CUDA 二维、三维数组遍历
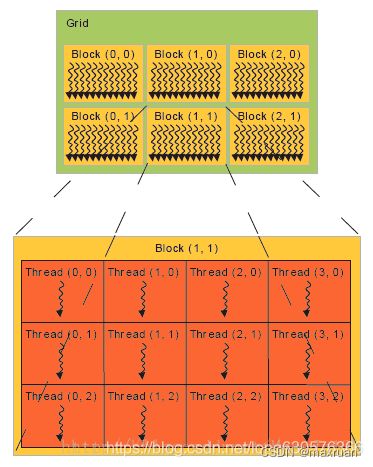
一个 Grid 分成 按维度分成多个Block,Block 个数为 GridDim.x * GridDim.y
遍历: blockIdx.x , blockIdx.y
一个Block 按维度分成多个Thread,Thread个数为 BlockDim.x * BlockDim.y
Thread 是最小的运行单元
遍历:threadIdx.x , threadIdx.y
二维数据处理
cudaMemcpy2D( d_A, // 目的指针
d_pitch, // 目的pitch
bmp1, // 源指针
sizeof(int)*2, // 源数据pitch
sizeof(int)*2, // 数据拷贝宽度
2, // 数据拷贝高度
cudaMemcpyHostToDevice);//从CPU拷贝二维数组到GPU上
#define H 2
#define W 3
__gloabal__ void process(float* d_mat, size_t pitch){
// y 方向最大长度到 blockDim.y * gridDim.y
for(int h = blockIdx.y * blockDim.y + threadIdx.y; h < H; h += blockDim.y * gridDim.y)
{
float* row_d_mat = (float*)((char*)d_mat + h * pitch);
//x 方向最大长度到 blockDim.x * gridDim.x
for(int w = blockIdx.x * blockDim.x + threadIdx.x; w < W; w += blockDim.x * gridDim.x)
{
// process
}
}
}
int main(){
//定义一个数组
float h_mat[H][W] = {{1,2,3},{11,12,13}};
float* d_mat;
size_t pitch;
transMat = (float*)malloc(sizeof(float)*M*N);
// 分配二维cuda内存
cudaMallocPitch(&d_mat, &pitch, sizeof(float) * W, H);
cudaMemset2D(d_mat, pitch, 0, sizeof(float) * W, H);
//拷贝到device
cudaMemcpy2D(d_mat, pitch, h_mat, sizeof(float) * W, sizeof(float) * W, H, cudaMemcpyHostToDevice);
//拷贝到host
cudaMemcpy2D(h_mat, sizeof(float) * W, d_mat, pitch, sizeof(float) * W, H, cudaMemcpyDeviceToHost);
process<<<gridsize, blocksize>>>(d_transMat, pitch);
cudaThreadSynchronize();
}
三维数据处理
void __global__ process(cudaPitchedPtr d_F1, cudaExtent extent_3d){
double* devd_F1=(double*)d_F1.ptr;
size_t pitchf1=d_F1.pitch;
size_t slicePitchf1=pitchf1 * extent_3d.height;
double *slice_F1, *row_F1,;
for (int i = blockIdx.y * blockDim.y + threadIdx.y; i < NX; i += blockDim.y * gridDim.y) {
slice_F1 = (double*)((char*)devd_F1 + i * slicePitchf1);
for (int j = blockIdx.x * blockDim.x + threadIdx.x; j < NY; j += blockDim.x * gridDim.x){
row_F1 = (double*)(((char *)slice_F1 + j * pitchf1));
for (int k = 0; k < Q; k++){
double temp1 = row_F1[k];
}
}
}
}
int main(){
// 分配内存
cudaPitchedPtr d_3d;
cudaExtent extent_3d = make_cudaExtent(sizeof(double) * W, H, Z);
cudaMalloc3D(&d_3d, extent_3d);
double h_mat[Z][H][W] = {{{1,2,3},{11,12,13}}, {{1,2,3},{11,12,13}}};
cudaMemcpy3DParms cpyParm = {0};
// copy to host
cpyParm1.kind = cudaMemcpyDeviceToHost;
cpyParm1.extent = extent_3d;
cpyParm1.srcPtr = d_3d;
cpyParm1.dstPtr = make_cudaPitchedPtr((void*)h_mat, sizeof(double) * W, W, H);
cudaMemcpy3D(&cpyParm);
// copy to device
cpyParm1.kind = cudaMemcpyHostToDevice;
cpyParm1.extent = extent_3d;
cpyParm1.dstPtr = d_3d;
cpyParm1.srcPtr = make_cudaPitchedPtr((void*)h_mat, sizeof(double) * W, W, H);
cudaMemcpy3D(&cpyParm);
process<<<gridsize, blocksize>>>(d_3d, extent_3d);