高维矩阵相乘 及对应的numpy pytorch函数
矩阵相乘
一、向量的点乘和叉乘
在介绍矩阵的乘法之前,需要先回顾总结一下向量的点乘和叉乘(矩阵的点乘叉乘和向量是不一样的)
①向量点乘
向量的点乘(dot produce)又称为内积,等于对应位置相乘再相加,两个向量点乘(内积)的结果是一个标量
有两个向量 a ⃗ \vec{a} a 和 和 和 b ⃗ \vec{b} b, a ⃗ = ( x 1 , y 1 , z 1 ) \vec{a}=(x_1, y_1, z_1) a=(x1,y1,z1), b ⃗ = ( x 2 , y 2 , z 2 ) \vec{b}=(x_2, y_2, z_2) b=(x2,y2,z2)
a ⃗ ⋅ b ⃗ = x 1 x 2 + y 1 y 2 + z 1 z 2 \vec{a} \cdot \vec{b} = x_1x_2+y_1y_2+z_1z_2 a⋅b=x1x2+y1y2+z1z2
从几何角度看,点积是两个向量的长度与它们夹角余弦的积
a ⃗ ⋅ b ⃗ = ∣ a ⃗ ∣ ∣ b ⃗ ∣ c o s θ \vec{a} \cdot \vec{b} = |\vec{a}||\vec{b}|cos\theta a⋅b=∣a∣∣b∣cosθ
点乘的结果表示 a ⃗ \vec{a} a 和 和 和 b ⃗ \vec{b} b在 b ⃗ \vec{b} b 向上的投影与 向上的投影与 向上的投影与 ∣ b ⃗ ∣ |\vec{b}| ∣b∣的乘积,反映了两个向量在方向上的相似度
②向量叉乘
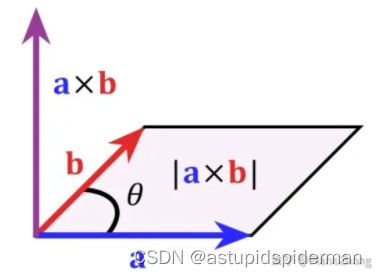
向量叉乘(cross product)又称向量积、外积,叉乘的结果是一个向量,与这两个向量都垂直,是这两个向量所在平面的法线向量
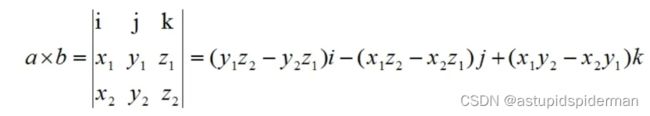
a ⃗ × b ⃗ = ∣ a ⃗ ∣ ∣ b ⃗ ∣ s i n θ n ⃗ \vec{a} \times \vec{b} = |\vec{a}||\vec{b}|sin\theta\ \vec{n} a×b=∣a∣∣b∣sinθ n
几何意义:如果以向量 a ⃗ \vec{a} a 和 和 和 b ⃗ \vec{b} b为边构成一个平行四边形,那么这两个向量外积的模长与这个平行四边形的面积相等。
③对应位置相乘
对应位置相乘的结果还是一个向量 size不变 结果为 ( x 1 ∗ x 2 , y 1 ∗ y 2 , z 1 ∗ z 2 ) (x_1*x_2,y_1*y_2,z_1*z_2) (x1∗x2,y1∗y2,z1∗z2)
import numpy as np
# 向量点乘
np.dot(a,b) # 标量
# 向量叉乘
np.cross(a,b) # 向量
# 对应位置相乘
np.nultiply(a,b) # 向量
二、矩阵乘法
一般来说我们说的矩阵相乘也是分为三种:按元素相乘、矩阵乘法、克罗内克积
①矩阵点乘/按元素相乘
与向量相乘不同的是,矩阵点乘得到的仍然是一个矩阵,不改变维数,他的结果是矩阵的各个元素对应相乘
矩阵点乘要求两个矩阵的size必须相等,或者行数相等,后者列数为1(广播机制)
当矩阵维度相等时,矩阵点积即为哈达玛积(hadamand product),符号为 A ⊙ B A\odot B A⊙B
②矩阵叉乘/矩阵乘法
矩阵叉乘即为矩阵乘法(matmul product),需要满足矩阵乘法的运算规则,即前者的列数和后者的行数要相等
③矩阵的克罗内克积(kronecker product)
矩阵的点乘和叉乘在numpy中的函数和向量运算是不一样的
# 矩阵点乘/按元素相乘
np.multiply(A,B)
or
A*B
# 矩阵叉乘/矩阵乘法
np.dot(A,B)
or
A@B # @和np.matmul的用法应该是一样的
or
A.dot(B)
三、高维矩阵相乘
高维矩阵相乘时,是把前面n-2维看做batch计算的,后面两维相乘,这样可以转换为二维矩阵运算
需要满足的规则是:矩阵的最后两维满足矩阵相乘原则,前面的n-2维相同(或者利用广播机制 可以为1)
需要注意的是 高维矩阵相乘用到的函数是np.matmul,它和np.dot在二维矩阵下是一致的。但高维是不同的
# np.dot可以实现矩阵与标量的乘法,而np.matmul不行
# 在二维矩阵乘法中,np.dot和np.matmul的结果是一样的
a = np.array([i for i in range(12)]).reshape([2,2,3])
b = np.array([i for i in range(12)]).reshape([2,3,2])
np.matmul(a,b).shape # (2,2,2)
np.dot(a,b).shape # (2,2,2,2)
np.dot将a数组的最后一维作为向量,并将b数组的倒数第二维作为了另一个向量然后进行向量间的点乘
一般情况下矩阵乘法采用np.matmul
但是当矩阵维度不同的时候,np.matmul是不能用的 这个时候如果一定要相乘,那么可以用*实现按元素相乘,通过广播机制补充到同维度,再进行同维度的乘法,只需要较低维矩阵的最高维与较高维矩阵对应维度形状相同即可
pytorch中处理张量
神经网络中一般都是高维矩阵[B,C,H,W],所以我们需要看一下pytorch中矩阵乘法的实现
import torch
# 按元素相乘
x * y
torch.mul(x,y)
# 向量点乘
torch.matmul(x,y) # 返回的是一个标量
torch.dot(x,y) # 只允许一维的tensor,不允许广播
# 矩阵乘法
torch.matmul(x,y)
torch.mm(x,y) # 仅处理矩阵乘法 torch.matmul可以处理向量 也可以广播
# 高维矩阵相乘
torch.matmul(x,y)
x shape: torch.Size([2, 2, 3])
y shape: torch.Size([2, 3, 2])
xy = torch.matmul(x,y)
xy shape: torch.Size([2, 2, 2])
or
torch.bmm(x,y) # torch.bmm仅能处理三维的矩阵相乘
矩阵乘法首选torch.matmul,这个函数功能很强大,可以实现向量点积,矩阵乘法,并且引入了广播机制
爱因斯坦求和简记法
爱因斯坦求和约定(einsum)也可以实现矩阵相乘的操作 并且在神经网络中处理高维数据时很可能会用到
numpy和pytorch都对它进行了实现,两者用法是一样的 这里给出pytorch中的例子
详细请看 一文学会 Pytorch 中的 einsum - 知乎 (zhihu.com) 一文掌握爱因斯坦求和约定 einsum_einstein求和_神功智能的博客-CSDN博客
使用时需要明确的是下面这几点,
- 哪几个输入数组参与运算
- 沿输入的哪些轴(维度)计算乘积
- 输出数组需要保留哪些轴
该简记法当中,省略掉的部分是:1)求和符号 与2)求和号的下标
与2)求和号的下标
**省略规则为:**默认成对出现的下标为求和下标
这里提供两个例子 来源:Pytorch中, torch.einsum详解。_电子科技大学的博客-CSDN博客
①二维矩阵乘法
print(a_tensor)
tensor([[11, 12, 13, 14],
[21, 22, 23, 24],
[31, 32, 33, 34],
[41, 42, 43, 44]])
print(b_tensor)
tensor([[1, 1, 1, 1],
[2, 2, 2, 2],
[3, 3, 3, 3],
[4, 4, 4, 4]])
# 'ik, kj -> ij'语义解释如下:
# 输入a_tensor: 2维数组,下标为ik,
# 输入b_tensor: 2维数组,下标为kj,
# 输出output:2维数组,下标为ij。
# 隐含语义:输入a,b下标中相同的k,是求和的下标,对应上面的例子2的公式
output = torch.einsum('ik, kj -> ij', a_tensor, b_tensor)
print(output)
tensor([[130, 130, 130, 130],
[230, 230, 230, 230],
[330, 330, 330, 330],
[430, 430, 430, 430]])
②高阶张量
a = np.arange(60.).reshape(3,4,5)
b = np.arange(24.).reshape(4,3,2)
# 语义解析:
# 输入a:3阶张量,下标为ijk
# 输入b: 3阶张量,下标为jil
# 输出o: 2阶张量,下标为k和l
# 隐含语义:对i,j进行求和,公式附于代码之后:
o = np.einsum('ijk,jil->kl', a, b)
print(o)
array([[4400., 4730.],
[4532., 4874.],
[4664., 5018.],
[4796., 5162.],
[4928., 5306.]])
# 验证:
print(np.sum(a[:,:,0]*b[:,:,0].T))
4400.0
print(np.sum(a[:,:,1]*b[:,:,0].T))
4532.0
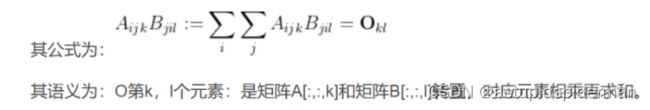
参考
向量点乘与叉乘的概念及几何意义 - 知乎 (zhihu.com)
pytorch tensor 乘法运算汇总与解析_tensor乘法_程序之巅的博客-CSDN博客
【全面理解多维矩阵运算】多维(三维四维)矩阵向量运算-超强可视化 - 知乎 (zhihu.com)