RAM(recognize anything)—— 论文详解
一、概述
1、是什么
RAM 论文全称 Recognize Anything: A Strong Image Tagging Model。区别于图像领域常见的分类、检测、分割,他是标记任务——即多标签分类任务(一张图片命中一个类别),区分于分类(一张图片命中一个类别)。然后他这里提到的anything,需要注意,模型本身原始支持6449个标签(去掉同义词后4585个标签),但是可以通过后面提到的一些方法实现未知的标签(6449以外)识别。
如下是原生支持的6449个标签(去掉同义词后4585个标签)的官方地址,需要注意其中英文和中文是一一对应的,都是4585组。
原生支持的中文标签:https://github.com/xinyu1205/recognize-anything/blob/main/ram/data/ram_tag_list_chinese.txt
原生支持的英文标签:https://github.com/xinyu1205/recognize-anything/blob/main/ram/data/ram_tag_list.txt
2、亮点
1)强大的图片标记能力和zero-shot泛化识别能力;
2)可较低成本复现,使用的都是开源和免人工标记的数据集,最强版本的RAM也只需要8卡A100训练3天;
3)灵活并且可以满足各种应用场景:可以单独使用作为标记系统;也可以结合Grounding DINO 和SAM 多标签分割。
3、对比Tag2Text的提升
准确性更高。RAM利用数据引擎生成额外的注释并清除不正确的标记,与Tag2Text相比具有更高的准确性。(详见后面的数据处理部分。)
标记类别数更多。RAM将固定标签的数量从3,400个升级到6,400个(同义减少到4,500个不同的语义标签),涵盖了更有价值的类别。此外,RAM具有开集能力,可以识别训练中未看到的标签。
PS
这篇来自OPPO的论文,写的相对真的很详细,有任何细节疑问可以参考论文,论文中不含的细节也在本博客末尾写到作为后续待解决项。
二、模型
1、模型结构
PS:关于模型,由于官方没有释放训练的代码,对比推理代码和论文,也发现了有不一致的地方(后面描述),所以这里只是描述目前能看到的和推测到的,不一定准确。
论文中提到,SAM 只保留了(Tag2Text )的 Tagging 和 Generation 两个:
*主干的image Encoder 使用了swin-transformer, 有两个版本,swin-b 和 swin-l ;
*Tagging 分支用来多tags推理,完成识别任务;使用的是BIRT(代码里是BIRT,论文里说是2 层的transformer);
*Generation分支用来做 image caption任务encoder-decoder使用的是12 层的transformer。
*Alignment 分支是做 Visual-Language Features学习的,在这里被移除了。
*这里还涉及两个离线模型:一个是CLIP(又涉及到image encoder 和 Text encoder,后面介绍),一个是SceneGraphParser (OPPO 官方修改过)。
2、训练过程
PS:这里抛开数据处理过程的训练细节,主要将住进程;这里的更多细节目前官方并未开源,所以也只能大概。
注意:
1)训练过程没有上图右侧的CLIP Text Encoder。N个类别对应N个textual label queries——也就是可学习的参数,假设论文4585个类,每个类768维度表示,那么就是4585*768。
2)训练输入是三个元素:图片-Tag-文本构成,对应网络的一个输入(图像,文本输入不算,是网络自己的可学习参数)+ 2个输出(文本描述和多标签分类)。损失也就是常见的文本生成损失+多标签ASL损失。
3)image-Tag-interaction encoder 的文本输入是label 解析的Tag,不是模型的输出(推理时是模型的输出)
4)训练过程的某个节点(论文没有详细说)使用了CLIP image encoder 的输出进行蒸馏(distill)RAM 自己的image encoder。(这个我的理解是潜在对齐了CLIP Text encoder ,才更好的实现了后面推理阶段的open set 的识别。)
3、推理过程
分为两种,第一种就是模型本身支持的类别的推理;第二种是模型不支持(当然支持的类别也可以使用这种方式)的open set 的推理。推理过程是开源了的。
第一种,模型支持的类别。
* 这里不需要文本输入,只需要输入图片即可。
* 对应的代码为:https://github.com/xinyu1205/recognize-anything/blob/main/inference_ram.py
* 需要先查看是否有自己的类目,
中文:https://github.com/xinyu1205/recognize-anything/blob/main/ram/data/ram_tag_list_chinese.txt
英文:https://github.com/xinyu1205/recognize-anything/blob/main/ram/data/ram_tag_list.txt
对应的阈值:https://github.com/xinyu1205/recognize-anything/blob/main/ram/data/ram_tag_list_threshold.txt
* 当前版本231020,如果大量调用建议修改源代码,因为会重复的读取模型权重:https://github.com/xinyu1205/recognize-anything/blob/main/ram/models/ram.py#L170
第二种,模型不支持的类别(open set)。
* 这里需要提前输入自己想要的类别+图片。自己想要的类别参考这个进行填充:https://github.com/xinyu1205/recognize-anything/blob/main/ram/utils/openset_utils.py#L91
* 原理:这里其实是模型里的queries 可学习输入给换掉了,换成了CLIP 的编码。CLIP 的编码方式是使用了一组模板:https://github.com/xinyu1205/recognize-anything/blob/main/ram/utils/openset_utils.py#L24 把自己想要的单词编码成了句子,然后离线的算出每个模板的CLIP Text encoder 的输出特征向量,然后进行求平均来当做这个单词的特征表示,然后其他地方不变得到这个类别的得分。这里说一下另一点就是在训练过程中作者也特别实用了CLIP 的image encoder 进行蒸馏 RAM 的image encoder ,这其实相当于为这里的open set 使用CLIP Text encoder 作了文本和图片的特征对齐,作者的实验也显示提高了模型的性能。
4、消融经验
1)两个分支训练提升了模型的Tag分之的能力。
2)开发集合识别主要依靠CLIP,并没有提升闭集的能力(???跟训练本来就无关啊)
3)提升标签的类别对已有类影响较小(有影响,因为提升了训练难度),但是可以提升开放识别的能力,增强了模型的覆盖范围。
三、数据
1、数据标签
参考来源:
1)开源的学术数据集(分类、检测、分割)。
2)商业已有的API(谷歌、微软、苹果)
指导原则:
1)高频出现,代表更有价值。
2)标签包括:对象、场景、属性、动作(行为),这提升了模型的泛化能力(复杂、未知场景)。
3)标签的数量需要适中,过多会导致严重的标注成本。
数量:
1)使用修改后的SceneGraph-Parser 解析1400W预训练句子。
2)手工从top-1W 高频Tag 中选取6449个Tag。
3)通过多种手段(手工检查、参考WordNet、翻译等)合并同义词汇到同一个ID,最后变为4585个Tag。
PS:RAM 覆盖 OpenImages 和 ImageNet 较少,原因是里面很多Tag比较不常见,比如ImageNet 很多鸟的细类。

2、数据构成
一共两个版本的数据4 Millon和14 Millon,分别对应训练了两个参数量的模型swin-b和swin-l。
1)4M:2个人工标注数据集,COCO(113K 图像、557K 描述)、Visual Genome(101K 图像、822K 描述);2个大规模互联网数据集 Conceptual Captions (3M 图像, 3M 描述) and SBU
Captions (849K 图像, 849K 描述)。
2)14M:4M 基础上增加 Conceptual 12M (10M 图像, 10M 描述)
3、数据清洗
原因:来自网络的图像文本对本质上是嘈杂的,通常包含缺失或不正确的标签。为了提高注释的质量,我们设计了一个标记数据引擎。
解决丢失的标签。使用一部分数据训练一个base model,然后使用这个model将剩余数据进行打标,然后混合原始标注和生成的标注进行扩充,本文4M image 的tag 12M -> 39.8M。
解决多余的标签。我们首先使用Grounding-Dino定位与图像中不同标签对应的特定区域,随后:
1)我们采用区域聚类技术( K-Means++)来识别和消除同一类中的异常值(最外部的10%)(使用的特征来源和聚类数未做说明);
2)我们过滤掉在整个图像及其相应区域之间表现出相反预测的标签(使用base model 对裁切区域进行推理,如果没有预测出对应的tag 进行删除)(整图有的标签、裁切区域更应该被识别到),确保更清晰和更准确的注释。
预估平均一个tag 也有1W图片。
4、消融结果
1)在12.0M到41.7M范围内添加更多的标签,可以显著提高所有测试集的模型性能,说明原始数据集存在严重的标签缺失问题。
2)进一步清理某些类别的标签会导致OPPO-common和OpenImages-common测试集上的性能略有提高。受GroundingDino推理速度的限制,我们只对534个类别进行清洗处理。
3)将训练图像从4M扩展到14M,在所有测试集上都有显著的改进。
4)使用更大的骨干网络会导致openimages的性能略有改善——在常见类别上的性能很少甚至略差。我们将这种现象归因于我们进行超参数搜索的可用资源不足。
5)对从COCO Caption数据集解析的标签进行微调,在OPPO-common和7OpenImages-common测试集上显示出显著的性能提高。(COCOCaption数据集为每个图像提供了五个描述性句子,提供了一个全面的描述,近似于一组完整的标签标签。)
四、策略
1、训练过程
参考数据清洗流程,整个训练过程如下
1)通过自动文本语义解析在大规模数据上获得无标注的图像标签。
2)使用原始文本和解析后的标记训练第一版模型。
3)一个数据引擎用于生成额外的注释和清理不正确的(参考数据清洗小结)。
4)使用更小但更高质量的数据集处理数据并进行模型微调。
五、结果
1、多维度对比。
对比分割模型SAM,标记模型Tag2Text等,多模态模型CLIP、BLIP等,主要从定位能力和识别精度和类别数上如下

2、标记能力对比。
RAM提供更精确(精度)、更多(召回&覆盖范围)的结果。
*RAM展示了令人印象深刻的zero-shot性能,明显优于CLIP和BLIP。
*RAM甚至超过了完全监督的方式(ML-Decoder)。
*RAM表现出与Google标签API相当的性能。

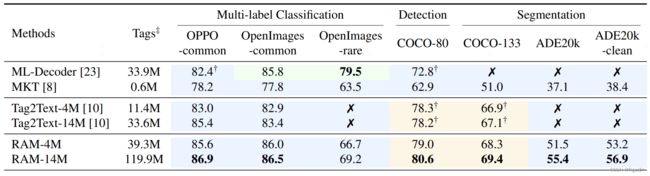
3、测试集对比
六、使用方法
TRANSFORMERS_OFFLINE=1 python inference_ram.py --image images/1641173_2291260800.jpg --pretrained pretrained/ram_swin_large_14m.pth
七、待解决
1、聚类的内容是什么?图像特征?
2、训练代码,描述分支网络的结果。
八、参考链接
GitHub - xinyu1205/recognize-anything: Code for the Recognize Anything Model (RAM) and Tag2Text Model
Recognize Anything: A Strong Image Tagging Model
识别一切模型RAM(Recognize Anything Model)及其前身 Tag2Text 论文解读 - 知乎
https://arxiv.org/pdf/2306.03514.pdf
https://github.com/xinyu1205/recognize-anything/blob/main/ram/utils/openset_utils.py#L293
ASL: 多标签分类之非对称损失-Asymmetric Loss_asl loss-CSDN博客