LeetCode刷题笔记 --- python
目录
- 一、python交换两个变量的值
-
- 1.1 使用tuple
- 1.2 使用临时变量temp
- 二、python中‘/’和‘//’区别
- 三、python列表的使用
-
- 3.1 列表的基本操作
- 3.2 列表实现栈操作
- 3.3 列表实现排序
- 3.4 列表的算法效率
- 四、python字典
-
- 4.1 python字典的使用
- 4.2 检查字典中是否存在键和值
- 4.3 字典中的get()方法
- 4.4 字典中的setdefault()方法
- 4.5 删除字典元素
- 五、python实现三目运算符(if else 在同一行)
- 六、python修改字符串的方法
- 七、python 双向队列(deque)
-
- 7.1 常用方法
- 7.2 时间复杂度:
- 7.3 相关代码案例:
- 八、python中的最大值和最小值
- 九、python经典报错
-
- 9.1 UnboundLocalError: local variable 'xxx' referenced before assignment
- 十、python中集合set的使用详解
-
- 10.1 set的作用
- 10.1 set的初始化
- 10.2 set集合的增删改查操作
- 10.3 常见使用注意事项
一、python交换两个变量的值
1.1 使用tuple
x,y = y,x
print(x)
print(y)
说明:y,x 的返回值是一个tuple,所以变换变量可以看做把一个tuple的值赋值给另一个tuple
1.2 使用临时变量temp
x = 1
y = 2
temp = x
x = y
y = temp
print(x)
print(y)
二、python中‘/’和‘//’区别
python中‘/’表示浮点数除法,返回浮点结果
6 / 4 =1.5
python中 ‘//’表示整数除法,返回不大于结果的一个最大的整数
6 // 4 = 1
三、python列表的使用
3.1 列表的基本操作
list2 = ["a", "b", "c", "d"] # 定义列表
l = list() # 新建空列表
l.append(1) # 添加元素
l.append(2)
l.append(3)
l.append(4)
# l.insert(index, obj) 将指定对象插入列表的指定位置
l.insert(0,"first") # 在位置为0的地方插入字符串"first"
# 在列表末尾一次性追加另一个序列中的多个值(用新列表扩展原来的列表)
l.extend([6,7])
# 统计某个元素在列表中出现的次数
l.count(obj)
del l[2] # 删除元素
l[0] # 查看元素
l[1:3] # 查看元素
3.2 列表实现栈操作
使用列表的pop()方法 可以把列表当做栈使用
# 出栈
l.pop([index=-1]) # 移除列表中的一个元素(默认最后一个元素),并且返回该元素的值
# 进栈
l.append()
# 查看栈顶 即查看列表中的最后一个元素
l[-1]
3.3 列表实现排序
list.sort(cmp=None, key=None, reverse=False)
参数说明:
- cmp – 可选参数, 如果指定了该参数会使用该参数的方法进行排序。
- key – 主要是用来进行比较的元素,只有一个参数,具体的函数的参数就是取自于可迭代对象中,指定可迭代对象中的一个元素来进行排序。
- reverse – 排序规则,reverse = True 降序, reverse = False 升序(默认)。
aList = ['123', 'Google', 'Runoob', 'Taobao', 'Facebook'];
aList.sort();
print("List : ")
print(aList)
# 获取列表的第二个元素
def takeSecond(elem):
return elem[1]
# 列表
random = [(2, 2), (3, 4), (4, 1), (1, 3)]
# 指定第二个元素排序
random.sort(key=takeSecond)
# 上面sort语句也可以使用lambda表达式的方式实现
# random.sort(key=lambda x:x[1])
# 输出类别
print('排序列表:')
print(random)
3.4 列表的算法效率
列表的算法效率
可以采用时间复杂度来衡量:
index() O(1)
append O(1)
pop() O(1)
pop(i) O(n)
insert(i,item) O(n)
del operator O(n)
iteration O(n)
contains(in) O(n)
get slice[x:y] O(k)
del slice O(n)
set slice O(n+k)
reverse O(n)
concatenate O(k)
sort O(nlogn)
multiply O(nk)
O括号里面的值越大代表效率越低
四、python字典
4.1 python字典的使用
d = {} # 新建空字典
# d = dict() # 新建空字典
d[1] = 2 # 添加元素
d[3] = 4
d.update({'a':'b','c':'d'}) # 添加元素
print(d)
output:
{1: 2, 3: 4, 'a': 'b', 'c': 'd'}
4.2 检查字典中是否存在键和值
data in dict.keys()
data in dict.values()
data in dict 等价于 data in dict.keys()
如果要检查一个值是否为字典中的键,就可以将关键字in (或not in)作用于该字典本身
4.3 字典中的get()方法
在访问一个键的值之前,检查该键是否存在于字典中,这很麻烦。
dict.get()方法有两个参数,分别为键和键不存在时返回的备用值
dict.get('key',deafaultValue)
4.4 字典中的setdefault()方法
当键不存在时增加一个键并设置一个默认值返回该默认值
当键存在时直接返回键的值
spam = {'name': 'hjy', 'age': 5}
print(spam.setdefault('color', 'black'))
print(spam)
print(spam.setdefault('name', 'zhangsan'))
print(spam)
black
{'name': 'hjy', 'age': 5, 'color': 'black'}
hjy
{'name': 'hjy', 'age': 5, 'color': 'black'}
4.5 删除字典元素
能删单一的元素也能清空字典,清空只需一项操作。
显示删除一个字典用del命令,如下实例:
tinydict = {'Name': 'Zara', 'Age': 7, 'Class': 'First'}
del tinydict['Name'] # 删除键是'Name'的条目
tinydict.clear() # 清空字典所有条目
del tinydict # 删除字典
print "tinydict['Age']: ", tinydict['Age']
print "tinydict['School']: ", tinydict['School']
output:
tinydict['Age']:
Traceback (most recent call last):
File "test.py", line 10, in <module>
print "tinydict['Age']: ", tinydict['Age']
NameError: name 'tinydict' is not defined
五、python实现三目运算符(if else 在同一行)
c语言版本:条件?a:b【解释:如果条件为真,则结果为a 否则,结果为b】
python实现三目运算符
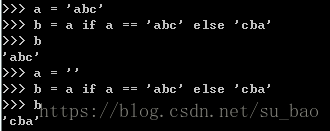
上图可以看出,python实现了和三目运算符差不多的功效,方法是if else 在同一行。
六、python修改字符串的方法
在Python中,字符串是不可变类型,即无法直接修改字符串的某一位字符。
如果字符串类型修改值会报错(如下)
错误 TypeError: ‘str’ object does not support item assignment
翻译:TypeError:“unicode”对象不支持项分配
因此改变一个字符串的元素需要新建一个新的字符串。
将字符串转换成列表后修改值,然后用join组成新字符串
>>> s='abcdef' #原字符串
>>> s1=list(s) #将字符串转换为列表
>>> s1
['a', 'b', 'c', 'd', 'e', 'f'] #列表的每一个元素为一个字符
>>> s1[4]='E' #将列表中的第5个字符修改为E
>>> s1[5]='F' #将列表中的第5个字符修改为E
>>> s1
['a', 'b', 'c', 'd', 'E', 'F']
>>> s=''.join(s1) #用空串将列表中的所有字符重新连接为字符串
>>> s
'abcdEF' #新字符串
七、python 双向队列(deque)
deque (double-ended queue,双向队列)是以双向链表的形式实现的 (Well, a list of arrays rather than objects, for greater efficiency)。双向队列的两端都是可达的,但从查找队列中间的元素较为缓慢,增删元素就更慢了,deque属于高性能的数据结构之一。
7.1 常用方法
- append 队列右边添加元素
- appendleft 队列左边添加元素
- clear 清空队列中的所有元素
- count 返回队列中包含value的个数
- extend 队列右边扩展,可以是列表、元组或字典,如果是字典则将字典的key加入到deque
- extendleft 同extend,在左边扩展
- pop 移除并返回队列右边的元素
- popleft 移除并返回队列左边的元素
- remove(value) 移除队列第一个出现的元素 reverse 队列的所有元素进行反转
- rotate(n) 对队列数进行移动
- len(队列名) 获取队列长度
7.2 时间复杂度:
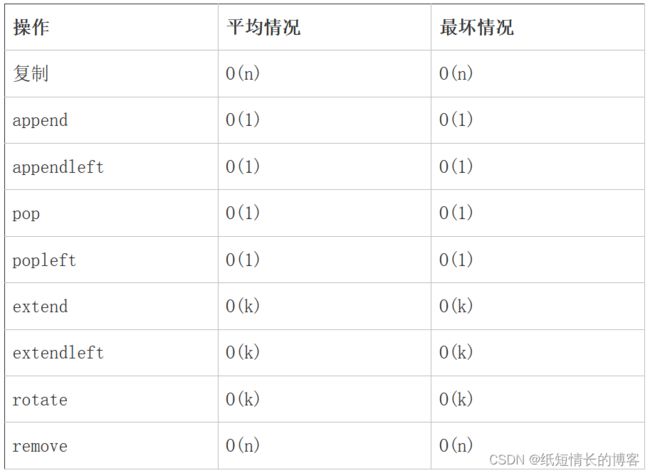
7.3 相关代码案例:
from collections import deque
que = deque()
que.append(1)
que.append(2)
que.appendleft(3)
len(que)
import collections
que = collections.deque([1,3,4]) # 初始化
八、python中的最大值和最小值
应用场景
有时候需要初始化一些变量,让其表示一个尽可能大的值或者尽可能小的值。
代码在这里插入代码片
max_value = float('inf')
min_value = float('-inf')
九、python经典报错
9.1 UnboundLocalError: local variable ‘xxx’ referenced before assignment
- 翻译 :赋值前引用的局部变量
- 修改:根据实际需求可以把’xxx’修改成全局变量,如:变量path改为变量self.path
十、python中集合set的使用详解
在python3中按数据类型的可变与不可变大致分为如下几种类型。
- 不可变数据(3 个):Number(数字)、String(字符串)、Tuple(元组);
- 可变数据(3 个):List(列表)、Dictionary(字典)、Set(集合)。
10.1 set的作用
- python中,用set来表示一个无序不重复元素的序列。set的只要作用就是用来给数据去重。
- 可以使用大括号 { } 或者 set() 函数创建集合,但是注意如果创建一个空集合必须用 set() 而不是 {},因为{}是用来表示空字典类型的
10.1 set的初始化
s = set() # 空set的初始化
print(type(s))
s = {} # 空字典的初始化
print(type(s))
d1 = {'x': 1, 'y': 2} # 非空字典的初始化
print(d1['x'])
person ={"student","teacher","babe",123,321,123} #同样各种类型嵌套,可以赋值重复数据,但是存储会去重
print(type(person))
print(len(person)) #存放了6个数据,长度显示是5,存储是自动去重.
print(person) #但是显示出来则是去重的
output:
<class 'set'>
<class 'dict'>
<class 'set'>
5
{321, 'student', 'babe', 'teacher', 123}
10.2 set集合的增删改查操作
#1.给set集合增加数据
person ={"student","teacher","babe",123,321,123}
person.add("student") #如果元素已经存在,则不报错,也不会添加,不会将字符串拆分成多个元素,去别update
print(person)
person.add((1,23,"hello")) #可以添加元组,但不能是list
print(person)
'''
{321, 'babe', 'teacher', 'student', 123}
{(1, 23, 'hello'), 321, 'babe', 'teacher', 'student', 123}
'''
person.update((1,3)) #可以使用update添加一些元组列表,字典等。但不能是字符串,否则会拆分
print(person)
person.update("abc")
print(person) #会将字符串拆分成a,b,c三个元素
'''
{321, 1, 3, 'teacher', (1, 23, 'hello'), 'babe', 'student', 123}
{321, 1, 3, 'b', 'c', 'teacher', (1, 23, 'hello'), 'a', 'babe', 'student', 123}
'''
#2.从set里删除数据
person.remove("student")#按元素去删除
print(person)
#print("student")如果不存在 ,会报错。
'''
{321, 1, 3, 'c', 'b', (1, 23, 'hello'), 'teacher', 'babe', 'a', 123}
'''
person.discard("student")#功能和remove一样,好处是没有的话,不会报错
person.pop() #在list里默认删除最后一个,在set里随机删除一个。
print(person)
'''
{1, 3, (1, 23, 'hello'), 'teacher', 'b', 'a', 'babe', 123, 'c'}
'''
#3.更新set中某个元素,因为是无序的,所以不能用角标
#所以一般更新都是使用remove,然后在add
#4.查询是否存在,无法返回索引,使用in判断
if "teacher" in person:
print("true")
else:
print("不存在")
'''
true
'''
#5.终极大招:直接清空set
print(person)
person.clear()
print(person)
'''
set()
'''
10.3 常见使用注意事项
#1.set对字符串也会去重,因为字符串属于序列。
str1 = set("abcdefgabcdefghi")
str2 = set("abcdefgabcdefgh")
print(str1,str2)
print(str1 - str2) #-号可以求差集
print(str2-str1) #空值
#print(str1+str2) #set里不能使用+号
====================================================================
{'d', 'i', 'e', 'f', 'a', 'g', 'b', 'h', 'c'} {'d', 'e', 'f', 'a', 'g', 'b', 'h', 'c'}
{'i'}
set()