用户新增预测挑战赛学习笔记(讯飞)
用户新增预测挑战赛:
2023 iFLYTEK A.I.开发者大赛-讯飞开放平台
举办方:科大讯飞
一、赛事背景
讯飞开放平台针对不同行业、不同场景提供相应的AI能力和解决方案,赋能开发者的产品和应用,帮助开发者通过AI解决相关实际问题,实现让产品能听会说、能看会认、能理解会思考。
用户新增预测是分析用户使用场景以及预测用户增长情况的关键步骤,有助于进行后续产品和应用的迭代升级。
二、赛事任务
本次大赛提供了讯飞开放平台海量的应用数据作为训练样本,参赛选手需要基于提供的样本构建模型,预测用户的新增情况。
三、数据说明
赛题数据由约62万条训练集、20万条测试集数据组成,共包含13个字段。其中uuid为样本唯一标识,eid为访问行为ID,udmap为行为属性,其中的key1到key9表示不同的行为属性,如项目名、项目id等相关字段,common_ts为应用访问记录发生时间(毫秒时间戳),其余字段x1至x8为用户相关的属性,为匿名处理字段。target字段为预测目标,即是否为新增用户。本次竞赛的评价标准采用f1_score,分数越高,效果越好。
四、实践流程
本次学习通过Datawhale学习平台进行,并在平台给出的baseline上进一步操作。
1.数据预处理


train_data.describe(include='all')
数据预处理主要包括缺失值、异常值处理和内存优化等。
1.1缺失值处理
- 对于类别特征:可以选择最常见的一类填充方法,即填充众数;或者直接填充一个新类别,比如0、-1、负无穷。
- 对于数值特征:可以填充平均数、中位数、众数、最大值、最小值等。具体选择哪种统计值,需要具体问题具体分析。
- 对于有序数据(比如时间序列):可以填充相邻值 next 或者 previous 。
- 模型预测填充:普通的填充只是一个结果的常态,并未考虑其他特征之间相互作用的影响,可以对含有缺失值的那一列进行建模并预测其中缺失值的结果。虽然这种方法比较复杂,但是最后得到的结果直觉上比直接填充要好,不过在实际竞赛中的效果则需要具体检验。
本次的数据不存在缺失值,因此暂时无需进行缺失值的处理。
1.2异常值处理
- 删除含有异常值的记录。这种办法的优点是可以消除含有异常值的样本带来的不确定性,缺点是减少了样本量。
- 视为缺失值。将异常值视为缺失值,利用缺失值处理的方法进行处理。这种办法的优点是将异常值集中化为一类,增加了数据的可用性;缺点是将异常值和缺失值混为一谈,会影响数据的准确性。
- 平均值(中位数)修正。可用对应同类别的数值使用平均值修正该异常值,优缺点同"视为缺失值"。
- 不处理。直接在具有异常值的数据集上进行数据挖掘。这种办法的效果好坏取决于异常值的来源,若异常值是录入错误造成的,则对数据挖掘的效果会产生负面影响;若异常值只是对真实情况的记录,则直接进行数据挖掘能够保留最真实可信的信息。
1.3内存优化:
当使用 pandas 操作小规模数据(低于 100 MB)时,性能一般不是问题。而当面对更大规模的数据(100 MB 到数 GB)时,性能问题会让运行时间变得更漫长,而且会因为内存不足导致运行完全失败。本次的数据集在经过后续的特征工程之后,内存占有量很大,需要对数据进行内存优化以提升运行速度和模型性能。
下面是本次学习中通过数值类型优化来降低数据内存的代码:
train_int = train_data.select_dtypes(include=['int'])
converted_int = train_int.apply(pd.to_numeric,downcast='unsigned')
train_float = train_data.select_dtypes(include=['float'])
converted_float = train_float.apply(pd.to_numeric,downcast='float')
optimized_train = train_data.copy()
optimized_train[converted_int.columns] = converted_int
optimized_train[converted_float.columns] = converted_float该代码使用函数 pd.to_numeric() 来对数值类型进行 downcast(向下转型)操作,使用 DataFrame.select_dtypes 来选择整型列,然后对其数据类型进行优化。
2.特征变换
2.1非数值变量处理
原数据中udmap特征为字典形式,udmap为行为属性,其中的key1到key9表示不同的行为属性,如项目名、项目id等相关字段,将其处理为9列特征向量,表示每个key是否存在。再对 udmap 特征进行编码,生成 udmap_isunknown 特征,表示该特征是否为空。将处理后的 udmap 特征与原始数据拼接起来,形成新的数据框。代码实现如下:
# 定义函数 udmap_onethot,用于将 'udmap' 列进行 One-Hot 编码
def udmap_onethot(d):
v = np.zeros(9) # 创建一个长度为 9 的零数组
if d == 'unknown': # 如果 'udmap' 的值是 'unknown'
return v # 返回零数组
d = eval(d) # 将 'udmap' 的值解析为一个字典
for i in range(1, 10): # 遍历 'key1' 到 'key9', 注意, 这里不包括10本身
if 'key' + str(i) in d: # 如果当前键存在于字典中
v[i-1] = d['key' + str(i)] # 将字典中的值存储在对应的索引位置上
return v # 返回 One-Hot 编码后的数组
# 使用 apply() 方法将 udmap_onethot 函数应用于每个样本的 'udmap' 列
# np.vstack() 用于将结果堆叠成一个数组
train_udmap_df = pd.DataFrame(np.vstack(train_data['udmap'].apply(udmap_onethot)))
test_udmap_df = pd.DataFrame(np.vstack(test_data['udmap'].apply(udmap_onethot)))
# 为新的特征 DataFrame 命名列名
train_udmap_df.columns = ['key' + str(i) for i in range(1, 10)]
test_udmap_df.columns = ['key' + str(i) for i in range(1, 10)]
# 将编码后的 udmap 特征与原始数据进行拼接,沿着列方向拼接
train_data = pd.concat([train_data, train_udmap_df], axis=1)
test_data = pd.concat([test_data, test_udmap_df], axis=1)
# 使用比较运算符将每个样本的 'udmap' 列与字符串 'unknown' 进行比较,返回一个布尔值的 Series
# 使用 astype(int) 将布尔值转换为整数(0 或 1),以便进行后续的数值计算和分析
train_data['udmap_isunknown'] = (train_data['udmap'] == 'unknown').astype(int)
test_data['udmap_isunknown'] = (test_data['udmap'] == 'unknown').astype(int)对于时间戳 common_ts ,对其提取分钟、小时、一天中的时间段、一月中的哪天、星期数、是否为周末等特征,充分提取时间信息生成新的特征,
# 提取时间戳
train_data['common_ts'] = pd.to_datetime(train_data['common_ts'], unit='ms')
test_data['common_ts'] = pd.to_datetime(test_data['common_ts'], unit='ms')
train_data['minute'] = train_data['common_ts'].dt.minute
test_data['minute'] = test_data['common_ts'].dt.minute
train_data['hour'] = train_data['common_ts'].dt.hour
test_data['hour'] = test_data['common_ts'].dt.hour
def encode_time_period(time):
hour = time.hour
if 2 <= hour < 5:
return 1 # 凌晨
elif 5 <= hour < 8:
return 2 # 早上
elif 8 <= hour < 12:
return 3 # 上午
elif 12 <= hour < 14:
return 4 # 中午
elif 14 <= hour < 18:
return 5 # 下午
elif 18 <= hour < 22:
return 6 # 晚上
else:
return 7 # 深夜
train_data['period'] = train_data['common_ts'].apply(encode_time_period)
test_data['period'] = test_data['common_ts'].apply(encode_time_period)
train_data['day'] = train_data['common_ts'].dt.day
test_data['day'] = test_data['common_ts'].dt.day
train_data['weekday'] = train_data['common_ts'].dt.weekday
test_data['weekday'] = test_data['common_ts'].dt.weekday
train_data['weekend'] = train_data['common_ts'].apply(lambda x: 1 if x.dayofweek in [5, 6] else 0)
test_data['weekend'] = test_data['common_ts'].apply(lambda x: 1 if x.dayofweek in [5, 6] else 0)
2.2连续变量无量纲化
标准化:特征值须符合正态分布,标准化后,特征值服从标准正态分布。最简单的转换为零-均值规范化。
区间缩放:将特征的取值区间缩放到某个特定的范围,如[0,1]。
单特征转换是构建线性回归、KNN、神经网络等模型的关键,对决策树等模型没有影响,最后我打算采用随机森林、XGBoost、Lightbgm、CatBoost等模型进行训练预测,因为未进行该部分的处理。
2.3连续变量离散化
离散化后的特征对异常数据有很强的健壮性,更便于探索数据的相关性。在这里我们使用有监督的离散化,并使用谢士晨博士开发的scorecardpy库进行处理,
scorecardpy库是Python中信贷评分卡中常用的库,该软件包是R软件包评分卡的python版本。它的目标是通过提供一些常见任务的功能,使传统信用风险计分卡模型的开发更加轻松有效。该包的功能及对应的函数如下:
- 数据划分(split_df)
- 过滤变量(var_filter())
- 决策树分箱(woebin, woebin_plot, woebin_adj, woebin_ply)
- 评分转换(scorecard, scorecard_ply)
- 模型评估(perf_eva, perf_psi)
参考链接:
逻辑回归:基于Scorecardpy库的German Credit 风控评分卡模型 - 知乎
评分卡建模工具scorecardpy全解读 - 知乎
GitHub - ShichenXie/scorecardpy: Scorecard Development in python, 评分卡
本次学习中我们使用库中的决策树分箱方法并结合sklearn库中的决策树模型来对部分连续性变量进行分箱处理。
from sklearn import tree
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import cross_val_score
dtree = DecisionTreeClassifier(max_depth=2)
dtree.fit(train_data[['key1']],train_data[['target']])
train_data['key1_bin'] = dtree.predict_proba(train_data.key1.to_frame())[:,1].round(4)
test_data['key1_bin'] = dtree.predict_proba(test_data.key1.to_frame())[:,1].round(4)
dtree = DecisionTreeClassifier(max_depth=2)
dtree.fit(train_data[['key6']],train_data[['target']])
train_data['key6_bin'] = dtree.predict_proba(train_data.key6.to_frame())[:,1].round(4)
test_data['key6_bin'] = dtree.predict_proba(test_data.key6.to_frame())[:,1].round(4)
dtree = DecisionTreeClassifier(max_depth=4)
dtree.fit(train_data[['x3']],train_data[['target']])
train_data['x3_bin'] = dtree.predict_proba(train_data.x3.to_frame())[:,1].round(4)
test_data['x3_bin'] = dtree.predict_proba(test_data.x3.to_frame())[:,1].round(4)
import scorecardpy as sc
bins = sc.woebin(train_data[[
'x4', 'x5', 'key2', 'key3', 'key4',
'key5', 'minute', 'hour', 'period', 'day', 'weekday', 'target'
]],
y='target')
train_data[[
'x4_bin', 'x5_bin',
'key2_bin', 'key3_bin', 'key4_bin', 'key5_bin', 'minute_bin', 'hour_bin','period_bin',
'day_bin', 'weekday_bin'
]] = sc.woebin_ply(
train_data[[
'x4', 'x5', 'key2', 'key3',
'key4', 'key5', 'minute', 'hour', 'period', 'day', 'weekday'
]], bins)
test_data[[
'x4_bin', 'x5_bin',
'key2_bin', 'key3_bin', 'key4_bin', 'key5_bin', 'minute_bin', 'hour_bin','period_bin',
'day_bin', 'weekday_bin'
]] = sc.woebin_ply(
test_data[[
'x4', 'x5', 'key2', 'key3',
'key4', 'key5', 'minute', 'hour', 'period', 'day', 'weekday'
]], bins)




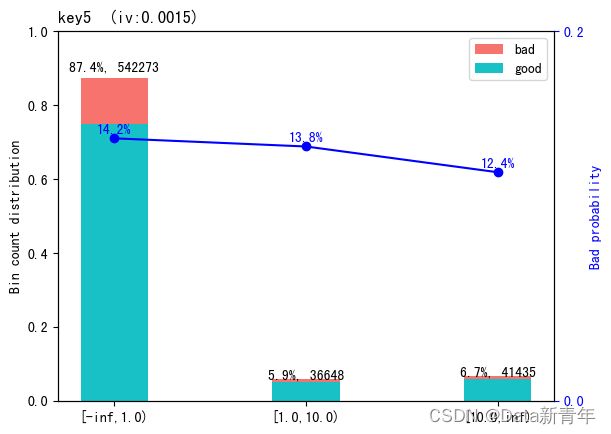
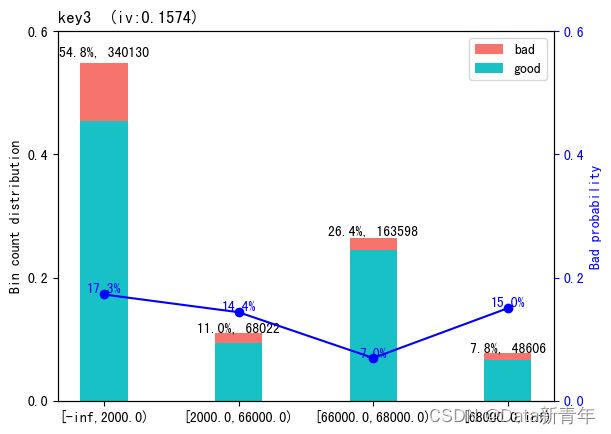




eid为访问行为ID,应为离散型变量,可以提取eid特征的频次(出现次数)和目标均值,并添加为新的特征。在使用目标变量时,非常重要的一点是不能泄露任何验证集的信息。所有基于目标编码的特征都应该在训练集上计算,接着仅仅合并或连接验证集和测试集。即使验证集中有目标变量,它不能用于任何编码计算,否则会给出过于乐观的验证误差估计。
# 提取 eid 的频次特征
# 使用 map() 方法将每个样本的 eid 映射到训练数据中 eid 的频次计数
# train_data['eid'].value_counts() 返回每个 eid 出现的频次计数
train_data['eid_freq'] = train_data['eid'].map(train_data['eid'].value_counts())
test_data['eid_freq'] = test_data['eid'].map(train_data['eid'].value_counts())# 提取 eid 的标签特征
# 使用 groupby() 方法按照 eid 进行分组,然后计算每个 eid 分组的目标值均值
# train_data.groupby('eid')['target'].mean() 返回每个 eid 分组的目标值均值
train_data['eid_mean'] = train_data['eid'].map(train_data.groupby('eid')['target'].mean())
# 继续使用训练集的信息来对测试集进行编码
test_data['eid_mean'] = test_data['eid'].map(train_data.groupby('eid')['target'].mean())