Pytorch Kaggle房价预测
超详解pytorch实战Kaggle比赛:房价预测
大佬写的太好了,转载记录一下
详解pytorch实战Kaggle比赛:房价预测
| 教程名称 | 教程地址 |
|---|---|
| 机器学习/深度学习 | 【李宏毅】机器学习/深度学习国语教程(双语字幕) |
| 生成对抗网络 | 【李宏毅】生成对抗网络国语教程(双语字幕) |
目录
- 前言
- 一、获取和读取数据集
- 二、数据集预处理
- 三、训练模型
- 四、K折交叉验证
- 五、模型选择
- 六、预测并正在kaggle提交结果
前言
这是pytorch学习的小实践,这个比赛的数据用了79个解释性变量(几乎)描述了爱荷华州埃姆斯市住宅的方方面面,从而预测房价最终价格。
一、获取和读取数据集
1_导入
# 不导入会产生的问题参考:https://blog.csdn.net/qq_43374681/article/details/115469240
import os
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
# Matplotlib是Python的一个绘图库,是Python中最常用的可视化工具之一
%matplotlib inline
import torch
# torch.nn是为神经网络设计的模块化接口。构建于autograd之上,可以用来定义和运行神经网络。
import torch.nn as nn
# NumPy是Python语言的一个扩充程序库。支持高级大量的维度数组与矩阵运算,此外也针对#数组运算提供大量的数学函数库。
# Pandas是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。Pandas 纳##入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。Pandas提#供了大量能使我们快速便捷地处理数据的函数和方法。
import numpy as np
import pandas as pd```
# 可以添加自己写好的模块路径
import sys
sys.path.append("..")
# dcj_pytorch包里有经常会用到的函数模块
import dcj_pytorch as d21

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
2_(32 bit 浮点CPU:torch.FloatTensor,GPU:torch.cuda.FloatTensor)
# 输出torch版本号
print(torch.__version__)
# 设置pytorch中默认的浮点类型
torch.set_default_tensor_type(torch.FloatTensor)
- 1
- 2
- 3
- 4
3_读取数据
# 使用pandas读取两个文件
train_data = pd.read_csv('../dohand/data/kaggle_house/train.csv')
test_data = pd.read_csv('../dohand/data/kaggle_house/test.csv')
- 1
- 2
- 3
4_输出训练与测试数据集形状
# 训练数据集包括1460个样本、80个特征和1个标签
# print(train_data.shape)
# 测试数据集包括1459个样本和80个特征,需要将测试数据集中每个样本的标签预测出来
# print(test_data.shape)
- 1
- 2
- 3
- 4
5_前4个样本的前4个特征、后两个特征和最后一个列的标签(saleprice)
# 输出0到4行的第0,1,2,3,-3,-2,-1列
# print(train_data.iloc[0:4, [0, 1, 2, 3, -3, -2, -1]])
- 1
- 2
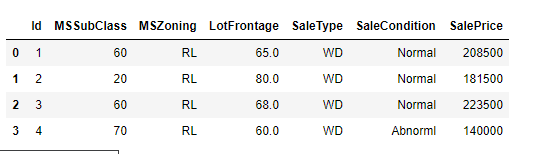
6_第一个特征是ID,他能帮助模型记住每个训练样本,但难以推广到测试样本,所以我们不用他来训练,我们将所有的训练数据和测试数据的79个特征按样本连结
# [:,1:-1]所有行的第一列到-2列,[:,1:]
all_features = pd.concat((train_data.iloc[:, 1:-1], test_data.iloc[:, 1:]))
- 1
- 2
二、数据集预处理
1_对连续数值的特征做标准化(standardization):设该特征在整个数据集上的均值为μ,标准差为σ。那么,我们可以将该特征的每个值先减去μ再除以σ得到标准化后的每个特征值。对于缺失的特征值,我们将其替换成该特征的均值。
# object是str类或数字混合类型(mixed),将特征为数字的列单独拿出。并保存列名到numeric
numeric_features = all_features.dtypes[all_features.dtypes != 'object'].index # 排除object类型的特征
# 对每种数字型的特征(每一的数字)进行标准化
all_features[numeric_features] =
all_features[numeric_features].apply(lambda x: (x - x.mean()) / (x.std()))
- 1
- 2
- 3
- 4
- 5
print的numeric_features:

2_ 标准化后,每个数值特征的均值变为0,所以可以直接用0代替缺失值,即缺失值NA和无意义值NAN用0代替
all_features[numeric_features] = all_features[numeric_features].fillna(0)
3_接下来将离散数值转换为指示特征,假设特征MSZoning里面有两个不同的离散值RL和RM,那么这一步转换将去掉MSZoning特征,并新加两个特征MSZoning_RL和MSZoning_RM,其值为0或1。如果一个样本原来在MSZoning里的值为RL,那么有MSZoning_RL=1且MSZoning_RM=0。
# dummpy_na=True将缺失值也当做合法的特征值并为其创建指示特征
# get_dummies即上述将离散值转换为指示特征
all_features = pd.get_dummies(all_features, dummy_na=True)
#print(all_features.shape)
- 1
- 2
- 3
- 4
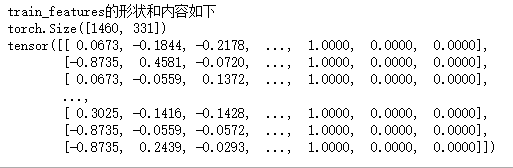
4_通过value属性得到numpy 格式的数据,并转成tensor方便后面的训练
# 取train_data的行数,即训练集个数
n_train = train_data.shape[0]
# 训练集特征
train_features = torch.tensor(all_features[:n_train].values, dtype=torch.float)
# 测试集特征
test_features = torch.tensor(all_features[n_train:].values, dtype=torch.float)
# 训练标签 将shape=(1460)转换为shape=(1460,1)
# view(-1,1),-1为不确定数,只能确定后面1列,前面计算机自己会生成相应的数,例如5*6=x*1,x相当于-1
train_labels = torch.tensor(train_data.SalePrice.values, dtype=torch.float).view(-1, 1)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
三、训练模型
1_使用一个基本的线性回归模型和平方损失函数来训练模型
平方损失函数
nn.liner: https://pytorch.org/docs/master/generated/torch.nn.Linear.html?highlight=nn%20linear#torch.nn.Linear
MSELoss:https://pytorch.org/docs/master/generated/torch.nn.MSELoss.html
# 声明平方损失函数
loss = torch.nn.MSELoss()
def get_net(feature_num):
# 实例化nn
net = nn.Linear(feature_num, 1)
for param in net.parameters():
nn.init.normal_(param, mean=0, std=0.01)
return net
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
2_对数均方根误差的实现如下(预测价格的对数与真实标签价格的对数之间出现以下均方根误差)
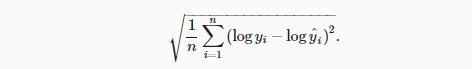
def log_rmse(net, features, labels):
with torch.no_grad():
# 将小于1的值设成1,使得取对数时数值更稳定
clipped_preds = torch.max(net(features), torch.tensor(1.0))
rmse = torch.sqrt(loss(clipped_preds.log(), labels.log()))
return rmse.item()
- 1
- 2
- 3
- 4
- 5
- 6
3_下面的训练函数和本章的前几节不同的是使用adma优化算法,相对与之前使用了小批量随机梯度下降,它对学习率相对不那么敏感
def train(net, train_features, train_labels, test_features, test_labels,
num_epochs, learning_rate, weight_decay, batch_size):
# 训练损失,测试损失
train_ls, test_ls = [], []
# 加载数据
dataset = torch.utils.data.TensorDataset(train_features, train_labels)
train_iter = torch.utils.data.DataLoader(dataset, batch_size, shuffle=True)
# 这里使用了Adam优化算法
optimizer = torch.optim.Adam(params=net.parameters(), lr=learning_rate, weight_decay=weight_decay)
net = net.float()
# 进行迭代
for epoch in range(num_epochs):
# 取出小批次的特征和标签,X:特征,y:标签
for X, y in train_iter:
l = loss(net(X.float()), y.float())
# 梯度清零
optimizer.zero_grad()
# 反向传播计算得到每个参数的梯度值
l.backward()
# 通过梯度下降执行一步参数更新
optimizer.step()
train_ls.append(log_rmse(net, train_features, train_labels))
if test_labels is not None:
test_ls.append(log_rmse(net, test_features, test_labels))
return train_ls, test_ls
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
四、K折交叉验证
简单解释,将训练集分为k份,每次将其中一份作为验证集,其余做训练集。
1_它返回第i折交叉验证时所需要的训练和验证数据。
def get_k_fold_data(k, i, X, y):
# 返回第i折交叉验证时所需要的训练和验证数据
# k需要大于1,assert用于判断一个表达式,在表达式条件为false的时候出发异常。
assert k > 1
# 划分成k个集合,fold_size每个集合的个数
fold_size = X.shape[0] // k
# 初始化X_train, y_train
X_train, y_train = None, None
# 循环访问k个集合
for j in range(k):
# slice(start, stop[, step]);start:开始位置,stop:结束位置,step:间距
# 则idx等于就是第j个集合切片对象的集合
idx = slice(j * fold_size, (j + 1) * fold_size)
# 将第j个集合的特征,和第j个集合的标签分别放在X_part, y_part
X_part, y_part = X[idx, :], y[idx]
# 如果当前的集合是第i折交叉验证,就将当前的集合当作验证模型
# (j=i)就是当前所取部分刚好是要当验证集的部分
if j == i:
# 将当前所取集合放进验证集
X_valid, y_valid = X_part, y_part
# 如果j!=i且X_train是空的则直接将此部分放进训练集
elif X_train is None:
X_train, y_train = X_part, y_part
# 如果j!=i且访问到其余除了验证集(j=i)其余集合的子集,就使用concat连接已经放进训练集的集合
else:
X_train = torch.cat((X_train, X_part), dim=0)
y_train = torch.cat((y_train, y_part), dim=0)
# 依次返回训练模型和第i个验证模型
return X_train, y_train, X_valid, y_valid
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
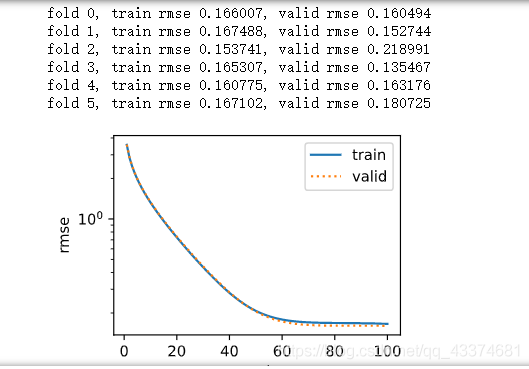
2_在K折交叉验证中我们训练K次并返回训练和验证的平均误差。
def k_fold(k, X_train, y_train, num_epochs,
learning_rate, weight_decay, batch_size):
# 初始化训练集损和验证集的损失和
train_l_sum, valid_l_sum = 0, 0
# 依次访问所划分集合
for i in range(k):
# 获得训练模型和第i个验证模型
data = get_k_fold_data(k, i, X_train, y_train)
# 获得net实例
net = get_net(X_train.shape[1])
# 分别计算出训练集与验证集损失
# *data可以分别读取数据,在这里等于是得到了get_k_fold_data)函数的return的四个表,直接写data会导致缺位置参数。
train_ls, valid_ls = train(net, *data, num_epochs, learning_rate,
weight_decay, batch_size)
#计算训练集损失之和
train_l_sum += train_ls[-1]
#计算验证集损失之和
valid_l_sum += valid_ls[-1]
# 画图
if i == 0:
# d21:自己封装的包,包里是常用的函数模块
d21.semilogy(range(1, num_epochs + 1), train_ls, 'epochs', 'rmse',
range(1, num_epochs + 1), valid_ls,
['train', 'valid'])
print('fold %d, train rmse %f, valid rmse %f' % (i, train_ls[-1], valid_ls[-1]))
return train_l_sum / k, valid_l_sum / k
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
五、模型选择
我们使用一组未经调优的超参数并计算交叉验证误差,可以改动这些超参数来尽可能减小平均测试误差。
k, num_epochs, lr, weight_decay, batch_size = 6, 100, 6, 0, 64
train_l, valid_l = k_fold(k, train_features, train_labels, num_epochs, lr, weight_decay, batch_size)
print('%d-fold validation: avg train rmse %f, avg valid rmse %f' % (k, train_l, valid_l))
- 1
- 2
- 3
六、预测并正在kaggle提交结果
1_下面定义的预测函数。在预测之前,我们会使用完整的训练数据集来重新训练模型,转换预测结果存成提交所需要的格式。
def train_and_pred(train_features, test_features, train_labels, test_data,
num_epochs, lr, weight_decay, batch_size):
# 获得net实例
net = get_net(train_features.shape[1])
# 返回训练集损失
# 单下划线 _ 单个独立下划线是用作一个名字,来表示某个变量是临时的或无关紧要的。
train_ls, _ = train(net, train_features, train_labels, None, None,
num_epochs, lr, weight_decay, batch_size)
# 作图
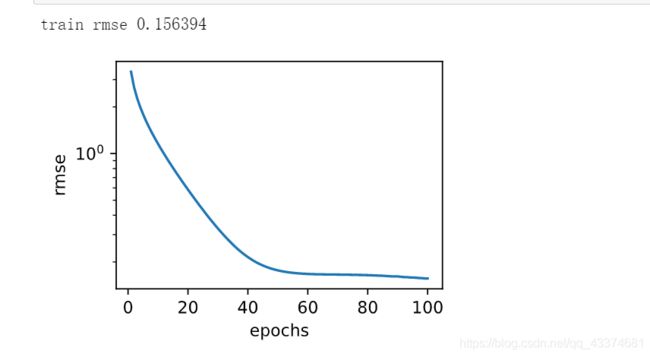
d2l.semilogy(range(1, num_epochs + 1), train_ls, 'epochs', 'rmse')
print('train rmse %f' % train_ls[-1])
# 计算预测标签
# detach:返回一个新的tensor,从当前图形分离(官方文档解释)
preds = net(test_features).detach().numpy()
# SalePrice标签列
test_data['SalePrice'] = pd.Series(preds.reshape(1, -1)[0])
# 将测试集的Id和预测结果拼接在一起,axis沿水平方向拼接,与上面默认纵向拼接不同。
submission = pd.concat([test_data['Id'], test_data['SalePrice']], axis=1)
# 转成可提交的csv格式
submission.to_csv('./submission.csv', index=False)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
2_设计好模型并调好超参数之后,接下来就是对测试数据集上的房屋样本做价格预测。如果我们得到与交叉验证时差不多的训练误差,那么这个结果很可能是理想的,可以在Kaggle上提交结果
train_and_pred(train_features, test_features, train_labels, test_data, num_epochs, lr, weight_decay, batch_size)
- 1
可提交文件:
3_上述代码执行完之后会生成一个submission.csv文件,这个文件是符合Kaggle比赛要求的提交格式。
注:学习记录,仅供参考,如有错误,可联系交流。
所需数据和源码均可关注微信公众号:Time木
回复:房价预测