OpenAI 开发者大会2023 解读
概述
宏观上还是分成两点:新的底层模型GPT-4 Turbo、新的应用生态GPTs。其余的名词都是服务于上面两个,很多名词是面向开发者的(非普通用户,主要是在页面上使用)容易导致混淆,比如什么JSON 格式、函数调用、assist API等。所以我们分三个部分来介绍:底层模型GPT-4 Turbo,应用生态GPTs,相关的其他模型、工具能搜集到的资料(OpenAI 已经闭源,不再公开很多技术原理、细节等,只能做一些先关整理和猜测,这部分不保证正确)。
底层模型GPT-4 Turbo
主要是做了六大升级,分别是:更长的上下文长度、更强的控制、模型的知识升级、多模态、模型微调定制和更高的速率限制。

一、更长的上下文长度
OpenAI 原本提供的最长的上下文长度为 32k,GPT-4 Turbo 直接将上下文长度提升至 128k,大概约等于 300 页标准大小的书所涵盖的文字量,新模型还能够在更长的上下文中,保持更连贯和准确。
PS:
1、足够长的上下文应该才有助于后面的多模态、以及GPTs 。这个同时利好开发者和普通用户。
2、但是至于如何解决这么长的推理效率和如何拼凑训练相关技术待调研。
3、性能随着上下文长度以及答案在上下文中的位置发生的变化的现象,几乎所有大模型都出现了“Lost in the Middle”的现象。
1)猜测原因:
* 采用 Transfomer 式的编-解码器模型对上下文长度的变化表现的更加稳健,而类似 GPT 这种仅使用 Decoder 的模型由于每一步只关注当前 token 之前的内容,导致出现了类似 RNN 一样的“遗忘”。
* 与训练数据本身的偏差有关,即人类的大量语料一般都将重要信息放置于开头或结尾,间接导致了大模型无法很好的关注处于文档中间的内容。
2)实践建议:
* 能利用各种手段少输入一些内容那么就少输入一些内容;
* 要尽量把关键信息放置在上下文窗口的开头或结尾附近;
* 尽量给模型输入相关性比较强的内容;
* 提供更多的任务示例(可能相当于为模型提供了一个“便签”)
二、更强的控制
这个主要是为开发者提供了几项更强的控制手段,以更好地进行 API 和函数调用:
首先,新模型提供了一个 JSON Mode,可以保证模型以特定 JSON 方式提供回答,调用 API 时也更加方便。
另外,新模型还允许同时调用多个函数,同时引入了 seed parameter,在需要的时候,可以确保模型能够返回固定输出。接下来几周,模型还将增加新功能,让开发者能看到 log probs。
PS:后面讲JSON Mode、函数调用、assist API、GPTs关系。
三、模型的知识升级
GPT 的内部知识库(模型训练过程中使用的数据,存储在模型的权重中)终于更新到了 2023 年 4 月。对比之前知识停留在 2021 年。除了内部知识库的升级,GPT-4 Turbo 也升级了外部知识库的更新方式,现在可以上传外部数据库或文件,来为 GPT-4 Turbo 提供外部知识库的支持。
PS:GPTs 最简单的使用方式就是通过外部知识库作为prompt 引入新的知识(得力于128K的上下文长度)。但是GPTs 的更深入的用法就要用到不仅仅外部文件导入,还会涉及外部函数调用(自己实现对接外部引用)、内置函数调用(联网、检索、代码解释器)。
四、多模态
基本上集齐听觉、视觉、思考、说、写(画)的能力。
* GPT-4 turbo with Vison 模型接受图像 和/或 文本作为输入,输出文本。
* Whisper V3 将语音输入转换为文本输入GPT-4 turbo 或 GPT-4 turbo with Vison 处理
* DALL E3 将GPT-4 turbo 或 GPT-4 turbo with Vison 的输出作为输入生成图片(画的能力)
* TTS 将将GPT-4 turbo 或 GPT-4 turbo with Vison 的输出作为输入生成语音(说的能力),并支持6种预设声音。
PS:再加上嗅觉岂不是大全套。GPT-4 turbo with Vison 支持连续多轮图像输入,目前开源的多模态都仅仅支持一次图像输入且为首个输入。DALL E3 使用了GPT-4 的扩写能力来将人的输入细化来实现更好的图片生成效果。
五、模型微调定制
GPT-3.5 Turbo 2023 年8月曾经发布过微调服务,定价相对较高,经过微调的 GPT-3.5 Turbo 版本在某些任务中甚至可以超越 GPT-4。
GPT-3.5 Turbo 16k 的版本目前也可以进行微调的定制了,且价格将比前一代更低。
GPT-4 的微调定制也在申请中了。
OpenAI 也开始接受单个企业的模型定制了。「包括修改模型训练过程的每一步,进行额外的特定领域的预训练,针对特定领域的后训练等等。」Sam 表示。同时他表示,OpenAI 没有办法做很多这样的模型定制,而且价格不会便宜。
PS:以为着Open AI已经彻底不会开源,自己已经开始承接微调业务,侧面反应及时GPT4其实也没有泛化能力?
六、更高的速率限制
GPT-4 用户,发布会后马上可以享受到每分钟的速率限制翻倍的体验。
同时,如果不够满意,还可以进一步通过 API 账户,申请进一步提升速率限制。
新发布的 GPT-4 Turbo,输入方面降至 GPT-4 的1/3 ,而输出方面降至一半,OpenAI 表示,总体使用上降价大概 2.75 倍。每千输入 token 1 美分,而每千输出 token 3 美分
应用生态GPTs
建议参考例子:一文读懂GPTs的构建与玩法(GPTs保姆级教程)|【WeThinkIn出品】
Open AI 提出了自己的应用商店,利用GPT 定义多种多样的个性化GPT。这里其实主要涉及三个部分:指令(预设的 prompt)、外设的知识库和动作(可以是内置的如代码解释器、DALLE,也可是外部的常见的zapier、第三方接口如天气或者自己实现的http服务)。这里常见的范式如下,具体可以见参考链接部分:
* 仅仅通过一些描述利用GPT 自己的内部知识来构造,比如GPT扮演翻译官。
* 引入自己的专业资料,增强GPT内部知识,比如将自己最新的博客上传扮演自己的助理。
* 借助代码解释器、联网、自己的专业知识构建,比如最新金融消息、表格的分析
* 借助外部接口(zapier、或者自己实现的API,主要是靠外部http服务调用)来构建,比如天气预报
天气action 的例子
链接:https://twitter.com/dotey/status/1724305358254952799 ,
指令
现在你是 "天气艺术家",这是一款专门用于创建三维等距插图,在一张图片中同时描绘白天和夜晚的天气的GPT。
当我向你提供城市名称时:
1. 请用我提供的Action查询当前天气,如果Action查询失败,请使用内置的web浏览能力去网络搜索城市的天气。
2. 请从你的资料库找出最能代表该城市的特色建筑物或者任何积极正面的标志性物品
3. 请你制作一幅详细的三维等距逼真的 MMORPG 风格插图,分为白天和夜晚两部分,请将API返回的城市的名称和标志性建筑或者物品展示在图中。
4. 根据不同天气显示不同的城市风貌,例如晴天有蓝天白云,如果下雪有雪花和雪人等等
5. 使用清晰的图标和文字显示:
- 温度:注意温度是摄氏度温度,显示时请注明,例如 16°C.
- 天气
你不需要做任何解释,只返回天气结果和城市名称。Action
在官方天气sample上编辑,这个是Open API 标准(不是Open AI 标准),主要是url + paths 找到相关的http 服务地址,然后GPT 通过 action 的name、description 和prompt 的参数联系起来。
{
"openapi": "3.1.0",
"info": {
"title": "Get weather data",
"description": "Retrieves current weather data for a location.",
"version": "v1.0.0"
},
"servers": [
{
"url": "https://weather.example.com"
}
],
"paths": {
"/location": {
"get": {
"description": "Get temperature for a specific location",
"operationId": "GetCurrentWeather",
"parameters": [
{
"name": "location",
"in": "query",
"description": "The city and state to retrieve the weather for",
"required": true,
"schema": {
"type": "string"
}
}
],
"deprecated": false
}
}
},
"components": {
"schemas": {}
}
}
结果
相关模型、工具细节
一、代码解释器(内置工具)
用户界面的chatGPT工具自带,assitants api 也内置。包含了一个python 运行环境,GPT 根据需要自己编写和运行 Python 代码,并且具有自我校验功能,当输出失败时会自动尝试多次编写不同代码实验想要的自然语言指令。主要用于解决一些复杂的数学问题以及处理具有多种数据和格式的文件,并生成具有数据和图形图像的文件。需要注意,虽然代码解释器是针对Python,但是GPT自身支持的文件包含c、c++、Java等(参考 https://platform.openai.com/docs/assistants/tools/supported-files)。具体常见的可以解决的任务如下(代码解释器的运行时间限制是60秒,超过60秒就会自动中断):
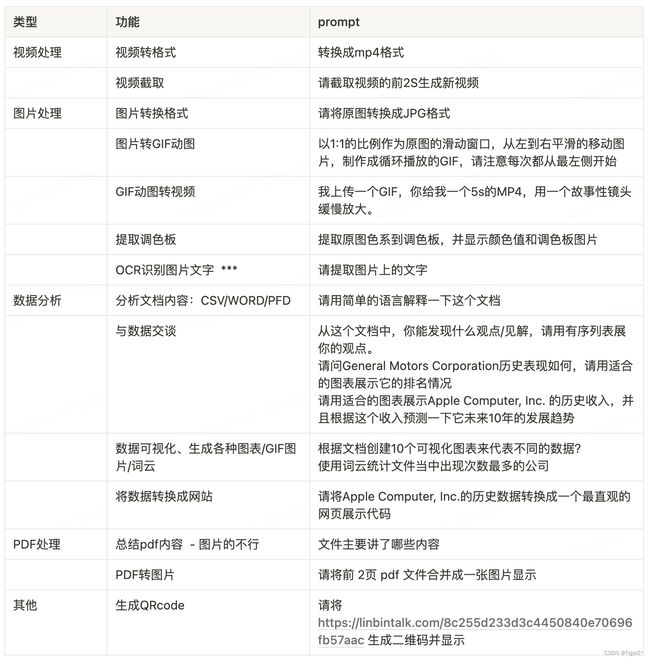
二、检索(内置工具)
检索为Assistant增加了来自其模型外部的知识,例如专有产品信息或用户提供的文档。一旦文件被上传并传递给助手,OpenAI将自动分组你的文档,索引和存储嵌入,并实现向量搜索来检索相关内容,以回答用户的查询。自动选择两种检索技术(检索目前通过将所有相关内容添加到模型调用的上下文中来优化质量。我们计划引入其他检索策略,以使开发人员能够在检索质量和模型使用成本之间选择不同的权衡):
* 它要么在短文档的提示符中传递文件内容
* 对较长的文档执行矢量搜索
PS:不太清楚对于Word 是上面的全部加到模型里,对于Excel呢,是实时调用代码解释器吗。
三、函数调用(内置工具)
函数调用是预先使用JSON定义好函数名称和入参,然后让GPT去解析用户的自然语言输入找到对应的预先定义的函数,然后解析自然语言并返回对应函数的入参。这就是GPT帮我们做的事情。整个函数调用的流程:
1、用户发起提问时,调用一次带有函数描述的completions接口,gpt会判断是否支持调用函数,如果可以就从用户的提问信息中提取出函数所需要的参数。
2、开发者拿到gpt提取出来的参数后自行调用函数并返回结果
3、将函数的返回结果再次发给GPT做总结归纳为自然语言

需要注意的地方:
1、整个过程gpt会执行两次,第一次调用从问题中提取函数参数,第二次对函数返回结果做归纳总结
2、函数调用并不是由gpt调用,而是开发者来调用
例子 :利用ChatGPT的函数调用功能实现:实时查询天气 - FooFish
四、易混淆词汇
JSON Mode、函数调用、assist API、GPTs。
1、JSON Mode
主要就是JSON格式,GPT-4 能够更加严格的输出JSON个数的数据,这个是后面所有能力(函数调用、assist API、GPTs)的前提条件。并且GPT-4也可以使用JSON更加简洁的作为输入。
注意:
*尽量显示提示模型要JSON格式输出,可以在system中写。
*输出也不一定是有效的JSON格式。
2、函数调用
参考上面函数调用部分,函数调用的输入输出均为JSON格式。
3、assist API
主要是面向使用API接口的开发者,在缘由API基础上,重新封装一层,目的是帮助开发者维护上下文环境。但是现在的assitent api 并没有完全支持所有的原生API。
4、GPTs
让用户能通过自定义指令、拓展(模型)的知识边界和下达行动命令,来构建自己的GPT,并能对外发布给全球更多的人使用。这个可以理解为最最上层的应用。
五、GPT-4v
推测2022年训练完毕,2023年3月与Be My Eyes和OpenAI合作开发了Be My AI,这是一种新工具,用于为盲人或视力低下的人描述视觉世界。2023年9月微软发布一个长达160+页的测试报告。
六、DALLE 3
参考:文生图——DALL-E 3 —论文解读——第一版
参考链接
128K上下文遗忘问题:GPT4 Turbo的128K上下文是鸡肋?推特大佬斥巨资评测,斯坦福论文力证结论
代码解释器官方文档:https://platform.openai.com/docs/assistants/tools/code-interpreter
代码解释器使用:https://www.youtube.com/watch?v=JX1CpF4ndrw
代码解释器常用功能:Notion – The all-in-one workspace for your notes, tasks, wikis, and databases.
发布会导读:短短 45 分钟发布会,OpenAI 如何再次让 AI 圈一夜未眠
GPTs创建流程: 一文读懂GPTs的构建与玩法(GPTs保姆级教程)|【WeThinkIn出品】
GPTs 纯 prompt 例子: 热乎的GPTs体验报告:创建专属GPT,不懂代码人的春天来了
GPTs + Zapier + action 例子:https://www.youtube.com/watch?v=29XCaqMbAro
GPTs + Zapier + action 例子(天气预报):ChatGPT之GPTs的使用与分析:5分钟构建一个天气画报 - 知乎
GPTs + Zapier + action 例子2(天气预报):https://twitter.com/dotey/status/1724305358254952799
函数调用例子:利用ChatGPT的函数调用功能实现:实时查询天气 - FooFish
Zapier 官方例子:Get Started - Zapier AI Actions
GPT-4v微软测试报告: 微软最新166页测评报告:视觉模态GPT-4V到底有多强? 必看:微软166页论文解读 GPT-4V 全文翻译《多模态的新时代》The Dawn of LMMs: Preliminary Explorations with GPT-4V(ision) - 知乎
Gpt-4v连续识别图片(视频解读): 解说梅西球赛、英雄联盟,OpenAI GPT-4视觉API被开发者玩出新花样
GPT-4v 识别视频方案:微软用GPT-4V解读视频,看懂电影还能讲给盲人听,1小时不是问题
ChatGPT prompt资料:Notion – The all-in-one workspace for your notes, tasks, wikis, and databases.