MySQL--视图、存储过程、触发器
1、视图
1、定义:
所谓的视图是一种虚拟存在的表,视图中的数据并不在数据库中实际存在,就是视图只保存了查询的SQL逻辑,不保存查询的结果,所以在创建视图的时候,主要的工作就是落在创建这条SQL查询语句的时候。
创建一个视图:
create view 视图的名称 as select 语句
create view stu_v as select id , name from student ;
查询视图:
show create view 视图的名称;
查询视图表中的数据:
select * from 视图表的名称;
修改视图的命令:
alter view 视图的名称 as select 语句;
删除视图:
drop view [if exists ]视图的名称;2、视图的检查选项:
当使用with check option子句在创建视图的时候,MySQL会通过视图检查正在修改的每一行的数据,查看是否符合视图的定义。MySQL允许基于一个视图创建另一个视图,还是会检测依赖视图中的规则,以保证规则的一致性,为了检查范围,mysql提供了两种选项:cascaded和local,默认使用的是cascaded
1、cascaded:
例如:
create view stu_v as select id ,name ,age from student where age >10 with cascaded check option;
此时如果对上面的视图进行修改的时候,此时就会判断修改的是否符合修改的规则,如果不符合,那么就不会进行修改。
create view stu_v as select id ,name ,age from student where age >10 ;
create view stu_v1 as select id ,age from stu_v where age > 5 with cascaded check option;
此时因为视图stu_v1是依赖于视图stu_v之上进行的查询,此时当修改视图stu_v1时,会判断是否符合stu_v1的规则,也会去判断是否符合stu_v的规则。也就相当于在stu_v后面也添加了with cascaded check option;
2、local:
与cascaded是基本一致的,对于依赖的视图中,如果有条件,就会去判断是否符合条件,如果没有,那么就不会去判断以来的视图。
create view stu_v as select id ,name ,age from student where age >10 with local check option;
create view stu_v as select id ,name ,age from student where age >10 ;
create view stu_v1 as select id ,age from stu_v where age > 5 with local check option;
此时的stu_v1是依赖于stu_v。3、视图更新
对于视图能更新的前提就是视图中的行和基础表中的行之间是一一对应的。对于存在聚合函数、窗口函数、distinct、having、group by、union的是不能更新视图的。
4、视图的作用:
1、简单,可以简化用户对数据的理解,也可以简化他们的操作,可以对于那些常用的语句进行视图操作,以至于以后该操作就需要在指定全部的条件。
2、安全,数据库可以授权,但是不能授权到数据库特定的行和列中,可以通过视图用户可以查询和修改能看见的数据。
例如:在学生系统中,只能让用户看见学生的姓名和学号,此时可以使用视图进行操作
创建一个视图
create view stu_v as select id ,name from student ;
此时用户可以从该视图中查询学生的姓名和学号
select id,name from stu_v where id =001;3、数据独立,视图可以帮助用户屏蔽真是表结构改变带来的影响。如果在基础表中,某一列发生改变了, 此时可以通过更新视图表与基础表保持一致,但是可以将原先的列名作为别名,此时视图表的结构并没有发生改变。
2、存储过程:
1、定义
所谓的存储过程指的是事先编译并存储在数据库中的一点SQL的集合,调用存储过程可以简化数据在数据库和应用服务器之间的传输,可以提高数据处理的效率。
特点:封装、复用、可以接受参数、也可以返回数据、减少网络的交互、效率提高。
1、创建存储过程:
create procedure 存储过程的名称 ()
begin
执行的SQL语句;
end;
例如:
create procedure stu ()
begin
select * from student ;
end;
2、调用存储过程:
call 存储过程的名称 (参数);
例如:
call stu() ;
3、查看存储过程:
show procedure 存储过程的名字;
例如:
show procedure stu();
4、删除存储过程:
drop procedure 存储过程的名称;
例如:
drop procedure stu;2、变量
变量:
1、变量主要分成三种变量:系统变量、用户自定变量、局部变量
2、系统变量:
主要分成两种:全局变量(global)、会话变量(session)
全部变量:作用在全局
会话变量:作用在当前会话内,与其他的会话不会产生影响。
查看系统的全局、会话变量:
show [ global/session ]variables;
设置系统变量:
语法:set [global/session] 环境参数;
set session sutocommit = 0;
3、用户自定变量:是用户根据自己的需求定义的变量,作用域只在当前的会话中。
赋值:语法格式:set @变量名 = 变量参数
使用:select @变量名;
4、局部变量:指的是在局部生效的变量,在访问之前是需要declare进行声明的,局部变量生效的范围是在begin...end之间。
声明的语法:declare 变量名 变量的类型;
对局部变量进行赋值:set 变量名 = 值
或者 select 字段名 into 变量名 from 表名3、存储函数:

4、触发器:
1、定义
触发器是与表有关的数据库对象,会在增删改之前或之后进行触发在触发器中定义的SQL的语句集合。使用OLD和NEW来引用触发器中数据发生变化的记录的内容。
2、触发器的类型
触发器的种类:
1、insert触发器
2、delete触发器
3、update触发器
查看触发器
show trigger ;
删除一个触发器
drop trigger 数据库的名称 触发器的名称5、Mysql的锁:
1、锁:是计算机中多个线程和进程并发访问某一个资源的机制。主要可以分成三类:
1、全局锁:锁定的数据库中所有的表
2、表级锁:锁定的是每一次操作的整张表
3、行级锁:锁定的是每一次操作对应的行数据
2、全局锁:
全局锁是对整个数据库实例加锁,在加锁之后整个数据就变成了一个只读的状态,后续的DML、语句、DDL语句和已经更新操作的事务提交语句都将被阻塞。
最典型的引用应用:在进行数据库全库的逻辑备份的时候,对所有的表进行全局锁,从而获取一致性视图,保证数据库的完整性。
在MySQL中的数据备份指定是将数据变成一个SQL文件存储到磁盘中。
1、添加全局锁:
flush table with read lock;
//对数据进行备份在window中执行:
mysqldump -u 用户名 -p 密码 指定需要备份的数据库的名称 > 指定数据库中的数据存储到那个SQL文件中。
2、解锁全局锁:
unlock table ;
3、在INNODB 计算引擎中,我们可以在备份的时候加上参数 --single-transaction 参数来完成不加锁的一致性数据备份。
mysqldump --single-transaction -u 用户名 -p 密码 指定需要备份的数据库 > 指定数据库中的数据存储到哪一个SQL文件中。
全局锁的特点:
1、如果在主数据库中添加全局锁,在备份期间数据是不能进行更新、插入、删除的操作。
2、如果在从数据库中备份,那么从库就不能执行主库同步过来的二进制日志。会导致主从延迟。
3、表级锁:
又可以分成表锁、元数据锁(meta data lock,MDL) 、意向锁
1、表锁:
对于表锁又可以分成两种:表共享读锁(read lock)、表独占写锁(write lock)
1、表共享读锁(read lock):
加上表的读锁,当前客户端只能读取数据,不能写入数据,并且不会阻碍其他的客户端的读操作,会阻碍其他客户端的写操作。
2、表独占写锁(write lock):
加上了写锁,当前客户端既可以读取数据也可以写入数据,单数对于其他的客户端既不能读数据,也不也能写入数据。
对表进行加锁:
lock table 表名...[可以是多张表] read/write
释放锁:
unlock tables /也可以通过断开客户端的连接来释放表锁。2、元数据锁(meta data lock,MDL)
MDL加锁的过程是系统自动控制的,在访问一张表的时候会自动的加上。他的主要作用是维护数据一致性,当表上有活跃的事务的时候,此时就不可以对元数据进行写入操作。
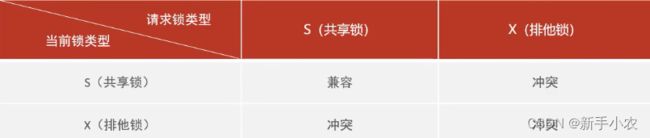
在MySQL5.5中引入了MDL,当对一张表进行增删改的时候,加上的MDL读锁(共享锁),当对表的结构进行改变的时候,加上DML写锁(排他锁)
 ,
,
3、意向锁:
为了避免DML在执行的时候,加的行锁和表锁之间的冲突,在INNODB中引入意向锁,是的表锁不用检查每行是否加锁,使用意向锁来减少表锁的检查。
1、意向共享锁(IS):
select .... lock in share mode 2、意向排他锁(IX):
insert update delete select .... for update 
4、行级锁:
行级锁,每次操作锁住对应的行数据,锁定的力度最小,发生锁冲突的概率最低,并发度是最高的。应用在INNODB存储引擎中。
主要分成三种:
InnoDB的数据是基于索引组织的,行锁是通过对索引上的索引项加锁来实现的,而不是对记录加的锁。对于行级锁,主要分为以下三类
1. 行锁(Record Lock):锁定单个行记录的锁,防止其他事务对此行进行update和delete。在RC、RR隔离级别下都支持。
2间隙锁(Gap Lock):锁定索引记录间隙(不含该记录),确保索引记录间隙不变,防止其他事务在这个间隙进行insert,产生幻读。在RR隔离级别下都支持
3.临键锁(Next-Key Lock)∶行锁和间隙锁组合,同时锁住数据,并锁住数据前面的间隙Gap。在RR隔离级别下支持
lnnoDB实现了以下两种类型的行锁:
1.共享锁(S)∶允许一个事务去读一行,阻止其他事务获得相同数据集的排它锁。
2.排他锁(X)∶允许获取排他锁的事岛更新数据,阻止其他事务获得相同数据集的共享锁和排他锁。