深入了解Apache InLong和重点理解Sort的应用
深入了解Apache InLong和重点理解Sort的应用
- 一、产品优势
- 二、产品架构
- 三、模块
- 四、已支持数据节点
- 五、基本概念
- 六、Agent 插件
- 七、Sort插件
- 八、Manager 插件
- 九、DataProxy插件
- 十、重点理解Sort的应用
-
- 1.支持多种数据节点
- 2.安装部署
- 3.启动 InLong Sort 任务
- 4.MySQL to PostgreSQL示例
- 十一、InLong Sort的使用示例
-
- 1.环境要求
- 2.准备 InLong Sort 和 Connectors
- 3.使用 SQL API 方式
- 十二、InLong Sort监控指标
- 十三、数据节点Extract Nodes
-
- 1.MySQL-CDC
- 2.Kafka
- 十四、数据节点Load Nodes
-
- 1.Kafka
- 2.MySQL
- 3.Hive
- 4.Iceberg
Apache InLong(应龙)是一个一站式海量数据集成框架,提供自动、安全、可靠和高性能的数据传输能力,同时支持批和流,方便业务构建基于流式的数据分析、建模和应用。
Apache InLong 依托 10 万亿级别的数据接入和处理能力,整合了数据采集、汇聚、存储、分拣数据处理全流程,拥有简单易用、灵活扩展、稳定可靠等特性。 该项目最初于 2019 年 11 月由腾讯大数据团队捐献到 Apache 孵化器,2022 年 6 月正式毕业成为 Apache 顶级项目。目前 InLong 正广泛应用于广告、支付、社交、游戏、人工智能等各个行业领域,为多领域客户提供高效化便捷化服务。
一、产品优势
简单易用:
- 基于SaaS模式对外服务,用户只需要按主题发布和订阅数据即可完成数据的上报,传输和分发工作。
稳定可靠:
- 系统源于实际的线上系统,服务上十万亿级的高性能及上千亿级的高可靠数据数据流量,系统稳定可靠
功能完善:
- 支持各种类型的数据接入方式,多种不同类型的MQ集成,以及基于配置规则的实时数据ETL和数据分拣落地,并支持以可插拔方式扩展系统能力
服务集成:
- 支持统一的系统监控、告警,以及细粒度的数据指标呈现,对于管道的运行情况,以数据主题为核心的数据运营情况,汇总在统一的数据指标平台,并支持通过业务设置的告警信息进行异常告警提醒
灵活扩展:
- 全链条上的各个模块基于协议以可插拔方式组成服务,业务可根据自身需要进行组件替换和功能扩展
二、产品架构
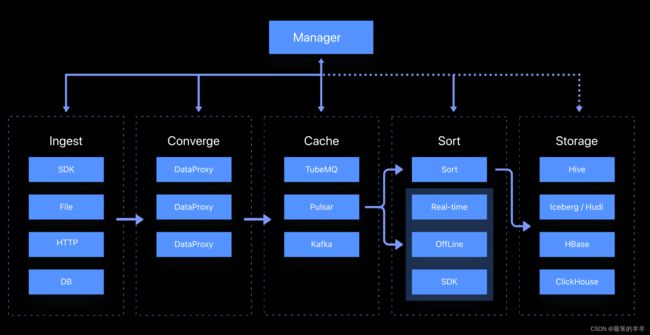
标准架构:
- 包含 InLong Agent、Manager、MQ、Sort、Dashboard 等所有 InLong 组件,适合海量数据、大规模生产环境。
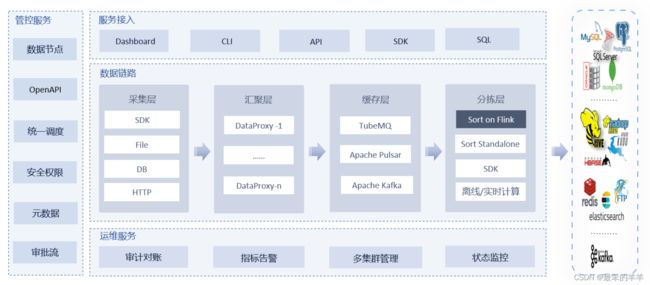
轻量化架构:
- 只包含 InLong Sort 一个组件,也可以搭配 Manager,Dashboard 一起使用。轻量化架构简单、灵活,适合小规模数据。
三、模块
Apache InLong 服务于数据采集到落地的整个生命周期,按数据的不同阶段提供不同的处理模块,主要包括:
- inlong-agent,数据采集服务,包括文件采集、DB 采集等。
- inlong-dataproxy,一个基于 Flume-ng 的 Proxy 组件,支持数据发送阻塞和落盘重发,拥有将接收到的数据转发到不同 MQ(消息队列)的能力。
- inlong-tubemq,腾讯自研的消息队列服务,专注于大数据场景下海量数据的高性能存储和传输,在海量实践和低成本方面有着良好的核心优势。
- inlong-sort,对从不同的 MQ 消费到的数据进行 ETL 处理,然后汇聚并写入 Hive、ClickHouse、Hbase、Iceberg、Hudi 等存储系统。
- inlong-manager,提供完整的数据服务管控能力,包括元数据、任务流、权限,OpenAPI 等。
- inlong-dashboard,用于管理数据接入的前端页面,简化整个 InLong 管控平台的使用。
- inlong-audit,对 InLong 系统的 Agent、DataProxy、Sort 模块的入流量、出流量进行实时审计对账。
四、已支持数据节点
Type:Extract Node数据源类型
| Name | Version | Architecture |
|---|---|---|
| Auto Push | None | Standard |
| File | None | Standard |
| Kafka | 2.x | Lightweight, Standard |
| MySQL | 5.6, 5.7, 8.0.x | Lightweight, Standard |
| MongoDB | >= 3.6 | Lightweight, Standard |
| MQTT | >= 3.1 | Standard |
| Oracle | 11,12,19 | Lightweight |
| PostgreSQL | 9.6, 10, 11, 12 | Lightweight, Standard |
| Pulsar | 2.8.x | Lightweight |
| Redis | 2.6.x | Standard |
| SQLServer | 2012, 2014, 2016, 2017, 2019 | Lightweight, Standard |
Type:Load Node数据流向目标类型
| Name | Version | Architecture |
|---|---|---|
| Auto Consumption | None | Standard |
| Hive | 1.x, 2.x, 3.x | Lightweight, Standard |
| Iceberg | 0.12.x | Lightweight, Standard |
| Hudi | 0.12.x | Lightweight, Standard |
| ClickHouse | 20.7+ | Lightweight, Standard |
| Kafka | 2.x | Lightweight, Standard |
| HBase | 2.2.x | Lightweight, Standard |
| PostgreSQL | 9.6, 10, 11, 12 | Lightweight, Standard |
| Oracle | 11, 12, 19 | Lightweight, Standard |
| MySQL | 5.6, 5.7, 8.0.x | Lightweight, Standard |
| TDSQL-PostgreSQL | 10.17 | Lightweight, Standard |
| Greenplum | 4.x, 5.x, 6.x | Lightweight, Standard |
| Elasticsearch | 6.x, 7.x | Lightweight, Standard |
| SQLServer | 2012, 2014, 2016, 2017, 2019 | Lightweight, Standard |
| Doris | >= 0.13 | Lightweight, Standard |
| StarRocks | >= 2.0 | Lightweight, Standard |
| HDFS | 2.x, 3.x | Lightweight, Standard |
五、基本概念
| Name | Description | Other |
|---|---|---|
| Standard | 标准架构,包含 InLong Agent、Manager、MQ、Sort、Dashboard 等所有 InLong 组件 | 适合海量数据、大规模生产环境 |
| Lightweight | 轻量化架构,只包含 InLong Sort 一个组件,也可以搭配 Manager,Dashboard 一起使用 | 轻量化架构简单、灵活,适合小规模数据 |
| Group | 数据流组,包含多个数据流,一个 Group 代表一个数据业务单元 | Group 有 ID、Name 等属性 |
| Stream | 数据流,一个数据流有具体的数据源、数据格式和数据流向 | Stream 有 ID、Name、数据字段等属性 |
| Node | 数据节点,包括 Extract Node 和 Load Node,分别代表数据源类型和数据流向目标类型 | |
| InLongMsg | InLong 数据格式,如果从消息队列中直接消费,需要先进行 InLongMsg 解析 | |
| Cluster | 集群,每个组件都可以构成单一集群。 | 包含集群名、标签,每个组件必要信息等 |
| Tag | 标签,不同组件的集群可以使用相同标签,代表一组数据流执行单元 | 目前标签只适用于集群 |
| Agent | 标准架构使用 Agent 进行数据采集,Agent 代表不同类型的采集能力 | 包含文件 Agent、SQL Agent、Binlog Agent 等 |
| DataProxy | 将接收到的数据转发到不同的消息队列 | 支持数据发送阻塞和落盘重发 |
| Sort | 数据流分拣 | 主要有基于 Flink 的 sort-flink,sort-standalone 本地分拣 |
| TubeMQ | InLong 自带的消息队列服务 | 也可以叫 Tube,拥有低成本、高性能特性 |
| Pulsar | 即 Apache Pulsar,高性能、高一致性消息队列服务 |
六、Agent 插件
在 Standard Architecture 中,可以通过 InLong Agent 来采集各种类型的数据源。InLong Agent 支持以插件的方式扩展新的采集类型。
概念和模型
InLong Agent 是一个数据采集框架,采用 Job + Task 架构模型,将数据源读取和写入抽象成为 Reader/Sink 插件。
- Job: Job是 Agent 用以描述从一个源头到一个目的端的同步作业,是 Agent 数据同步的最小业务单元。比如:读取一个文件目录下的所有文件
一个 Task 包含以下组件:
- Reader:数据采集模块,负责采集数据源的数据,将数据发送给 Channel。
- Sink: 数据写入模块,负责不断向 Channel 取数据,并将数据写入到目的端。
- Channel:连接 Reader 和 Sink,作为两者的数据传输通道,并起到了数据的写入读取监控作用。
当扩展一个 Agent 插件时,需要开发特定的 Source、Reader 以及 Sink,数据如果需要持久化到本地磁盘,使用持久化 Channel ,如果否则使用内存 Channel
流程图示
上述介绍的 Job/Task/Reader/Sink/Channel 概念可以用下图表示:
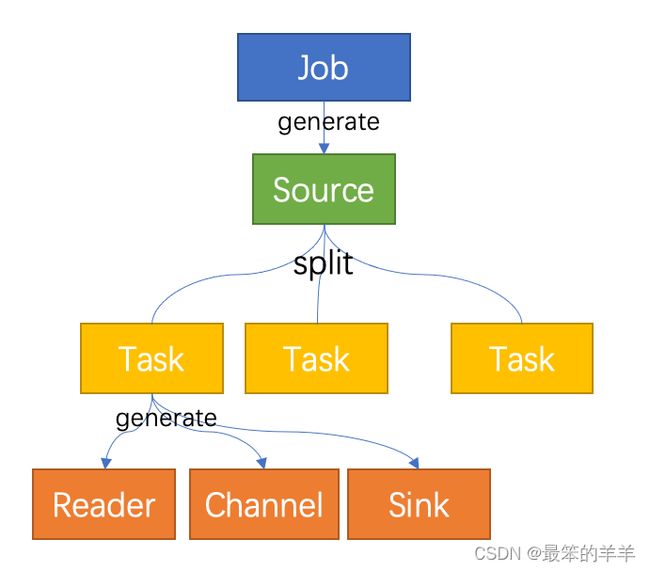
- 用户提交 Job(通过 manager),Job 中定义了需要使用的 Source, Channel, Sink(通过类的全限定名定义)
- 框架启动 Job,通过反射机制创建出 Source
- 框架启动 Source,并调用 Source 的 Split 接口,生成一个或者多个 Task
- 生成一个 Task 时,同时生成 Reader(一种类型的 Source 会生成对应的 reader),用户配置的 Channel 以及用户配置的 Sink
- Task 开始执行,Reader 开始读取数据到 Channel,Sink 从 Channel 中取数进行发送
- Job 和 Task 执行时所需要的所有信息都封装在 JobProfile 中
开发流程
- 首先开发 Source , 实现 Split 逻辑,返回 Reader 列表
- 开发对应的 Reader ,实现读取数据并写入到 Channel 的逻辑
- 开发对应的 Sink , 实现从 Channel 中取数并写入到指定 Sink 中的逻辑
接口
下面将介绍开发一个 Agent 插件需要知道的类与接口。
Reader
private class ReaderImpl implements Reader {
private int count = 0;
@Override
public Message read() {
count += 1;
return new DefaultMessage("".getBytes(StandardCharsets.UTF_8));
}
@Override
public boolean isFinished() {
return count > 99999;
}
@Override
public String getReadSource() {
return null;
}
@Override
public void setReadTimeout(long mill) {
}
}
Reader 接口功能如下:
- read: 被单个 Task 调用,调用后返回读取的一条消息,Agent 内部的消息使用 Message 封装
- isFinished: 判断是否读取完成,举例:如果是 SQL 任务,则判断是否读取完了 ResultSet 中的所有内容,如果是文件任务,则判断超过用户设置的等待时间后是否还有数据写入
- getReadSource: 获取采集源,举例:如果是文件任务,则返回当前读取的文件名
- setReadTimeout: 设置读取超时时间
Sink
public interface Sink extends Stage {
/**
* Write data into data center
*
* @param message - message
*/
void write(Message message);
/**
* set source file name where the message is generated
* @param sourceName
*/
void setSourceName(String sourceName);
/**
* every sink should include a message filter to filter out stream id
*/
MessageFilter initMessageFilter(JobProfile jobConf);
}
Sink 接口功能如下:
- write: 被单个 Task 调用,从 Task 中的 Channel 读取一条消息,并写入到特定的存储介质中,以 PulsarSink 为例,则需要通过 PulsarSender 发送到 Pulsar
- setSourceName: 设置数据源名称,如果是文件,则是文件名
- initMessageFilter: 初始化 MessageFilter , 用户可以在Job配置文件中通过设置 agent.message.filter.classname 来创建一个消息过滤器来过滤每一条消息
Source
/**
* Source can be split into multiple reader.
*/
public interface Source {
/**
* Split source into a list of readers.
*
* @param conf job conf
* @return - list of reader
*/
List<Reader> split(JobProfile conf);
}
Source接口功能如下:
- split: 被单个 Job 调用,产生多个 Reader,举例:一个读取文件任务,匹配文件夹内的多个文件,在 job 启动时,会指定 TextFileSource 作为 Source 入口, 调用 split 函数后,TextFileSource 会检测用户设置的文件夹内有多少符合路径匹配表达式的路径,并生成 TextFileReader 读取
任务配置
代码写好了,有没有想过框架是怎么找到插件的入口类的?框架是如何加载插件的呢?
在提交任务时,会发现任务中定义了插件的相关信息,包括入口类。例如:
{
"job": {
"name": "fileAgentTest",
"source": "org.apache.inlong.agent.plugin.sources.TextFileSource",
"sink": "org.apache.inlong.agent.plugin.sinks.ProxySink",
"channel": "org.apache.inlong.agent.plugin.channel.MemoryChannel"
}
}
- source: Source 类的全限定名称,框架通过反射插件入口类的实例。
- sink: Sink 类的全限定名称,框架通过反射插件入口类的实例。
- channel: 使用的 Channel 类名,框架通过反射插件入口类的实例。
Message
跟一般的生产者-消费者模式一样,Reader插件和Sink插件之间也是通过channel来实现数据的传输的。 channel可以是内存的,也可能是持久化的,插件不必关心。插件通过RecordSender往channel写入数据,通过RecordReceiver从channel读取数据。
channel中的一条数据为一个Message的对象,Message中包含一个字节数组以及一个Map表示的属性数据
Message有如下方法:
public interface Message {
/**
* Data content of message.
*
* @return bytes body
*/
byte[] getBody();
/**
* Data attribute of message
*
* @return map header
*/
Map<String, String> getHeader();
}
开发人员可以根据该接口拓展定制化的 Message ,比如 ProxyMessage 中,就包含了 InLongGroupId, InLongStreamId 等属性
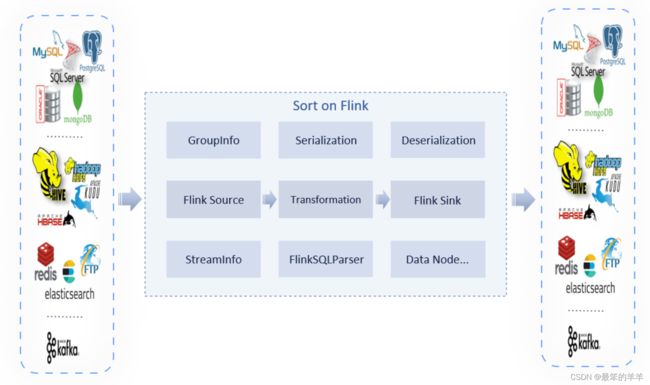
七、Sort插件
InLong Sort 是一个基于 Apache Flink SQL 的 ETL 服务。Flink SQL 强大的表达能力带来的高可扩展性、灵活性,基本上 Flink SQL 支持的语意,InLong Sort 都支持。 当 Flink SQL 内置的函数不满足需求时,还可通过 UDF 来扩展。这对于曾经使用过 SQL 尤其是 Flink SQL 的开发者非常友好。
本文介绍如何在 InLong Sort 中扩展一个新的 source(在 InLong 中抽象为 Extract Node)或一个新的 sink(在InLong中抽象为 Load Node )。 InLong Sort 架构的 UML 对象关系图如下:
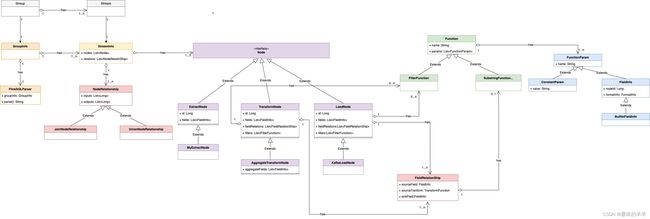
其中各个组件的概念为:
| 名称 | 描述 |
|---|---|
| Group | 数据流组,包含多个数据流,一个 Group 代表一个数据接入 |
| Stream | 数据流,一个数据流有具体的流向 |
| GroupInfo | Sort 中对数据流向的封装,一个 GroupInfo 可包含多个 DataFlowInfo |
| StreamInfo | Sort 中数据流向的抽象,包含该数据流的各种来源、转换、去向等 |
| Node | 数据同步中数据源、数据转换、数据去向的抽象 |
| ExtractNode | 数据同步的来源端抽象 |
| TransformNode | 数据同步的转换过程抽象 |
| LoadNode | 数据同步的去向端抽象 |
| NodeRelationShip | 数据同步中各个节点关系抽象 |
| FieldRelationShip | 数据同步中上下游节点字段间关系的抽象 |
| FieldInfo | 节点字段 |
| MetaFieldInfo | 节点 Meta 字段 |
| Function | 转换函数的抽象 |
| FunctionParam | 函数的入参抽象 |
| ConstantParam | 常量参数 |
扩展 Extract Node 或 Load Node 需要做的工作是:
- 继承 Node 类(例如 MyExtractNode),构建具体的 extract 或 load 使用逻辑;
- 在具体的 Node 类(例如 MyExtractNode)中,指定对应 Flink connector;
- 在具体的 ETL 实现逻辑中使用具体的 Node 类(例如 MyExtractNode)。
其中第二步中可以使用已有的 Flink Connector。
扩展 Extract Node
扩展一个 ExtractNode 分为三个步骤:
第一步:继承 ExtractNode 类,类的位置在:
inlong-sort/sort-common/src/main/java/org/apache/inlong/sort/protocol/node/ExtractNode.java
在实现的 ExtractNode 中指定 connector;
// 继承 ExtractNode 类,实现具体的类,例如 MongoExtractNode
@EqualsAndHashCode(callSuper = true)
@JsonTypeName("MongoExtract")
@Data
public class MongoExtractNode extends ExtractNode implements Serializable {
@JsonInclude(Include.NON_NULL)
@JsonProperty("primaryKey")
private String primaryKey;
...
@JsonCreator
public MongoExtractNode(@JsonProperty("id") String id, ...) { ... }
@Override
public Map<String, String> tableOptions() {
Map<String, String> options = super.tableOptions();
// 配置指定的 connector,这里指定的是 mongodb-cdc
options.put("connector", "mongodb-cdc");
...
return options;
}
}
第二步:在 ExtractNode 和 Node 中的 JsonSubTypes 添加该 Extract
// 在 ExtractNode 和 Node 的 JsonSubTypes 中添加字段
...
@JsonSubTypes({
@JsonSubTypes.Type(value = MongoExtractNode.class, name = "mongoExtract")
})
...
public abstract class ExtractNode implements Node{...}
...
@JsonSubTypes({
@JsonSubTypes.Type(value = MongoExtractNode.class, name = "mongoExtract")
})
public interface Node {...}
第三步:扩展 Sort Connector,查看此(inlong-sort/sort-connectors/mongodb-cdc)目录下是否已经存在对应的 connector。如果没有,则需要参考 Flink 官方文档 DataStream Connectors 来扩展, 调用已有的 Flink-connector(例如inlong-sort/sort-connectors/mongodb-cdc)或自行实现相关的 connector 均可。
扩展 Load Node
扩展一个 LoadNode 分为三个步骤:
第一步:继承 LoadNode 类,类的位置在:
inlong-sort/sort-common/src/main/java/org/apache/inlong/sort/protocol/node/LoadNode.java
在实现的LoadNode 中指定 connector;
// 继承 LoadNode 类,实现具体的类,例如 KafkaLoadNode
@EqualsAndHashCode(callSuper = true)
@JsonTypeName("kafkaLoad")
@Data
@NoArgsConstructor
public class KafkaLoadNode extends LoadNode implements Serializable {
@Nonnull
@JsonProperty("topic")
private String topic;
...
@JsonCreator
public KafkaLoadNode(@Nonnull @JsonProperty("topic") String topic, ...) {...}
// 根据不同的条件配置使用不同的 connector
@Override
public Map<String, String> tableOptions() {
...
if (format instanceof JsonFormat || format instanceof AvroFormat || format instanceof CsvFormat) {
if (StringUtils.isEmpty(this.primaryKey)) {
// kafka connector
options.put("connector", "kafka");
options.putAll(format.generateOptions(false));
} else {
// upsert-kafka connector
options.put("connector", "upsert-kafka");
options.putAll(format.generateOptions(true));
}
} else if (format instanceof CanalJsonFormat || format instanceof DebeziumJsonFormat) {
// kafka-inlong connector
options.put("connector", "kafka-inlong");
options.putAll(format.generateOptions(false));
} else {
throw new IllegalArgumentException("kafka load Node format is IllegalArgument");
}
return options;
}
}
第二步:在 LoadNode 和 Node 中的 JsonSubTypes 添加该 Load
// 在 LoadNode 和 Node 的 JsonSubTypes 中添加字段
...
@JsonSubTypes({
@JsonSubTypes.Type(value = KafkaLoadNode.class, name = "kafkaLoad")
})
...
public abstract class LoadNode implements Node{...}
...
@JsonSubTypes({
@JsonSubTypes.Type(value = KafkaLoadNode.class, name = "kafkaLoad")
})
public interface Node {...}
第三步:扩展 Sort Connector,Kafka 的 sort connector 在 inlong-sort/sort-connectors/kafka 目录下。
集成到 Entrance
将 Extract 和 Load 集成到 InLong Sort 主流程中,需要构建总览小节中提到的语意:Group、Stream、Node 等。 InLong Sort 的入口类在:
inlong-sort/sort-core/src/main/java/org/apache/inlong/sort/Entrance.java
Extract 和 Load 如何集成至 InLong Sort,可参考下面的 UT,首先构建对应的 ExtractNode、LoadNode,再构建 NodeRelation、StreamInfo、GroupInfo,最后通过 FlinkSqlParser 执行。
public class MongoExtractToKafkaLoad extends AbstractTestBase {
// 构建 MongoExtractNode
private MongoExtractNode buildMongoNode() {
List<FieldInfo> fields = Arrays.asList(new FieldInfo("name", new StringFormatInfo()), ...);
return new MongoExtractNode(..., fields, ...);
}
// 构建 KafkaLoadNode
private KafkaLoadNode buildAllMigrateKafkaNode() {
List<FieldInfo> fields = Arrays.asList(new FieldInfo("name", new StringFormatInfo()), ...);
List<FieldRelation> relations = Arrays.asList(new FieldRelation(new FieldInfo("name", new StringFormatInfo()), ...), ...);
CsvFormat csvFormat = new CsvFormat();
return new KafkaLoadNode(..., fields, relations, csvFormat, ...);
}
// 构建 NodeRelation
private NodeRelation buildNodeRelation(List<Node> inputs, List<Node> outputs) {
List<String> inputIds = inputs.stream().map(Node::getId).collect(Collectors.toList());
List<String> outputIds = outputs.stream().map(Node::getId).collect(Collectors.toList());
return new NodeRelation(inputIds, outputIds);
}
// 测试主流程 MongoDB to Kafka
@Test
public void testMongoDbToKafka() throws Exception {
EnvironmentSettings settings = EnvironmentSettings. ... .build();
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
...
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env, settings);
Node inputNode = buildMongoNode();
Node outputNode = buildAllMigrateKafkaNode();
StreamInfo streamInfo = new StreamInfo("1", Arrays.asList(inputNode, outputNode), ...);
GroupInfo groupInfo = new GroupInfo("1", Collections.singletonList(streamInfo));
FlinkSqlParser parser = FlinkSqlParser.getInstance(tableEnv, groupInfo);
ParseResult result = parser.parse();
Assert.assertTrue(result.tryExecute());
}
}
八、Manager 插件
Inlong 设计初衷即是为了在不同数据源之间创建数据流,截止目前,Inlong 已经支持多种常用数据源的读取和写入,如 MySQL, Apache Kafka, ClickHouse 等, 详细内容可参考 数据节点。 InLong 的每种数据节点,支持通过 Manager 提供统一的管理,以简化用户的使用。 本文介绍通过 Manager 如何扩展一个新的数据节点,实现提供服务。
扩展 Extract Node
- 首先需要在 Sort 组件内支持该数据源,详情参考 Sort 插件
- 在枚举类org.apache.inlong.common.enums.TaskTypeEnum中增加对应的枚举
- 在常量类org.apache.inlong.manager.common.consts.SourceType中同样增加对应常量
- 在org.apache.inlong.manager.common.pojo.source路径下创建文件夹,创建对应实体类
- 在org.apache.inlong.manager.service.source路径下,创建对应工具类
支持数据源到ExtractNode的转换函数,参考 org.apache.inlong.manager.pojo.sort.util.ExtractNodeUtils
扩展 Load Node
- 首先需要在 Sort 组件内支持该数据源,详情参考 Sort 插件
- 在常量类org.apache.inlong.manager.common.consts.SinkType中增加对应常量
- 在org.apache.inlong.manager.common.pojo.sink路径下创建文件夹, 创建对应实体类
- 在org.apache.inlong.manager.service.sink路径下创建对应工具类
支持数据源到LoadNode的转换函数,参考代码 org.apache.inlong.manager.pojo.sort.util.LoadNodeUtils
九、DataProxy插件
DataProxy 实现了统一抽象 MQ (Message Queue) Sink 模型,支持在标准 MessageQueueZoneSink 下方便灵活添加不同类型的 MQ 流向,默认支持 Apache Pulsar、Apache Kafka 和 InLong TubeMQ。
概念和模型
DataProxy 是基于 Apache Flume 的数据接收和流转框架,采用 Source + Channel + Sink 架构模型,本文重点关注 Sink 部分。
- MessageQueueZoneSink: DataProxy 的标准 MQ Sink,所有类型消息队列统一在此 Sink 下扩展和支持
- MessageQueueHandler: 具体某类 MQ 的连接、数据发送、关闭的处理接口,默认使用 PulsarHandler 实现
- EventHandler: 消息打包器接口,可用于发送下游 MQ 之前转换 Header/Body 协议, 默认透传
当扩展新的 MQ 类型时,需要开发至少实现 MessageQueueHandler 作为插件,如果需要转换数据协议,可以同时扩展 EventHandler 做相应的处理。MessageQueueHandler 和 EventHandler 作为元数据配置由 Manager 下发,达到灵活部署扩展的效果。
数据流图示
上述相关模块和接口在数据流转过程中的关系可以用下图表示:
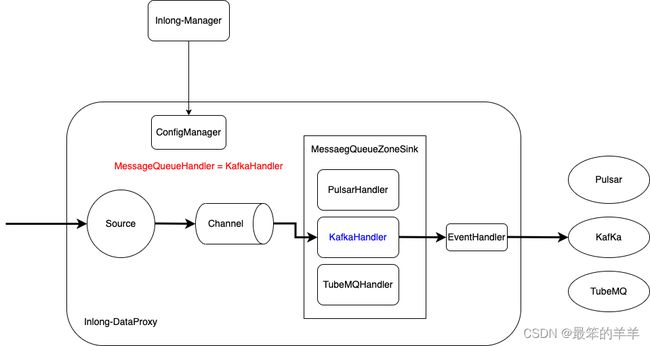
开发流程
以扩展 Kafka 类型 MQ 和 发送 ProtoBuffer 消息为例
- 首先开发 MessageQueueHandler 的子类插件 KafKaHandler, 实现 init / start /stop / send 接口逻辑
- 按需要实现 EventHandler 接口 parseHeader / parseBody 插件逻辑, 如 ProtoBufferEventHandler
接口
MessageQueueHandler
private class KafkaHandler implements MessageQueueHandler {
private EventHandler handler;
@Override
public void init(CacheClusterConfig config, MessageQueueZoneSinkContext sinkContext) {
// 初始化配置和EventHandler
}
@Override
public void start() {
// 创建 Kafka Producer
}
@Override
public void stop() {
// 关闭 Kafka Producer
}
@Override
public boolean send(BatchPackProfile event) {
// 处理并发送
}
}
EventHandler
public class ProtoBufferEventHandler implements EventHandler {
@Override
public Map<String, String> parseHeader(IdTopicConfig idConfig, BatchPackProfile profile, String nodeId,
INLONG_COMPRESSED_TYPE compressType) {
// 处理、转换消息头部
}
@Override
public byte[] parseBody(IdTopicConfig idConfig, BatchPackProfile profile, INLONG_COMPRESSED_TYPE compressType)
throws IOException {
// 处理、转换消息体为pb
}
}
完整示例参考 Inlong 代码库 org.apache.inlong.dataproxy.sink.mq.kafka.KafkaHandler 实现
source-channel-sink 管道配置(dataproxy-{tube|pulsar}.conf)
DataProxy 支持配置化的 source-channel-sink,配置方式与 flume 的配置文件结构一致,修改该配置文件时要按照 Apache flume 的配置文件定义来进行修改。配置文件放在 dataproxy-{tube|pulsar}.conf 文件中,目前支持 dataproxy-pulsar.conf 和 dataproxy-tube.conf 两种,用于区分不同的中间件类型,具体类型可以在启动时指定,默认(未指定时)使用 dataproxy-pulsar.conf 作为配置文件。 如下是针对该配置文件的示例:
Source 配置示例:
agent1.sources.tcp-source.channels = ch-msg1 ch-msg2 ch-msg3 ch-more1 ch-more2 ch-more3 ch-msg5 ch-msg6 ch-msg7 ch-msg8 ch-msg9 ch-msg10 ch-transfer ch-back
定义source中使用到的channel,注意此source下面的配置如果有使用到channel,均需要在此注释
agent1.sources.tcp-source.type = org.apache.flume.source.SimpleTcpSource
tcp解析类型定义,这里提供类名用于实例化,SimpleTcpSource主要是初始化配置并启动端口监听
agent1.sources.tcp-source.msg-factory-name = org.apache.flume.source.ServerMessageFactory
用于构造消息解析的handler,并设置read stream handler和write stream handler
agent1.sources.tcp-source.host = 0.0.0.0
tcp ip绑定监听,默认绑定所有网卡
agent1.sources.tcp-source.port = 46801
tcp 端口绑定,默认绑定46801端口
agent1.sources.tcp-source.highWaterMark=2621440
netty概念,设置netty高水位值
agent1.sources.tcp-source.max-msg-length = 524288
限制单个包大小,这里如果传输的是压缩包,则是压缩包大小,限制512KB
agent1.sources.tcp-source.topic = test_token
默认topic值,如果groupId和topic的映射关系找不到,则发送到此topic中
agent1.sources.tcp-source.attr = m=9
默认m值设置,这里的m值是inlong内部TdMsg协议的版本
agent1.sources.tcp-source.connections = 5000
并发连接上线,超过上限值时会对新连接做断链处理
agent1.sources.tcp-source.max-threads = 64
netty线程池工作线程上限,一般推荐选择cpu的两倍
agent1.sources.tcp-source.receiveBufferSize = 524288
netty server tcp调优参数
agent1.sources.tcp-source.sendBufferSize = 524288
netty server tcp调优参数
agent1.sources.tcp-source.custom-cp = true
是否使用自研的channel process,自研channel process可在主channel阻塞时,选择备用channel发送
agent1.sources.tcp-source.selector.type = org.apache.flume.channel.FailoverChannelSelector
这个channel selector就是自研的channel selector,和官网的差别不大,主要是有channel主从选择逻辑
agent1.sources.tcp-source.selector.master = ch-msg5 ch-msg6 ch-msg7 ch-msg8 ch-msg9
指定master channel,这些channel会被优先选择用于数据推送。那些不在master、transfer、fileMetric、slaMetric配置项里的channel,但在
channels里面有定义的channel,统归为slave channel,当master channel都被占满时,就会选择使用slave channel,slave channel一般建议使用file channel类型
agent1.sources.tcp-source.selector.transfer = ch-msg5 ch-msg6 ch-msg7 ch-msg8 ch-msg9
指定transfer channel,承接transfer类型的数据,这里的transfer一般是指推送到非tube集群的数据,仅做转发,这里预留出来供后续功能使用
agent1.sources.tcp-source.selector.fileMetric = ch-back
指定fileMetric channel,用于接收agent上报的指标数据
Channel 配置示例,memory channel:
agent1.channels.ch-more1.type = memory
memory channel类型
agent1.channels.ch-more1.capacity = 10000000
memory channel 队列大小,可缓存最大消息条数
agent1.channels.ch-more1.keep-alive = 0
agent1.channels.ch-more1.transactionCapacity = 20
原子操作时批量处理最大条数,memory channel使用时需要用到加锁,因此会有批处理流程增加效率
Channel 配置示例,file channel:
agent1.channels.ch-msg5.type = file
file channel类型
agent1.channels.ch-msg5.capacity = 100000000
file channel最大可缓存消息条数
agent1.channels.ch-msg5.maxFileSize = 1073741824
file channel文件最大上限,字节数
agent1.channels.ch-msg5.minimumRequiredSpace = 1073741824
file channel所在磁盘最小可用空间,设置此值可以防止磁盘写满
agent1.channels.ch-msg5.checkpointDir = /data/work/file/ch-msg5/check
file channel checkpoint路径
agent1.channels.ch-msg5.dataDirs = /data/work/file/ch-msg5/data
file channel数据路径
agent1.channels.ch-msg5.fsyncPerTransaction = false
是否对每个原子操作做同步磁盘,建议改false,否则会对性能有影响
agent1.channels.ch-msg5.fsyncInterval = 5
数据从内存flush到磁盘的时间间隔,单位秒
Sink 配置示例:
agent1.sinks.mq-sink-msg1.channel = ch-msg1
sink的上游channel名称
agent1.sinks.mq-sink-msg1.type = org.apache.inlong.dataproxy.sink.mq.MessageQueueZoneSink
sink类实现,此处为统一MQ模型Sink
agent1.sinks.mq-sink-msg1.maxThreads = 2
最大发送线程数
agent1.sinks.mq-sink-msg1.dispatchTimeout = 2000
Dispatch队列超时时间
agent1.sinks.mq-sink-msg1.dispatchMaxPackCount = 256
Dispatch队列最大包数量
agent1.sinks.mq-sink-msg1.dispatchMaxPackSize = 3276800
Dispatch队列最大包Size
agent1.sinks.mq-sink-msg1.maxBufferQueueSize=131072
Dispatch队列最大长度
agent1.sinks.mq-sink-msg1.processInterval=100
重试发送间隔
agent1.sinks.mq-sink-msg1.reloadInterval=60000
配置重新加载时间间隔
agent1.sinks.mq-sink-msg1.producer.compressionType=SNAPPY
数据压缩算法
十、重点理解Sort的应用
InLong Sort 是一个基于 Apache Flink 的 ETL 系统,支持多种数据源,支持简单的字段抽取,支持多种存储系统。 InLong Sort 既支持和 Manager 一起配合使用,通过 Manager 进行系统元数据的管理,也可以在 Flink 环境下独立运行。
1.支持多种数据节点
Extract Node:
- Pulsar
- MySQL
- Kafka
- MongoDB
- PostgreSQL
Transform:
- String Split
- String Regular Replace
- String Regular Replace First Matched Value
- Data Filter
- Data Distinct
- Regular Join
Load Node:
- Hive
- Kafka
- HBase
- ClickHouse
- Iceberg
- PostgreSQL
- HDFS
- TDSQL Postgres
- Hudi
2.安装部署
配置 Flink 运行环境
InLong Sort 是基于 Flink 的一个应用,需要准备好 Apache Flink 环境。
当前 InLong Sort 依赖的是 Apache Flink 1.13.5 版本,因此在下载部署包时,请选择 flink-1.13.5-bin-scala_2.11.tgz
准备安装文件
InLong Sort 运行文件,下载 apache-inlong-[version]-bin.tar.gz
数据节点 Connectors,下载 apache-inlong-[version]-sort-connectors.tar.gz
下载地址如下所示:
- https://inlong.apache.org/zh-CN/download/
Connectors 下载后可以将需要的 jars 放到FLINK_HOME/lib/下。
如果使用mysql-cdc-inlong 连接器,请将 mysql-connector-java:8.0.21.jar 包放到 FLINK_HOME/lib/下。
3.启动 InLong Sort 任务
./bin/flink run
-c org.apache.inlong.sort.Entrance apache-inlong-[version]-bin/inlong-sort/sort-dist-[version].jar \
--sql.script.file [souce-to-sink].sql
- –sql.script.file 需要指定一个 SQL 脚本文件,包含多个 Flink SQL 语句,可以用分号分隔。支持CREATE TABLE、CRETAE VIEW、INSERT INTO 等。
4.MySQL to PostgreSQL示例
如果我们想从 MySQL 读取数据并写入 PostgreSQL,我们可以编写以下 SQL 脚本。
准备 mysql-to-postgresql.sql
CREATE TABLE `table_1`(
`age` INT,
`name` STRING)
WITH (
'connector' = 'mysql-cdc-inlong',
'hostname' = 'localhost',
'username' = 'root',
'password' = 'inlong',
'database-name' = 'test',
'scan.incremental.snapshot.enabled' = 'false',
'server-time-zone' = 'GMT+8',
'table-name' = 'user'
);
CREATE TABLE `table_2`(
PRIMARY KEY (`name`) NOT ENFORCED,
`name` STRING,
`age` INT)
WITH (
'connector' = 'jdbc',
'url' = 'jdbc:postgresql://localhost:5432/postgres',
'username' = 'postgres',
'password' = 'inlong',
'table-name' = 'public.user',
'port' = '3306'
);
INSERT INTO `table_2`
SELECT
`name` AS `name`,
`age` AS `age`
FROM `table_1`;
提交任务
./bin/flink run
-c org.apache.inlong.sort.Entrance apache-inlong-[version]-bin/inlong-sort/sort-dist-[version].jar \
--sql.script.file mysql-to-postgresql.sql
十一、InLong Sort的使用示例
为了更容易创建 InLong Sort 作业,这里我们列出了一些数据流配置示例。下面将介绍 InLong Sort 的 SQL、Dashboard、Manager 客户端工具的使用。
1.环境要求
- Apache Flink 1.13.5
- MySQL
- Apache Kafka
- Apache Hadoop
- Apache Hive 3.x
2.准备 InLong Sort 和 Connectors
准备安装文件
- InLong Sort 运行文件,下载 apache-inlong-[version]-bin.tar.gz
- 数据节点 Connectors,下载 apache-inlong-[version]-sort-connectors.tar.gz
Connectors 下载后可以将需要的 jars 放到FLINK_HOME/lib/下。
如果使用mysql-cdc-inlong 连接器,请将 mysql-connector-java:8.0.21.jar 包放到 FLINK_HOME/lib/下。
3.使用 SQL API 方式
示例构建了 MySQL --> Kafka --> Hive 的数据流,为了便于理解流程执行过程进行了拆解。
读 MySQL 写 Kafka
单表同步配置示例如下:
./bin/flink run
-c org.apache.inlong.sort.Entrance apache-inlong-[version]-bin/inlong-sort/sort-dist-[version].jar \
--sql.script.file mysql-to-kafka.sql
mysql-to-kafka.sql
CREATE TABLE `table_1`(
PRIMARY KEY (`id`) NOT ENFORCED,
`id` BIGINT,
`name` STRING,
`age` INT,
`salary` FLOAT,
`ts` TIMESTAMP(2),
`event_type` STRING)
WITH (
'append-mode' = 'true',
'connector' = 'mysql-cdc-inlong',
'hostname' = 'localhost',
'username' = 'root',
'password' = 'password',
'database-name' = 'dbName',
'table-name' = 'tableName'
);
CREATE TABLE `table_2`(
`id` BIGINT,
`name` STRING,
`age` INT,
`salary` FLOAT,
`ts` TIMESTAMP(2))
WITH (
'topic' = 'topicName',-- Your kafka topic
'properties.bootstrap.servers' = 'localhost:9092',
'connector' = 'kafka',
'json.timestamp-format.standard' = 'SQL',
'json.encode.decimal-as-plain-number' = 'true',
'json.map-null-key.literal' = 'null',
'json.ignore-parse-errors' = 'true',
'json.map-null-key.mode' = 'DROP',
'format' = 'json',
'json.fail-on-missing-field' = 'false'
);
INSERT INTO `table_2`
SELECT
`id` AS `id`,
`name` AS `name`,
`age` AS `age`,
CAST(NULL as FLOAT) AS `salary`,
`ts` AS `ts`
FROM `table_1`;
读 Kafka 写 Hive
需要在 hive 中先创建 user 表。
./bin/flink run
-c org.apache.inlong.sort.Entrance apache-inlong-[version]-bin/inlong-sort/sort-dist-[version].jar \
--sql.script.file kafka-to-hive.sql
kafka-to-hive.sql
CREATE TABLE `table_1`(
`id` BIGINT,
`name` STRING,
`age` INT,
`salary` FLOAT,
`ts` TIMESTAMP(2)
WITH (
'topic' = 'topicName',-- Your kafka topic
'properties.bootstrap.servers' = 'localhost:9092',
'connector' = 'kafka',
'scan.startup.mode' = 'earliest-offset',
'json.timestamp-format.standard' = 'SQL',
'json.encode.decimal-as-plain-number' = 'true',
'json.map-null-key.literal' = 'null',
'json.ignore-parse-errors' = 'true',
'json.map-null-key.mode' = 'DROP',
'format' = 'json',
'json.fail-on-missing-field' = 'false',
'properties.group.id' = 'groupId'-- Your group id
);
CREATE TABLE `user`(
`id` BIGINT,
`name` STRING,
`age` INT,
`salary` FLOAT,
`ts` TIMESTAMP(9))
WITH (
'connector' = 'hive',
'default-database' = 'default',
'hive-version' = '3.1.2',
'hive-conf-dir' = 'hdfs://ip:9000/.../hive-site.xml' -- Put your hive-site.xml into HDFS
);
INSERT INTO `user`
SELECT
`id` AS `id`,
`name` AS `name`,
`age` AS `age`,
CAST(NULL as FLOAT) AS `salary`,
`ts` AS `ts`
FROM `table_1`;
十二、InLong Sort监控指标
为节点增加了指标计算。 用户添加 with 选项 inlong.metric.labels 后 Sort 会计算指标,inlong.metric.labels 选项的值由三部分构成:groupId={groupId}&streamId={streamId}&nodeId={nodeId}。 用户可以使用 metric reporter 去上报数据。
将介绍一个同步MYSQL数据到PostgreSQL的例子,同时介绍指标的使用。
flink sql 的使用
create table `table_groupId_streamId_nodeId1`(
`id` INT,
`name` INT,
`age` STRING,
PRIMARY KEY(`id`) NOT ENFORCED)
WITH (
'connector' = 'mysql-cdc-inlong',
'hostname' = 'xxxx',
'username' = 'xxx',
'password' = 'xxx',
'database-name' = 'test',
'scan.incremental.snapshot.enabled' = 'true',
'server-time-zone' = 'GMT+8',
'table-name' = 'user',
'inlong.metric' = 'mysqlGroup&mysqlStream&mysqlNode1'
);
CREATE TABLE `table_groupId_streamId_nodeId2`(
PRIMARY KEY (`id`) NOT ENFORCED,
`id` INT,
`name` STRING,
`age` INT)
WITH (
'connector' = 'jdbc-inlong',
'url' = 'jdbc:postgresql://ip:5432/postgres',
'username' = 'postgres',
'password' = 'inlong',
'table-name' = 'public.user',
'inlong.metric' = 'pggroup&pgStream&pgNode'
);
INSERT INTO `table_groupId_streamId_nodeId2`
SELECT
`id`,
`name`,
`age`
FROM `table_groupId_streamId_nodeId1`;
可以在flink-conf.yaml中添加metric report配置
metric.reporters: promgateway
metrics.reporter.promgateway.class: org.apache.flink.metrics.prometheus.PrometheusPushGatewayReporter
metrics.reporter.promgateway.host: ip
metrics.reporter.promgateway.port: 9091
metrics.reporter.promgateway.interval: 60 SECONDS
ip 和 port 是你的 pushgateway 的配置。
执行上面的sql后,我们可以访问 pushgateway 的 url: http://ip:port
十三、数据节点Extract Nodes
1.MySQL-CDC
MySQL Extract 节点允许从 MySQL 数据库中读取快照数据和增量数据。
支持的版本
| Extract 节点 | 版本 | Driver |
|---|---|---|
| MySQL-CDC | MySQL: 5.6, 5.7, 8.0.x 、RDS MySQL: 5.6, 5.7, 8.0.x、PolarDB MySQL: 5.6, 5.7, 8.0.x、Aurora MySQL: 5.6, 5.7, 8.0.x、MariaDB: 10.x、PolarDB X: 2.0.1 | JDBC Driver: 8.0.21 |
Maven 依赖
<dependency>
<groupId>org.apache.inlong</groupId>
<artifactId>sort-connector-mysql-cdc</artifactId>
<version>1.5.0-SNAPSHOT</version>
</dependency>
连接 MySQL 数据库还需要 MySQL 驱动程序依赖项。请下载mysql-connector-java-8.0.21.jar 并将其放入 FLINK_HOME/lib/。
创建一个 MySQL Extract 节点
SQL API 用法
下面这个例子展示了如何用 Flink SQL 创建一个 MySQL Extract 节点。
-- 设置 Checkpoint 为 3000 毫秒
Flink SQL> SET 'execution.checkpointing.interval' = '3s';
Flink SQL> CREATE TABLE mysql_extract_node (
order_id INT,
order_date TIMESTAMP(0),
customer_name STRING,
price DECIMAL(10, 5),
product_id INT,
order_status BOOLEAN,
PRIMARY KEY(order_id) NOT ENFORCED
) WITH (
'connector' = 'mysql-cdc-inlong',
'hostname' = 'YourHostname',
'port' = '3306',
'username' = 'YourUsername',
'password' = 'YourPassword',
'database-name' = 'YourDatabaseName',
'table-name' = 'YourTableName');
Flink SQL> SELECT * FROM mysql_extract_node;
多库多表同步
Mysql Extract 节点支持整库、多表同步。开启该功能后,Mysql Extract 节点会将表的物理字段压缩成 ‘canal-json’ 格式的特殊元字段 ‘data_canal’,也可配置为 ‘debezium-json’ 格式的元数据字段 ‘data_debezium’。
CREATE TABLE 示例演示该功能语法:
CREATE TABLE `table_1`(
`data` STRING METADATA FROM 'meta.data_canal' VIRTUAL)
WITH (
'inlong.metric.labels' = 'groupId=1&streamId=1&nodeId=1',
'migrate-all' = 'true',
'connector' = 'mysql-cdc-inlong',
'hostname' = 'localhost',
'database-name' = 'test,test01',
'username' = 'root',
'password' = 'inlong',
'table-name' = 'test01\.a{2}[0-9]$, test\.[\s\S]*'
)
2.Kafka
Kafka Extract 节点 支持从 Kafka topics 中读取数据。它支持以普通的方式读取数据和 Upsert 的方式读取数据。upsert-kafka 连接器生产 changelog 流, 其中每条数据记录代表一个更新或删除事件。kafka-inlong 连接器可以以普通方式读取数据和元数据信息。
Maven 依赖
<dependency>
<groupId>org.apache.inlong</groupId>
<artifactId>sort-connector-kafka</artifactId>
<version>1.5.0-SNAPSHOT</version>
</dependency>
创建 Kafka Extract 节点
SQL API 用法
用 Flink SQL 创建一个 Kafka Extract 节点:
- 连接器是 kafka-inlong
-- 设置 Checkpoint 为 3000 毫秒
Flink SQL> SET 'execution.checkpointing.interval' = '3s';
-- 使用 Flink SQL 创建 Kafka 表 'kafka_extract_node'
Flink SQL> CREATE TABLE kafka_extract_node (
`id` INT,
`name` STRINTG
) WITH (
'connector' = 'kafka-inlong',
'topic' = 'user',
'properties.bootstrap.servers' = 'localhost:9092',
'properties.group.id' = 'testGroup',
'scan.startup.mode' = 'earliest-offset',
'format' = 'csv'
)
-- 读取数据
Flink SQL> SELECT * FROM kafka_extract_node;
- 连接器是 upsert-kafka
-- 设置 Checkpoint 为 3000 毫秒
Flink SQL> SET 'execution.checkpointing.interval' = '3s';
-- 使用 Flink SQL 创建 Kafka 表 'kafka_extract_node'
Flink SQL> CREATE TABLE kafka_extract_node (
`id` INT,
`name` STRINTG,
PRIMARY KEY (`id`) NOT ENFORCED
) WITH (
'connector' = 'upsert-kafka-inlong',
'topic' = 'user',
'properties.bootstrap.servers' = 'localhost:9092',
'properties.group.id' = 'testGroup',
'scan.startup.mode' = 'earliest-offset',
'key.format' = 'csv',
'value.format' = 'csv'
)
-- 读取数据
Flink SQL> SELECT * FROM kafka_extract_node;
十四、数据节点Load Nodes
Load 节点列表是一组基于 Apache Flink® 的 Sink Connectors 用于将数据加载到不同的存储系统。
1.Kafka
Kafka Load 节点支持写数据到 Kafka topics。 它支持以普通的方式写入数据和 Upsert 的方式写入数据。 upsert-kafka 连接器可以消费 changelog 流。它会将 INSERT/UPDATE_AFTER 数据作为正常的 Kafka 消息写入,并将 DELETE 数据以 value 为空的 Kafka 消息写入(表示对应 key 的消息被删除)
Maven 依赖
<dependency>
<groupId>org.apache.inlong</groupId>
<artifactId>sort-connector-kafka</artifactId>
<version>1.5.0-SNAPSHOT</version>
</dependency>
创建 Kafka Load 节点
用 Flink SQL 创建一个 Kafka Load 节点:
- 连接器是 kafka-inlong
-- 使用 Flink SQL 创建 Kafka 表 'kafka_load_node'
Flink SQL> CREATE TABLE kafka_load_node (
`id` INT,
`name` STRINTG
) WITH (
'connector' = 'kafka-inlong',
'topic' = 'user',
'properties.bootstrap.servers' = 'localhost:9092',
'properties.group.id' = 'testGroup',
'format' = 'csv'
)
- 连接器是 upsert-kafka
-- 使用 Flink SQL 创建 Kafka 表 'kafka_load_node'
Flink SQL> CREATE TABLE kafka_load_node (
`id` INT,
`name` STRINTG,
PRIMARY KEY (`id`) NOT ENFORCED
) WITH (
'connector' = 'upsert-kafka-inlong',
'topic' = 'user',
'properties.bootstrap.servers' = 'localhost:9092',
'key.format' = 'csv',
'value.format' = 'csv'
)
特征
支持动态 Schema 写入
动态 Schema 写入支持从数据中动态提取 Topic 和 Partition, 并写入到对应的 Topic 和 Partition。为了支持动态 Schema 写入,需要设置 Kafka 的 Format 格式为 ‘raw’, 同时需要设置上游数据的序列化格式(通过选项 ‘sink.multiple.format’ 来设置, 目前仅支持 [canal-json|debezium-json])。
动态 Topic 提取
动态 Topic 提取即通过解析 Topic Pattern 并从数据中提取 Topic 。 为了支持动态提取 Topic, 需要设置选项 ‘topic-pattern’, Kafka Load Node 会解析 ‘topic-pattern’ 作为最终的 Topic, 如果解析失败, 会写入通过 ‘topic’ 设置的默认 Topic 中。‘topic-pattern’ 支持常量和变量,常量就是字符串常量, 变量是严格通过 ‘${VARIABLE_NAME}’ 来表示, 变量的取值来自于数据本身, 即可以是通过 ‘sink.multiple.format’ 指定的某种 Format 的元数据字段, 也可以是数据中的物理字段。
关于 ‘topic-parttern’ 的例子如下:
- ‘sink.multiple.format’ 为 ‘debezium-json’:
{
"before": {
"id": 4,
"name": "scooter",
"description": "Big 2-wheel scooter",
"weight": 5.18
},
"after": {
"id": 4,
"name": "scooter",
"description": "Big 2-wheel scooter",
"weight": 5.15
},
"source": {
"db": "inventory",
"table": "products"
},
"op": "u",
"ts_ms": 1589362330904,
"transaction": null
}
- ‘topic-pattern’ 为 ‘{database}_${table}’, 提取后的 Topic 为 ‘inventory_products’ (‘source.db’, ‘source.table’ 为元数据字段)
- ‘topic-pattern’ 为 ‘{database} t a b l e {table} table{id}’, 提取后的 Topic 为 ‘inventory_products_4’ (‘source.db’, ‘source.table’ 为元数据字段, ‘id’ 为物理字段)
动态 Partition 提取
动态 Partition 提取即通过解析 Partition Pattern 并从数据中提取 Partition, 这和动态 Topic 提取类似。 为了支持动态提取 Topic, 需要设置选项 ‘sink.partitioner’ 为 ‘raw-hash’ 和选项 ‘sink.multiple.partition-pattern’, Kafka Load Node 会解析 ‘sink.multiple.partition-pattern’ 作为 Partition key, 并对 Partition key 进行 Hash 和对 Partition Size 取余以确定最终 Partition, 如果解析失败, 会返回 null 并执行 Kafka 默认的分区策略。‘sink.multiple.partition-pattern’ 支持常量、变量和主键,常量就是字符串常量, 变量是严格通过 ${VARIABLE_NAME} 来表示, 变量的取值来自于数据本身, 即可以是通过 ‘sink.multiple.format’ 指定的某种 Format 的元数据字段, 也可以是数据中的物理字段, 主键是一种特殊的常量 ‘PRIMARY_KEY’, 基于某种 Format 的数据格式下来提取该条记录的主键值。
注意: 基于 ‘PRIMARY_KEY’ 的 Kafka 动态 Partition 提取, 有一个限制, 即需要在数据中指定主键信息, 由于 Format ‘debezium-json’ 无主键的定义, 对此 我们约定 ‘debezium-json’ 的主键 Key 也为 ‘pkNames’ 且和其他元数据字段如 ‘table’、‘db’ 一样包含在 'source’中, 如果用到了按主键分区, 且 Format 为 ‘debezium-json’, 需要确保真实数据满足上述约定。
2.MySQL
MySQL Load 节点支持将数据写入 MySQL 数据库。
Maven 依赖
<dependency>
<groupId>org.apache.inlong</groupId>
<artifactId>sort-connector-jdbc</artifactId>
<version>1.5.0-SNAPSHOT</version>
</dependency>
MySQL license 和 Inlong license 是冲突的。 所以移除了pom中的 MySQL 驱动依赖。 如果我们想使用这个连接器,我们可以修改pom文件。
创建 MySQL Load 节点
-- MySQL Extract 节点
CREATE TABLE `mysql_extract_table`(
PRIMARY KEY (`id`) NOT ENFORCED,
`id` BIGINT,
`name` STRING,
`age` INT
) WITH (
'connector' = 'mysql-cdc-inlong',
'url' = 'jdbc:mysql://localhost:3306/read',
'username' = 'inlong',
'password' = 'inlong',
'table-name' = 'user'
)
-- MySQL Load 节点
CREATE TABLE `mysql_load_table`(
PRIMARY KEY (`id`) NOT ENFORCED,
`id` BIGINT,
`name` STRING,
`age` INT
) WITH (
'connector' = 'jdbc-inlong',
'url' = 'jdbc:mysql://localhost:3306/write',
'username' = 'inlong',
'password' = 'inlong',
'table-name' = 'user'
)
-- 写数据到 MySQL
INSERT INTO mysql_load_table
SELECT id, name , age FROM mysql_extract_table;
3.Hive
Hive 加载节点可以将数据写入 Hive。使用 Flink 方言,目前仅支持 Insert 操作,Upsert 模式下的数据会转换成 Insert 方式 目前暂时不支持使用 Hive 方言操作 Hive 表。
通过 Maven 引入 sort-connector-hive 构建自己的项目。 当然,你也可以直接使用 INLONG 提供的 jar 包。(sort-connector-hive)
Maven 依赖
<dependency>
<groupId>org.apache.inlonggroupId>
<artifactId>sort-connector-hiveartifactId>
<version>1.5.0-SNAPSHOTversion>
dependency>
配置 Hive 数据加载节点
使用 Flink SQL Cli :
CREATE TABLE hiveTableName (
id STRING,
name STRING,
uv BIGINT,
pv BIGINT
) WITH (
'connector' = 'hive',
'default-database' = 'default',
'hive-version' = '3.1.2',
'hive-conf-dir' = 'hdfs://localhost:9000/user/hive/hive-site.xml'
);
4.Iceberg
Apache Iceberg是一种用于大型分析表的高性能格式。
依赖项
<dependency>
<groupId>org.apache.inlonggroupId>
<artifactId>sort-connector-icebergartifactId>
<version>1.5.0-SNAPSHOTversion>
dependency>
SQL API 用法
在 flink 中创建Iceberg表,推荐使用Flink SQL Client,因为它更便于用户理解概念。
Step.1 在hadoop环境下启动一个独立的flink集群。
# HADOOP_HOME is your hadoop root directory after unpack the binary package.
export HADOOP_CLASSPATH=`$HADOOP_HOME/bin/hadoop classpath`
# Start the flink standalone cluster
./bin/start-cluster.sh
Step.2 启动flink SQL客户端。
flink-runtime在 iceberg 项目中创建了一个单独的模块来生成一个捆绑的 jar,可以直接由 flink SQL 客户端加载。
如果想要flink-runtime手动构建捆绑的 jar,只需构建inlong项目,它将在/inlong-sort/sort-connectors/iceberg/target。
默认情况下,iceberg 包含用于 hadoop 目录的 hadoop jars。如果我们要使用 hive 目录,我们需要在打开 flink sql 客户端时加载 hive jars。幸运的是,apache inlong将 一个捆绑的hive jar打包进入Iceberg。所以我们可以如下打开sql客户端:
# HADOOP_HOME is your hadoop root directory after unpack the binary package.
export HADOOP_CLASSPATH=`$HADOOP_HOME/bin/hadoop classpath`
./bin/sql-client.sh embedded -j <flink-runtime-directory>/iceberg-flink-runtime-xxx.jar shell
Step.3 在当前 Flink 目录中创建表
默认情况下,我们不需要创建目录,只需使用内存目录即可。在目录中如果catalog-database.catalog-table不存在,会自动创建。这里我们只是加载数据。
在 Hive 目录中管理的表
下面的 SQL 会在当前 Flink 目录中创建一个 Flink 表,映射到 iceberg 目录中default_database.iceberg_table管理的 iceberg 表。由于目录类型默认是 hive,所以这里不需要放catalog-type.
CREATE TABLE flink_table (
id BIGINT,
data STRING
) WITH (
'connector'='iceberg',
'catalog-name'='hive_prod',
'uri'='thrift://localhost:9083',
'warehouse'='hdfs://nn:8020/path/to/warehouse'
);
将记录写入 Flink 表时,如果底层目录数据库(hive_db上例中)不存在,则会自动创建它。
在 hadoop 目录中管理的表
以下 SQL 将在当前 Flink 目录中创建一个 Flink 表,该表映射到default_database.flink_tablehadoop 目录中管理Iceberg表。
CREATE TABLE flink_table (
id BIGINT,
data STRING
) WITH (
'connector'='iceberg',
'catalog-name'='hadoop_prod',
'catalog-type'='hadoop',
'warehouse'='hdfs://nn:8020/path/to/warehouse'
);
Step.6 向Iceberg表中插入数据
INSERT INTO `flink_table`
SELECT
`id` AS `id`,
`d` AS `name`
FROM `source_table`
在自定义Catalog中管理的表
以下 SQL 将在当前 Flink 目录中创建一个 Flink 表,该表映射到default_database.flink_table自定义目录中管理的Iceberg表。
CREATE TABLE flink_table (
id BIGINT,
data STRING
) WITH (
'connector'='iceberg',
'catalog-name'='custom_prod',
'catalog-type'='custom',
'catalog-impl'='com.my.custom.CatalogImpl',
-- More table properties for the customized catalog
'my-additional-catalog-config'='my-value',
...
);
多表写入
目前 Iceberg 支持多表同时写入,需要在 FLINK SQL 的建表参数上添加 ‘sink.multiple.enable’ = ‘true’ 并且目标表的schema 只能定义成 BYTES 或者 STRING ,以下是一个建表语句举例:
CREATE TABLE `table_2`(
`data` STRING)
WITH (
'connector'='iceberg-inlong',
'catalog-name'='hive_prod',
'uri'='thrift://localhost:9083',
'warehouse'='hdfs://localhost:8020/hive/warehouse',
'sink.multiple.enable' = 'true',
'sink.multiple.format' = 'canal-json',
'sink.multiple.add-column.policy' = 'TRY_IT_BEST',
'sink.multiple.database-pattern' = '${database}',
'sink.multiple.table-pattern' = 'test_${table}'
);
要支持多表写入同时需要设置上游数据的序列化格式(通过选项 ‘sink.multiple.format’ 来设置, 目前仅支持 [canal-json|debezium-json])。
动态表名映射
Iceberg 在多表写入的时可以自定义映射的数据库名和表名的规则,可以填充占位符然后添加前后缀来修改映射的目标表名称。 Iceberg Load Node 会解析 ‘sink.multiple.database-pattern’ 作为目的端的 数据库名, 解析 ‘sink.multiple.table-pattern’ 作为目的端的表名,占位符是从数据中解析出来的,变量是严格通过 ‘${VARIABLE_NAME}’ 来表示, 变量的取值来自于数据本身, 即可以是通过 ‘sink.multiple.format’ 指定的某种 Format 的元数据字段, 也可以是数据中的物理字段。
动态建库、建表
Iceberg在多表写入时遇到不存在的表和不存在的库时会自动创建数据库和数据表,并且支持在运行过程中新增捕获额外的表入库。 默认的Iceberg表参数为:‘format-version’ = ‘2’、‘write.upsert.enabled’ = ‘true’'、‘engine.hive.enabled’ = ‘true’
动态schema变更
Iceberg在多表写入时支持同步源表结构变更到目标表(DDL同步),支持的schema变更如下:
| schema变更类型 | 是否支持 |
|---|---|
| 列增加 | 是 |
| 列减少 | 否 |
| 列位置变更 | 否 |
| 列重命名 | 否 |
| 列类型变更 | 否 |