Graph Neural Prompting with Large Language Models
动机:
1LLM包含大量的参数和它们需要大量的计算资源。
2现存的方法仍然表现出语言建模在准确捕获和返回基础知识方面的固有局限性。
存在问题以及解决方法:
1LLM在下游工作中返回知识仍存在局限性\面临着精确捕捉准确的事实知识的限制:
我的理解是对于多条信息叠加的问题难以捕捉正确的事实知识。
1用KGs辅助回答,但用的是定制模型。
2用KGs辅助LLM需要定制融合模型不够通用:
1用预训练过的LLM联合KGs
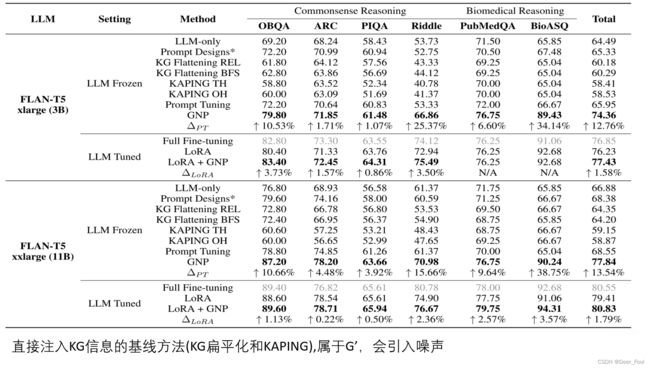
3直接将KGs三元组输入至已预训练过的LLM会引入大量噪声(无效信息)(存在问题5)(算法模型具体定义.2方法论.3GNP.1GNN Encoder):
1(本文工作)一种插件(GNP)将已预训练的LLM直接从KG中学习有用信息(降噪)
4LLM大量参数导致难以适应下游任务:
解决方向:减轻密集训练依赖性并减少计算开销
1引入了软提示,以调节下游任务的预训练LLM
2利用KGs的事实知识,以提高LLM适应下游任务能力,同时受益于通过使用预先培训的法LLM规避繁重的训练开销。
5用Subgraph Retrieval来提取相关三元组存在噪声(无效信息)(存在问题3):
1(本文工作)用GNP中的GNN从KGs识别有益的知识,提供给LLM
现有工作:
1Fine-Tune下游任务:
1Lora微调参数
2Frozen参数,并添加新的可训练参数(解决模型大小的增加和培训资源依赖性的加剧问题)
2联合KGs的方法:
1直接将KGs三元组输入至已预训练过的LLM(存在问题3)(与现有工作4.1一样)
2用插件(本文为GNP)让已训练过的LLM学习KGs中的有用知识
3KGs可以通过提供背景知识来增强语言建模:
1将KG集成到LLM的预训练阶段:
1用定制融合模型将KGs与LLM的预训练联合
2用LLM为KGs中的triplets and the paired sentences进行预训练以达到目标
2用KG来辅助用于问题回答的LLM:
1KG可以用图结构支撑关于实体的推理
4KG entity and relation embeddings的方法:
1用知识图来提取相关三元组,三元组对应于输入问题,期望直接将它们馈送到LLM中是有益的,但存在噪声(无效信息)(存在问题3)(存在问题5)(与现有工作2.1一样)
5多项选择题回答方法:
1Prompt LLM 将C 可选上下文(有无取决于开闭卷)、Q 问题、A选项集合串联为输入文本X;将Prompt P连接到X前端
6下游任务训练:
1标准最大似然损失+交叉熵损失![]()
7Prompt形式:
1hard prompt 文本输入形式
2soft prompt 可学习嵌入向量形式:
(本文工作)GNP将KGs的结构信息,事实信息encode soft prompt P,可与X token embedding 连接。
GNP具体工作:
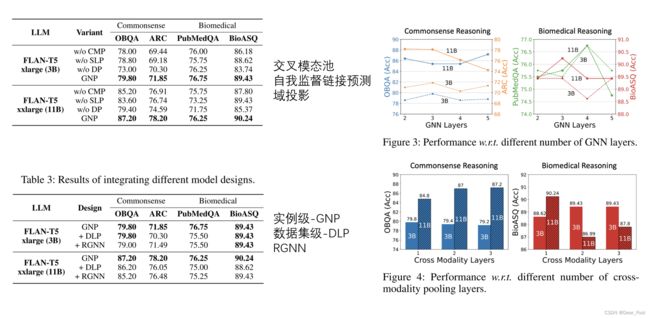
1、GNP对KGs信息进行Encoder,得到Graph Prompt,Graph Prompt是一个Embedding Vector;
2、跨模态池模块用来在XX寻找与文本输入最相关的节点进行Embedding,将这些节点Embedding整合为一个Graph-level Embedding;
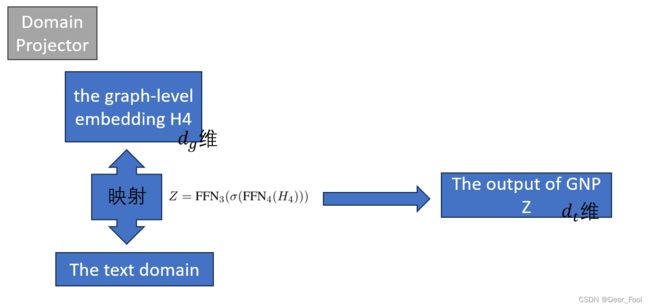
3、用域投影(domain projector)降低Graph domain与Text domain之间的差异;
4、self-supervised link prediction objective是用自监督方式捕获图知识,增强实体之间关系的模型理解。
结构图:
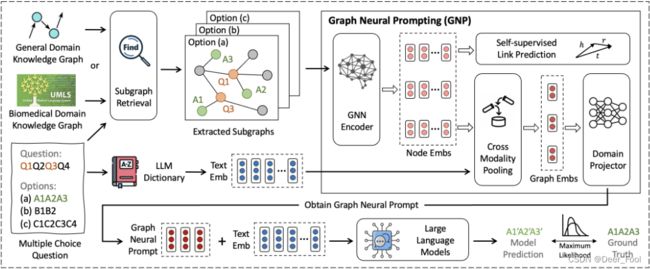
给定一个多项选择题,我们首先根据问题中的实体和选项从知识图谱中检索子图。然后,我们开发图形神经提示(GNP)来编码相关的事实知识和结构信息,以获得图形神经提示。GNP包含各种设计,包括GNN,跨模态池模块,域投影仪和自监督链路预测目标。之后,获得的图形神经提示与输入文本嵌入一起发送到LLM进行推理。我们利用标准的最大似然目标进行下游任务适应,而LLM则根据不同的实验设置保持冻结或调整。
算法模型具体定义:
1模型准备:
1多项选择题回答
给定一个问题Q,一组答案选项![]() ,以及一个可选的上下文C(取决于开卷或闭卷),任务是设计一个具有参数Θ的机器学习模型FΘ,该模型选择回答问题的最佳选项。这里K表示答案选项的总数,ak表示第k个答案选项。真值标签y ∈ A是Q的正确答案。此外,我们使用知识图G来提供丰富的知识,并协助模型回答问题。
,以及一个可选的上下文C(取决于开卷或闭卷),任务是设计一个具有参数Θ的机器学习模型FΘ,该模型选择回答问题的最佳选项。这里K表示答案选项的总数,ak表示第k个答案选项。真值标签y ∈ A是Q的正确答案。此外,我们使用知识图G来提供丰富的知识,并协助模型回答问题。
2知识图
被定义为G =(E,R,T),其中E是实体的集合,R是关系的集合。T是事实三元组{(eh,r,et)} ∈ E ×R× E的集合,其中eh表示头实体,r是关系,et表示尾实体。
2方法论:
1prompt LLM 回答问题:
1多项选择题回答方法:
1Prompt LLM 将C 可选上下文(有无取决于开闭卷)、Q 问题、A选项集合串联为输入文本X;将Prompt P连接到X前端
2下游任务训练:
1标准最大似然损失+交叉熵损失![]()
3Prompt形式:
1hard prompt 文本输入形式
2soft prompt 可学习嵌入向量形式:
GNP将KGs的结构信息,事实信息encode soft prompt P,可与X token embedding 连接。(本文工作)

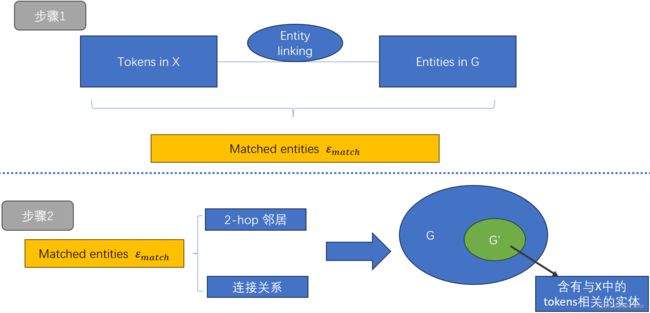
2子图检索:
为了在输入文本标记X与拥有数百万节点的庞大知识图G之间进行语义对齐
![]() :X token 与G entities 匹配的一组匹配entities
:X token 与G entities 匹配的一组匹配entities
通过![]() entities 的2-hop 邻居+关系搜索形成子图G'
entities 的2-hop 邻居+关系搜索形成子图G'
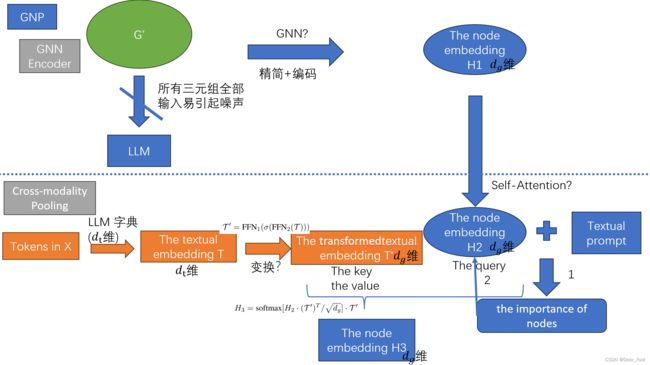
3GNP:
1GNN Encoder
直接将实体三元组(具体是啥?)输入LLM模型中会引入噪声,阻碍LLM模型集中于关键信息。
![]() 为标准的图注意力网络。标准的图注意力网络作为GNN编码器。
为标准的图注意力网络。标准的图注意力网络作为GNN编码器。
2Cross-modality Pooling
为了识别与问题相关的最相关的节点,并将节点嵌入整合为一个整体的图形级表示。
1、把H1经过自注意力机制层变成了Node Embs。
2、利用文本提示来计算图中节点的重要性。
3、utilize the dictionary in the LLM to obtain the text embeddings T
4、applying a transformation to the text embeddings T and obtain the transformed text embedding T′
![]()
5、calculate the crossmodality attention using H2 and T′
![]() H2作为查询,T '作为键和值
H2作为查询,T '作为键和值
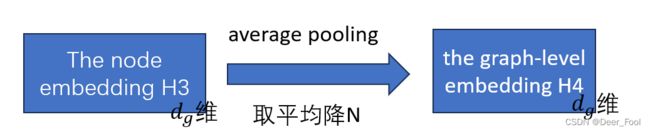
6 H3取平均降N得H4(the graph-level embedding)
3Domain Projector
 iction
iction
各种关系:
1
a question Q, the optional context C, and the answer options A
将问题Q、可选上下文C、答案选项A串联标记为一个输入文本标记序列X
将设计的Prompt P连接到X前部
2
the node embeddings H1
pre-trained entity embeddings
a holistic graphlevel representation
node embeddings obtained after calculating self-attention H2
the text embeddings
the transformed text embedding T′
T'与H2维度一致
the final node embeddings obtained with cross-modality attention considered H3
{
the graph-level embedding by average pooling the node embeddings H3 in G′
the graph-level embedding that takes into account the node significance in G′ H4
}
用预训练embedding(从哪里来的不知道)初始化H1;
利用的东西:

评价:
好水句:
1Large Language Models (LLMs) have shown remarkable generalization capability with exceptional performance in various language modeling tasks--夸LLM表现好
2LLMs still exhibit inherent limitations in precisely capturing and returning grounded knowledge.--说LLM的局限性
3Extensive experiments on multiple datasets demonstrate the superiority of GNP on both commonsense and biomedical reasoning tasks across different LLM sizes and settings.-跨方法性能好
学到了:
1LLM在精确捕获和返回知识方面仍然表现出局限性。
为什么有GNP?/GNP的优势(个人拙见)
1、这个方法利用了KG,而传统fine-tune可能不能直接利用图的知识
2、Prompt Tune可能在某些方面表现不如GNP