hive判断重复数据连续并分组
目录
一、需求
二、测试案例
1.测试数据
2.实现步骤
1.判断同一班级进入班级的人是否连续
2.判断出连续的人同一班级同一人每个时间段的开始节点
3.将同一班级同一人每个时间段分组
4.取出同一班级同一人每个时间段的开始时间结束时间
5.按每个时间段按时间顺序拼接出id的值
6.每个时间段拼接好的结果
一、需求
想实现根据时间升序排序取出同班级下一个进入班级的时间,然后判断同一班级上一个人和下一个人是否连续,并生成符合分组条件的连续分组id。
(跟上一篇博文的区别是上一篇适合比较规范的数据,本篇数据质量不高,且数据有同一时间同一分组都重复且跳跃性连续的情况)
二、测试案例
1.测试数据
create table test_detail(
id bigint comment '主键',
num string comment '班级号码',
name string comment '名字',
start_timestamp bigint comment '进入班级时间',
end_timestamp bigint comment '离开班级时间'
)comment '测试数据明细'
row format delimited fields terminated by '\t'
stored as textfile;
--同一班级同一时间戳有2位同学
insert into table test_detail values(1,'01','桑稚',1667516488000,1667516519035);
insert into table test_detail values(2,'01','桑稚',1667516519035,1667516529809);
insert into table test_detail values(3,'01','温以凡',1667516519035,1667516529809);
insert into table test_detail values(4,'01','桑稚',1667516529809,1667516533990);
insert into table test_detail values(5,'01','桑稚',1667516533990,1667516538492);
--同一同学连续进入班级时有2个时间段
insert into table test_detail values(6,'02','段嘉许',1667525190365,1667525196616);
insert into table test_detail values(7,'02','桑延',1667525190365,1667525196616);
insert into table test_detail values(8,'02','段嘉许',1667525196616,1667525203375);
insert into table test_detail values(9,'02','桑延',1667525203375,1667525207599);
insert into table test_detail values(10,'02','段嘉许',1667525207599,1667525224663);
insert into table test_detail values(11,'02','桑延',1667525224663,1667525229056);
insert into table test_detail values(12,'02','段嘉许',1667525224663,1667525229056);
insert into table test_detail values(13,'02','段嘉许',1667525229056,1667525232773);2.实现步骤
1.判断同一班级进入班级的人是否连续
select
id --主键
,num --班级号码
,name --名字
,start_timestamp --进入班级时间
,end_timestamp --离开班级时间
--判断同一班级进入班级的人是否连续
,case when (start_timestamp=lag(end_timestamp) over(partition by num order by start_timestamp asc )
and name=lag(name) over(partition by num order by start_timestamp asc )) or
(end_timestamp=lead(start_timestamp) over (partition by num order by start_timestamp asc)
and name=lead(name) over(partition by num order by start_timestamp asc )
)
then 'continued' --开始时间等于上一条结束时间且名字等于上一条名字or结束时间等于下一条开始时间且
when lag(start_timestamp,1) over (partition by num order by start_timestamp asc)
=lag(start_timestamp,2) over (partition by num order by start_timestamp asc)
and (name=lag(name,1) over(partition by num order by start_timestamp asc )
or name=lag(name,2) over(partition by num order by start_timestamp asc ))
then 'continued'
when lead(start_timestamp,1) over (partition by num order by start_timestamp asc)
=lead(start_timestamp,2) over (partition by num order by start_timestamp asc)
and (name=lead(name,1) over(partition by num order by start_timestamp asc )
or name=lead(name,2) over(partition by num order by start_timestamp asc ))
then 'continued'
else 'discontinued'
end as is_continue
from test_detail
order by start_timestamp
;
2.判断出连续的人同一班级同一人每个时间段的开始节点
with is_continue as (
--判断出同一班级进入班级的人是否连续
select
id --主键
,num --班级号码
,name --名字
,start_timestamp --进入班级时间
,end_timestamp --离开班级时间
--判断同一班级进入班级的人是否连续
,case when (start_timestamp=lag(end_timestamp) over(partition by num order by start_timestamp asc )
and name=lag(name) over(partition by num order by start_timestamp asc )) or
(end_timestamp=lead(start_timestamp) over (partition by num order by start_timestamp asc)
and name=lead(name) over(partition by num order by start_timestamp asc )
)
then 'continued'
when lag(start_timestamp,1) over (partition by num order by start_timestamp asc)
=lag(start_timestamp,2) over (partition by num order by start_timestamp asc)
and (name=lag(name,1) over(partition by num order by start_timestamp asc )
or name=lag(name,2) over(partition by num order by start_timestamp asc ))
then 'continued'
when lead(start_timestamp,1) over (partition by num order by start_timestamp asc)
=lead(start_timestamp,2) over (partition by num order by start_timestamp asc)
and (name=lead(name,1) over(partition by num order by start_timestamp asc )
or name=lead(name,2) over(partition by num order by start_timestamp asc ))
then 'continued'
else 'discontinued'
end as is_continue
from test_detail
)
--判断出同一班级同一人每个时间段的开始节点
select
id --主键
,num --班级号码
,name --名字
,start_timestamp --进入班级时间
,end_timestamp --离开班级时间
,case when lag(end_timestamp) over(partition by num,name order by start_timestamp) is null and
end_timestamp=lead(start_timestamp) over(partition by num,name order by start_timestamp) then 1
when lag(end_timestamp) over(partition by num,name order by start_timestamp) is not null
and start_timestamp<>lag(end_timestamp) over(partition by num,name order by start_timestamp) then 1
else 0
end as start_point --同一班级同一人每个时间段的开始节点,标记为1
from is_continue
where is_continue='continued' --连续
order by start_timestamp;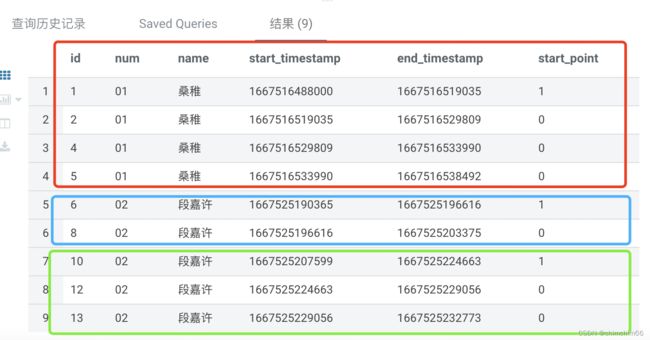
3.将同一班级同一人每个时间段分组
with is_continue as (
--判断出同一班级进入班级的人是否连续
select
id --主键
,num --班级号码
,name --名字
,start_timestamp --进入班级时间
,end_timestamp --离开班级时间
--判断同一班级进入班级的人是否连续
,case when (start_timestamp=lag(end_timestamp) over(partition by num order by start_timestamp asc )
and name=lag(name) over(partition by num order by start_timestamp asc )) or
(end_timestamp=lead(start_timestamp) over (partition by num order by start_timestamp asc)
and name=lead(name) over(partition by num order by start_timestamp asc )
)
then 'continued'
when lag(start_timestamp,1) over (partition by num order by start_timestamp asc)
=lag(start_timestamp,2) over (partition by num order by start_timestamp asc)
and (name=lag(name,1) over(partition by num order by start_timestamp asc )
or name=lag(name,2) over(partition by num order by start_timestamp asc ))
then 'continued'
when lead(start_timestamp,1) over (partition by num order by start_timestamp asc)
=lead(start_timestamp,2) over (partition by num order by start_timestamp asc)
and (name=lead(name,1) over(partition by num order by start_timestamp asc )
or name=lead(name,2) over(partition by num order by start_timestamp asc ))
then 'continued'
else 'discontinued'
end as is_continue
from test_detail
) ,
start_point as (
--判断出同一班级同一人每个时间段的开始节点
select
id --主键
,num --班级号码
,name --名字
,start_timestamp --进入班级时间
,end_timestamp --离开班级时间
,case when lag(end_timestamp) over(partition by num,name order by start_timestamp) is null and
end_timestamp=lead(start_timestamp) over(partition by num,name order by start_timestamp) then 1
when lag(end_timestamp) over(partition by num,name order by start_timestamp) is not null
and start_timestamp<>lag(end_timestamp) over(partition by num,name order by start_timestamp) then 1
else 0
end as start_point --同一班级同一人每个时间段的开始节点,标记为1
from is_continue
where is_continue='continued'
)
--将同一班级同一人每个时间段分组
select
id --主键
,num --班级号码
,name --名字
,start_timestamp --进入班级时间
,end_timestamp --离开班级时间
,sum(start_point) over(partition by num,name order by start_timestamp,end_timestamp
rows between unbounded preceding and current row ) as group_id --分组id
from start_point
order by start_timestamp;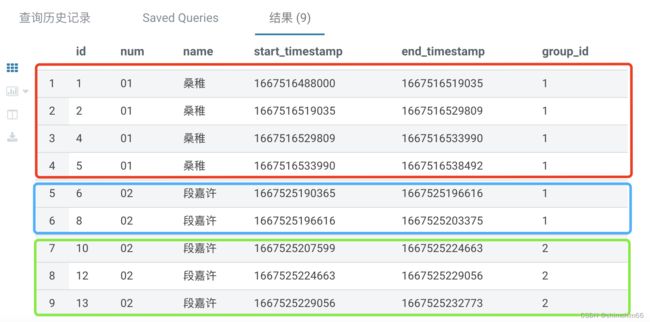
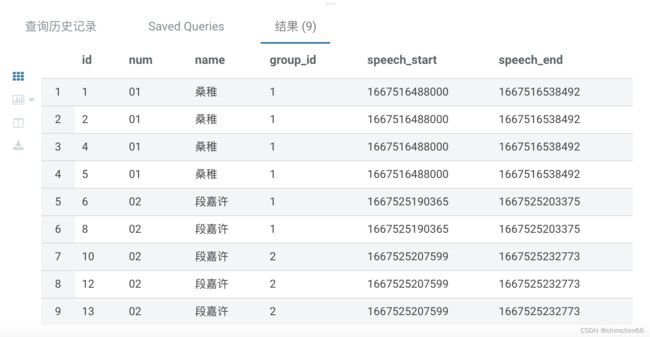
4.取出同一班级同一人每个时间段的开始时间结束时间
with is_continue as (
--判断出同一班级进入班级的人是否连续
select
id --主键
,num --班级号码
,name --名字
,start_timestamp --进入班级时间
,end_timestamp --离开班级时间
--判断同一班级进入班级的人是否连续
,case when (start_timestamp=lag(end_timestamp) over(partition by num order by start_timestamp asc )
and name=lag(name) over(partition by num order by start_timestamp asc )) or
(end_timestamp=lead(start_timestamp) over (partition by num order by start_timestamp asc)
and name=lead(name) over(partition by num order by start_timestamp asc )
)
then 'continued'
when lag(start_timestamp,1) over (partition by num order by start_timestamp asc)
=lag(start_timestamp,2) over (partition by num order by start_timestamp asc)
and (name=lag(name,1) over(partition by num order by start_timestamp asc )
or name=lag(name,2) over(partition by num order by start_timestamp asc ))
then 'continued'
when lead(start_timestamp,1) over (partition by num order by start_timestamp asc)
=lead(start_timestamp,2) over (partition by num order by start_timestamp asc)
and (name=lead(name,1) over(partition by num order by start_timestamp asc )
or name=lead(name,2) over(partition by num order by start_timestamp asc ))
then 'continued'
else 'discontinued'
end as is_continue
from test_detail
),
start_point as (
--判断出同一班级同一人每个时间段的开始节点
select
id --主键
,num --班级号码
,name --名字
,start_timestamp --进入班级时间
,end_timestamp --离开班级时间
,case when lag(end_timestamp) over(partition by num,name order by start_timestamp) is null and
end_timestamp=lead(start_timestamp) over(partition by num,name order by start_timestamp) then 1
when lag(end_timestamp) over(partition by num,name order by start_timestamp) is not null
and start_timestamp<>lag(end_timestamp) over(partition by num,name order by start_timestamp) then 1
else 0
end as start_point --同一班级同一人每个时间段的开始节点,标记为1
from is_continue
where is_continue='continued'
),
group_id as (
--将同一班级同一人每个时间段分组
select
id --主键
,num --班级号码
,name --名字
,start_timestamp --进入班级时间
,end_timestamp --离开班级时间
,sum(start_point) over(partition by num,name order by start_timestamp,end_timestamp
rows between unbounded preceding and current row ) as group_id --分组id
from start_point
)
select
id --主键
,num --班级号码
,name --名字
,group_id --分组id
,min(start_timestamp) over (partition by num,name,group_id) as speech_start --时间段开始时间
,max(end_timestamp) over (partition by num,name,group_id) as speech_end --时间段结束时间
from group_id
order by start_timestamp
;
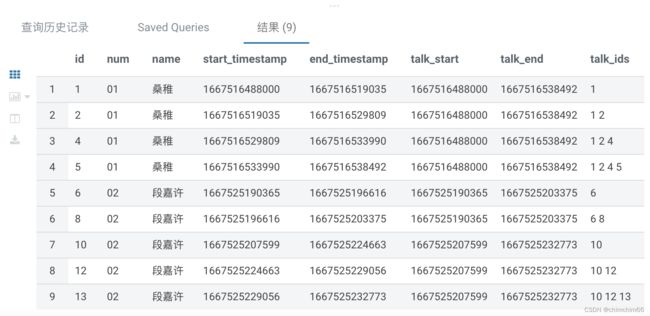
5.按每个时间段按时间顺序拼接出id的值
with is_continue as (
--判断出同一班级进入班级的人是否连续
select
id --主键
,num --班级号码
,name --名字
,start_timestamp --进入班级时间
,end_timestamp --离开班级时间
--判断同一班级进入班级的人是否连续
,case when (start_timestamp=lag(end_timestamp) over(partition by num order by start_timestamp asc )
and name=lag(name) over(partition by num order by start_timestamp asc )) or
(end_timestamp=lead(start_timestamp) over (partition by num order by start_timestamp asc)
and name=lead(name) over(partition by num order by start_timestamp asc )
)
then 'continued'
when lag(start_timestamp,1) over (partition by num order by start_timestamp asc)
=lag(start_timestamp,2) over (partition by num order by start_timestamp asc)
and (name=lag(name,1) over(partition by num order by start_timestamp asc )
or name=lag(name,2) over(partition by num order by start_timestamp asc ))
then 'continued'
when lead(start_timestamp,1) over (partition by num order by start_timestamp asc)
=lead(start_timestamp,2) over (partition by num order by start_timestamp asc)
and (name=lead(name,1) over(partition by num order by start_timestamp asc )
or name=lead(name,2) over(partition by num order by start_timestamp asc ))
then 'continued'
else 'discontinued'
end as is_continue
from test_detail
),
start_point as (
--判断出同一班级同一人每个时间段的开始节点
select
id --主键
,num --班级号码
,name --名字
,start_timestamp --进入班级时间
,end_timestamp --离开班级时间
,case when lag(end_timestamp) over(partition by num,name order by start_timestamp) is null and
end_timestamp=lead(start_timestamp) over(partition by num,name order by start_timestamp) then 1
when lag(end_timestamp) over(partition by num,name order by start_timestamp) is not null
and start_timestamp<>lag(end_timestamp) over(partition by num,name order by start_timestamp) then 1
else 0
end as start_point --同一班级同一人每个时间段的开始节点,标记为1
from is_continue
where is_continue='continued'
),
group_id as (
--将同一班级同一人每个时间段分组
select
id --主键
,num --班级号码
,name --名字
,start_timestamp --进入班级时间
,end_timestamp --离开班级时间
,sum(start_point) over(partition by num,name order by start_timestamp,end_timestamp
rows between unbounded preceding and current row ) as group_id --分组id
from start_point
),
min_max as (
select
id --主键
,num --班级号码
,name --名字
,start_timestamp --进入班级时间
,end_timestamp --离开班级时间
,group_id --分组id
,min(start_timestamp) over (partition by num,name,group_id) as talk_start --时间段开始时间
,max(end_timestamp) over (partition by num,name,group_id) as talk_end --时间段结束时间
from group_id
)
select
id --主键
,num --班级号码
,name --名字
,start_timestamp --进入班级时间
,end_timestamp --离开班级时间
,talk_start --时间段开始时间
,talk_end --时间段结束时间
,concat_ws(' ',collect_set(cast(id as string)) over(partition by num,name,talk_start,talk_end order by start_timestamp asc)) as talk_ids
from min_max
order by start_timestamp
;
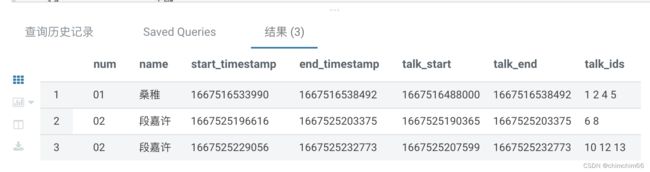
6.每个时间段拼接好的结果
with is_continue as (
--判断出同一班级进入班级的人是否连续
select
id --主键
,num --班级号码
,name --名字
,start_timestamp --进入班级时间
,end_timestamp --离开班级时间
--判断同一班级进入班级的人是否连续
,case when (start_timestamp=lag(end_timestamp) over(partition by num order by start_timestamp asc )
and name=lag(name) over(partition by num order by start_timestamp asc )) or
(end_timestamp=lead(start_timestamp) over (partition by num order by start_timestamp asc)
and name=lead(name) over(partition by num order by start_timestamp asc )
)
then 'continued'
when lag(start_timestamp,1) over (partition by num order by start_timestamp asc)
=lag(start_timestamp,2) over (partition by num order by start_timestamp asc)
and (name=lag(name,1) over(partition by num order by start_timestamp asc )
or name=lag(name,2) over(partition by num order by start_timestamp asc ))
then 'continued'
when lead(start_timestamp,1) over (partition by num order by start_timestamp asc)
=lead(start_timestamp,2) over (partition by num order by start_timestamp asc)
and (name=lead(name,1) over(partition by num order by start_timestamp asc )
or name=lead(name,2) over(partition by num order by start_timestamp asc ))
then 'continued'
else 'discontinued'
end as is_continue
from test_detail
),
start_point as (
--判断出同一班级同一人每个时间段的开始节点
select
id --主键
,num --班级号码
,name --名字
,start_timestamp --进入班级时间
,end_timestamp --离开班级时间
,case when lag(end_timestamp) over(partition by num,name order by start_timestamp) is null and
end_timestamp=lead(start_timestamp) over(partition by num,name order by start_timestamp) then 1
when lag(end_timestamp) over(partition by num,name order by start_timestamp) is not null
and start_timestamp<>lag(end_timestamp) over(partition by num,name order by start_timestamp) then 1
else 0
end as start_point --同一班级同一人每个时间段的开始节点,标记为1
from is_continue
where is_continue='continued'
),
group_id as (
--将同一班级同一人每个时间段分组
select
id --主键
,num --班级号码
,name --名字
,start_timestamp --进入班级时间
,end_timestamp --离开班级时间
,sum(start_point) over(partition by num,name order by start_timestamp,end_timestamp
rows between unbounded preceding and current row ) as group_id --分组id
from start_point
),
min_max as (
select
id --主键
,num --班级号码
,name --名字
,start_timestamp --进入班级时间
,end_timestamp --离开班级时间
,group_id --分组id
,min(start_timestamp) over (partition by num,name,group_id) as talk_start --时间段开始时间
,max(end_timestamp) over (partition by num,name,group_id) as talk_end --时间段结束时间
from group_id
),
talk_ids as (
select
id --主键
,num --班级号码
,name --名字
,start_timestamp --进入班级时间
,end_timestamp --离开班级时间
,talk_start --时间段开始时间
,talk_end --时间段结束时间
,concat_ws(' ',collect_set(cast(id as string)) over(partition by num,name,talk_start,talk_end order by start_timestamp asc)) as talk_ids
from min_max
)
--每个时间段只取最后一条拼接好的数据
select
id --主键
,num --班级号码
,name --名字
,start_timestamp --进入班级时间
,end_timestamp --离开班级时间
,talk_start --时间段开始时间
,talk_end --时间段结束时间
,talk_ids --按时间段及时间升序拼接好的id
from talk_ids
where end_timestamp=talk_end
order by start_timestamp
;