背景
今天定位一个接口耗时问题,通过日志定位到在数据库查询完毕后,中间一段逻辑耗时很长有十几秒的样子,发现是循环中使用ArraysList中的contains方法,当循环数量级变得很大时,执行时间变得不可控。
代码示例
// 有5万个门店
List storeList = storeMapper.selectAll();
// 有十万个用户
List userList = userMapper.selectAll();
// 最坏情况循环5亿次
for (user : userList){
if (storeList.contains(user.getStoreCode())){
doSth();
}
}
1. 原理说明
1.1 ArrayList
ArrayList中contains()方法的实现过程:
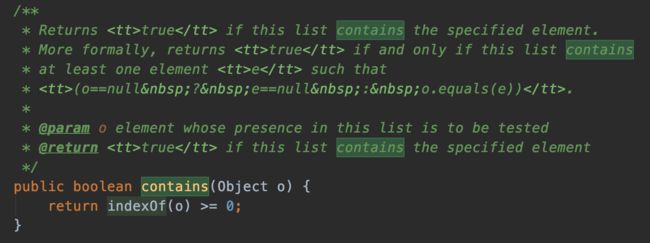
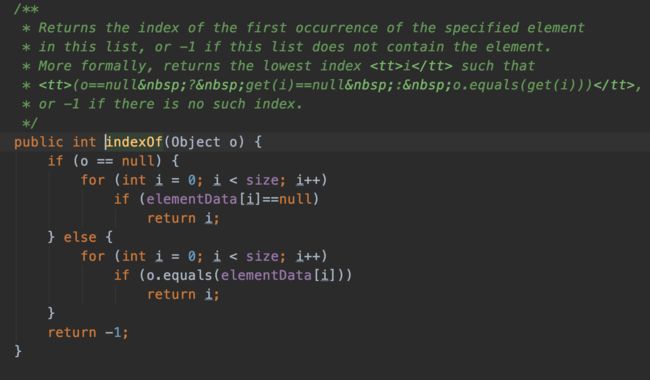
contains()方法调用了indexOf()方法,indexOf()具体实现如下。从源码可以看出,该方法通过遍历数据和比较元素的方式来判断是否存在给定元素。当ArrayList中存放的元素非常多时,这种实现方式来判断效率将非常低,后面通过实例来验证。
1.2 HashSet
既然ArrayList的contains()方法存在性能问题,那么就应该寻找改进的办法。这里推荐使用HashSet来代替ArrayList。下面介绍HashSet的contains()方法的实现过程:
HashSet将元素存放在HashMap中(HashMap的key)
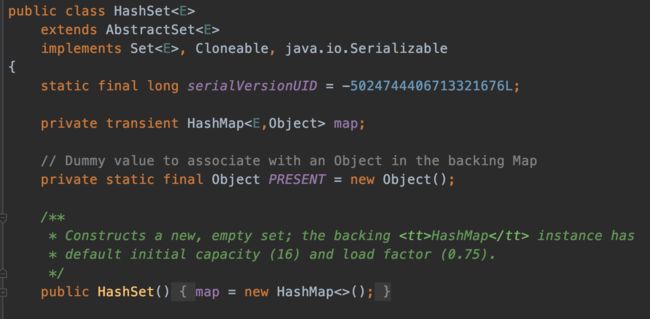
contains()方法调用HashMap的containsKey()方法
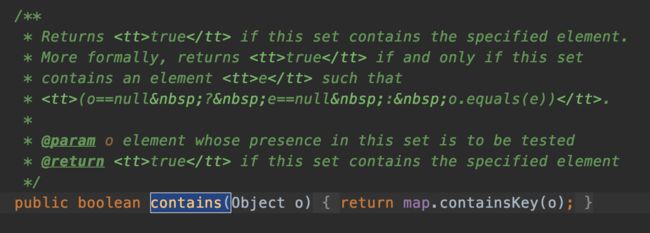
containsKey()方法调用getEntry()方法。在该方法中,首先根据key计算hash值,然后从HashMap中取出该hash值对应的链表(链表的元素个数将很少),再通过变量该链表判断是否存在给定值。这种实现方式效率将比ArrayList的实现方法效率高非常多。
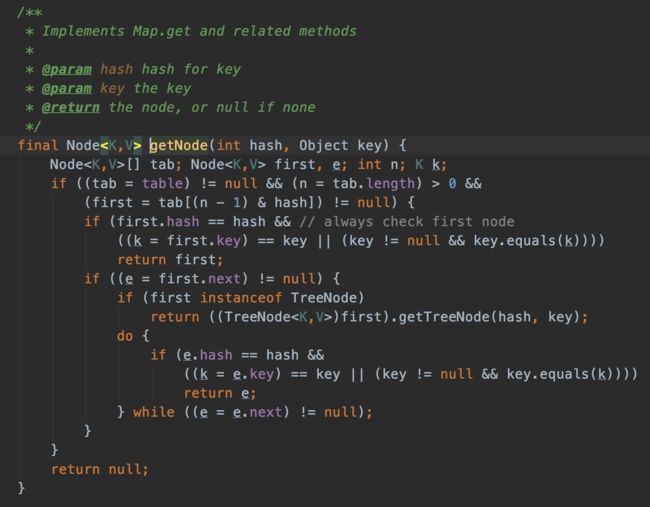
2. 实例验证
2.1 测试ArrayList
public static void main(String[] args) {
ArrayList arrayList = new ArrayList<>();
// 存入100000个数据
for (int i = 0; i < 100000; i++) {
arrayList.add("test" + i);
}
// 验证300000个数据(其中200000不存在)
long beginTime = System.currentTimeMillis(); for (int i = 0; i < 300000; i++) {
arrayList.contains("test" + i);
}
long endTime = System.currentTimeMillis();
System.out.println("cost time: " + (endTime - beginTime) + "ms");
}
打印结果:
cost time: 182210ms
2.2 测试HashSet
public static void main(String[] args) {
Set hashSet = new HashSet<>();
// 存入100000个数据
for (int i = 0; i < 100000; i++) {
hashSet.add("test" + i);
}
// 验证300000个数据(其中200000不存在)
long beginTime = System.currentTimeMillis();
for (int i = 0; i < 300000; i++) {
hashSet.contains("test" + i);
}
long endTime = System.currentTimeMillis();
System.out.println("cost time: " + (endTime - beginTime) + "ms");
}
打印结果:
cost time: 49ms
3. 总结
通过第二节的实例可以看出,使用ArrayList的contains()耗时是使用HashSet的contains()方法的30多倍。具体原因可以参考第一节中的原理分析。
本篇文章如有帮助到您,请给「翎野君」点个赞,感谢您的支持。
首发链接: https://www.cnblogs.com/lingyejun/p/17818584.html