我们认为应该查询出来的数据有可能会查询不到。
如果定义成keyword类型(关键字类型),那么默认就不会对其进行分词,原样存储。当一个字段需要按照精确值进行过滤、排序、聚合等操作时, 就应该使用keyword类型.
keyword类型检索,直接被存储为了二进制,检索时我们直接匹配,不匹配就返回false。所以精确匹配可以用keyword。
那为什么我们有时候使用查询条件时,查询条件里加keyword和不加keyword得到结果有时候和预想当中的不一样呢?看下面例子
3.示例
准备数据
PUT /test/_doc/1
{
"name":"张三",
"address":"广东深圳",
"age":12
}
PUT /test/_doc/2
{
"name":"李四",
"address":"广西老表",
"age":13
}
查看该索引的mapping,可以看到ES默认对字符串类型数据的mapping既有text也有keyword类型
GET /test/_mapping

3.1、match查询不加keyword(match查询会分析查询条件,先将查询条件进行分词,然后查询,求并集)
GET /test/_search
{
"query": {
"match": {
"address":"广东深圳"
}
}
}
结果

查看索引中数据的分词结果 GET /test/_doc/1/_termvectors?fields=address

可以看到,这里的数据被ES分为了4个词分别是“广” ,“东”,“深”,“圳”。同样,第二条数据也被分为了“广” ,“西”,“南”,“宁”。这里可以理解为
keyword类型存储的数据为“广东深圳”(存储未分词的原始数据)
text类型存储的数据为“广” ,“东”,“深”,“圳”(存储分词后的)
之所以查到两条,原因是,match查询会将查询条件分词,
也就是查询条件(广东深圳)会被分词为“广” ,“东”,“深”,“圳”和原始数据“广东深圳”去查询,前面说了,字符串默认是既有text类型,又有keyword类型,没有加keyword,查询的就是text类型的,所以命中了两条数据
接下来加上keyword去查询看看结果会是怎么样
GET /test/_search
{
"query": {
"match": {
"address.keyword":"广东深圳"
}
}
}

不出意外,只命中了一条
接下来查询条件由广东深圳–>广东深,结果会怎样呢
GET /test/_search
{
"query": {
"match": {
"address.keyword":"广东深"
}
}
}

match查询不是会对查询条件分词吗?怎么一条都没有命中
原因是不管加没加keyword,只要是match查询,都会对查询条件进行分词,
但是加了keyword,ES只会去检索keyword类型里存储的数据,不加keyword,ES只会去检索text类型里存储的数据
3.2、term查询(不会分析查询条件,只有当词条和查询字符串完全匹配时才匹配,也就是精确查找)
term不加keyword
GET /test/_search
{
"query": {
"term": {
"address":"广东深圳"
}
}
}
结果:
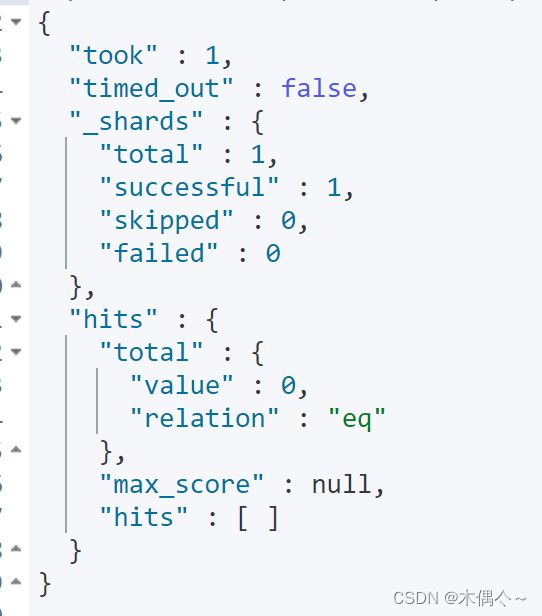
不出意料,一条也没有命中,原因是term不会分词,不加keyword,ES只会去检索text类型里面的数据,自然匹配不到
加上keyword后
GET /test/_search
{
"query": {
"term": {
"address.keyword":"广东深圳"
}
}
}

不出意料命中了一条。
4.总结:
1、match查询会分词(注意,也会保留一份未分词的原始数据去查询),term查询不会分词
2、查询条件加keyword和不加keyword,决定了查询的是存储在keyword类型里面的数据还是存储在text类型里面的数据
以上是对于加keyword和不加keyword查询的一些总结,初学ES,不对的地方欢迎各位多多指正