计算机视觉:使用opencv实现车牌识别
1 引言
汽车车牌识别(License Plate Recognition)是一个日常生活中的普遍应用,特别是在智能交通系统中,汽车牌照识别发挥了巨大的作用。汽车牌照的自动识别技术是把处理图像的方法与计算机的软件技术相连接在一起,以准确识别出车牌牌照的字符为目的,将识别出的数据传送至交通实时管理系统,以最终实现交通监管的功能。在车牌自动识别系统中,从汽车图像的获取到车牌字符处理是一个复杂的过程,主要分为四个阶段:图像获取、车牌定位、字符分割以及字符识别。目前关于车牌识别的算法有很多,本文基于opencv构建了车牌识别的整个流程,供大家学习参考。
1 车牌识别概述
1.1 opencv介绍
OpenCV的全称是:Open Source Computer Vision Library。OpenCV是一个基于开源发行的跨平台计算机视觉库,可以运行在Linux、Windows和Mac OS操作系统上。它轻量级而且高效——由一系列 C 函数和少量 C++ 类构成,同时提供了Python、Ruby、MATLAB等语言的接口,实现了图像处理和计算机视觉方面的很多通用算法。
1.2 车牌识别分解
车牌辨认的整个过程,可以拆解为以下三个步骤:
- 车牌定位: 第一步是从轿车上检测车牌地点方位。本文将运用OpenCV中矩形的边框检测来找到车牌位置。
- 字符切割:检测到车牌后,使用opencv将其裁剪并保存为新的图片,用于后续识别。
- 字符辨认: 在新的图片运用光学字符识(OCR)技术,提取图片中的文字、字符、数字。
2 车牌识别的实现
2.1 车牌定位
我国的汽车牌照一般由七个字符和一个点组成,车牌字符的高度和宽度是固定的,分别为90mm和45mm,七个字符之间的距离也是固定的12mm,点分割符的直径是10mm,字符间的差异可能会引起字符间的距离变化。
在民用车牌中,字符的排列位置遵循以下规律:
- 第一个字符通常是我国各省区的简称,用汉字表示;
- 第二个字符通常是发证机关的代码号,最后五个字符由英文字母和数字组合而成,字母是二十四个大写字母(除去I和O这两个字母)的组合,数字用"0-9"之间的数字表示。
从图像处理角度看,汽车牌照有以下几个特征:
- 第一个特征是是车牌的几何特征,即车牌形状统一为长宽高固定的矩形;
- 第二个特征是车牌的灰度分布呈现出连续的波谷-波峰-波谷分布,这是因为我国车牌颜色单一,字符直线排列;
- 第三个特征是车牌直方图呈现出双峰状的特点,即车牌直方图中可以看到双个波峰;
- 第四个特征是车牌具有强边缘信息,这是因为车牌的字符相对集中在车牌的中心,而车牌边缘无字符,因此车牌的边缘信息感较强;
- 第五个特征是车牌的字符颜色和车牌背景颜色对比鲜明。目前,我国国内的车牌大致可分为蓝底白字和黄底黑字,特殊用车采用白底黑字或黑底白字,有时辅以红色字体等。
为了简化处理,本次学习中只考虑蓝底白字的车牌。

2.1.1 图像加载与灰度化
import cv2
img = cv2.imread('../data/bmw01.jpg')
# 调整图片大小
img = cv2.resize(img, (1024, 800))
# 灰度图
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 显示效果
cv2.imshow('gray', gray)
cv2.waitKey(0)
cv2.destroyAllWindows()显示结果如下:
2.1.2 双边滤波去除噪声
# 双边滤波
blf = cv2.bilateralFilter(gray, 13, 15, 15)
show_image('bilateralFilter', blf)显示结果如下:
2.1.3 边缘检测
# 边缘检测
edged = cv2.Canny(blf, 30, 200)
show_image('canny', edged)显示结果如下:

2.1.4 寻找车牌轮廓(四边形)
cv2.findContours说明:
- opencv3.x
image, contours, hierarchy = cv.findContours(image, mode, method[, contours[, hierarchy[, offset]]])- opencv2.x和4.x
contours, hierarchy = cv.findContours(image, mode, method[, contours[, hierarchy[, offset]]])OpenCV中HSV空间颜色对照表
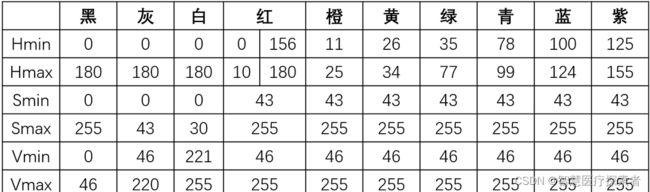
提取图像区域的颜色
def reg_area_color(image):
"""找到原图像最多的颜色,当该颜色为红色或蓝色时返回该颜色的名称"""
kernel = np.ones((35, 35), np.uint8)
hsv = cv2.cvtColor(image, cv2.COLOR_BGR2HSV)
# 以上为图像处理
Open = cv2.morphologyEx(hsv, cv2.MORPH_OPEN, kernel)
# 对Open图像的H通道进行直方图统计
hist = cv2.calcHist([Open], [0], None, [180], [0, 180])
# 找到直方图hist中列方向最大的点hist_max
hist_max = np.where(hist == np.max(hist))
# hist_max[0]为hist_max的行方向的值,即H的值,H在0~10为红色
if 0 < hist_max[0] < 10:
res_color = 'red'
elif 100 < hist_max[0] < 124: # H在100~124为蓝色
res_color = 'blue'
else:
# H不在前两者之间跳出函数
res_color = 'unknow'
return res_color寻找车牌轮廓:
# 寻找轮廓(图像矩阵,输出模式,近似方法)
contours, _ = cv2.findContours(edged.copy(), cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
# 根据区域大小排序取前十
contours = sorted(contours, key=cv2.contourArea, reverse=True)[:10]
screenCnt = None
# 遍历轮廓,找到车牌轮廓
for c in contours:
if cv2.contourArea(c) > 1024 * 768 * 0.05:
continue
# 计算轮廓周长(轮廓,是否闭合)
peri = cv2.arcLength(c, True)
# 折线化(轮廓,阈值(越小越接近曲线),是否闭合)返回折线顶点坐标
approx = cv2.approxPolyDP(c, 0.018 * peri, True)
# 获取四个顶点(即四边形, 左下/右下/右上/左上
if len(approx) == 4:
# [参数]左上角纵坐标:左下角纵坐标,左上角横坐标:右上角横坐标
crop_image = img[approx[3][0][1]:approx[0][0][1], approx[3][0][0]:approx[2][0][0]]
show_image('crop', crop_image)
if 'blue' == reg_area_color(crop_image):
screenCnt = approx
break
# 如果找到了四边形
if screenCnt is not None:
# 根据四个顶点坐标对img画线(图像矩阵,轮廓坐标集,轮廓索引,颜色,线条粗细)
cv2.drawContours(img, [screenCnt], -1, (0, 0, 255), 3)
show_image('contour', img)运行结果显示:
2.1.5 图像位运算进行遮罩
"""遮罩"""
# 创建一个灰度图一样大小的图像矩阵
mask = np.zeros(gray.shape, np.uint8)
# 将创建的图像矩阵的车牌区域画成白色
cv2.drawContours(mask, [screenCnt], 0, 255, -1, )
# 图像位运算进行遮罩
mask_image = cv2.bitwise_and(img, img, mask=mask)
show_image('mask_image', mask_image)运行结果显示:

2.1.6 图像剪裁
"""图像剪裁"""
# 获取车牌区域的所有坐标点
(x, y) = np.where(mask == 255)
# 获取底部顶点坐标
(topx, topy) = (np.min(x), np.min(y))
# 获取底部坐标
(bottomx, bottomy,) = (np.max(x), np.max(y))
# 剪裁
Cropped = gray[topx:bottomx, topy:bottomy]运行结果显示:

2.1.7 OCR字符识别
paddleocr是一款轻量型字符识别工具库,支持多语言识别,支持pip安装与自定义训练。
- conda下工具类安装
pip install paddleocr -i https://mirror.baidu.com/pypi/simple
pip install paddlepaddle -i https://mirror.baidu.com/pypi/simple
代码实现:
"""OCR识别"""
# 使用CPU预加载,不用GPU
ocr = PaddleOCR(use_angle_cls=True, use_gpu=False, ocr_version='PP-OCRv3')
text = ocr.ocr(cropped, cls=True)
for t in text:
print(t[0][1])运行结果显示如下:
[2023/11/15 20:57:43] ppocr DEBUG: dt_boxes num : 1, elapsed : 0.016942501068115234
[2023/11/15 20:57:43] ppocr DEBUG: cls num : 1, elapsed : 0.013955354690551758
[2023/11/15 20:57:43] ppocr DEBUG: rec_res num : 1, elapsed : 0.12021970748901367
('苏A·0MR20', 0.8559348583221436)2.2 完整代码实现
import cv2
import numpy as np
from paddleocr import PaddleOCR
def show_image(desc, image):
cv2.imshow(desc, image)
cv2.waitKey(0)
cv2.destroyAllWindows()
def reg_area_color(image):
"""找到原图像最多的颜色,当该颜色为红色或蓝色时返回该颜色的名称"""
kernel = np.ones((35, 35), np.uint8)
hsv = cv2.cvtColor(image, cv2.COLOR_BGR2HSV)
# 以上为图像处理
Open = cv2.morphologyEx(hsv, cv2.MORPH_OPEN, kernel)
# 对Open图像的H通道进行直方图统计
hist = cv2.calcHist([Open], [0], None, [180], [0, 180])
# 找到直方图hist中列方向最大的点hist_max
hist_max = np.where(hist == np.max(hist))
# hist_max[0]为hist_max的行方向的值,即H的值,H在0~10为红色
if 0 < hist_max[0] < 10:
res_color = 'red'
elif 100 < hist_max[0] < 124: # H在100~124为蓝色
res_color = 'blue'
else:
# H不在前两者之间跳出函数
res_color = 'unknow'
return res_color
img = cv2.imread('../data/bmw01.jpg')
# 调整图片大小
img = cv2.resize(img, (1024, 768))
# 灰度图
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
show_image('gray', gray)
# 双边滤波
blf = cv2.bilateralFilter(gray, 13, 15, 15)
show_image('bilateralFilter', blf)
# 边缘检测
edged = cv2.Canny(blf, 30, 200)
show_image('canny', edged)
# 寻找轮廓(图像矩阵,输出模式,近似方法)
contours, _ = cv2.findContours(edged.copy(), cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
# 根据区域大小排序取前十
contours = sorted(contours, key=cv2.contourArea, reverse=True)[:10]
screenCnt = None
# 遍历轮廓,找到车牌轮廓
for c in contours:
if cv2.contourArea(c) > 1024 * 768 * 0.05:
continue
# 计算轮廓周长(轮廓,是否闭合)
peri = cv2.arcLength(c, True)
# 折线化(轮廓,阈值(越小越接近曲线),是否闭合)返回折线顶点坐标
approx = cv2.approxPolyDP(c, 0.018 * peri, True)
# 获取四个顶点(即四边形, 左下/右下/右上/左上
if len(approx) == 4:
# [参数]左上角纵坐标:左下角纵坐标,左上角横坐标:右上角横坐标
crop_image = img[approx[3][0][1]:approx[0][0][1], approx[3][0][0]:approx[2][0][0]]
show_image('crop', crop_image)
if 'blue' == reg_area_color(crop_image):
screenCnt = approx
break
# 如果找到了四边形
if screenCnt is not None:
# 根据四个顶点坐标对img画线(图像矩阵,轮廓坐标集,轮廓索引,颜色,线条粗细)
cv2.drawContours(img, [screenCnt], -1, (0, 0, 255), 3)
show_image('contour', img)
"""遮罩"""
# 创建一个灰度图一样大小的图像矩阵
mask = np.zeros(gray.shape, np.uint8)
# 将创建的图像矩阵的车牌区域画成白色
cv2.drawContours(mask, [screenCnt], 0, 255, -1, )
# 图像位运算进行遮罩
mask_image = cv2.bitwise_and(img, img, mask=mask)
show_image('mask_image', mask_image)
"""图像剪裁"""
# 获取车牌区域的所有坐标点
(x, y) = np.where(mask == 255)
# 获取底部顶点坐标
(topx, topy) = (np.min(x), np.min(y))
# 获取底部坐标
(bottomx, bottomy,) = (np.max(x), np.max(y))
# 剪裁
cropped = gray[topx:bottomx, topy:bottomy]
show_image('cropped', cropped)
"""OCR识别"""
# 使用CPU预加载,不用GPU
ocr = PaddleOCR(use_angle_cls=True, use_gpu=False, ocr_version='PP-OCRv3')
text = ocr.ocr(cropped, cls=True)
for t in text:
print(t[0][1])