初始MySQL(五)(自我复制数据,合并查询,外连接,MySQL约束:主键,not null,unique,foreign key)
目录
表复制
自我复制数据(蠕虫复制)
合并查询
union all(不会去重)
union(会自动去重)
MySQL表的外连接
左连接
右连接
MySQL的约束
主键
not null
unique(唯一)
foreign key(外键)
表复制
自我复制数据(蠕虫复制)
#为了对某个sql语句进行效率测试,我们需要海量数据时,可以使用此法为表创建海量数据
-- 演示表的复制
CREATE TABLE my_tab01
( id INT,
`name` VARCHAR(32),
sal DOUBLE,
job VARCHAR(32),
deptno INT);
DESC my_tab01;
SELECT * FROM my_tab01;
-- 演示如何自我复制
-- 1.先把emp表记录复制到my_tab01
INSERT INTO my_tab01
(id, `name` ,sal,job,deptno)
SELECT empno,ename,sal,job,deptno FROM emp;
SELECT * FROM my_tab01;
-- 2.自我复制
INSERT INTO my_tab01
SELECT * FROM my_tab01;
SELECT * FROM my_tab01;
-- 如何删除掉一张表重复记录
-- 1.先创建一张表 my_tab02
-- 2.考虑去重
-- 如何删除掉一张表重复记录
-- 1.先创建一张表 my_tab02
CREATE TABLE my_tab02 LIKE emp; -- 这个语句 把emp表结构(列) ,
-- 复制到my_tab02,并没有复制数据
DESC my_tab02;
SELECT * FROM my_tab02
INSERT INTO my_tab02
SELECT *FROM emp
SELECT * FROM my_tab02;
-- 2.考虑去重
-- 思路:(1)先创建一个临时表 my_tmp,该表的结构和my_tab02一致
-- (2)把my_tab02的记录通过distinct关键字处理后,把记录复制到my_tmp
-- (3)清除掉my_tab02记录
-- (4)把my_tmp 表的记录复制到my_tab02
-- (5)drop掉 临时表my_tmp
-- (1)先创建一个临时表 my_tmp,该表的结构和my_tab02一致
CREATE TABLE my_tmp LIKE my_tab02
-- (2)把my_tab02的记录通过distinct关键字处理后,把记录复制到my_tmp
INSERT INTO my_tmp SELECT DISTINCT * FROM my_tab02;
-- (3)清除掉my_tab02记录
DELETE FROM my_tab02;
-- (4)把my_tmp 表中的记录复制到my_tab02
INSERT INTO my_tab02 SELECT * FROM my_tmp
-- (5)drop掉 临时表my_tmp
DROP TABLE my_tmp
SELECT * FROM my_tab02;
合并查询
介绍 有时在实际应用中,为了合并多个select语句的结果,可以使用集合操作符号 union , union all
union all(不会去重)
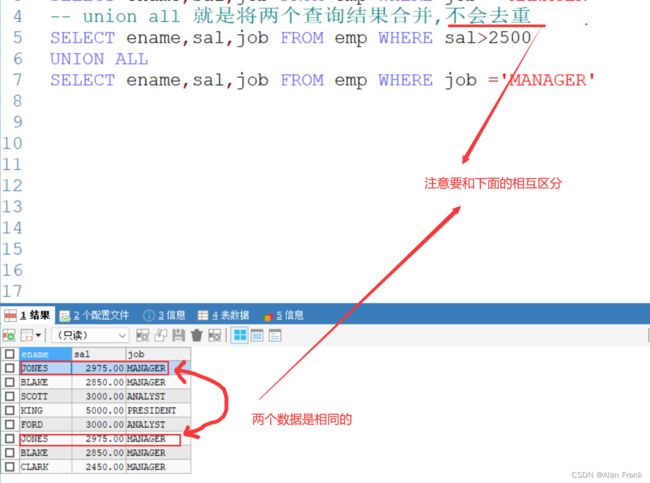
union(会自动去重)

MySQL表的外连接
# 创建stu
CREATE TABLE stu(
id INT,
`name` VARCHAR(32));
INSERT INTO stu VALUES(1,'jack'),(2,'tom'),(3,'kity'),(4,'nono');
SELECT * FROM stu;
#创建exam表
CREATE TABLE exam(
id INT,
grade INT);
INSERT INTO exam VALUES(1,56),(2,76),(11,8);
SELECT * FROM exam;
#笛卡尔集
SELECT * FROM stu,exam左连接
练习要求:显示所有人的成绩,如果没有成绩,也要显示该姓名和id号,成绩显示为空
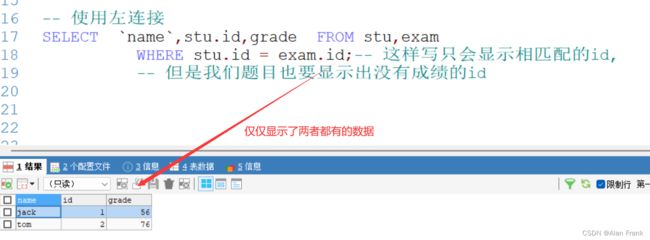
我们可以用左连接(我们以左边的表为基准去右边的表去找,找到一起显示,找不到显示NULL)

-- 改成左外连接,显示所有人的成绩,如果没有成绩,也要显示该人的姓名和id号,
-- 成绩显示空
-- select ... from 表1 left join 表2 on 条件
-- 上面的表1是左表,表2是右表
SELECT `name`,stu.id,grade FROM stu LEFT JOIN exam
ON stu.id = exam.id; -- 一左边为基准去右边找,找到显示,找不到显示NULL
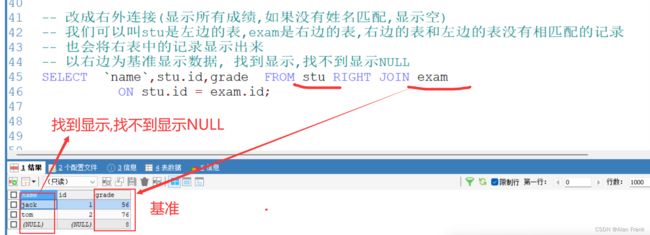
右连接
再来一个练习
列出部门名称和那些部门的员工信息(名字和工作), 同时列出那些没有员工的部门名
-- 右外连接 select ... from 表1 right join 表2 on 条件
SELECT ename ,dname
FROM emp RIGHT JOIN dept
ON emp.deptno = dept.deptno
ORDER BY dnameMySQL的约束
主键
在创建表的时候使用 基本语法: 字段名 字段类型 primary key
用于唯一的标示表行的数据,当定义主键约束后,该行的值不能重复

主键使用的细节
(1) primary key 不能重复而且不能为空
INSERT INTO t17 VALUES(NULL,'nb','nb克拉斯') -- Column 'id' cannot be null(2)-- 一张表中最多只能有一个主键,但是可以设置复合主键
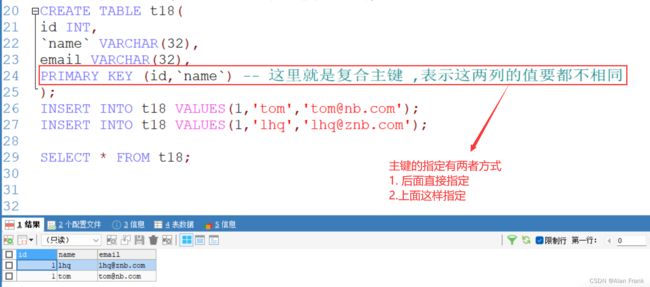
-- 一张表中最多只能有一个主键
CREATE TABLE t18(
id INT PRIMARY KEY,
`name` VARCHAR(32) PRIMARY KEY,
email VARCHAR(32));
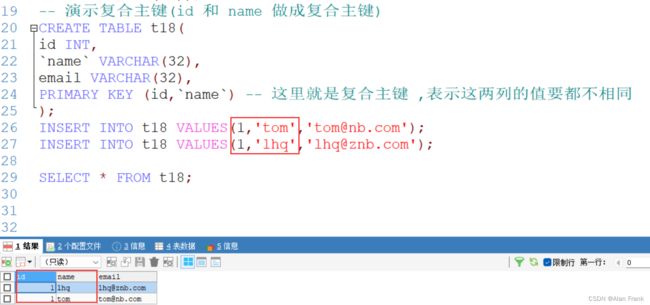
-- 演示复合主键(id 和 name 做成复合主键)
CREATE TABLE t18(
id INT,
`name` VARCHAR(32),
email VARCHAR(32),
PRIMARY KEY (id,`name`) -- 这里就是复合主键 ,表示这两列的值要都不相同
);
INSERT INTO t18 VALUES(1,'tom','[email protected]');
INSERT INTO t18 VALUES(1,'lhq','[email protected]');
SELECT * FROM t18;
只有设置复合主键中的值都相同的时候会报错误
desc来查看主键

not null
如果在列上定义了not null ,那么当插入数据时,必须为列提供数据
字段 字段类型 NOT NULL

说明我们输入id的时候不可以输入NULL值
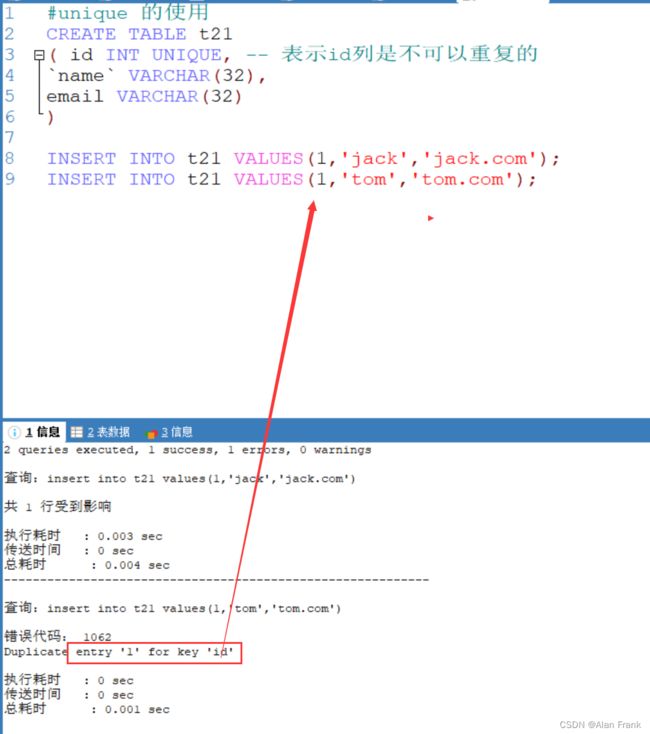
unique(唯一)
当定义了唯一约束后,该列值是不能重复的
字段名 字段类型 unique
下面重复的id时候报错误的
unique使用细节
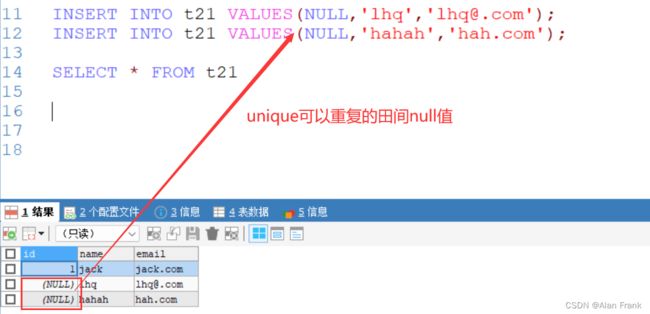
-- 1.如果没有指定not null ,则unique 字段可以有多个null
-- 如果一个列(字段),是 unique not null 使用效果类似于 primary key
--2.一张表中可以有多个unique字段

foreign key(外键)
啥叫外键?

用韩老师画的这张图就是说,我现在班级表设置成主表,id有主键约束,学生表中的class_id正好和班级表的id一样,我们将学生表中的class_id指向班级表的id,这两个表之间就产生了联系,我再往学生表中添加信息,如果class_id在主表的id中不存在,那就添加不上去,这就是我们的外键约束
用于定义主表和从表之间的关系: (1)外键约束要定义在从表上, (2)主表则必须具有主键约束或者unique约束,(3)当定义外键约束后,要求外键列数据在主表的主键列存在或为null

建立外键的时候,表的引擎必须是innodb才行,别的是建不起来的
就是在这

创建两个表
设置外键约束的时候,设置在从表中
#外键演示
-- 创建 主表 my_class
CREATE TABLE my_class(
id INT PRIMARY KEY,
`name` VARCHAR(32) NOT NULL DEFAULT '');
-- 创建 从表 my_stu
CREATE TABLE my_stu(
id INT PRIMARY KEY,
`name` VARCHAR(32) NOT NULL DEFAULT '',
class_id INT,
-- 下面指定外键关系
FOREIGN KEY (class_id) REFERENCES my_class(id));
一旦主外键的关系形成了,那么就不能随意删除
但是可以先删除完从表的,当主表中主键没有外键指向他了,那主键的这一行也是可以删除的