《Redis设计与实现》(16-21)个人学习总结
注明:《Redis设计与实现》的个人学习总结,这本书对redis的讲解清晰易懂,如果深入学习可以看看这本书
目录
- 第16章 Sentinel
-
- 16.1 启动并初始化Sentinel
-
- 16.1.1 初始化服务器
- 16.1.2 使用Sentinel专用代码
- 16.1.3 初始化Sentinel状态
- 16.1.4 初始化Sentinel状态的masters属性
- 16.1.5 创建连向主服务器的网络连接
- 16.2 获取主服务器信息
- 16.3 获取从服务器信息
- 16.4 向主服务器和从服务器发送信息
- 16.5 接收来自主服务器和从服务器的频道信息
-
- 16.5.1 更新sentinels字典
- 16.5.2 创建连向其他Sentinel的命令连接
- 16.6 检测主观下线状态
- 16.7 检查客观下线状态
-
- 16.7.1 发送SENTINEL is-master-down-by-addr命令
- 16.7.2 接收SENTINEL is-master-down-by-addr命令
- 16.7.3 接收SENTINEL is-master-down-by-addr命令的回复
- 16.8 选举领头Sentinel
- 16.9 故障转移
-
- 16.9.1 选出新的主服务器
- 16.9.2 修改从服务器的复制目标
- 16.9.3 将旧的主服务器变为从服务器
- 16.10 重点回顾
- 第17章 集群
-
- 17.1 节点
-
- 17.1.1 启动节点
- 17.1.2 集群数据结构
- 17.1.3 CLUSTER MEET命令的实现
- 17.2 槽指派
-
- 17.2.1 记录节点的槽指派信息
- 17.2.2 传播节点的槽指派信息
- 17.2.3 记录集群所有槽的指派信息
- 17.2.4 CLUSTER ADDSLOTS命令的实现
- 17.3 在集群中执行命令
-
- 17.3.1 计算键属于哪个槽
- 17.3.2 判断槽是否由当前节点负责处理
- 17.3.3 MOVED错误
- 17.3.4 节点数据库的实现
- 17.4 重新分片
-
- 重新分片的实现原理
- 17.5 ASK错误
-
- 17.5.1 CLUSTER SETSLOT IMPORTING命令的实现
- 17.5.2 CLUSTER SETSLOT MIGRATING命令的实现
- 17.5.3 ASK错误
- 17.5.4 ASKING命令
- 17.5.5 ASK错误和MOVED错误的区别
- 17.6 复制与故障转移
-
- 17.6.1 设置从节点
- 17.6.2 故障检测
- 17.6.3 故障转移
- 17.6.4 选举新的主节点
- 17.7 消息
-
- 17.7.1 消息头
- 17.7.2 MEET、PING、PONG消息的实现
- 17.7.3 FAIL消息的实现
- 17.7.4 PUBLISH消息的实现
- 17.8 重点回顾
- 第18章 发布与订阅
-
- 18.1 频道的订阅与退订
-
- 18.1.1 订阅频道
- 18.1.2 退订频道
- 18.2 模式的订阅与退订
-
- 18.2.1 订阅模式
- 18.2.2 退订模式
- 18.3 发送消息
-
- 18.3.1 将消息发送给频道订阅者
- 18.3.2 将消息发送给模式订阅者
- 18.4 查看订阅信息
-
- 18.4.1 PUBSUB CHANNELS
- 18.4.2 PUBSUB NUMSUB
- 18.4.3 PUBSUB NUMPAT
- 18.5 重点回顾
- 第19章 事务
-
- 19.1 事务的实现
-
- 19.1.1 事务开始
- 19.1.2 命令入队
- 19.1.3 事务队列
- 19.1.4 执行事务
- 19.2 WATCH命令的实现
-
- 19.2.1 使用WATCH命令监视数据库键
- 19.2.2 监视机制的触发
- 19.2.3 判断事务是否安全
- 19.3 事务的ACID性质
-
- 19.3.1 原子性
- 19.3.2 一致性
- 19.3.3 隔离性
- 19.3.4 耐久性
- 19.4 重点回顾
- 第21章 排序
-
- 21.1 SORT命令的实现
- 21.2 ALPHA选项的实现
- 21.3 ASC选项和DESC选项的实现
- 21.4 BY选项的实现
- 21.5 带有ALPHA选项的BY选项的实现
- 21.6 LIMIT选项的实现
- 21.7 GET选项的实现
- 21.10 重点回顾
第16章 Sentinel
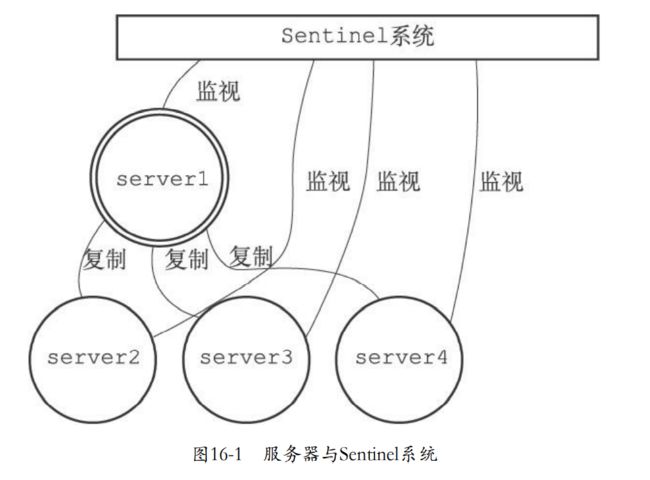
- Sentinel是redis高可用性的解决方案。由一个或者多个Sentinel实例组成的Sentinel系统监视多个主服务器,和下面的从服务器。
- 双环是主服务器
- 单环就是从服务器
- sentinel监视这四个服务器。
- 如果server1下线超时,sentinel就会对server1执行故障转移。
- 选择一个从服务器升级为主服务器
- 其它从服务器重新发送复制请求,认定新的主服务器。
- 监控下线的server1,如果上线就设置为新主服务器的从服务器。


16.1 启动并初始化Sentinel
- 启动命令
$ redis-sentinel /path/to/your/sentinel.conf
$ redis-server /path/to/your/sentinel.conf --sentinel
- 启动的步骤
- 初始化服务器
- 普通redis服务器使用的代码替换成sentinel专用代码
- 初始化sentinel状态
- 根据配置文件,初始化sentinel监视主服务器列表
- 创建连向服务器的网络连接。
16.1.1 初始化服务器
- sentinel本质就是运行在特殊模式下的redis服务器。
- 一开始就要初始化普通redis服务器,但是redis普通服务器和sentinel有所不同。所以初始化也不同
- 载入文件还原数据库这里的方式也是不同的。

16.1.2 使用Sentinel专用代码
- 把redis服务器使用的代码转换成sentinel的专用代码。他们使用的服务器端口也是不同的。
#define REDIS_SERVERPORT 6379
#define REDIS_SENTINEL_PORT 26379
- redis普通服务器使用redis.c/redisCommandTable作为命令表
- Sentinel使用sentinel.c/sentinelcmds作为命令表。而且实现的函数也是有所不同。
- 所以sentinel模式下无法执行set,dbsize,eval等命令。因为服务器的命令表没有这些。
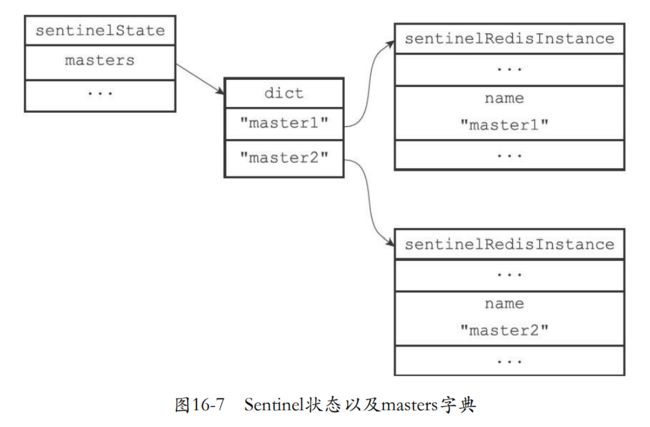
16.1.3 初始化Sentinel状态
- 接下来就会初始化sentinel.c/sentinelState结构保存了sentinel相关的状态。
struct sentinelState {
//
当前纪元,用于实现故障转移
uint64_t current_epoch;
//
保存了所有被这个sentinel
监视的主服务器
//
字典的键是主服务器的名字
//
字典的值则是一个指向sentinelRedisInstance
结构的指针
dict *masters;
//
是否进入了TILT
模式?
int tilt;
//
目前正在执行的脚本的数量
int running_scripts;
//
进入TILT
模式的时间
mstime_t tilt_start_time;
//
最后一次执行时间处理器的时间
mstime_t previous_time;
一个FIFO
队列,包含了所有需要执行的用户脚本
list *scripts_queue;
} sentinel;
16.1.4 初始化Sentinel状态的masters属性
- master字典记录了所有被监视的主服务器相关信息
- 字典的键是被监视的主服务器名字
- 值就是sentinel.c/sentinelRedisInstance结构
- sentinelRedisInstance结构代表一个被监视主服务器的实例,可以是主服务器,也可以是从服务器
- 部分sentinelRedisInstance结构属性。
typedef struct sentinelRedisInstance {
//
标识值,记录了实例的类型,以及该实例的当前状态
int flags;
//
实例的名字
//
主服务器的名字由用户在配置文件中设置
//
从服务器以及Sentinel
的名字由Sentinel
自动设置
//
格式为ip:port
,例如"127.0.0.1:26379"
char *name;
//
实例的运行ID
char *runid;
//
配置纪元,用于实现故障转移
uint64_t config_epoch;
//
实例的地址
sentinelAddr *addr;
// SENTINEL down-after-milliseconds
选项设定的值
//
实例无响应多少毫秒之后才会被判断为主观下线(subjectively down
)
mstime_t down_after_period;
// SENTINEL monitor
选项中的quorum
参数
//
判断这个实例为客观下线(objectively down
)所需的支持投票数量
int quorum;
// SENTINEL parallel-syncs
选项的值
//
在执行故障转移操作时,可以同时对新的主服务器进行同步的从服务器数量
int parallel_syncs;
// SENTINEL failover-timeout
选项的值
//
刷新故障迁移状态的最大时限
mstime_t failover_timeout;
// ...
} sentinelRedisInstance;
- sentinelRedisInstance.addr属性指向sentinel.c/sentinelAddr结构,保存实例的ip地址和端口号。
typedef struct sentinelAddr {
char *ip;
int port;
} sentinelAddr;
- masters字典的初始化根据被载入的sentinel文件。
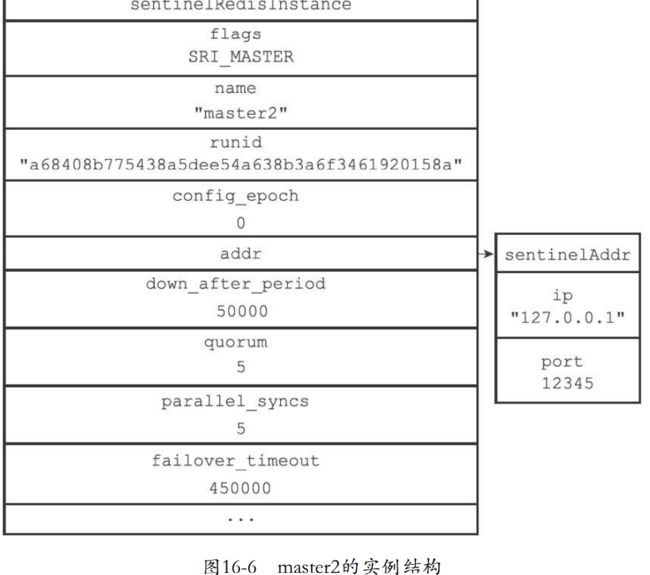
- 下面展示master1的实例结构还有master2的实例结构。
#####################
# master1 configure #
#####################
sentinel monitor master1 127.0.0.1 6379 2
sentinel down-after-milliseconds master1 30000
sentinel parallel-syncs master1 1
sentinel failover-timeout master1 900000
#####################
# master2 configure #
#####################
sentinel monitor master2 127.0.0.1 12345 5
sentinel down-after-milliseconds master2 50000
sentinel parallel-syncs master2 5
sentinel failover-timeout master2 450000

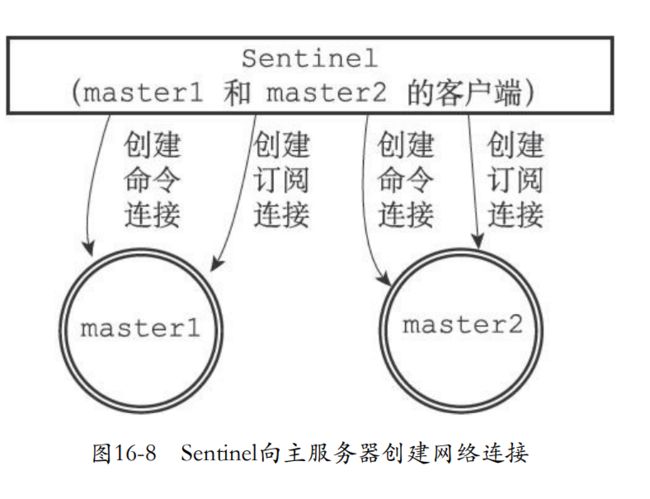
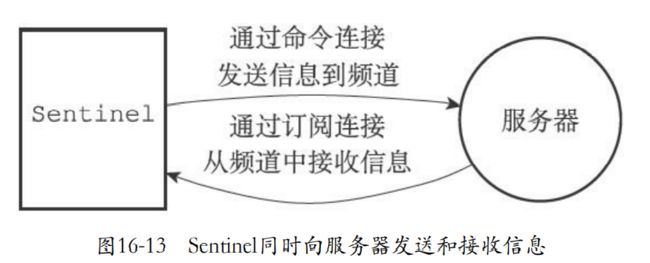
16.1.5 创建连向主服务器的网络连接
-
最后一步就是向被监视的主服务器进行网络连接。成为主服务器的客户端,发送命令并且获取对应的信息。
-
但是需要两个连接
- 命令连接:专门发送命令和接收回复
- 订阅连接:订阅主服务器的__sentinel__:hello频道
-
为什么有两个连接?
-
因为redis订阅和发布功能中,被发送信息不会存于server,为了防止丢失,那么sentinel就需要一个订阅连接来特殊处理这些订阅接收信息。
-
而且还需要发送命令和接收回复。
-
sentinel和多个实例进行网络连接所以sentinel使用的是异步连接。
-
16.2 获取主服务器信息
- 每10s,sentinel都会发送info获取主服务器信息。
- 获取下面的内容。
- 主服务器的runid和服务器角色
- 从服务器的ip和端口号
# Server
...
run_id:7611c59dc3a29aa6fa0609f841bb6a1019008a9c
...
# Replication
role:master
...
slave0:ip=127.0.0.1,port=11111,state=online,offset=43,lag=0
slave1:ip=127.0.0.1,port=22222,state=online,offset=43,lag=0
slave2:ip=127.0.0.1,port=33333,state=online,offset=43,lag=0
...
# Other sections
...

-
如果发现runid和sentinel保存的那个主服务器实例结构不同那么就要进行更新。
-
对于从服务器的信息用于更新主服务器实例的结构slaves字典,字典记录从服务器的名单。
- 键是从服务器名字
- 值就是对应的从服务器的实例结构。
-
sentinel还会检查从服务器的实例是不是存在于字典里面
- 存在那么就sentinel就更新这个从服务器的实例
- 否则就创建一个sentinel实例结构。
-
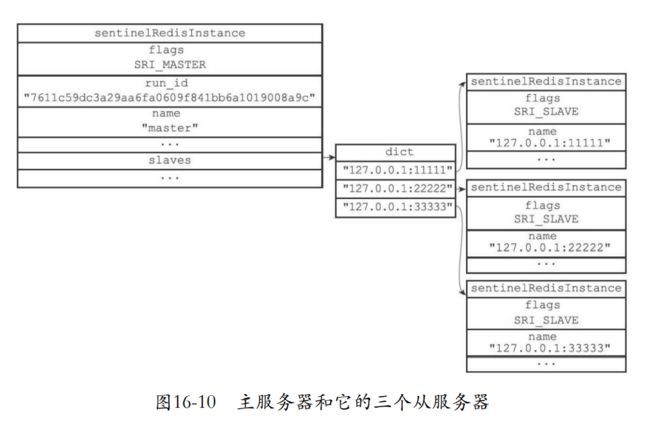
下面就是主服务器和所有的从服务器的sentinelRedisInstance实例。保存服务器名字,ip,端口。
- 主服务器的flags=SRI_MASTER,从服务器是SRI_SLAVE
- 主服务器的name是sentinel配置文件设置,从服务器就是ip+端口号。
16.3 获取从服务器信息
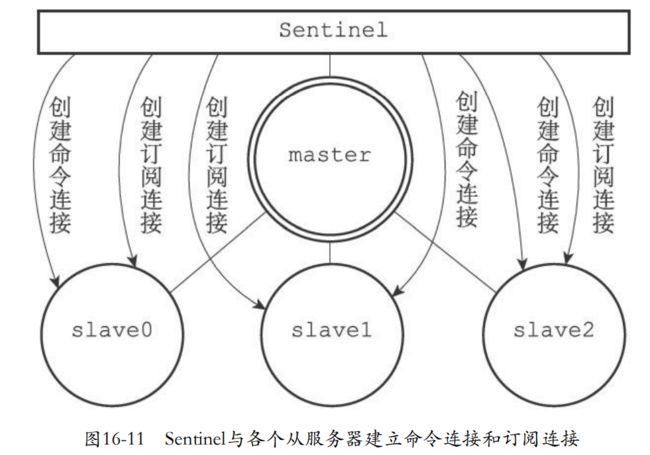
- 对于从服务器来说sentinel也会进行命令连接和订阅连接。
- 每10s发送info获取从服务器的信息更新实例信息。
- 从服务器的runid
- 从服务器角色role
- 主服务器的master_host
- 主服务器的端口号master_port。
- 主从服务器的连接状态master_link_status.
- 从服务器的优先级slave_priority
- 从服务器的复制偏移
# Server
...
run_id:32be0699dd27b410f7c90dada3a6fab17f97899f
...
# Replication
role:slave
master_host:127.0.0.1
master_port:6379
master_link_status:up
slave_repl_offset:11887
slave_priority:100
# Other sections
...

16.4 向主服务器和从服务器发送信息
- 每2s,sentinel通过命令连接发送命令
PUBLISH __sentinel__:hello 信息
- 命令向服务器的_sentinel__:hello频道发送一条信息
- s_开头就是sentinel本身的信息
- m_开头就是主服务器的信息。

- 发送信息的实例
"127.0.0.1,26379,e955b4c85598ef5b5f055bc7ebfd5e828dbed4fa,0.."
- sentinel的127.0.0.1端口号为26379,运行id是e955b4c85598ef5b5f055bc7ebfd5e828dbed4fa,纪元为0。
- 后面就是一个对应的主服务器的相关信息。
16.5 接收来自主服务器和从服务器的频道信息
- sentinel的订阅连接,发送一个下面的请求给服务器
- 这个订阅会持续到与服务器连接断开
- 也就是可以向sentinel:hello频道发送信息,而且也能够接收信息
SUBSCRIBE __sentinel__:hello
- 监视同一个服务器的多个sentinel,一个sentinel发送的信息,所有其他sentinel都可以共享。可以更新对被监视服务器的认知
- 当sentinel接收信息,就会根据sentinel的id,端口,运行id进行一个解析
- 运行id和自己的相同,信息丢弃
- 不同的话,说明这是其他sentinel发的,可以更新一下sentinel对这个服务器的实例结构更新。

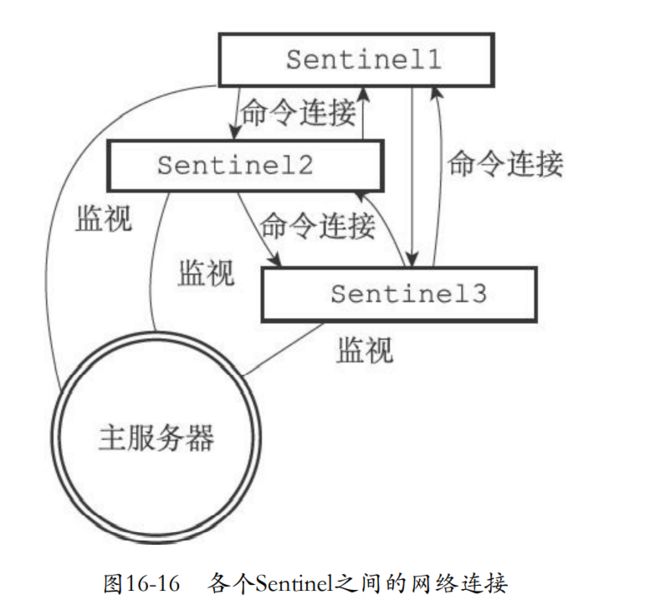
16.5.1 更新sentinels字典
- Sentinel为主服务器创建的sentinels字典,包括了其它的sentinel的信息
- 键就是其它sentinel的名字,格式ip:端口号
- 值就是对应的sentinel实例。
- sentinel接收信息会从信息提取
- 与sentinel相关的参数
- 与主服务器相关的参数。runid之类的。
- 根据主服务器的参数可以在sentinel的masters字典找到主服务器结构
- 根据sentinel参数可以在sentinels字典找到sentinel实例结构。
- 下面sentinel 26379收到3条信息
- 第一条忽略
- 第二条发送者是26381,从sentinels字典获取这个sentinel并且更新信息
- 第三条信息127.0.0.1:26380这个也是要更新
1) "message"
2) "__sentinel__:hello"
3) "127.0.0.1,26379,e955b4c85598ef5b5f055bc7ebfd5e828dbed4fa,0,mymaster,127.0.0.1,6379,0"
1) "message"
2) "__sentinel__:hello"
3) "127.0.0.1,26381,6241bf5cf9bfc8ecd15d6eb6cc3185edfbb24903,0,mymaster,127.0.0.1,6379,0"
1) "message"
2) "__sentinel__:hello"
3) "127.0.0.1,26380,a9b22fb79ae8fad28e4ea77d20398f77f6b89377,0,myma

16.5.2 创建连向其他Sentinel的命令连接
- sentinel之间也是会建立命令连接的。
16.6 检测主观下线状态
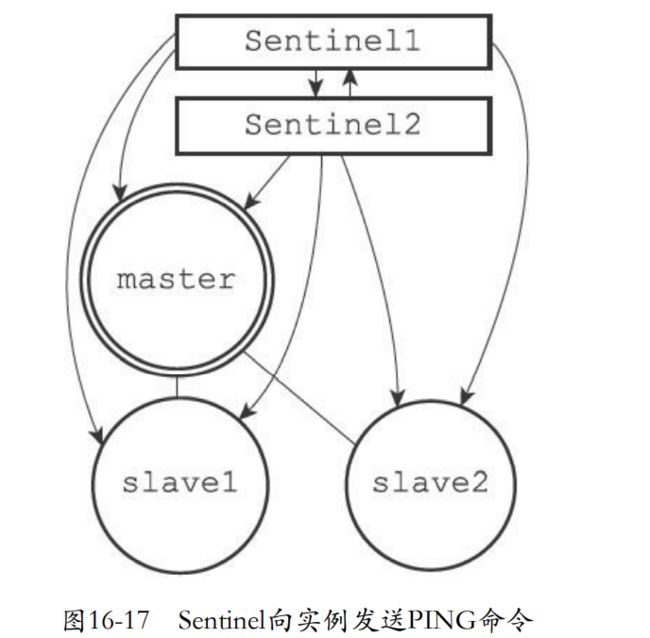
- Sentinel每秒发送ping验证连接实例是不是在线
- ping回复
- 有效回复+PONG、-LOADING、-MASTERDOWN
- 无效回复+PONG、-LOADING、-MASTERDOWN这三个之外的回复。
- down-after-milliseconds也就是sentinel配置文件的选项,指定判断实例已经下线的所需时间长度。比如在规定时间实例向sentinel返回无效回复,那么sentinel只能把实例的flags修改为SRI_S_DOWN
- 而且每个sentinel的down-after-milliseconds都有可能是不同的。所以这个只是sentinel认为的主观下线。

16.7 检查客观下线状态
- 一个sentinel不足以认为实例下线,所以可以询问其他sentinel,如果他们也这么认为那么就是下线了。就可以对主服务器进行故障转移。
16.7.1 发送SENTINEL is-master-down-by-addr命令
- 询问其他sentinel是否同意主服务器下线
- 下面是命令和各个参数。
SENTINEL is-master-down-by-addr
例子,主服务器IP为127.0.0.1,端口号为6379,纪元是0,询问其他sentinel问一下是不是下线了。
SENTINEL is-master-down-by-addr 127.0.0.1 6379 0 *

16.7.2 接收SENTINEL is-master-down-by-addr命令
- 接收到命令后,立刻提取主服务器参数,并且检查是否已经下线。
- 然后返回一条三个参数的Multi Bulk回复
1)
2)
3)

- 比如,这个1就说明回复的是主服务器已经下线了。
1) 1
2) *
3) 0
16.7.3 接收SENTINEL is-master-down-by-addr命令的回复
- 源sentinel统计其它sentinel认为主服务器下线的数量,如果达到客观下线数量,那么就会修改主服务器实例的flags=SRI_O_DOWN,说明现在已经是客观下线状态。
- 如果其它sentinel认为主服务器下线的数量超过quorum参数那么就是客观下线。
- 不同的sentinel设置的客观下线参数也是不同的。所以一个sentinel认为客观下线不代表其它的sentinel也符合这样的规则。

16.8 选举领头Sentinel
- 如果主服务器下线,那么这个时候需要选举出一个sentinel的领头,并且让领头处理故障转移操作。
- 谁都可能是领头
- 不管是不是选举成功纪元都+1
- 领头设置之后,领头的纪元不能被修改
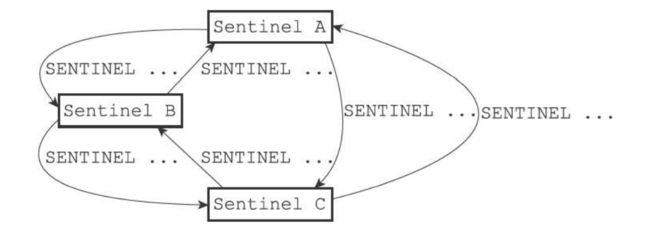
- 每个发现主服务器进入客观下线的sentinel都会要求其他sentinel将自己设置为领头Sentinel。
- 源sentinel向目标sentinel发送SENTINEL is-master-down-by-addr,如果runid不是*而是源sentinel的id那么表示源sentinel要求目标sentinel设置后者为局部领头
- 设置局部领头先到先得,最先向目标发送信息要求的那个源sentinel才会成为这个目标的sentinel的局部领头。
- 目标sentinel接收命令后回复leader_runid参数和leader_runid参数记录了领头id和纪元
- 源sentinel收到回复查看纪元leader_epoch是不是和自己的相同,如果是取出leader_runid,如果runid也和sentinel的runid相同,表示说明目标已经设置它为局部领头
- 如果一个sentinel获得半数其它sentinel支持那么就能成为领头。
- 如果没有选出那么就会重新再来选,直到成功。

16.9 故障转移
- 选出领头之后的操作
- 挑出一个从服务器转换为主服务器
- 已下线的主服务器的从服务器改复制新的主服务器
- 已下线的主服务器设置为新主服务器的从服务器。
16.9.1 选出新的主服务器
- 从状态比较好的从服务器中选出一个新的主服务器。发送 slave of no one
- 新的主服务器是怎样挑选出来的
- 删除列表中下线的从服务器。
- 删除最近5s没有恢复sentinel的info命令的从服务器
- 删除所有和主服务器断开连接超过down-after-milliseconds*10毫秒的从服务器。这个参数指定了判断主服务器下线所需要的时间,删除断开连接超过down-after-milliseconds * 10能够保证剩余从服务器没有过早和主服务器断开连接,保存的数据比较新。
- 然后根据优先级和复制偏移量大小选出最好的。

- 选出来之后领头sentinel就会每秒一直发送info,直到被升级的从服务器的role已经变了master。那么说明升级成功。
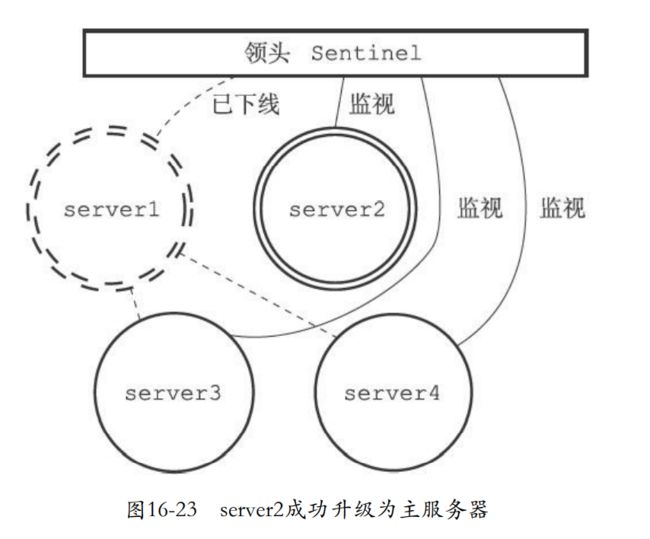
16.9.2 修改从服务器的复制目标
- 实际上下一步就是修改其他从服务器的复制对象,使用slaveof命令就可以进行处理。


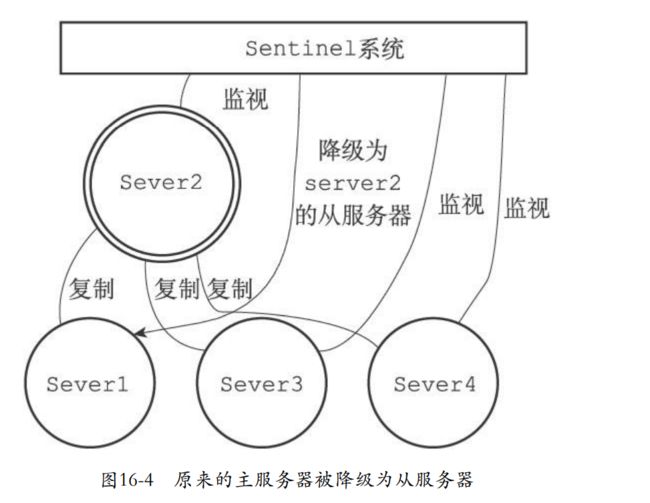
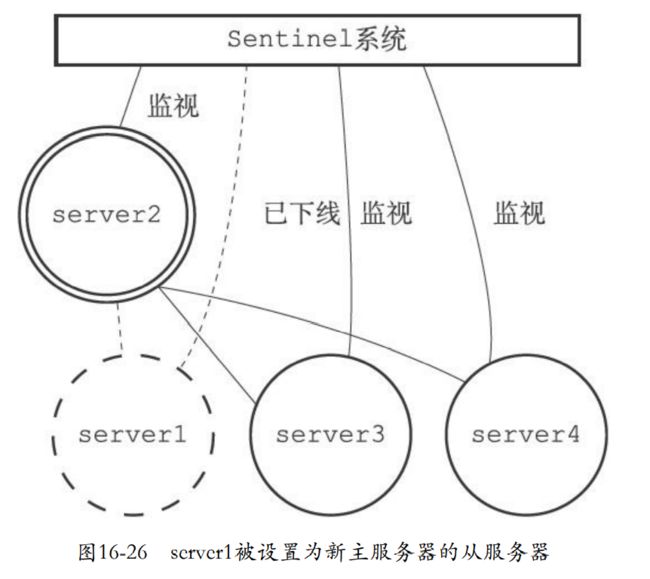
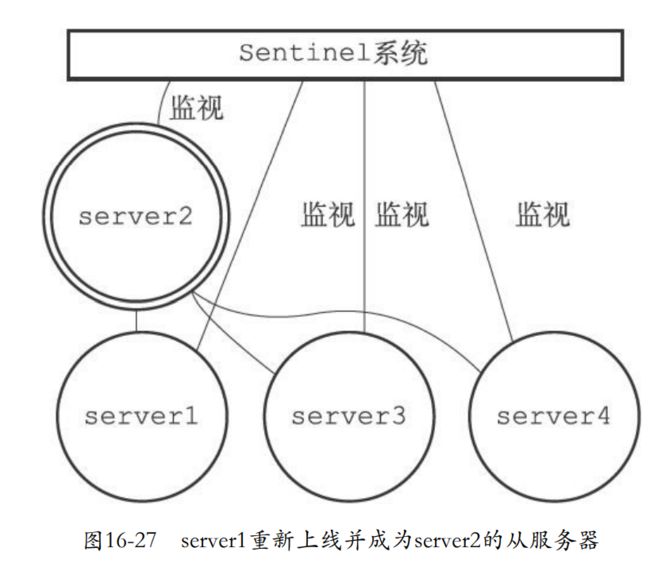
16.9.3 将旧的主服务器变为从服务器
- 以前的主服务器上线的时候就会设置为新主服务器的从服务器。
16.10 重点回顾
- Sentinel是特殊的redis服务器,和普通的服务器不同在于,使用不同的命令表,命令表的函数也是不一样的。
- Sentinel会创建两个连接一个是命令,一个是订阅,订阅连接主要是处理获取其它Sentinel和服务器的最新信息,命令连接就是为了处理好主服务器发送的命令请求。
- Sentinel可以通过Info命令获取主服务器的信息,和所有从服务器的信息,并且为这些服务器创建实例结构。它也会和其它从服务器进行一个订阅和命令连接
- 每10s发送一次info命令,如果发现主服务器处于下线或者是处于故障转移的时候,那么就会改成每秒发送一次,主要是监测主服务器是否真的下线,还有就是故障转移是否成功。
- 监视同一个服务器的Sentinel可以通过发送消息到这个频道告知自己的存在
- 也可以接受频道的信息,并且为他们创建实例结构
- Sentinel之间只会创建命令连接
- Sentinel每秒向所有服务器和Sentinel发送ping,如果没有在规定时间做出有效的应答,那么就会认为是主观下线,并且询问其他的Sentinel是不是他们也认为该服务器主观下线,要是多个Sentinel超过半数认为是主观下线,那么就会给该服务器标记为客观下线
- 这个时候就会开始争夺领头,通过向其他Sentinel发送请求,投票自己,成为领头之后就可以进行故障转移。选出新的主服务器,改变从服务器的复制目标,最后就是把以前的主服务器设置为新服务器的从服务器。
第17章 集群
17.1 节点
- redis集群由多个节点组成。
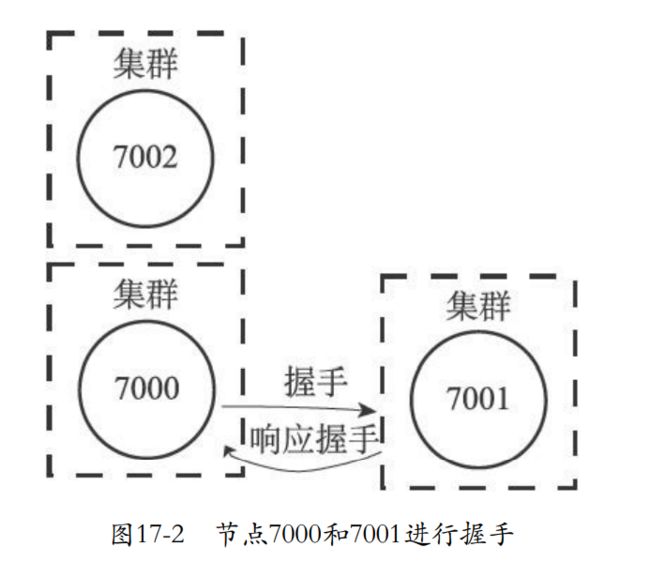
- 下面就是集群工作命令
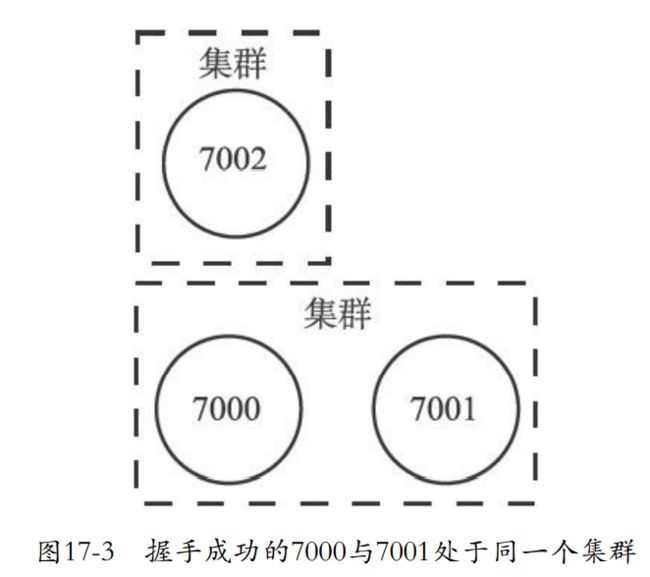
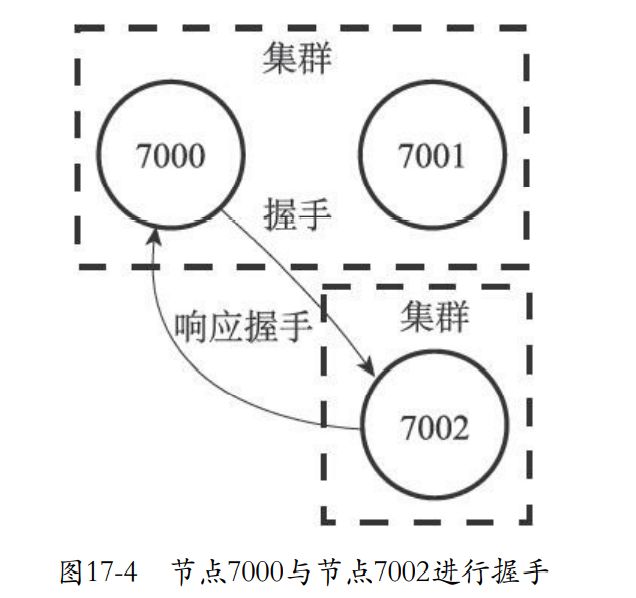
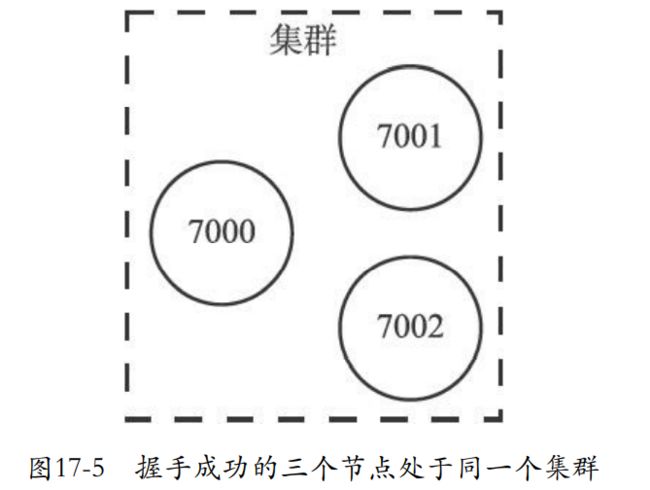
- 发送命令到指定的node,可以进行握手,握手成功就会加入到本node的集群中
- 下面就是7000邀请7001来到自己的集群。然后再邀请7002。
CLUSTER MEET ip port

17.1.1 启动节点
- 一个节点就是运行在集群模式下的redis服务器。会根据cluster-enabled配置选项决定不是开启集群。
- 节点会使用单机模式的所有服务器组件
- 节点会使用文件事件处理器完成请求和回复
- 时间事件处理器完成serverCron函数,serverCron又会调用clusterCron主要处理集群下的常规操作
- 还是会使用数据库
- 持久化组件
- 复制等

17.1.2 集群数据结构
- clusterNode结构保存节点的状态。
struct clusterNode {
//
创建节点的时间
mstime_t ctime;
//
节点的名字,由40
个十六进制字符组成
//
例如68eef66df23420a5862208ef5b1a7005b806f2ff
char name[REDIS_CLUSTER_NAMELEN];
//
节点标识
//
使用各种不同的标识值记录节点的角色(比如主节点或者从节点),
//
以及节点目前所处的状态(比如在线或者下线)。
int flags;
//
节点当前的配置纪元,用于实现故障转移
uint64_t configEpoch;
//
节点的IP
地址
char ip[REDIS_IP_STR_LEN];
//
节点的端口号
int port;
//
保存连接节点所需的有关信息
clusterLink *link;
// ...
};
- clusterNode的link对应一个clusterLink,保存套接字描述符,输入输出缓冲区
typedef struct clusterLink {
//
连接的创建时间
mstime_t ctime;
// TCP
套接字描述符
int fd;
//
输出缓冲区,保存着等待发送给其他节点的消息(message
)。
sds sndbuf;
//
输入缓冲区,保存着从其他节点接收到的消息。
sds rcvbuf;
//
与这个连接相关联的节点,如果没有的话就为NULL
struct clusterNode *node;
} clusterLink;
redisClient结构和clusterLink结构不同之处?
-
都有描述符和输入输出缓冲区
-
redisClient套接字和缓冲区是用于连接客户端的
-
clusterLink的套接字和缓冲区是用于连接节点的。
-
最后还有一个clusterState用于保存节点的状态。每个节点都有这个东西。
typedef struct clusterState {
//
指向当前节点的指针
clusterNode *myself;
//
集群当前的配置纪元,用于实现故障转移
uint64_t currentEpoch;
//
集群当前的状态:是在线还是下线
int state;
//
集群中至少处理着一个槽的节点的数量
int size;
//
集群节点名单(包括myself
节点)
//
字典的键为节点的名字,字典的值为节点对应的clusterNode
结构
dict *nodes;
// ...
} clusterState;
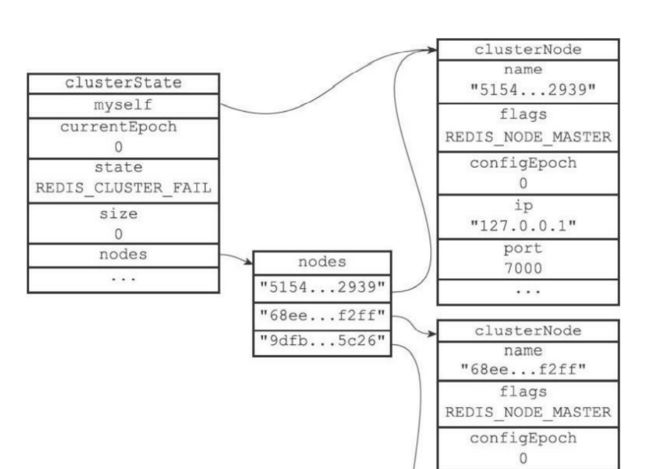
- 用这是三个节点为例子。从7000的角度来说记录集群和三个节点的状态(上面的代码)
- 结构的currentEpoch属性是0,表示集群的纪元就是0。
- size为0说明没有任何节点处理槽,所以state的值是REDIS_CLUSTER_FAIL,集群处于下线
- nodes字典保存了2个clusterNode结构,分别保存7001和7002。myself指向了7000
- 三个节点的clusterNode的flags是REDIS_NODE_MASTER说明都是主节点。
- 在7001创建的clusterState上面myself就是指向7001

17.1.3 CLUSTER MEET命令的实现
- 可以向节点A发送cluster meet命令来把节点B加入到自己的集群。
整个过程
- A会为B创建一个clusterNode,并且加入到自己的clusterState.nodes字典中
- 根据命令A会发送给节点B一条meet命令
- B接收,并且B为A创建一个clusterNode添加到cluster.nodes字典中
- B返回一条pong给A
- A接收到那么就知道B已经成功接收到meet
- A向B发送一条ping
- 如果B返回pong说明连接成功。
相当于就是发送命令给A去加入B,A发送meet,B回应,A发送ping,B回应那么就握手成功。
- 最后通过Goosip协议传播给集群的其它节点。

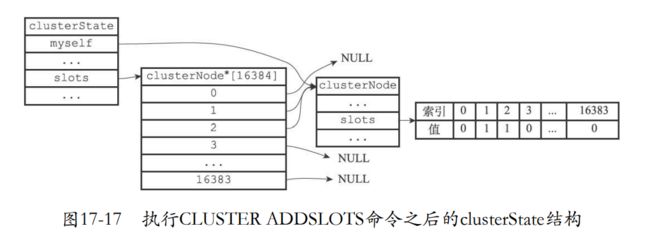
17.2 槽指派
- 集群通过分片存储数据库的键值对,集群被分为16384个槽。
- 集群每个节点可以处理0或者16384个槽
- 所有槽都有节点处理说明集群上线。如果其中一个没有处理说明下线。
- 可以通过命令来分配槽给对应的节点处理。
CLUSTER ADDSLOTS [slot ...]
- 把0-5000的槽交给7000节点来处理。
127.0.0.1:7000> CLUSTER ADDSLOTS 0 1 2 3 4 ... 5000
OK
127.0.0.1:7000> CLUSTER NODES
9dfb4c4e016e627d9769e4c9bb0d4fa208e65c26 127.0.0.1:7002 master - 0 1388316664849 0 connected
68eef66df23420a5862208ef5b1a7005b806f2ff 127.0.0.1:7001 master - 0 1388316665850 0 connected
51549e625cfda318ad27423a31e7476fe3cd2939 :0 myself,master - 0 0 0 co
- 把5001-10000交给7001
127.0.0.1:7001> CLUSTER ADDSLOTS 5001 5002 5003 5004 ... 10000
OK
- 剩下的交给7002。
127.0.0.1:7002> CLUSTER ADDSLOTS 10001 10002 10003 10004 ... 16383
OK
- 现在的状态就是ok也就是上线的状态。
127.0.0.1:7000> CLUSTER INFO
cluster_state:ok
cluster_slots_assigned:16384
cluster_slots_ok:16384
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:3
cluster_size:3
cluster_current_epoch:0
cluster_stats_messages_sent:2699
cluster_stats_messages_received:2617
127.0.0.1:7000> CLUSTER NODES
9dfb4c4e016e627d9769e4c9bb0d4fa208e65c26 127.0.0.1:7002 master - 0 1388317426165 0 connected 10001-16383
68eef66df23420a5862208ef5b1a7005b806f2ff 127.0.0.1:7001 master - 0 1388317427167 0 connected 5001-10000
51549e625cfda318ad27423a31e7476fe3cd2939 :0 myself,master - 0 0 0 c
17.2.1 记录节点的槽指派信息
- 节点的slots和numslots记录了节点负责处理哪些槽。
- slots是一个二进制数组长度是2048个字节包含了16384个bit
- 数位的二进制如果是1那么就是负责
- 数位的二进制0那么就是不负责
- numslots就是记录有多少个需要处理的槽。
- slots是一个二进制数组长度是2048个字节包含了16384个bit

struct clusterNode {
// ...
unsigned char slots[16384/8];
int numslots;
// ...
};
17.2.2 传播节点的槽指派信息
- 除了处理自己的槽,还需要告诉别的节点自己处理什么槽



- 当节点A接收到B的slots的时候,它会找到B对应的clusterNode进行更新。
17.2.3 记录集群所有槽的指派信息
- slots数组记录了每个槽的指向信息。每个指向都是一个clusterNode指针。
- null说明槽没有指派给其它节点
- 如果指向一个clusterNode那么说明槽已经委派给这个节点了。
- 如果指派信息是放到clusterNode上面那么就会导致每次查看槽的指派对象都需要进行遍历所有node。
- 但是在state上做一个这样的slots就很好地解决了指派问题。
- 但是对于clusterNode的slot也是必要的
- 每次通知其它节点的时候只需要把数组发出去
- 如果没有clusterNode的slot,那么每次发送A的被分配的槽的时候就需要遍历clusterState的slot获取所有的A的槽位置然后才能发送出去。
typedef struct clusterState {
// ...
clusterNode *slots[16384];
// ...
} clusterState;
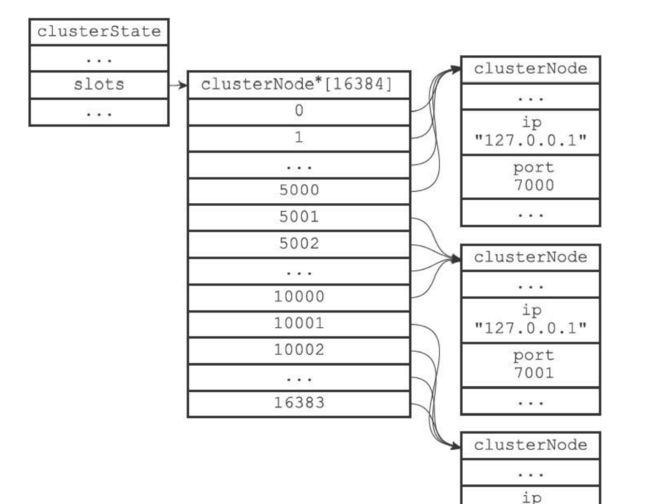

17.2.4 CLUSTER ADDSLOTS命令的实现
- 可以通过命令来把槽委派给节点处理。
- 如果有其中一个槽被委派那么返回错误,如果都是没有被委派,修改clusterState的slot,然后再修改节点clusterNode的slot。
CLUSTER ADDSLOTS <slot> [slot ...]
def CLUSTER_ADDSLOTS(*all_input_slots):
#
遍历所有输入槽,检查它们是否都是未指派槽
for i in all_input_slots:
#
如果有哪怕一个槽已经被指派给了某个节点
#
那么向客户端返回错误,并终止命令执行
if clusterState.slots[i] != NULL:
reply_error()
return
如果所有输入槽都是未指派槽
#
那么再次遍历所有输入槽,将这些槽指派给当前节点
for i in all_input_slots:
#
设置clusterState
结构的slots
数组
#
将slots[i]
的指针指向代表当前节点的clusterNode
结构
clusterState.slots[i] = clusterState.myself
#
访问代表当前节点的clusterNode
结构的slots
数组
#
将数组在索引i
上的二进制位设置为1
setSlotBit(clusterState.myself.slots, i)

- 做了一些委派CLUSTER ADDSLOTS 1 2
17.3 在集群中执行命令
- 都委派之后就可以发送命令了。
- 客户端发送命令,集群计算出数据库的键值对在什么槽,然后委派给节点来处理。
- 步骤
- 如果槽刚好在客户端发送命令的接收的节点上,直接执行
- 不在就会返回moved错误,并且引导客户端转向正确的节点。再次发送命令
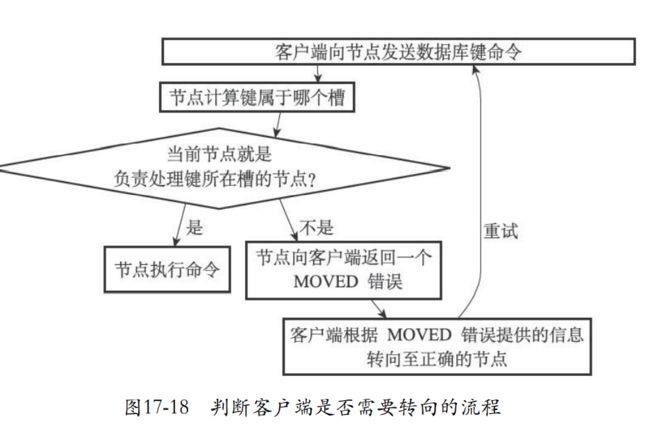
- 如果在7000中执行命令且槽也在7000中
127.0.0.1:7000> SET date "2013-12-31"
OK
- 如果7000中执行命令但不在7000中,最后转到7001执行。
127.0.0.1:7000> SET msg "happy new year!"
-> Redirected to slot [6257] located at 127.0.0.1:7001
OK
127.0.0.1:7001> GET msg
"happy new year!"
17.3.1 计算键属于哪个槽
- crc16是计算key的校验和,然后和16383相与计算出一个在0-16383之内的槽号
- cluster keyslot就能够计算出槽位。
def slot_number(key):
return CRC16(key) & 16383
127.0.0.1:7000> CLUSTER KEYSLOT "date"
(integer) 2022
127.0.0.1:7000> CLUSTER KEYSLOT "msg"
(integer) 6257
127.0.0.1:7000> CLUSTER KEYSLOT "name"
(integer) 5798
127.0.0.1:7000> CLUSTER KEYSLOT "fruits"
(integer) 14943
- 命令调用的实际上就是上面的算法
def CLUSTER_KEYSLOT(key):
#
计算槽号
slot = slot_number(key)
#
将槽号返回给客户端
reply_client(slot)
17.3.2 判断槽是否由当前节点负责处理
- 检查槽是不是自己处理只需要检查clusterState.slots就可以了。
- 如果是直接执行
- 否则转移到正确的节点(ip和端口)执行。
17.3.3 MOVED错误
- 如果发现不是自己执行那么就会返回一个moved错误。
- 下面是格式。
- 有点类似于重定向的过程,通知,然后重定向到其它节点。
- 正常是看不到这个moved错误的,因为他是自动转向的,并且被隐藏。
MOVED <slot> <ip>:<port>


17.3.4 节点数据库的实现
- 集群只能使用0号数据库。
- 键值对保存到数据库,但是还会使用跳表来保存槽和键之间的关系。
typedef struct clusterState {
// ...
zskiplist *slots_to_keys;
// ...
} clusterState;
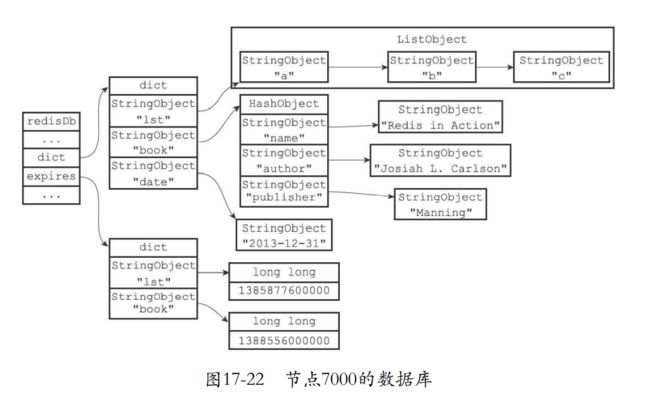
-
slots_to_keys的分值都是槽号,成员就是数据库键。
- 添加键值对,就会把键和槽号关联到跳跃表
- 删除的时候就会删除跳跃表和键的关联。
-
节点可以很方便对这些数据库键进行批量操作。
-
比如,返回最多count个属于slot的数据库键。
CLUSTER GETKEYSINSLOT

17.4 重新分片
- 重新分片就是指把任意数量已经指派给某个节点,但是可以修改这些分片的指派节点。
重新分片的实现原理
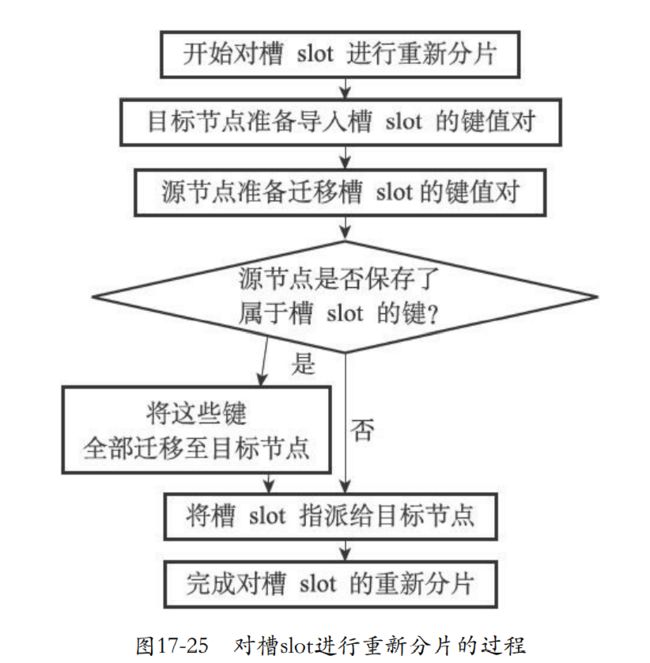
通过redis集群管理软件redis-trib负责执行。下面就是redis-trib对单个槽的分片处理
- redis-trib对目标节点发送下面的命令,让目标节点准备好从源节点导入属于槽slot的键值对。
CLUSTER
SETSLOTIMPORTING
- redis-trib对源节点发送下面命令,把目标槽的键值对进行迁移到目标节点
CLUSTER
SETSLOTMIGRATING
- 然后向源节点发送CLUSTER GETKEYSINSLOT (slot) (count)命令,获得最多count个的属于槽slot的键值对的键名。
- 对于每个键名,redis-trib都发送一个下面的指令,被选中的键迁移到目标节点。
MIGRATE0
-
重复执行3和4。
-
redis-trib向任意节点发送下面的命令,将槽slot委派给目标节点。并且把信息发送给整个集群。
CLUSTER
SETSLOTNODE

总结:执行cluster setslot (slot) importing (source_id)让目标节点准备好导入,CLUSTER SETSLOT (slot) MIGRATING (target_id)这个就是让源节点准备好迁移。再通过CLUSTER GETKEYSINSLOT来获取槽的键值对的键名,然后针对每个键名发送MIGRATE命令进行迁移。最后就是通知整个集群的迁移信息。
17.5 ASK错误
- 重新分片一种情况,被迁移的槽一部分键值对在源节点,一部分存储在目标节点。
- 如果这个时候客户端发送命令的键与这个迁移槽相关的时候怎么办?
- 先在源节点槽上找,有那么就执行
- 没找到就返回ASK错误,并且转向目标节点发送命令

17.5.1 CLUSTER SETSLOT IMPORTING命令的实现
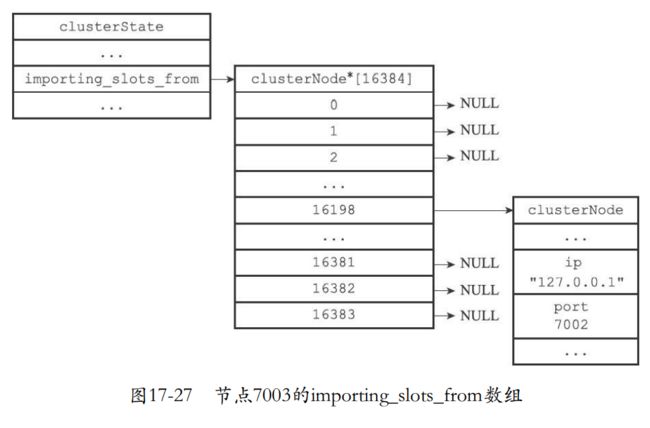
- importing_slots_from数组记录了正在迁移的槽
- importing_slots_from[i]的值不为NULL,指向一个节点,说明当前节点正在从clusterNode导入槽i。
typedef struct clusterState {
// ...
clusterNode *importing_slots_from[16384];
// ...
} clusterState;
- 重新分片会对目标节点发送命令CLUSTER SETSLOT (i) IMPORTING (source_id)那么这个i就可以设置目标的节点的clusterState.importing_slots_from[i]=source_id代表的clusterNode结构。
- 例子,向7003发送这个命令,说明7003正在从这个source_id上面导入槽16198
# 9dfb...
是节点7002
的ID
127.0.0.1:7003> CLUSTER SETSLOT 16198 IMPORTING 9dfb4c4e016e627d9769e4c9bb0d4fa208e65c26
OK
17.5.2 CLUSTER SETSLOT MIGRATING命令的实现
- 如果migrating_slots_to[i]的值不为NULL,那么指向的这个clusterNode,这个节点就是当前节点迁移槽i去的节点。
typedef struct clusterState {
// ...
clusterNode *migrating_slots_to[16384];
// ...
} clusterState;
- 重新分片会对源节点发送CLUSTER SETSLOT (i)MIGRATING (targetid)
- 比如对7002执行这个命令,那么他的clusterState.migrating_slots_to数组就会加上7003这个迁移的节点。
# 0457...
是节点7003
的ID
127.0.0.1:7002> CLUSTER SETSLOT 16198 MIGRATING 04579925484ce537d3410d7ce97bd2e260c459a2
OK

17.5.3 ASK错误
- 意思就是首先向源节点查找命令要操作的键,有就执行
- 没有那么就返回ASK错误,并且转移到正在转移的目标节点去处理命令。

[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-yUAscAWA-1637333363309)(C:/Users/11914/AppData/Roaming/Typora/typora-user-images/image-20211119142329843.png)]
17.5.4 ASKING命令
- 这个命令主要就是打开客户端的REDIS_ASKING标识。
- 如果客户端发送一个关于槽i的命令,刚好槽i没有指派这个节点,返回moved错误,并且重定向,又发现槽i正在迁移到当前的这个节点。意思就是你要给槽i加上东西,刚好槽i还没指派给当前节点,比如A节点现在要处理槽i,但是槽i没有指派A节点,问题是现在槽i原本指派的B节点,正在修改槽i的指派为A节点,刚好客户端又有REDIS_ASKING说明了A节点确实就是正在导入,但是还没有修改clusterState,这个时候就破例直接在A节点进行这个命令执行。
def ASKING():
#
打开标识
client.flags |= REDIS_ASKING
#
向客户端返回OK
回复
reply("OK")

- 向正在导入槽16198的节点7003发送以下命令,但是槽16198仍然指派7002,这个时候发送get前先发送一下ASKING命令,那么get命令就会让7003来进行执行。意思就是在执行get的时候先发送asking命令,那么命令就会被当前导入的节点执行。
$ ./redis-cli -p 7003
127.0.0.1:7003> GET "love"
(error) MOVED 16198 127.0.0.1:7002
17.5.5 ASK错误和MOVED错误的区别
- moved错误只是当前节点没有指派这个槽的意思。
- ASK错误就是两个节点正在迁移的一个临时措施。这个错误会把命令转移到正在迁移的节点上去执行和处理。
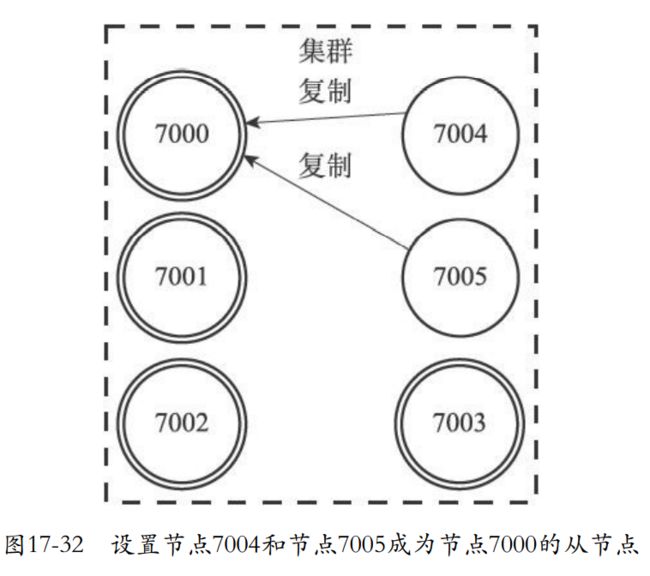
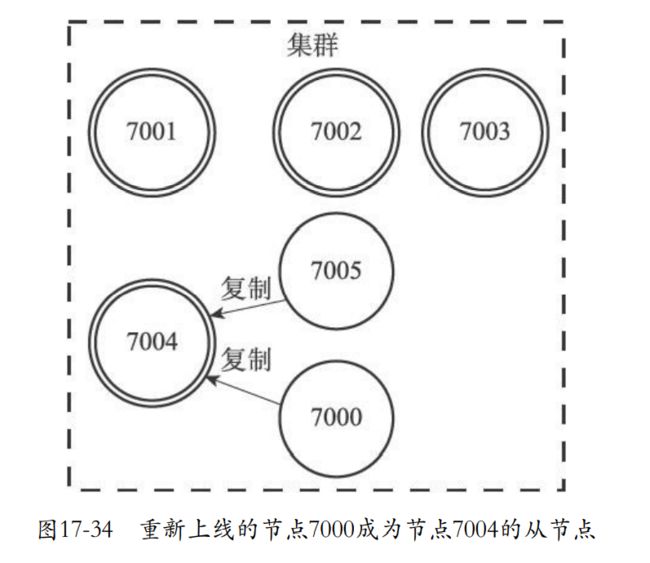
17.6 复制与故障转移
- 主节点用于处理槽,从节点负责复制主节点。
- 下面的7004和7005就是在复制这个7000主节点。如果主节点下线,从节点可以代替主节点来接收和处理命令请求。重新上线的主节点会成为新节点的从节点。

17.6.1 设置从节点
- 发送下面的命令,并且指定要复制节点的id。
CLUSTER REPLICATE
- 接收到这个命令的节点会在clusterState.nodes找到node_id对应的节点clusterNode结构,并且把自己的clusterState.myself.slaveof指向这个节点,记录节点正在复制那个节点。
- 然后修改clusterState.myself.flags属性,关闭原本的REDIS_NODE_MASTER标识,打开REDIS_NODE_SLAVE标识。标识节点已经是一个从节点了。
- 接着就是复制主节点的代码。
struct clusterNode {
// ...
//
如果这是一个从节点,那么指向主节点
struct clusterNode *slaveof;
// ...
};
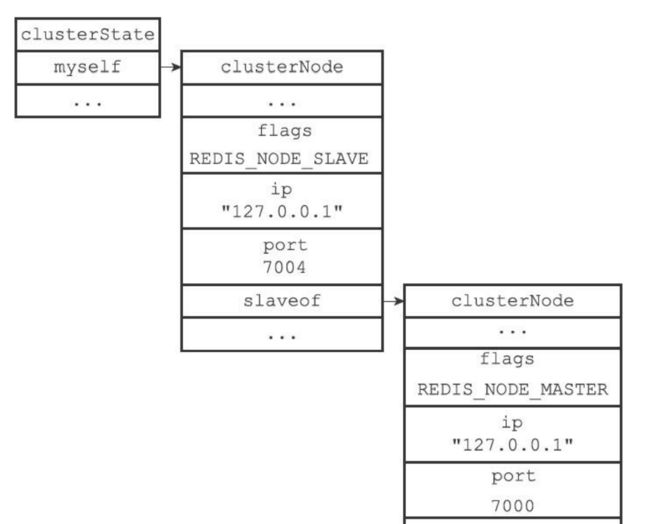
- 下面的这个例子就是7004节点复制主节点7001的图。就是按照上面的步骤,发送slaveof,然后找到nodes的目标节点clusterNode的结构,然后设置为myself上的slaveof指向节点。
- 然后就会把7004节点复制7001节点的信息发布到集群。
- 集群的所有节点都会在代表主节点的clusterNode的salves和numslaves记录复制节点的名单。
struct clusterNode {
// ...
//
正在复制这个主节点的从节点数量
int numslaves;
//
一个数组
//
每个数组项指向一个正在复制这个主节点的从节点的clusterNode
结构
struct clusterNode **slaves;
// ...
};
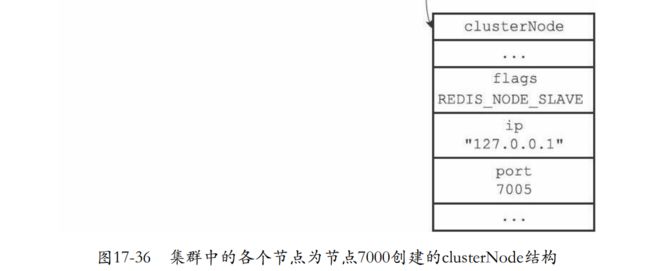
- 比如下面的例子,7000的两个从节点都保存到了7000的clusterNode结构上的slaves。

17.6.2 故障检测
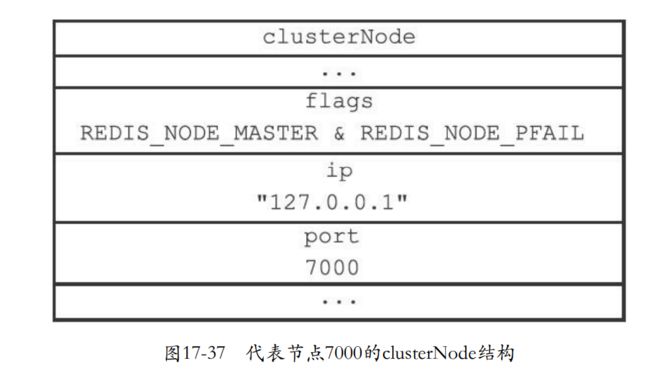
- 集群每个节点定期向其他节点发送ping,如果规定时间没有返回说明节点可能下线了。那么就会把这个节点标记REDIS_NODE_PFAIL。
- 下面就是7001测试7000的时候,发现没有回复,7001就会在nodes字典找到7000标记为REDIS_NODE_PFAIL(疑似下线),如果是fail那么就是下线
- 当节点A得知B节点认为C节点下线,那么就会找到C节点的结构,并且把这个消息存入fail_reports链表中,这个链表记录了所有其他节点对这个节点的下线报告。
- clusterNodeFailReport结构每个下线报告都是这个结构。
struct clusterNode {
// ...
//
一个链表,记录了所有其他节点对该节点的下线报告
list *fail_reports;
// ...
};
struct clusterNodeFailReport {
//
报告目标节点已经下线的节点
struct clusterNode *node;
//
最后一次从node
节点收到下线报告的时间
//
程序使用这个时间戳来检查下线报告是否过期
//
(与当前时间相差太久的下线报告会被删除)
mstime_t time;
} typedef clusterNodeFailReport;
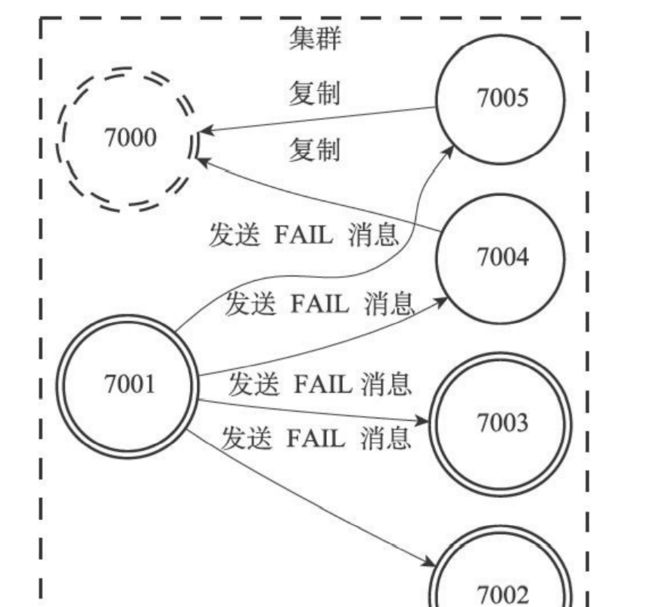
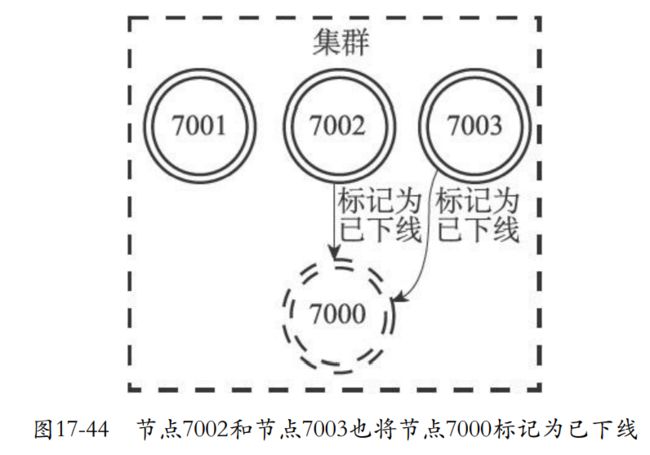
- 假如7002和7003认为7000下线,那么都会给下线node的链表添加下线报告。
- 如果半数认为节点下线,那么就会把它标记为FAIL也就是下线的意思。而且还要广播这个节点下线的信息。

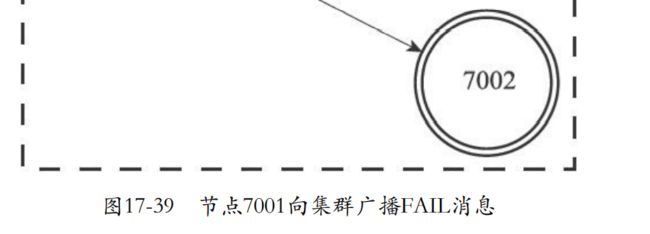
- 比如下面这个就是7001、7002、7003都认为7000已经下线。这个时候7001就会广播一条7000已经下线的信息。
17.6.3 故障转移
- 选择一个故障节点的从节点
- 执行slaveof no one成为主节点
- 主节点的槽指派到新的节点
- 广播pong信息,让大家知道新的主节点
- 新主节点开始接收槽的命令请求
17.6.4 选举新的主节点
- 集群的配置纪元是自增计数器,一开始是0
- 某个节点进行故障转移那么纪元+1
- 集群每个主节点有一次投票机会,如果从节点要求主节点投票给他,那么主节点就投票
- 当从节点发现主节点已经下线,就会广播CLUSTERMSG_TYPE_FAILOVER_AUTH_REQUEST要求主节点投票给这个从节点
- 主节点如果返回CLUSTERMSG_TYPE_FAILOVER_AUTH_ACK,说明它支持这个从节点成为主节点。
- 从节点根据自己接受到的信息个数统计得到多少个主节点的支持
- 如果从节点收到一半的主节点支持票n/2+1那么就可以成为新的主节点。
- 每个配置纪元,主节点只能投一次,所以只能有一个超过半数的从节点,保证新的主节点只有一个
- 如果失败,那么进入下一个纪元。纪元自增重新进行投票。
17.7 消息
- 节点通过消息来进行交互
- 消息类型
- meet消息:这个就是发送者请求接受者加入到集群中。
- PING消息:测试是否在线
- PONG消息:接收到meet或者是ping那么就要回复一个pong消息。也可以发送pong广播自己的消息,更新其它节点的认知,比如主节点的切换
- publish消息:如果收到一个publish命令,广播给其它节点,并且一起执行。

消息通过两个部分组成,包括消息头和消息正文。
17.7.1 消息头
- 主要记录发送者的信息。这是一个clusterMsg结构。
typedef struct {
//
消息的长度(包括这个消息头的长度和消息正文的长度)
uint32_t totlen;
//
消息的类型
uint16_t type;
//
消息正文包含的节点信息数量
//
只在发送MEET
、PING
、PONG
这三种Gossip
协议消息时使用
uint16_t count;
//
发送者所处的配置纪元
uint64_t currentEpoch;
//
如果发送者是一个主节点,那么这里记录的是发送者的配置纪元
//
如果发送者是一个从节点,那么这里记录的是发送者正在复制的主节点的配置纪元
uint64_t configEpoch;
//
发送者的名字(ID
)
char sender[REDIS_CLUSTER_NAMELEN];
//
发送者目前的槽指派信息
unsigned char myslots[REDIS_CLUSTER_SLOTS/8];
//
如果发送者是一个从节点,那么这里记录的是发送者正在复制的主节点的名字
//
如果发送者是一个主节点,那么这里记录的是REDIS_NODE_NULL_NAME
//
(一个40
字节长,值全为0
的字节数组)
char slaveof[REDIS_CLUSTER_NAMELEN];
//
发送者的端口号
uint16_t port;
//
发送者的标识值
uint16_t flags;
//
发送者所处集群的状态
unsigned char state;
//
消息的正文(或者说,内容)
union clusterMsgData data;
} clusterMsg;
- clusterMsg.data指向的结构是cluster.h/clusterMsgData也就是正文
union clusterMsgData {
// MEET
、PING
、PONG
消息的正文
struct {
//
每条MEET
、PING
、PONG
消息都包含两个
// clusterMsgDataGossip
结构
clusterMsgDataGossip gossip[1];
} ping;
// FAIL
消息的正文
struct {
clusterMsgDataFail about;
} fail;
// PUBLISH
消息的正文
struct {
clusterMsgDataPublish msg;
} publish;
//
其他消息的正文...
};
- clusterMsg包括currentEpoch,sender,myslots发送者自身的属性。然后接受者就可以通过nodes字典找到发送者的实例结构并且更新。
17.7.2 MEET、PING、PONG消息的实现
- Gossip协议交换不同节点的状态信息。协议由三个消息组成MEET、PING、PONG
- 消息的结构。都是clusterMsgData组成。
- 消息正文结构相同,所以需要通过消息头的type指定消息的类型。
union clusterMsgData {
// ...
// MEET
、PING
和PONG
消息的正文
struct {
//
每条MEET
、PING
、PONG
消息都包含两个
// clusterMsgDataGossip
结构
clusterMsgDataGossip gossip[1];
} ping;
//
其他消息的正文...
};
- 发送者会随机选中自己已知的两个节点封装到 clusterMsgDataGossip中。
- 记录了最后一次节点发送给被选中节点的ping和pong的时间戳,还有被选中节点的ip和端口号。
typedef struct {
//
节点的名字
char nodename[REDIS_CLUSTER_NAMELEN];
//
最后一次向该节点发送PING
消息的时间戳
uint32_t ping_sent;
//
最后一次从该节点接收到PONG
消息的时间戳
uint32_t pong_received;
//
节点的IP
地址
char ip[16];
//
节点的端口号
uint16_t port;
//
节点的标识值
uint16_t flags;
} clusterMsgDataGossip;
- 当接受者接收到的时候并根据自己是否认识这两个节点进行操作
- 如果不存在那么就要跟这些节点进行一个握手
- 存在那么就更新nodes字典上的信息就可以了。

17.7.3 FAIL消息的实现
- 如果A认为B已经下线,那么就会广播B的FAIL信息。
- 如果使用Grossip传播就会相对有延迟,因为还要做节点更新,查找两个节点等。
- FAIL需要整个集群立刻知道。所以FAIL的结构也是有所不同cluster.h/clusterMsgDataFail
- 这个结构只有下线的节点的名字。就能够立刻找到节点并且判断下线。
typedef struct {
char nodename[REDIS_CLUSTER_NAMELEN];
} clusterMsgDataFail;


17.7.4 PUBLISH消息的实现
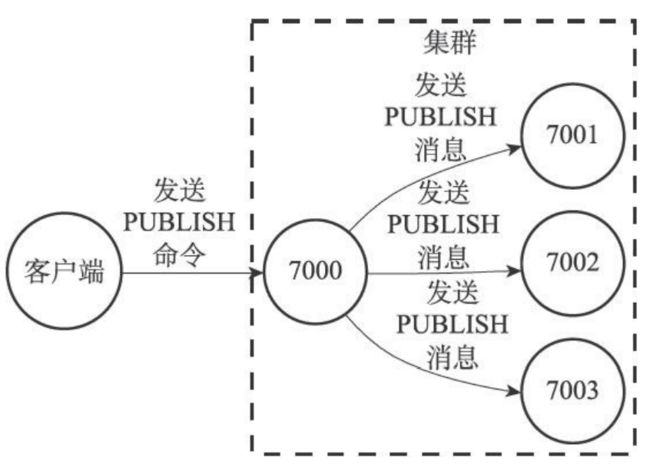
- 客户端可以向某个节点发送pubish channel message命令,接收命令之后会广播这条信息而且还会发送到频道上。所有接收到publish的节点都会发送消息到频道。
- 意思就是publish会导致集群所有节点都发送消息到频道上。相当于就是一个节点收到publish命令,广播publish消息到其它节点,那么其他节点才会执行publish命令发送消息到频道上。
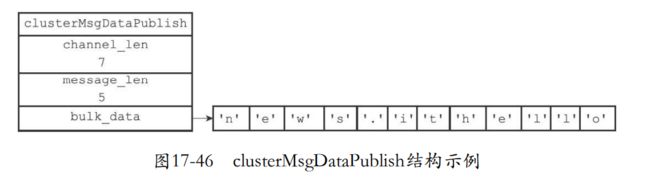
- publish消息正文的结构cluster.h/clusterMsgDataPublish
- bulk_data:保存channel参数和message参数
- 然后就是channel参数的长度和message的长度。
typedef struct {
uint32_t channel_len;
uint32_t message_len;
//
定义为8
字节只是为了对齐其他消息结构
//
实际的长度由保存的内容决定
unsigned char bulk_data[8];
} clusterMsgDataPublish;
17.8 重点回顾
- 节点可以通过握手来把其它节点添加到自己的集群
- 集群上线需要分配所有的槽给指定的节点
- 节点收到命令首先判断槽是不是自己管理,不是那么就返回moved之后让客户端重新定向
- 对于重新分片工作是交给redis-trib进行处理的。主要就是把源节点槽转移到目标节点。槽转移也可以说是部分键值对的转移。
- 如果A正在迁移槽i到B,假设访问A没有访问到某个键值对,那么就会返回ASK错误,并且重定向到B去执行命令访问。
- moved解决的是槽访问重定向,ask错误只是迁移槽的临时措施
- 集群通过发送接收消息得到集群的所有节点状态和认知。包括meet也就是发送请求让目标节点加入到集群,ping大部分时候检测是否在线,pong广播FAIL节点,回应meet和ping消息,publish就是用于广播消息,并且让集群发送消息到频道。FAIL消息就是快速解决广播某个节点已经下线的问题。
第18章 发布与订阅
- 订阅和发布的功能命令PUBLISH、SUBSCRIBE、PSUBSCRIBE
- 通过subscribe客户端可以订阅一个或者是多个频道。
- 假设SUBSCRIBE “news.it”
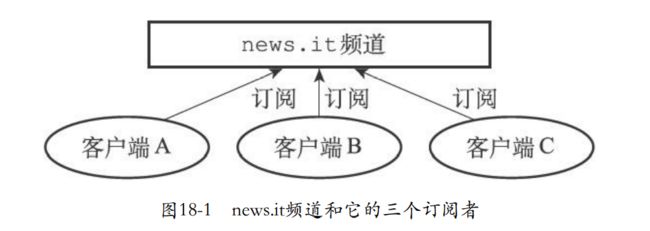
- PUBLISH “news.it” "hello"执行命令

-
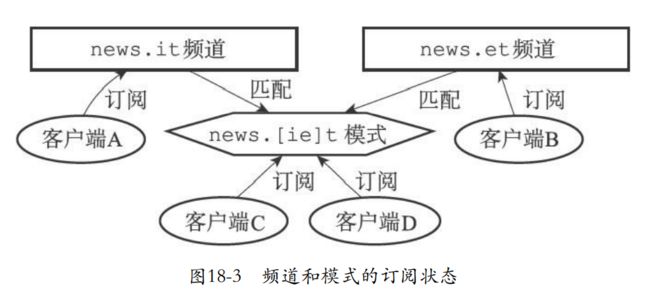
除了订阅频道。客户端还能够通过psubscribe来订阅一个或者是多个模式,成为模式的订阅者。这个模式其实也可以说是多个频道的抽象,只要频道符合规范,那么就能够加入到这个模式
-
下面这个例子的模式就是news.[ie]t,也就是频道的名字里面只要是it或者ie都能够匹配成功模式,订阅模式的客户端相当于订阅了多个频道。
- 比如现在发送一个消息到new.it频道,那么就会发送给模式和客户端a,还会模式发送消息到订阅的C和D
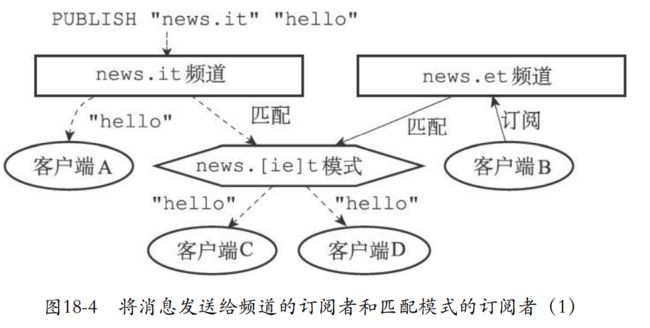
- et也是同样的操作。

18.1 频道的订阅与退订
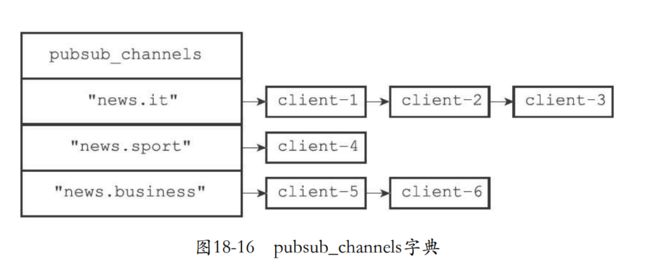
- 对于客户端和频道的订阅,它会关联到redisServer的pubsub_channels字典,字典的键是频道,值是一个链表,串联着所有订阅的客户端。
- 下面就是一个示例。
struct redisServer {
// ...
//
保存所有频道的订阅关系
dict *pubsub_channels;
// ...
};

18.1.1 订阅频道
-
当客户端执行subscribe的时候就会在pubsub_channels字典上面进行关联,根据是否存在其他订阅者进行操作
- 如果有就加入到链表尾巴
- 没有那么这个频道肯定没有存在于这个pubsub_channels,那么创建键值对,并且把订阅者加入到链表中。
-
比如下面的例子客户端执行了命令SUBSCRIBE “news.sport” “news.movie”,这个sport有链表直接加入尾巴,movie没有所以需要创建键,然后创建链表,把客户端加入到链表头。

def subscribe(*all_input_channels):
#
遍历输入的所有频道
for channel in all_input_channels:
#
如果channel
不存在于pubsub_channels
字典(没有任何订阅者)
#
那么在字典中添加channel
键,并设置它的值为空链表
if channel not in server.pubsub_channels:
server.pubsub_channels[channel] = []
#
将订阅者添加到频道所对应的链表的末尾
server.pubsub_channels[channel].append(client)
18.1.2 退订频道
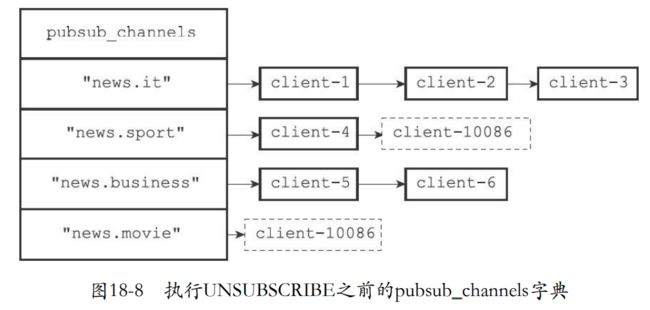
- unsubscribe取消到客户端和pubsub_channels的频道的关联。也就是从链表删除
- 如果发现删除这个订阅者之后链表没有了节点,那么就把频道的键从字典移除。
- 比如UNSUBSCRIBE “news.sport” “news.movie”

18.2 模式的订阅与退订
- 模式的订阅存在了pubsub_patterns属性上
struct redisServer {
// ...
//
保存所有模式订阅关系
list *pubsub_patterns;
// ...
};
- 这个patterns是一个链表,而不是字典。
typedef struct pubsubPattern {
//
订阅模式的客户端
redisClient *client;
//
被订阅的模式
robj *pattern;
} pubsubPattern;

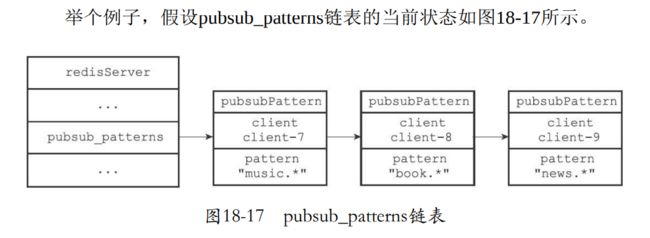
- 下面就是client7订阅music.*,client8订阅 book. *,然后就是client-9正在订阅模式"news. *发现他们都是一个链表串起来。
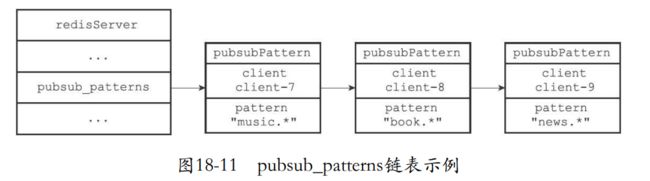
18.2.1 订阅模式
- 如果客户端执行psubscribe的时候,有两个操作
- 新创建一个pubsubPattern结构,并且结构pattrn设置为被订阅模式,client设置为客户端
- 然后加入到链表尾巴
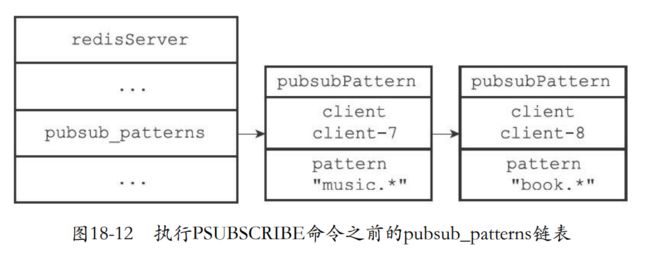
- 比如执行PSUBSCRIBE “news.*”

18.2.2 退订模式
- 简单来说就是直接从链表删除模式和客户端的关联。
18.3 发送消息
publish信息的时候
- 消息发送给所有订阅者
- 并且发送给模式的订阅者。
18.3.1 将消息发送给频道订阅者
- 直接在redisServer找到pubsub_channels字典获取频道所有订阅者
- 当某个客户端执行PUBLISH “news.it” "hello"那么就会发送消息到这些订阅者。
def channel_publish(channel, message):
#
如果channel
键不存在于pubsub_channels
字典中
#
那么说明channel
频道没有任何订阅者
#
程序不做发送动作,直接返回
if channel not in server.pubsub_channels:
return
#
运行到这里,说明channel
频道至少有一个订阅者
#
程序遍历channel
频道的订阅者链表
#
将消息发送给所有订阅者
for subscriber in server.pubsub_channels[channel]:
send_message(subscriber, message)
18.3.2 将消息发送给模式订阅者
- 为了把消息发送给匹配的模式,需要遍历整个pubsub_patterns链表。找到对应的模式,并且发送。
18.4 查看订阅信息
- pubsub可以查看频道和模式的信息。
18.4.1 PUBSUB CHANNELS
- 这个命令用于返回服务器被订阅的频道,PUBSUB CHANNELS[pattern]
- 如果有pattern参数那么就返回和pattern匹配的频道
- 否则就是返回所有的频道。
def pubsub_channels(pattern=None):
#
一个列表,用于记录所有符合条件的频道
channel_list = []
#
遍历服务器中的所有频道
#
(也即是pubsub_channels
字典的所有键)
for channel in server.pubsub_channels:
#
当以下两个条件的任意一个满足时,将频道添加到链表里面:
#1
)用户没有指定pattern
参数
#2
)用户指定了pattern
参数,并且channel
和pattern
匹配
if (pattern is None) or match(channel, pattern):
channel_list.append(channel)
#
向客户端返回频道列表
return channel_list
- 展示频道。
redis> PUBSUB CHANNELS
1) "news.it"
2) "news.sport"
3) "news.business"
4) "news.movie"

18.4.2 PUBSUB NUMSUB
- PUBSUB NUMSUB[channel-1 channel-2…channel-n]返回频道的订阅者数量
- 下面就是示例
redis> PUBSUB NUMSUB news.it news.sport news.business news.movie
1) "news.it"
2) "3"
3) "news.sport"
4) "2"
5) "news.business"
6) "2"
7) "news.movie"
8) "1"
def pubsub_numsub(*all_input_channels):
#
遍历输入的所有频道
for channel in all_input_channels:
#
如果pubsub_channels
字典中没有channel
这个键
#
那么说明channel
频道没有任何订阅者
if channel not in server.pubsub_channels:
#
返回频道名
reply_channel_name(channel)
#
订阅者数量为0
reply_subscribe_count(0)
#
如果pubsub_channels
字典中存在channel
键
#
那么说明channel
频道至少有一个订阅者
else:
#
返回频道名
reply_channel_name(channel)
#
订阅者链表的长度就是订阅者数量
reply_subscribe_count(len(server.pubsub_channels[channel]))

18.4.3 PUBSUB NUMPAT
- 返回订阅模式的数量。直接返回链表的长度。
18.5 重点回顾
- pubsub_channels字典保存所有频道和客户端的关系
- pubsub_pattrerns保存了客户端和模式之间的关系,它是一个链表结构。
- publish可以发送消息给所有订阅这个频道的订阅者。模式也是一样的逻辑
- pubsub可以读取频道数量,订阅频道的订阅者数量还有就是模式的数量。
第19章 事务
- redis通过muti、exec和watch命令来完成事务
19.1 事务的实现
- 事务开始
- 事务入队
- 事务执行。
19.1.1 事务开始
- multi命令可以让redis进入事务状态,打开事务标识
redis> MULTI
OK
def MULTI():
打开事务标识
client.flags |= REDIS_MULTI
#
返回OK
回复
replyOK()
19.1.2 命令入队
- 开启事务就是把这些命令入队
- 当客户端执行命令EXEC、DISCARD、WATCH、MULTI那么就能立即执行入队命令。
- 如果执行的是EXEC、DISCARD、WATCH、MULTI之外的命令,那么命令是不会执行的
redis> SET "name" "Practical Common Lisp"
OK
redis> GET "name"
"Practical Common Lisp"
redis> SET "author" "Peter Seibel"
OK
redis> GET "author"
"Peter Seibel"

19.1.3 事务队列
- 事务状态维护到客户端状态的mstate。
typedef struct redisClient {
// ...
//
事务状态
multiState mstate; /* MULTI/EXEC state */
// ...
} redisClient;
- mstate里面包含了一个命令队列
typedef struct multiState {
//
事务队列,FIFO
顺序
multiCmd *commands;
//
已入队命令计数
int count;
} multiState;
- 命令队列是一个mutiCmd结构的数组,每个multiCmd包含了指向命令的函数,命令参数和参数数量。
typedef struct multiCmd {
//
参数
robj **argv;
//
参数数量
int argc;
//
命令指针
struct redisCommand *cmd;
} multiCmd;
- 比如下面执行几条命令,形成的一个结构。
redis> MULTI
OK
redis> SET "name" "Practical Common Lisp"
QUEUED
redis> GET "name"
QUEUED
redis> SET "author" "Peter Seibel"
QUEUED
redis> GET "author"
QUEUED
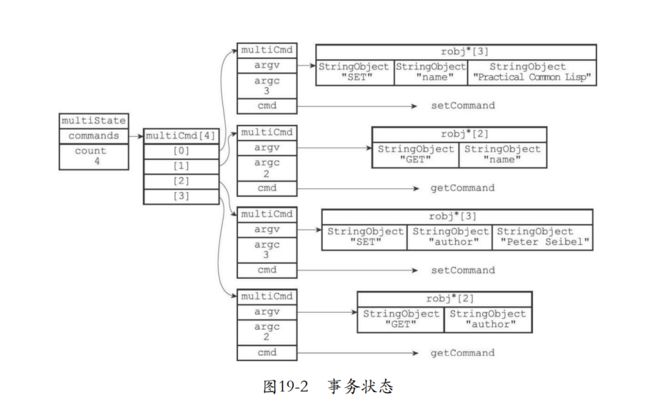
19.1.4 执行事务
- exec之后就会按照命令在队列的顺序执行命令。
19.2 WATCH命令的实现
- watch是一个乐观锁。它会监视任意数量的数据库键,如果发现键在事务执行之前被修改,那么就拒绝执行事务
redis> WATCH "name"
OK
redis> MULTI
OK
redis> SET "name" "peter"
QUEUED
redis> EXEC
(nil)
19.2.1 使用WATCH命令监视数据库键
- watched_keys就是一个数据库的监视键的字典,key就是被监视的键,值就是监视对应键值对的客户端。这个值的结构是一个链表。
- 下面可以看出c1和c2监视name,c3监视age
typedef struct redisDb {
// ...
//
正在被WATCH
命令监视的键
dict *watched_keys;
// ...
} redisDb;
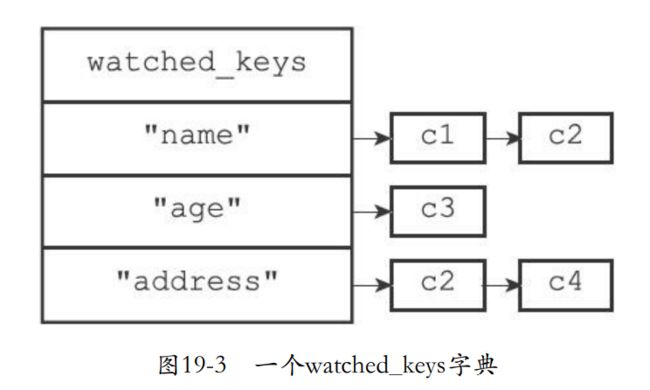
19.2.2 监视机制的触发
- 所有对键值对进行修改的命令都会调用函数multi.c/touchWatchKey函数watched_keys字典,查看是不是有客户端监视的键,如果有那么就会把监视它的客户端的REDIS_DIRTY_CAS标识打开,表示事务的安全性已经被破坏。
def touchWatchKey(db, key):
#
如果键key
存在于数据库的watched_keys
字典中
#
那么说明至少有一个客户端在监视这个key
if key in db.watched_keys:
#
遍历所有监视键key
的客户端
for client in db.watched_keys[key]:
#
打开标识
client.flags |= REDIS_DIRTY_CAS
19.2.3 判断事务是否安全
- 当事务要exec的时候首先看看客户端的REDIS_DIRTY_CAS判断事务是不是安全的。
- 如果标识被打开,那么就拒绝执行
- 否则那么就是安全可以执行。
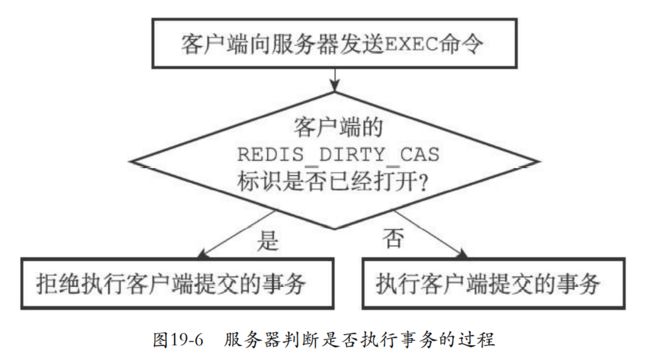
19.3 事务的ACID性质
19.3.1 原子性
- 原子性就是整个事务的所有命令必须一次执行完。要么就不执行
- redis事务不支持回滚
19.3.2 一致性
- 这里的一致性就是保证数据要符合数据库的规范
- 三个可能出错的地方
- 入队错误
命令不存在或者是命令格式不对,那么redis就会拒绝执行这个命令。
- 执行错误
事务的执行错误
- 比如对数据库键执行了错误类型的操作
- 服务器停机
- 无持久化的内存模式,宕机之后恢复的数据库还是空白
- RDB文件持久化,恢复数据库依靠RDB,和RDB的数据一致
19.3.3 隔离性
- 事务之间分隔开,不会互相影响。
- 事务串行执行,因为redis是一个单线程方式执行事务。
19.3.4 耐久性
- 这个持久性依靠的是RDB(关键是bgsave一定要同步到磁盘)或者是AOF
- 存入磁盘的才具有耐久性
19.4 重点回顾
- 事务提供了一次性、有序的执行多个命令机制
- 多个命令在事务是进入到事务队列,先进先出执行。
- 带有watch命令的事务执行会看看服务器的watched_keys字典看对应的键关联了什么客户端,并且打开标识REDIS_DIRTY_CAS
- 只要客户端的REDIS_DIRTY_CAS没有被打开,那么才能执行修改命令。
第21章 排序
- sort命令可以给集合键,列表键等进行排序
redis> RPUSH numbers 5 3 1 4 2
(integer) 5
#
按插入顺序排列的列表元素
redis> LRANGE numbers 0 -1
1) "5"
2) "3"
3) "1"
4) "4"
5) "2"
#
按值从小到大有序排列的列表元素
redis> SORT numbers
1) "1"
2) "2"
3) "3"
4) "4"
5) "5"
- sort+alpha选项。
redis> SADD alphabet a b c d e f g
(integer) 7
#
乱序排列的集合元素
redis> SMEMBERS alphabet
1) "d"
2) "a"
3) "f"
4) "e"
5) "b"
6) "g"
7) "c"
#
排序后的集合元素
redis> SORT alphabet ALPHA
1) "a"
2) "b"
3) "c"
4) "d"
5) "e"
6) "f"
7) "g"
- sort+by选项。下面的例子就是按照序号的权重进行排序。
redis> ZADD test-result 3.0 jack 3.5 peter 4.0 tom
(integer) 3
#
按元素的分值排列
redis> ZRANGE test-result 0 -1
1) "jack"
2) "peter"
3) "tom"
#
为各个元素设置序号
redis> MSET peter_number 1 tom_number 2 jack_number 3
OK
#
以序号为权重,对有序集合中的元素进行排序
redis> SORT test-result BY *_number
1) "peter"
2) "tom"
3) "jack"
21.1 SORT命令的实现
sort numbers的全部步骤
- 创建一个和numbers列表相同的数组,每个选项都是redis.h/redisSortObject结构
- 遍历数组,并且让obj指针指向numbers列表的每个项
- 遍历数组,把指向的列表项,转换成一个double类型的浮点数,保存在每个数组项的u.score

- 根据数组的u.score来进行排序。
- 遍历数组,返回排序后的结果。
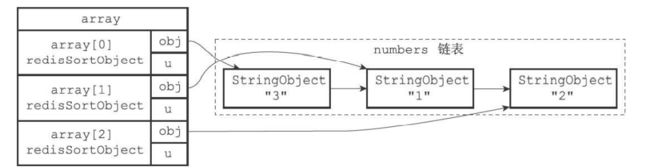

排序后的数组。
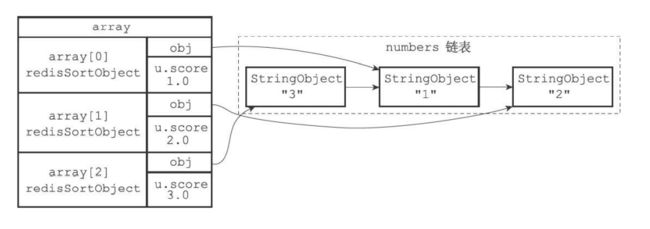
redis> RPUSH numbers 3 1 2
(integer) 3
redis> SORT numbers
1) "1"
2) "2"
3) "3"
- redisSortObject结构的完整定义
typedef struct _redisSortObject {
//
被排序键的值
robj *obj;
//
权重
union {
//
排序数字值时使用
double score;
//
排序带有BY
选项的字符串值时使用
robj *cmpobj;
} u;
} redisSortObject;
21.2 ALPHA选项的实现
- 按照字母的顺序来排序。
redis> SADD fruits apple banana cherry
(integer) 3
#
元素在集合中是乱序存放的
redis> SMEMBERS fruits
1) "apple"
2) "cherry"
3) "banana"
#
对fruits
键进行字符串排序
redis> SORT fruits ALPHA
1) "apple"
2) "banana"
3) "cherry"
- 完整步骤
- 创建一个redisSortObject数组,数组的长度等于fruits集合的大小。
- 遍历数组指向fruits的元素
- 根据obj指针的字符串进行一个排序。
- 遍历数组返回排序结果
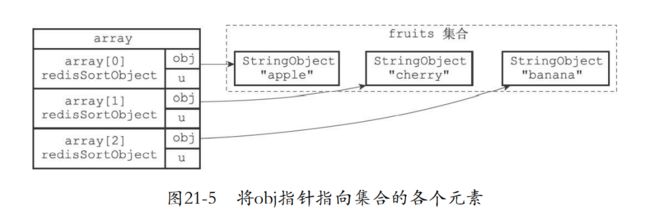

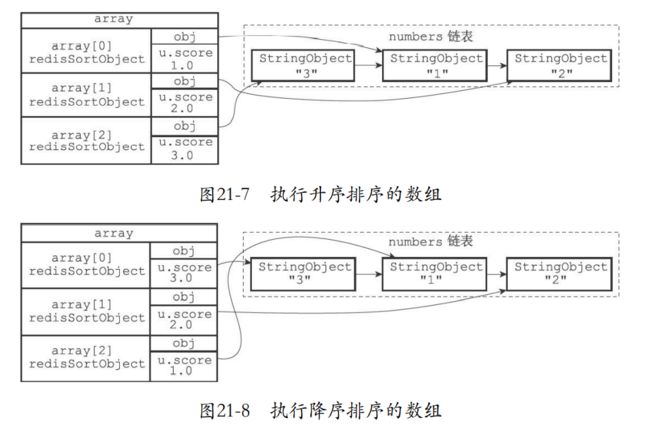
21.3 ASC选项和DESC选项的实现
- asc就是普通的升序排序
- desc就是降序
SORT
SORT ASC
SORT DESC
- 他们都是由快速排序算法排序。只不过是对比的方式不同。
21.4 BY选项的实现
- 这种相当于就是重新选定排序的权重
- sort命令可以指定某些字符串键,或者某个哈希键作为元素的权重,比如下面的例子apple指定的apple-price。设置了多个字符串键,然后通过sort指定用于对比的字符串键,来排序这个集合。
redis> SADD fruits "apple" "banana" "cherry"
(integer) 3
redis> SORT fruits ALPHA
1) "apple"
2) "banana"
3) "cherry"
redis> MSET apple-price 8 banana-price 5.5 cherry-price 7
OK
redis> SORT fruits BY *-price
1) "banana"
2) "cherry"
3) "apple"
步骤
- 创建redisSortObject数组
- 数组项指向fruits元素
- 根据by给定的模式查找权重键,比如apple返回的是apple-price,banana返回的是banana-price进行排序。fruits类表
- 然后根据各个权重键的值计算出浮点数,保存到u.score,最后再进行排序。

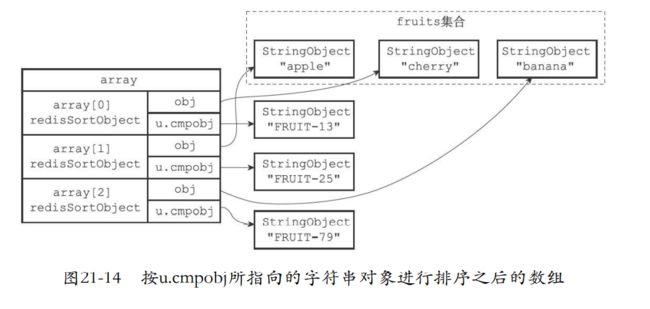
21.5 带有ALPHA选项的BY选项的实现
- by默认是数字排序,但是如果是字符串,那么就要让cmpobj指向这个字符串键,并且进行排序。
redis> SADD fruits "apple" "banana" "cherry"
(integer) 3
redis> MSET apple-id "FRUIT-25" banana-id "FRUIT-79" cherry-id "FRUIT-13"
OK
redis> SORT fruits BY *-id ALPHA
1)"cherry"
2)"apple"
3)"banana"
实现步骤
- 创建一个redisSortObject结构数组
- 遍历数组,将各个数组项的obj指针分别指向fruits集合的各个元 素
- 找到by后面的权重键
- 将各项的u.cmpobj指针指向权重键,如果是数字就直接计算出double。
- 对数组权重键为权重进行字符串排序。
- 最后就是遍历数组返回给客户端了。
还没排序
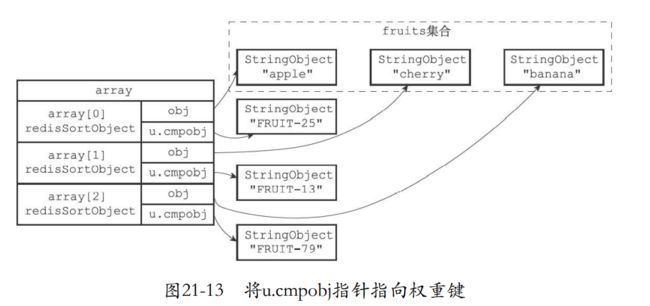
排好序的数组
21.6 LIMIT选项的实现
- limit选项可以限制排序之后返回部分
- offset表示要跳过的部分
- count表示表示跳过之后要返回的数量。
redis> SORT alphabet ALPHA LIMIT 0 4
1) "a"
2) "b"
3) "c"
4) "d"
步骤
- 创建一个redisSortObject结构数组,数组的长度等于alphabet集合 的大小
- 遍历数组,将各个数组项的obj指针分别指向alphabet集合的各个 元素
- 然后根据元素的字符串进行排序
- 根据limit 0 4指针移动到0并且依次访问4个并且返回。
21.7 GET选项的实现
- 这个其实就是排序之后按照某种格式输出
- 比如现在我排序了1,2,3,但是我可以设置另外几个键值对,one,two,three,最后排序完我可以参照另外对应的几个键值对输出。类似于别名的意思。
21.10 重点回顾
- sort命令大部分时候都是直接创建数组,然后指向元素项,计算出排序值,或者是直接通过字符串大小进行比较和排序
- 如果是alpha那么就是字符串的排序
- 排序通常都是通过快排完成。
- by可以通过其他对应键值对作为权重键来排序
- limit可以限制输出的元素
- get类似于别名