yolov8实例分割Tensorrt部署C++代码,engine模型推理示例和代码详解
接上文中的yolov8-aeg实例分割onnx转engine部分代码详解。本文对yolov8seg实例分割推理部分代码进行详细解不,此部分与常见的不同,后处理部分主要以矩阵处理为主。通过代码注释和示例运行,帮助大家理解和使用。
目录
- 代码
-
- infer_main.cpp
- utils.h
- CmakeLists.txt
- 运行示例
代码
文件夹内容如下。
主要包括主程序infer_main.cpp和用到的logging.h、utilus.h。其中logging.h在前篇博客已经讲过,附有代码,可参阅yolov8-aeg实例分割onnx转engine部分代码详解。utilus.h中仅包含两个函数的定义,比较简单不做赘述,可看相应代码。此处主要对含有预处理、推理和后处理等过程的infer_main.cpp代码进行解读,通过每行注释等形式。
infer_main.cpp
此代码为推理的主代码,包括预处理、推理和后处理等过程。
#include "NvInfer.h"
#include "cuda_runtime_api.h"
#include "NvInferPlugin.h"
#include "logging.h"
#include utils.h
#pragma once
#include CmakeLists.txt
在这里插入代码片
运行示例
打开文件夹终端,执行如下命令
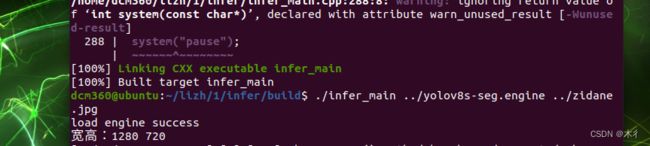
mkdir build
cd build
cmake ..
make -j32
./main ../yolov8s-seg.engine ../zidane,jpg
上述中的j32,可根据自己配置调整其数值。运行结果如下所示:
