CNN进展:AlexNet、VGGNet、ResNet 和 Inception
一、说明
二、探索 AlexNet:突破性的深度卷积网络
AlexNet 代表了深度卷积网络的开创性应用之一,真正重塑了机器学习领域。2012 年,这一革命性模型在 ImageNet LSVRC-2012 挑战赛中以 84.7% 的准确率夺得冠军,远远超过了第二名的 73.8% 的准确率。
AlexNet 的核心是其架构,包括五个卷积 (CONV) 层和三个全连接 (FC) 层。AlexNet 选择整流线性单元 (ReLU) 作为其激活函数,这一战略举措对其令人印象深刻的性能做出了重大贡献。这是网络内各个层的结构快照:
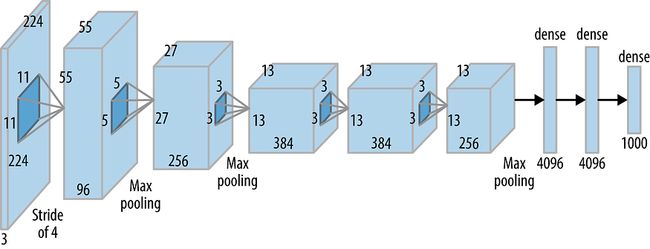
AlexNet 架构(来源:oreilly.com)
这是 AlexNet 的框图:

整个网络由大约 6200 万个可训练参数组成,这些参数协调工作以提供令人震惊的结果。
输入和输出尺寸:
AlexNet 接收大小为 227x227x3 的输入,并以 1000x1 概率向量的形式返回输出,每个元素对应于一个特定的类。
ReLU 革命:
在 AlexNet 出现之前,sigmoid 和 tanh 等激活函数是常态。然而,这些函数很容易受到梯度消失(VG)问题的影响,从而阻碍了训练过程。AlexNet 中引入 ReLU 激活函数避免了这个问题,正如原始论文所证明的那样,使用 ReLU 的网络的错误率比使用 tanh 非线性的相同网络快大约六倍。
尽管 ReLU 有许多优点,但由于其无界性质,可能会导致学习变量过大。为了解决这个问题,AlexNet 实施了本地响应标准化 (LRN)。LRN 促进激活的神经元与其周围对应神经元之间的平衡,从而增强网络的整体稳定性。
克服过度拟合:
AlexNet 的另一个值得注意的贡献是其对抗过度拟合的策略。AlexNet 采用 dropout 层,其中每个连接在训练期间有 50% 的机会被暂时“丢弃”或忽略。这种随机省略连接可以防止模型陷入过度拟合的陷阱,并帮助其避开不利的局部最小值。作为权衡,模型收敛所需的迭代次数可能会增加一倍,但模型的整体鲁棒性和准确性会显着提高。
三、VGGNet:深入探讨
时代:
2014 年是国际家庭农业和晶体学年,也是机器学习的里程碑时刻。它见证了机器人首次登陆彗星以及罗宾·威廉姆斯的不幸去世。然而,在深度学习领域,VGGNet 正是在这一年诞生的。
目的:
VGGNet 的出现是为了解决减少卷积层参数数量的需求,从而提高模型的效率和训练速度。
该设计:
VGGNet 存在多个版本,例如 VGG16、VGG19 等,根据网络总层数进行区分。以下是 VGG16 架构的说明性细分:
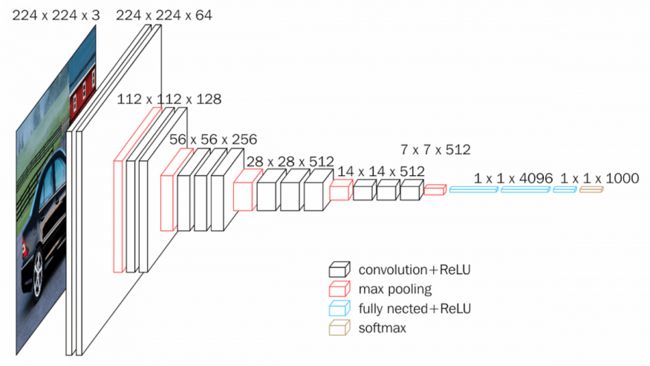
VGG16 框图(来源:neurohive.io)
VGG16 拥有约 1.38 亿个参数。需要强调的一个关键方面是,所有卷积核的大小均为 3x3,最大池核的大小为 2x2,步幅为 2。
优势:
真正的创新在于 3x3 卷积。让我们举个例子。如果我们有一个大小为 5x5x1 的输入层,使用内核大小为 5x5 且步幅为 1 的卷积层将得到 1x1 的输出特征图。然而,通过实现两个步幅为 1 的 3x3 卷积层可以获得相同的输出特征图。好处?5x5 卷积层滤波器需要训练 25 个变量。相比之下,两个内核大小为 3x3 的卷积层总共需要 3x3x2=18 个变量,减少了 28% 的参数。
该技术可以进一步扩展。7x7 卷积层的效果可以通过实现三个 3x3 卷积层来实现,将可训练变量的数量减少 44.9%。其结果是更快的学习和更强的针对过度拟合的鲁棒性。
四、ResNet:跳跃的艺术
问题:
随着卷积神经网络变得更深,当反向传播到初始层时,导数几乎可以忽略不计。
解决方案:
ResNet 通过引入两种类型的“快捷连接”提供了一种巧妙的补救措施:身份快捷方式和投影快捷方式。
架构:
ResNet 拥有多种层数不同的架构,例如 ResNet50 和 ResNet101。由于解决了梯度消失问题的快捷连接,ResNet 模型可以具有更大的深度。
这个概念:
ResNet 的核心是残差块。网络不是学习 x → F(x) 的直接映射,而是学习 x → F(x)+G(x) 的残差映射。恒等连接存在于输入和输出维度相同的地方,而投影连接存在于这些维度不同的地方。
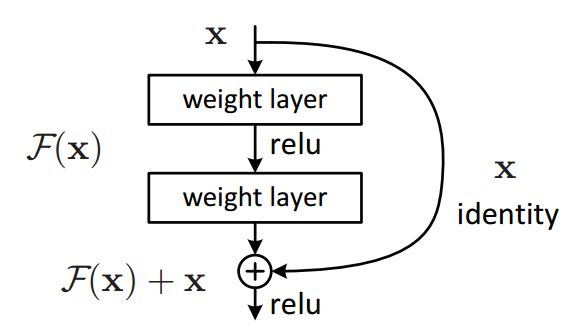
残差块(图片来源:原论文)
投影和身份:
当 F(x) 和 x 的尺寸不同时,将实现投影快捷方式。它调整输入 x 的维度以匹配输出 F(x) 的维度。另一方面,当F(x)和x的维度相同时,使用Identity捷径,这使得网络更容易学习。
五、Inception:广泛发展
动机:
Inception 与 VGGNet 诞生于同一时代,其动机是在图像分类任务中有效识别可变大小特征的需求。Inception 不是仅仅添加更多层(更深),而是通过在同一层中合并不同大小的内核来扩大范围。
架构:
Inception网络由多个Inception模块组成,每个模块包含四个并行操作:
- 1x1 转换层
- 3x3 转换层
- 5x5 转换层
- 最大池化

策略:
Inception扩展了网络空间,让训练相应地决定最有价值的特征和权重。通过允许不同的卷积捕获给定级别的各种特征,所有这些特征在输入到下一层之前都会被提取和连接。
六、CNN:比较快照

从 AlexNet、ResNet-152、VGGNet 和 Inception 的比较中得出了一些见解:
- 尽管 AlexNet 和 ResNet-152 都有大约 60M 参数,但它们的 top-5 准确率大约有 10% 的差异。然而,训练 ResNet-152 需要比 AlexNet 更多的计算量,从而导致训练时间和能耗增加。
- 与 ResNet-152 相比,VGGNet 具有更多的参数和浮点运算 (FLOP),但精度也有所下降。因此,它需要更多的时间来训练,但性能却会下降。
- 训练 AlexNet 所需的时间与训练 Inception 大致相同,但 Inception 所需的内存减少了十倍,并且提供了更高的准确性(大约提高了 9%)。