Flink 内核原理与实现-状态原理
可以关注下公众号,专注数据开发、数据架构之路,热衷于分享技术干货。
前言
状态在Flink中叫作State,用来保存中间计算结果或者缓存数据。根据是否需要保存中间结果,分为无状态计算和有状态计算。对于流计算而言,时间持续不断地产生,如果每次计算都是相互独立的,不依赖于上下游的事件,则是无状态计算。如果计算需要依赖于之前或者后续的事件,则是有状态计算。State是实现有状态计算的下的Exactly-Once的基础。
State的典型实例如:Sum求和、去重、模式检测CEP。
需要做好State管理,需要考虑:
1、状态数据的存储的和访问
2、状态数据的备份和恢复
3、状态数据的划分和动态扩容
4、状态数据的清理
一、状态类型
按照数据结构的不同,Flink中定义了多种State,应用于不同的场景。如下:
1、ValueState
类型为T的单值状态。这个状态与对应的Key绑定,是最简单的状态。可以通过update方法更新状态值,通过value()方法获取状态值。
2、ListState
Key上的状态值为一个列表。可以通过add方法往列表中附加值,也可以通过get()方法返回一个Iterable
3、ReducingState
这种状态通过用户传入的reduceFunction,每次调用add方法添加值时,会调用reduceFunction,最后合并到一个单一的状态值。
4、AggregatingState
聚合State,和ReducingState不同的是,这里聚合的类型可以是不同元素的元素类型,使用add(IN)来加入元素,并使用AggregateFunction函数计算聚合结果。
5、MapState
使用Map存储Key-Value对,通过put(UK,UV)或者putAll(Map
6、FoldingState
跟ReducingState有点类似,不过它的状态值类型可以与add方法中传入的元素类型不同。已被标位废弃,不建议使用。
二、KeyedState 与 OperatorState
2.1 KeyedState
在KeyedStream中使用。状态是跟特定的Key绑定的,即KeyedStream流上的每一个Key对应一个State对象。KeyedState可以使用所有的State。KeyedState保存在StateBackend中。
import org.apache.flink.api.common.functions.RichFlatMapFunction
import org.apache.flink.api.common.state.{ValueState, ValueStateDescriptor}
import org.apache.flink.api.common.typeinfo.{TypeHint, TypeInformation}
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.api.scala._
import org.apache.flink.configuration.Configuration
import org.apache.flink.util.Collector
object KeyedStateDemo {
class CountWindowAverage extends RichFlatMapFunction[(Long, Long), (Long, Long)] {
@transient var sum: ValueState[(Long, Long)] = _
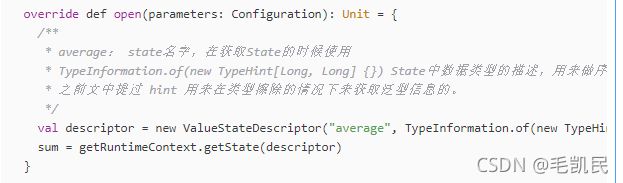
override def open(parameters: Configuration): Unit = {
/**
* average: state名字,在获取State的时候使用
* TypeInformation.of(new TypeHint[Long, Long] {}) State中数据类型的描述,用来做序列化和反序列化。
* 之前文中提过 hint 用来在类型擦除的情况下来获取泛型信息的。
*/
val descriptor = new ValueStateDescriptor("average", TypeInformation.of(new TypeHint[(Long, Long)] {}))
sum = getRuntimeContext.getState(descriptor)
}
override def flatMap(value: (Long, Long), out: Collector[(Long, Long)]): Unit = {
//保存之前的数据和
val tmpCurrentSum = sum.value()
//若之前有数据,则置当前数据和位之前的数据和,否则置总和为0
val currentSum: (Long, Long) = if (tmpCurrentSum != null) {
tmpCurrentSum
} else {
(0L, 0L)
}
val newSum = (currentSum._1, currentSum._2 + value._2)
sum.update(newSum)
if (newSum._2 % 2 == 0){
out.collect(value._1,newSum._2)
}
}
}
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.fromElements((1L, 1L), (2L, 1L), (1L, 2L), (2L, 22L), (1L, 3L))
.keyBy(0)
.flatMap(new CountWindowAverage)
.print()
env.execute(s"${this.getClass.getSimpleName}")
}
}2.2 算子状态OperatorState
与KeyedState不同,OperatorState跟一个特定算子的一个实例绑定,整个算子只对应一个State。相比较而言,在一个算子上,可能会有很多个Key,从而对应多个KeyState。
Operator 目前支持:
列表状态(List state):将状态表示为一组数据的列表。
联合列表状态(Union list state):也将状态表示为数据的列表。它与常规列表状态的区别在于,在发生故障时,或者从保存点(savepoint)启动应用程序时如何恢复。
广播状态(Broadcast state):如果一个算子有多项任务,而它的每项任务状态又都相同,那么这种特殊情况最适合应用于广播状态。
代码百度吧,太多了。官方Sink案例!!!!原谅我~~~(*^▽^*)
2.3 原始和托管状态
按照由Flink管理还是用户自行管理,状态可以分为原始状态(Raw State)和托管状态(Managed State)。
原始状态,即用户自定义的State,Flink在做快照的时候,把整个State当做一个整体,需要开发者自己管理,使用byte数组来读写状态内容。
托管状态是由Flink框架管理的State,如ValueState,ListState,MapState等,其序列化与反序列化由Flink框架提供支持,无序用户感知,干预。
KeyedState和OperatorState可以是原始状态,可以是托管状态。
通常在DataStream上的状态推荐使用托管状态,一般情况下,在实现自定义算子时,才会用到原始状态。
三、状态描述
State既然是暴露给用户的,那么就有一些属性需要指定,如State名称、State中类型信息和序列化/反序列化器、State的偶其实就等。在对应的状态后端(StateBackend)中,会调用对应的create方法获取到StateDescriptor中的值。在Flink中状态描述叫作StateDescriptor。

对应于每一类State,Flink内部都设计了对应的StateDescriptor,在任何使用State的地方,都需要通过StateDescriptor描述状态的信息。
运行时,在RichFunction和ProcessFunction中,通过RuntimeContext上下文对象,使用StateDescriptor从状态后端(StateBackend)中获取实际的State实例,然后在开发者编写的UDF中就可以使用这个State了。StateBackend中有对应则返回现有的State,没有则创建新的State。
3.1 广播状态
广播状态在Flink中叫做BroadcastState,在广播状态模式中使用。所谓广播状态模式,就是来自一个流的数据需要被广播到所有下游任务,在算子本地存储,在处理另一个流的时候依赖于广播的数据。广播State的类型必须是MapState类型。
用途:根据规则处理业务流数据。(避免实时性下降,规则更新不及时等情况发生。)
3.2 状态接口
1、面向应用开发者的State接口
只提供了对State中数据的添加、更新、删除等基本操作,用户无法访问状态的其他运行时所需要的的信息。
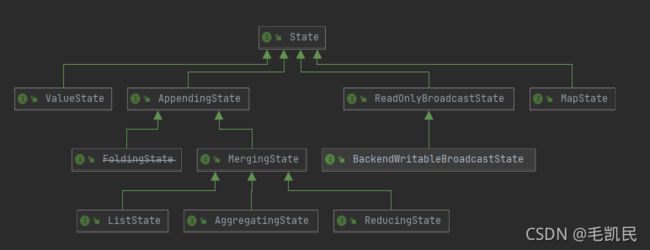
以MapState为例,提供了添加、获取、删除、遍历的API接口 
2、内部State接口
内部State接口是给Flink框架使用的,除了对State中数据的访问之外,还提供了内部的运行时信息接口,如State中数据的序列化器、命名空间(namespace)、命名空间的序列化器、命名空间合并的接口。
内部State接口的命名方式为InternalxxxState,内部State接口的体系非常复杂。下面以InternalMapState介绍。

InterMapState集成了面向应用开发者的State接口,也继承了InternalKvState接口,既能访问MapState中保存的数据,也能访问MapState运行时的信息。
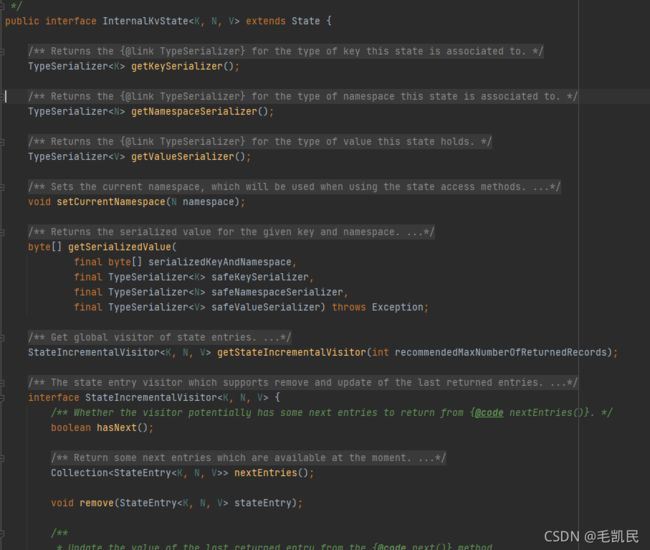
3、状态访问接口
有了状态之后,在开发者自定义的UDF中如何访问状态?
OperatorStateStore:数据以Map形式保存在内存中,并没有使用RocksDBStateBackend和HeapKeyedStateBackend。
KeyedStateStore:使用RocksDBStateBackend或者HeapKeyedStateBackend来保存数据,KeyedStateStore中获取/创建状态都交给了具体的StateBackend来处理,KeyedStateStore本身更像是一个代理。
4、状态存储
Flink中无论是哪种类的State,都需要被持久化到可靠存储中,才具备应用级的容错能力,State的存储在Flink中叫做StateBackend。
Flink内置了3种StateBackend。
- 纯内存:MemoryStateBackend,适用于验证、测试,不推荐生产环境。
运行时所需要的State数据保存在TaskManagerJVM堆上内存中,KV类型的State、窗口算子的State使用HashTable来保存数据、触发器等。执行检查点的时候,会把State的快照数据保存到JobManager进程的内存中。MemoryStateBackend可以使用异步的方式进行快照,也可以使用同步的方式。推荐使用异步,避免阻塞算子处理数据。
注意点:
1)State存储在JobManager内存中,受限于JobManager的内存大小。
2)每个State默认5MB,可通过MemoryStateBackend构造函数调整。
3)每个State不能超过Akka Frame大小。
- 内存+文件:FsStateBackend,适用于长周期大规模的数据。
运行时所需要的的State数据存在TaskManger的内存中,执行检查点的时候,会把State的亏按照保存到配制文件系统中,可以使用分布式文件系统或本地文件系统。
适用场景:
1)适用于处理大状态、长窗口,或者大键值状态的有状态处理任务。
2)FsStateBackend非常适用于高可用方案。
注意点:
1)State数据首先会被存在TaskManager的内存中。
2)State大小不能超过TM内存。
3)TM异步将State数据写入外部存储。
在运行时,MemoryStateBackend和FsStateBackend本地的State都保存在TaskManager的内存中,所以其底层都依赖于HeapKeyStateBackend。HeapKeyStateBackend面向Flink引擎内部,使用者无感。
- RocksDB:RocksDBStateBackend,适用于长周期大规模的数据。
适用嵌入式的本地数据库RocksDB将流计算数据状态存储在本地磁盘中,不会受限于TaskManager的内存大小,在执行检查点时,再将整个RocksDB中保存的State数据全量或者增量持久化到配置的文件系统中,在JobManager内存中会存储少量的检查点元数据。
缺点:访问State的成本对比于基于内存的StateBackend 会高很多,可能导致数据流的吞吐量剧烈下降。
适用场景:
1)最适合用于处理大状态、长窗口,或大键值状态的有状态任务处理。
2)RocksDBStateBackend非常适用于高可用方案。
3)RocksDBStateBackend是目前唯一支持增量检查点的后端。增量检查点非常适用于超大状态的场景。
注意点:
1)总State大小仅限于磁盘大小,不受内存限制。
2)RocksDBStateBackend也㤇配置外部文件系统,集中保存State。
3)RocksDB的JNI API基于byte数组,单key和单value的大小不能超过2^31 字节。
4)对于使用具有合并操作状态的程序,如ListState,随着时间累计超过2^31字节大小,将会导致接下来的查询中失败。
5、持久化策略
- 全量持久化策略
每次把全量State写入状态存储中。内存型、文件型、RocksDB类型的StateBackend都支持全量持久化策略。
在执行持久化策略的时候,使用异步机制,每个算子启动1个独立的线程,将自身的状态写入分布式存储中。在做持久化的过程中,状态可能会被持续修改,基于内存的状态后端使用CopyOnWriteStateTable来保证线程安全,RocksDBStateBackend则使用RockDB的快照机制保证线程安全。
- 增量持久化策略
每次持久化增量的State,只有RocksDBStateBackend支持增量持久化。
RocksDB是一个基于LSM-TREE的kv存储,新的数据保存在内存中,成为memtable。如果Key相同,后到的数据将覆盖之前的数据,一旦memtable写满了,RocksDB就会将数据压缩并写入到磁盘。memtable的数据持久化到磁盘后,就变成了不可变的sstable。
因为sstable是不可变的,Flink对比前一个检查点创建和删除的RocksDB sstable文件就可以计算出状态有哪些改变。为了确保sstable是不可变的,Flink会在RocksDB上触发刷新操作,强刷memtable到磁盘。在执行检查点时,会将新的sstable持久化到存储中(如HDFS等),同时保留引用。这个过程中 Flink并不会持久化本地所有的sstable,因为本地的一部分历史sstable在之前的检查点就已经持久化到存储中可。只需要增加对sstable文件的引用次数就可以。
RocksDB会在后台合并sstable并删除重复的数据。然后在RocksDB删除原来是sstable,替换成新合成的sstable,新的sstable包含了被删除的sstable中的信息。通过合并,历史的sstable会合并成一个新的sstable,并删除这些历史的sstable,可以减少检查点的历史文件,避免大量小文件产生。
6、状态重分布
- OperatorState重分布
1、ListState
并行度在改变的时候,会将并发上的每个List都取出,然后把这些List合并到一个新的List,根据元素的个数均匀分配给新的Task
2、UnionListState
比ListState更灵活,把划分的方式交给用户去做,当改变并发的时候,会将原来的List拼接起来,然后不做划分,直接交给用户。
3、BroadcastState
操作BroadcastState要保证不可变性,所以各个算子的同一个BroadcastState完全一样。改变并发的时候,把这些数据分发打新的Task即可。
- KeyedState重分布
基于Key-Group,每个Key隶属于唯一的一个Key-Group。Key-Group分配给Task实例,每个Task至少有一个Key-Group.
Key-Group数量取决于最大并行度(MaxParallism)。KeyedStream并发的上线是Key-Group的数量,等于最大并行度。
7、状态过期
- DataStream中状态过期
过期时间:超过多长时间未访问,视为State过期,类似于缓存。
过期时间更新策略:创建和写时更新、读取和写时更新。
State的可见性:未清理可用,超期则不可用。
import org.apache.flink.api.common.state.StateTtlConfig;
import org.apache.flink.api.common.state.ValueStateDescriptor;
import org.apache.flink.api.common.time.Time;
StateTtlConfig ttlConfig = StateTtlConfig
.newBuilder(Time.seconds(1))
.setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite)
.setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired)
.build();
ValueStateDescriptor stateDescriptor = new ValueStateDescriptor<>("text state", String.class);
stateDescriptor.enableTimeToLive(ttlConfig); -
Time.seconds(1) 周期过期时间
-
setUpdateType 更新类型
-
setStateVisibility 是否在访问state的时候返回过期值
setUpdateType:
-
StateTtlConfig.UpdateType.OnCreateAndWrite- 只在创建和写的时候清除 (默认) -
StateTtlConfig.UpdateType.OnReadAndWrite- 在读和写的时候清除
setStateVisibility:
-
StateTtlConfig.StateVisibility.NeverReturnExpired- 从不返回过期值 -
StateTtlConfig.StateVisibility.ReturnExpiredIfNotCleanedUp- 如果仍然可用,则返回
在 NeverReturnExpired 的情况下,过期状态的就好像它不再存在一样,即使它未被删除。这个选项对于 TTL 之后之前的数据数据不可用。
另一个选项 ReturnExpiredIfNotCleanedUp 允许在清理之前返回数据,也就是说他ttl过期了,数据还没有被删除的时候,仍然可以访问。
- FlinkSQL 中状态过期
@Test(expected = classOf[IllegalArgumentException])
def testMinBiggerThanMax(): Unit = {
//设置过期时间 min =12 小时,max = 24小时
new StreamQueryConfig().withIdleStateRetentionTime(Time.hours(12), Time.hours(24))
}8、状态过期清理
- 调用ValueState#value() 只有明确读出过期值时才会删除过期值。
- 调用cleanupFullSnapshot() 做完整快照时清理后,在获取完整状态时激活清理。
- 调用cleanupIncrementally 通过增量触发器渐进清理State。当进行状态访问或者处理数据时,在回调函数中进行清理。每次递增清理触发时,遍历StateBackend中的状态,清理过期的。
接下来Flink作业提交篇,如果对Flink感兴趣或者正在使用的小伙伴,可以加我入群一起探讨学习。
参考书籍《Flink 内核原理与实现》
欢迎关注公众号: 数据基石
