通过 Elasticsearch 和 Go 使用混合搜索进行地鼠狩猎
作者:CARLY RICHMOND,LAURENT SAINT-FÉLIX
就像动物和编程语言一样,搜索也经历了不同实践的演变,很难在其中做出选择。 在本系列的最后一篇博客中,Carly Richmond 和 Laurent Saint-Félix 将关键字搜索和向量搜索结合起来,使用 Go 客户端在 Elasticsearch 中寻找地鼠(gopher)。

今天构建软件是对终生学习的承诺。 正如你从本系列前面的博客中看到的那样,Carly 最近开始使用 Go。
搜索经历了不同实践的演变。 在你自己的搜索用例之间做出决定可能很困难。 本系列所有代码均以第一部分中介绍的关键字和向量搜索示例为基础。 请继续阅读第 2 部分及第二部分的代码,了解本系列中的所有代码。 在本系列的第 2 部分中,我们将分享如何使用 Elasticsearch 和 Elasticsearch Go 客户端组合向量搜索和关键字搜索的示例。
先决条件
就像本系列的第一部分一样,此示例需要以下先决条件:
- 安装 Go 版本 1.13 或更高版本
- 使用 Go 文档中介绍的推荐结构和包管理创建您自己的 Go 存储库
- 创建你自己的 Elasticsearch 集群,其中填充了一组基于啮齿动物的页面,包括来自维基百科的我们友好的 Gopher:
连接到 Elasticsearch
提醒一下,在我们的示例中,我们将使用 Go 客户端提供的 Typed API。 为任何查询建立安全连接需要使用以下任一配置客户端:
- 云 ID 和 API 密钥(如果使用 Elastic Cloud)
- 集群 URL、用户名、密码和证书
连接到位于 Elastic Cloud 上的集群如下所示:
func GetElasticsearchClient() (*elasticsearch.TypedClient, error) {
var cloudID = os.Getenv("ELASTIC_CLOUD_ID")
var apiKey = os.Getenv("ELASTIC_API_KEY")
var es, err = elasticsearch.NewTypedClient(elasticsearch.Config{
CloudID: cloudID,
APIKey: apiKey,
Logger: &elastictransport.ColorLogger{os.Stdout, true, true},
})
if err != nil {
return nil, fmt.Errorf("unable to connect: %w", err)
}
return es, nil
}然后,client 连接可用于搜索,如后续部分所示。
如果你是使用自己部署的 Elasticsearch 集群,你可以参考文章 “Elasticsearch:运用 Go 语言实现 Elasticsearch 搜索 - 8.x”。
手动配置 boost 参数
当组合任何一组搜索算法时,传统方法是手动配置常量来增强每种查询类型。 具体来说,为每个查询指定一个因素,并将组合结果集与预期集进行比较,以确定查询的召回率。 然后我们重复几组因素并选择最接近我们所需状态的一组。

例如,可以通过在两种查询类型中指定 Boost 字段来将增强系数为 0.8 的单个文本搜索查询与系数较低的 0.2 的 knn 查询组合起来,如下例所示:
func HybridSearchWithBoost(client *elasticsearch.TypedClient, term string) ([]Rodent, error) {
var knnBoost float32 = 0.2
var queryBoost float32 = 0.8
res, err := client.Search().
Index("vector-search-rodents").
Knn(types.KnnQuery{
Field: "text_embedding.predicted_value",
Boost: &knnBoost,
K: 10,
NumCandidates: 10,
QueryVectorBuilder: &types.QueryVectorBuilder{
TextEmbedding: &types.TextEmbedding{
ModelId: "sentence-transformers__msmarco-minilm-l-12-v3",
ModelText: term,
},
}}).
Query(&types.Query{
Match: map[string]types.MatchQuery{
"title": {
Query: term,
Boost: &queryBoost,
},
},
}).
Do(context.Background())
if err != nil {
return nil, err
}
return getRodents(res.Hits.Hits)
}每个查询的 Boost 选项中指定的因子将添加到文档分数中。 通过比 knn 查询更大的因子增加匹配查询的分数,关键字查询的结果的权重更大。
手动提升的挑战是,特别是如果你不是搜索专家,则需要进行调整以找出导致所需结果集的因素。 这只是尝试随机值以查看什么能让你更接近所需结果集的情况。
倒数排序融合 - Reciprocal Rank Fusion
倒数排序融合 (RRF) 在 Elasticsearch 8.9 中的混合搜索技术预览版中发布。 它的目的是减少与调整相关的学习曲线,并减少尝试因素以优化结果集的时间。
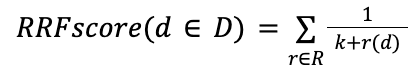
- D - 文档集
- R - 一组排名作为 1..|D| 的排列
- K - 通常默认设置为 60

使用 RRF,通过以下算法混合分数来重新计算文档分数:
score := 0.0
// q is a query in the set of queries (vector and keyword search)
for _, q := range queries {
// result(q) is the results
if document in result(q) {
// k is a ranking constant (default 60)
// rank(result(q), d) is the document's rank within result(q)
// range from 1 to the window_size (default 100)
score += 1.0 / (k + rank(result(q), d))
}
}
return score使用 RRF 的优点是我们可以利用 Elasticsearch 中合理的默认值。 排名常数 k 默认为 60。为了在大型数据集上搜索时返回文档的相关性和查询性能之间进行权衡,每个考虑的查询的结果集的大小限制为 window_size 的值,默认为 100 如文档中所述。
k 和 windows_size 也可以在 Go 客户端的 Rank 方法中的 Rrf 配置中进行配置,如下例所示:
func HybridSearchWithRRF(client *elasticsearch.TypedClient, term string) ([]Rodent, error) {
// Minimum required window size for the default result size of 10
var windowSize int64 = 10
var rankConstant int64 = 42
res, err := client.Search().
Index("vector-search-rodents").
Knn(types.KnnQuery{
Field: "text_embedding.predicted_value",
K: 10,
NumCandidates: 10,
QueryVectorBuilder: &types.QueryVectorBuilder{
TextEmbedding: &types.TextEmbedding{
ModelId: "sentence-transformers__msmarco-minilm-l-12-v3",
ModelText: term,
},
}}).
Query(&types.Query{
Match: map[string]types.MatchQuery{
"title": {Query: term},
},
}).
Rank(&types.RankContainer{
Rrf: &types.RrfRank{
WindowSize: &windowSize,
RankConstant: &rankConstant,
},
}).
Do(context.Background())
if err != nil {
return nil, err
}
return getRodents(res.Hits.Hits)
}结论
在这里,我们讨论了如何使用 Elasticsearch Go 客户端在 Elasticsearch 中组合向量搜索和关键字搜索。
查看 GitHub 存储库以获取本系列中的所有代码。 如果你还没有查看本系列中的所有代码,请查看第 1 部分和第 2 部分。
快乐地鼠狩猎!
原文:Using hybrid search for gopher hunting with Elasticsearch and Go — Elastic Search Labs