超详细の归并排序

文章目录
-
-
- 引入:
- 实现原理
- 问题引出:
- 递归实现:
- 迭代实现
- 稳定性分析:
- 总结:
-
引入:
如何将两个有序数组(假设为升序)合并为一个有序数组?
双指针法,如果第一个数组的第一个元素大于第二个数组的元素,就取第二个(即较小的那个放在合并的数组的首位置),然后在比较第一个数组第一个元素与第二个数组的第二个元素,以此类推,终将有一个数组的元素先被访问完,剩下的那个数组的元素一定是大于已经排序后的数组,直接将未排完序的数组的元素添加到我们要合并数组即可。

代码如下
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] < a[begin2])
{
tmp[index++] = a[begin1++];
}
else
{
tmp[index++] = a[begin2++];
}
}
while (begin1 <= end1)
{
tmp[index++] = a[begin1++];
}
while (begin2 <= end2)
{
tmp[index++] = a[begin2++];
}
实现原理
归并排序就是利用上边的思想进行排序,将无序的数组不断折中至最短,并在合并的过程中将两个数组进行合并并排序。其是建立在归并操作上的一种有效的排序方式,采用分治法,将已经排好序的子序列合并,得到完全有序的序列,在归的过程中将待排序的数组分为各个小块,在并的过程中不断使每个小区间变为有序,最终使该数组有序。
过程刨析
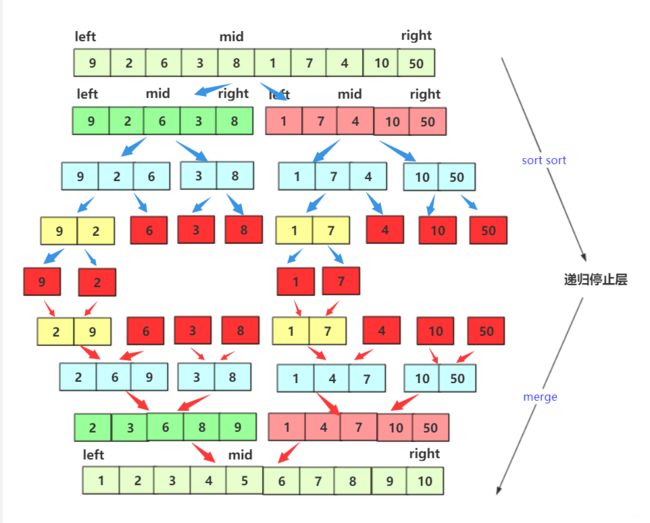
问题引出:
能否在原数组进行排序?
- 如果直接进行数据覆盖的话明显不可以,会将未修改的元素覆盖,直接修改了数组元素,这种想法必然是错误的。
- 聪明的同学会想到那么我用交换的形式呢?
看下边这种情况

第二个小数组区间已经排好的序已经被打乱,在后边的排序中,比较时就是先和5比,再和4比,这就违反了我们两个有序数组分别从第一个元素比大小将小的那个放在合并的数组的第一个位置的核心思想。
引出空间复杂度,顺便也说一说他的时间复杂度,我想大家已经有所猜测了,毕竟和二分法沾边的算法。
空间复杂度:
使用归并排序的方法时要开一份同样大小的数组装载这个新数组,比较时用原数组,放置时用开好的新数组。因为递归时空间可以复用,所以归并排序的空间复杂度明显是O(N)。
时间复杂度:
时间复杂度是容易判断,由递归的深度和判断的次数即可得出归并排序的时间复杂度,二分法将递归深度变为log(N),数据量为N,故时间复杂度为O(N*logN)。
递归实现:
void MergeSort(int* a, int n)
{
int* tmp = (int*)malloc(sizeof(int) * n);
if (tmp == NULL)
{
perroe("malloc fail");
return;
}
_MergeSort(a, tmp, 0, n - 1);
free(tmp);
}
void _MergeSort(int* a, int* tmp, int begin, int end)
{
if (end <= begin)
return;
int mid = (end + begin) / 2;
MergeSort(a, tmp, begin, mid);
MergeSort(a, tmp, mid + 1, end);
//归并到tmp数组,再拷贝回去
//a->[begin,mid][mid+1,end]->tmp拷贝过去,新开空间
int begin1 = begin, end1 = mid;
int begin2 = mid + 1, end2 = end;
int index = begin;
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] < a[begin2])
{
tmp[index++] = a[begin1++];
}
else
{
tmp[index++] = a[begin2++];
}
}
while (begin1 <= end1)
{
tmp[index++] = a[begin1++];
}
while (begin2 <= end2)
{
tmp[index++] = a[begin2++];
}
memcpy(a + begin, tmp + begin, (end - begin + 1) * sizeof(int));
}
要注意递归的结束条件已经想要用递归来做什么,不断分化小区间,然后调用小区间的归并,直至每个数组只有一个元素,然后再用两个有序数组合并为一个有序数组的方法,将两个数组合并。
上图展开中好似前半段和后半段的排序是同时进行的,其实不然,根据代码就可以看出,递归先排序好数组的前半部分,再排序数组的后半部分。
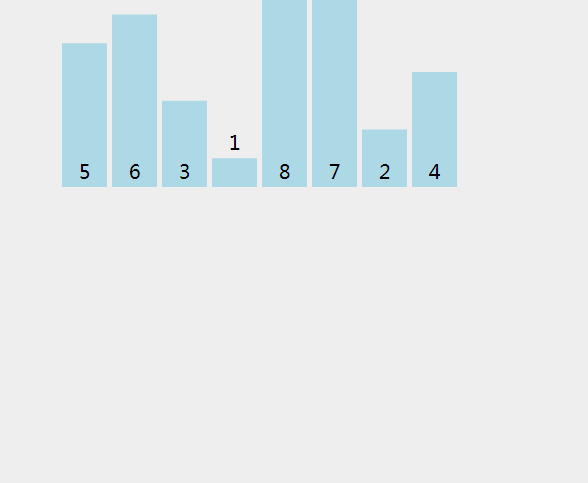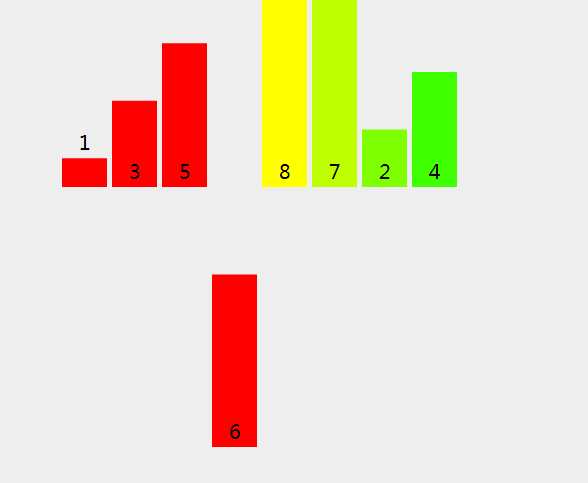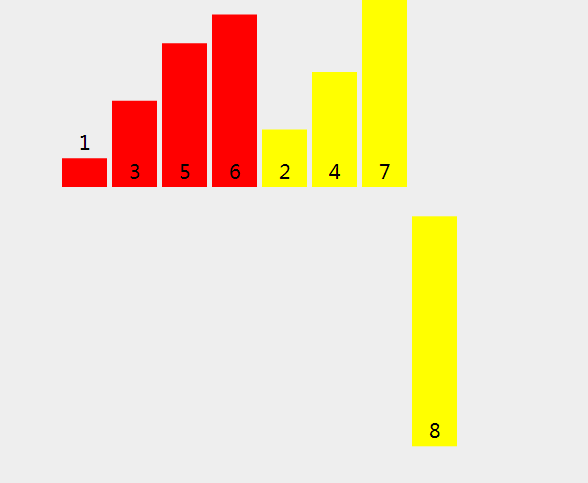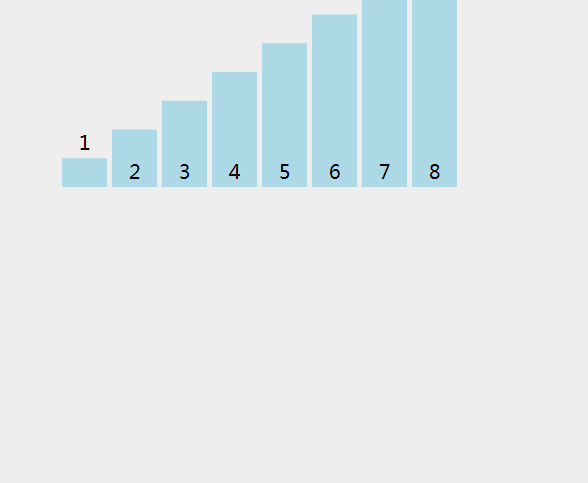
在分割时是有顺序的,如果递归的过程还是不够清晰可以自己尝试画一画递归展开图,也可移步二叉树问题详谈递归对递归的过程获得更大的理解和掌握。
迭代实现
无疑是借助==循环(迭代)==来实现。
仔细想一想我们会发现,在递归的过程中我们需要的是不断获得分割后每一小区间数组的坐标,分割直至每一个小数组只有一个元素为止,然后一个数组有两个元素,然后继续合并为八个元素,直至数组的每个坐标的值都被访问一遍为止。
如果大家已经看了快速排序的非递归版,可能会想到用栈来实现,然而这里用栈是不能解决这里的问题的,快速排序可以用栈是因为数组个数end在使用之后就pop出栈也没有影响,然而归并排序还需要知道划分的范围最后要合并数组,然而如果想要实现递归的过程,前边的数据都已经被pop掉,无法确定数组范围,就无法借此来合并。
如动图所示:
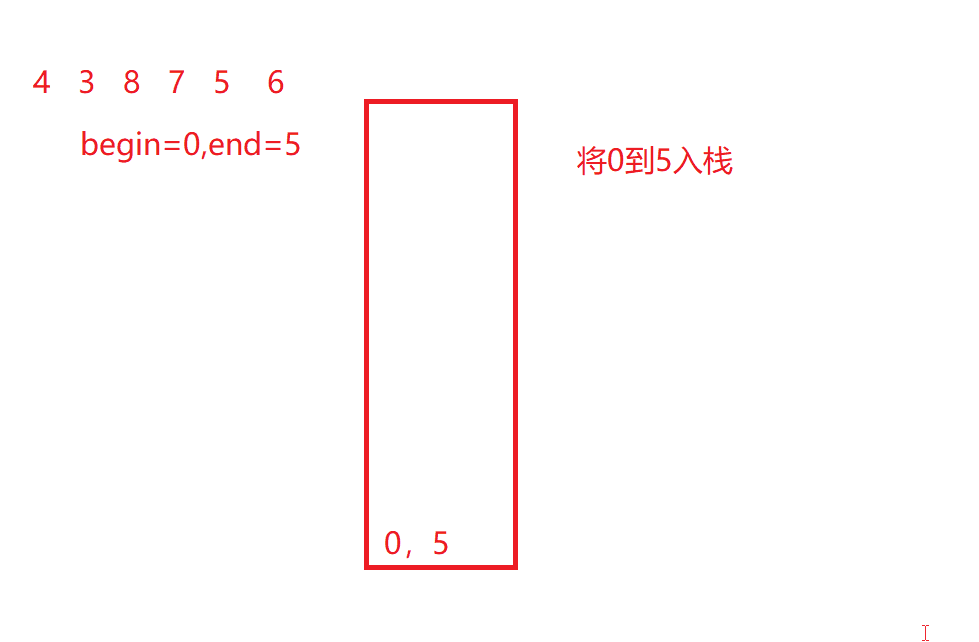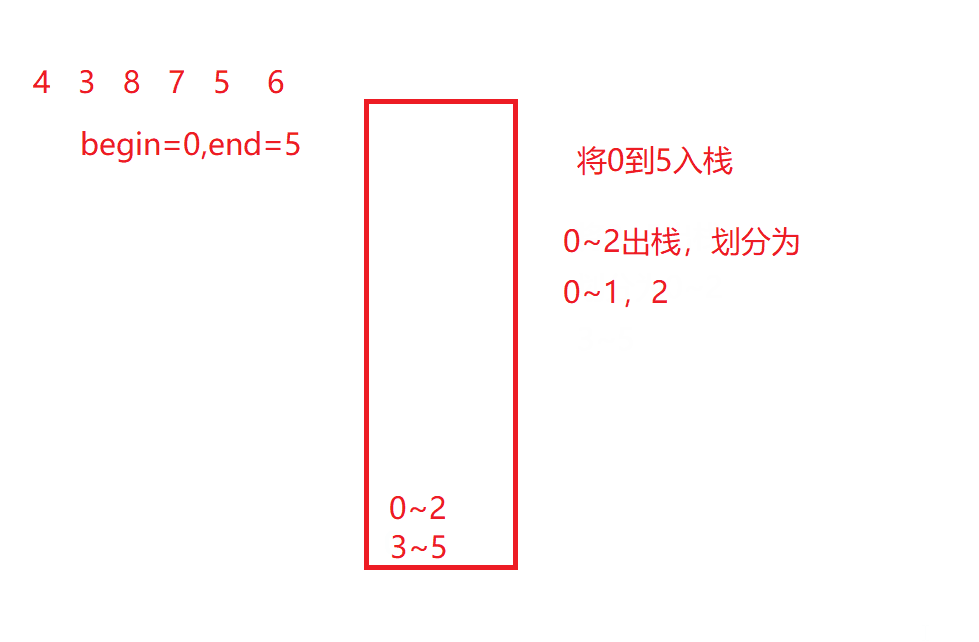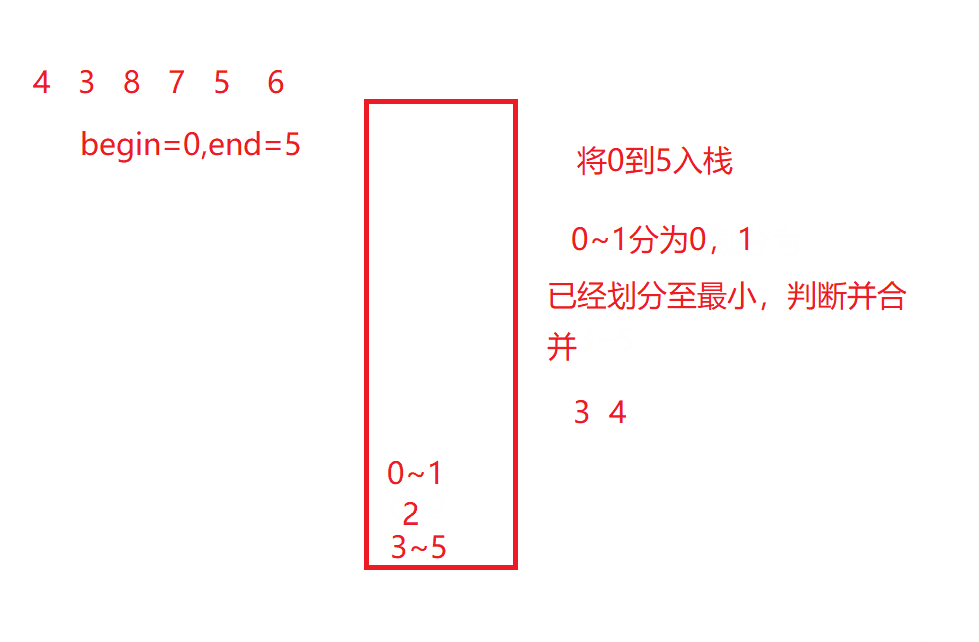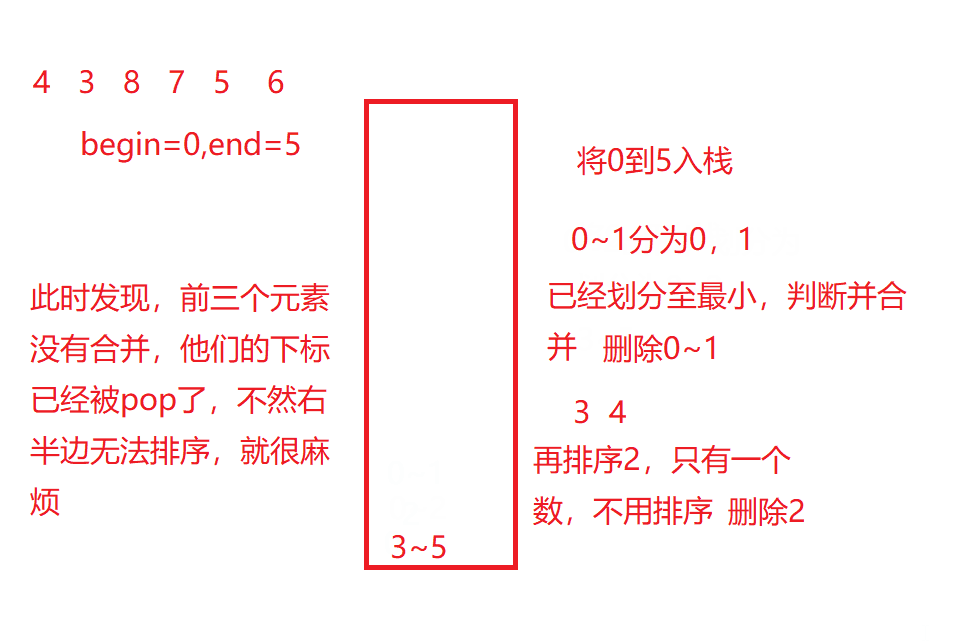
当然,如果一定要用栈或队列来实现他,会很麻烦,因为有更好的方法可以解决。
要跳出递归的思路,利用循环的方法,归并的思想。
如图所示
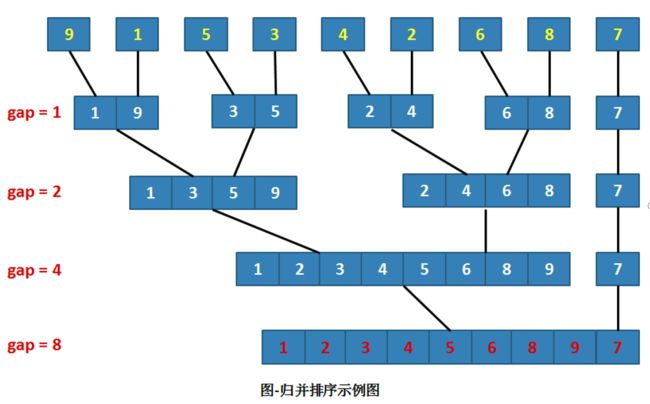
首先一个一个元素排序合并,两个两个元素进行排序并合并,两两排序后,每两个元素就变成有序的了,然后四个四个合并并排序,然后八个和八个,这样就将数组所由元素利用归并的方式进行排序。
void MergeSortNonR(int* a, int n)
{
int* tmp = (int*)malloc(sizeof(int) * n);
if (tmp == NULL)
{
perror("malloc fail");
return;
}
int gap = 1;
while (gap < n)
{
for (int i = 0; i < n; i += 2 * gap)
{
int begin1 = i, end1 = i + gap - 1;
int begin2 = i + gap, end2 = i + 2 * gap - 1;
//[begin1,end1] [begin2,end2]归并
//如果第二组不存在,这一组就不用归并啦
if (begin2 >= n)
{
break;
}
//如果第二组越界
if (end2 >= n)
{
end2 = n - 1;
}
int index = i;
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] < a[begin2])
{
tmp[index++] = a[begin1++];
}
else
{
tmp[index++] = a[begin2++];
}
}
while (begin1 <= end1)
{
tmp[index++] = a[begin1++];
}
while (begin2 <= end2)
{
tmp[index++] = a[begin2++];
}
memcpy(a + i, tmp + i, (end2 - i + 1) * sizeof(int));
}
printf("\n");
gap *= 2;
}
free(tmp);
}
下边是上述代码的解释:
可以看到,起始条件下gap的值为1,第一次循环时,将begin1为0,end1为0,begin2为1,end2为1。
判断大小,将小的放前边,大的放后边,最后归并到原数组。memcpy(a + i, tmp + i, (end2 - i + 1) * sizeof(int));
由于i=0。拷贝回原数组时,a+i还是a的位置,拷贝数量在-0+1后变为了2,就将判断后的两个元素归并到原数组,且已经排好了序。
- 然后下次循环,i+2,指向了数组第三个元素。
begin1=2,end1=2,begin2=3,end2=3。
这时就是第二个元素第三个元素排序归并,直至走完这一次for循环,gap*=2,回到外层while循环,gap
注意:这里while结束的条件为gap>n,在循环内,一定会出现这样的情况,虽然gap的值没有大于n,但在for循环中,i的值加等于二倍的gap,所以begin2一定会大于n,这就会造成越界访问,这时就不应该继续执行循环,直接break出去,然后在while循环结尾,gap会*=2,当gap的值大于n时,就代表数组已经排序完了。
//如果第二组不存在,这一组就不用归并啦
if (begin2 >= n)
{
break;
}
还有一种情况就是begin2没有越界,然而end2越界,这时第二个数组还是存在的,直接将end2更改为n-1即可。
if (end2 >= n)
{
end2 = n - 1;
}
稳定性分析:
归并排序是一个稳定的排序,除了空间复杂度比较大,其他的都是优点,通过上边的演示,可以发现,在归并的过程中相同数据的位置排列不会发生变化。
总结:
归并排序是一种很不错的排序方式,如果追求高效率且需要稳定性,归并排序是首当其冲的最优解,对于当前的计算机来说花费一点内存不算什么,归并排序的思想很简单,困难的是细节的把握,相对于其他相同时间复杂度的其他排序方式,大都是不稳定的,所以总体而言归并排序在排序界还是有一席之地的。
今天的内容就到这里,欢迎大家留言反馈。