基于tensorflow2.0的深度学习 三
基于卷积神经网络的深度计算机视觉
卷积神经网络(CNNs)起源于对大脑视觉皮层的研究, 广泛应用于图像搜索服务、自动驾驶汽车、自动视频分类系统等。此外,CNN还不局限于视觉感知:它们在许多情况下也是成功的,如语音识别和自然语言处理。 不过,我们现在将专注于视觉应用。
为什么不简单地使用常规的全连接深层神经网络进行图像识别任务呢? 不幸的是,虽然这对小图像(例如MNIST)可以正常工作,但是由于需要海量参数,使得它对大图像无能为力。而且全连接层展成1维的向量会丢失掉图片信息。因此需要引入卷积层和池化层。
卷积神经网络的结构:
(卷积层+(可选)池化层)* N + 全连接层 * M。(N>=1;M>=0)
卷积层的输入输出都是矩阵;全连接层的输入输出都是向量。
全连接层只能用于卷积层后面,因为卷积层输出到全连接层是需要一个展平的操作,这样就丢失了维度信息,不可逆。
全卷积神经网络:
(卷积层+(可选)池化层)* N + 反卷积层 * K。
卷积层和池化层的操作会使得输出的尺寸不断变小,而反卷积层就可以逆向,使输出的尺寸变大,那么这样就可以使得开始的输入和最后的输出尺寸相等,这可以应用到物体分割上。
卷积操作
CNN最重要的构建块是卷积层。卷积层采用局部连接,参数共享的办法可以解决参数过多的问题。
卷积核(过滤器)
卷积核是一个参数矩阵,它是要通过反向传播后调整得到的。(性质与连接权重一样)。
卷积的计算过程
下图表示图片在一个维度上具体值得计算过程:
步长:卷积核在输入图像上滑动的间隔:stride = 1
单通道:
卷积核每个方框表示卷积神经元,卷积神经元的权重需要反向传播计算训练得到。

三通道:
三通道图像经过一个卷积核之后得到的是单通道的(单个特征图):它将每个通道对应的值相加得到一个值再加上偏置。
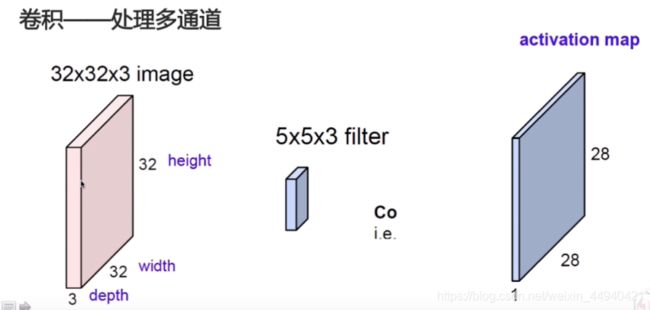
多个卷积核:
我们可以使用多个卷积核得到多个特征图,这样就可以得到多通道输出。
特征图中的所有神经元共享参数能够显著减小模型中的参数数量,但更重要的是,这一特征意味着一旦CNN学会了识别某个位置上的某个模式,它就可以在任何地方识别该模式。

对图片描述如下:

步长:当stride = 2时

可见不断地进行卷积操作会使图片尺寸不断变小,那么是否可以使得输出的side不变呢?
Padding—使得图片输出的side不变:
对输入图片的周围进行补零操作:

TensorFlow 实现
在TensorFlow中,每个输入图像通常表示为形状[height、width、channels]的三维张量。 小批量表示为四维张量[mini-batch、height、width、channels]。 卷积层的权重表示为四维张量[fh,fw,fn‘,fn]。 卷积层的偏置参数简单地表示为一维张量[fn]。
让我们看看一个简单的例子。 下面的代码使用Scikit-Learn的load_sample_image()加载图像(其中加载两个彩色图像,一个是中国寺庙,另一个是花) 然后,它创建两个7*7的过滤器(初始化为:一个中间有垂直白线,另一个中间有水平白线)并将它们应用于两个图像,最后它显示由此产生的特征图。
from sklearn.datasets import load_sample_image
#下载两张彩色图片
china = load_sample_image("china.jpg") / 255
flower = load_sample_image("flower.jpg") / 255
#显示一下中国寺庙的图,以及大小
plt.imshow(china)
china.shape
(427, 640, 3)

#显示一下花的图片,及大小
plt.imshow(flower)
flower.shape
(427, 640, 3)

#将两幅图和成一个四维张量,表示有2个批次
images = np.array([china, flower])
batch_size, height, width, channels = images.shape
# 创建两个7*7滤波器
filters = np.zeros(shape=(7, 7, channels, 2), dtype=np.float32)
filters[:, 3, :, 0] = 1 # 垂直白线
filters[3, :, :, 1] = 1 # 水平白线
#卷积得到输出特征图,这里使用零填充,步幅为2。
#因为有两个滤波器,故得到两张特征图。
outputs = tf.nn.conv2d(images, filters, strides=2, padding="SAME")
关于conv2d这个函数:
padding:可以设置为“SAME”或者“VALID”
- 设为“SAME”:则卷积层在必要时使用零填充。输出神经元的数量等于输入神经元的数量除以步幅,结果向上取整。
- 设为“VALID”:则卷积层不使用零填充,根据步幅可能会忽略输入图片中位于底部和右侧的一些行和列。
#卷积操作前的形状
print(images.shape)
#卷积操作后的形状
print(outputs.shape)
结果:
(2, 427, 640, 3)
(2, 214, 320, 2)
可见,本例的步长使用的是2,所以输出神经元的数量是输入神经元除以2。
#显示寺庙图的第2张特征图
plt.imshow(outputs[0, :, :, 1], cmap="gray") # plot 1st image's 2nd feature map
plt.show()

#显示花的第1张特征图
plt.imshow(outputs[1, :, :, 0], cmap="gray") # plot 1st image's 2nd feature map
plt.show()

在上面的例子中,是自定义过滤器的,而在真实的卷积神经网络中,过滤器是一个可训练的变量,通过反向传播来确定它的值,因此我们只需要定义过滤器的个数和它的大小即可:
conv = keras.layers.Conv2D(filters=32, kernel_size=3,
strides=1, padding="same", activation="relu")
此代码表示创建了一个Conv2D层,表示包含了32个过滤器,每个过滤器是3*3,步长为1,使用零填充的方法,并使用ReLU激活函数
池化操作
池化操作和卷积操作类似,池化层的目的是通过对输入图像进行二次采样以减少计算负载、内存利用率和参数数量(从而降低过拟合的风险)。减小输入图像的大小同样可以使神经网络容忍一定的图像位移(位移鲁棒性)。池化神经元没有权重(也就是核里面没有值),它只有两个超参数:步长(stride)和核大小(kernel_side)。池化神经元所做的事情就是使用聚合函数(比如max或者mean)聚合输入。
最大值池化(max聚合)
在池化层中kernel_side一般设置与Stride的值一致。池化操作中一般不补零,所以会丢弃掉某些值

平均值池化(mean聚合)
平均值池化与最大值池化操作相同,只是对输入图像不是取最大值,而是取平均值。

池化操作特点:
常使用补重叠不补零:即kernel_side和Stride是一样的,这样保证了每个Pooling滑动的区域不会重叠。如果滑到最后多出来一点不够计算的话直接丢弃,不补零。
可以用于减少图像尺寸,从而减少计算量。
TensorFlow 实现
应用最大值池化:
下面代码表示使用2×2内核创建最大池层。 步长默认为内核大小,因此此层将使用strIde为2(水平和垂直)。 默认情况下,它使用“VALID”填充(即根本没有填充)
max_pool = keras.layers.MaxPool2D(pool_size=2)
应用最大值池化:
avg_pool = keras.layers.AvgPool2D(pool_size=2)
如今,普遍使用最大值池化, 因为最大池只保留最强的特性,摆脱所有无意义的特性,因此下一层得到一个更干净的信号来工作。 此外,最大值池化与平均值池化相比具有更强的平移不变性,并且它需要的计算量较少。
应用深度最大池层
池化操作可以沿着深度维度执行,也就是说,当输入是多个过滤器生成的特征图,那么,深度最大池层可以更好地学习到各种特征,具有很强的旋转鲁棒性。
而 Keras不包括深度最大池层,但TensorFlow的低层API可以实现:
kside和stride为4维张量。他们的前三个值应该是1:这表明batch、hight和width的kernel size和步长应该是1。 最后一个值应该是kernel size和步长沿深度维度的步幅,这个值必须是输入深度的除数;比如下面代码设置为3,那么如果前一层输出的是20个特征图,则不起作用,因为20不是3的倍数。
output = tf.nn.max_pool(images, ksize=(1, 1, 1, 3),
strides=(1, 1, 1, 3), padding="valid")
如果你想将其作为一个层包含在Keras模型中。
depth_pool = keras.layers.Lambda(
lambda X: tf.nn.max_pool(X, ksize=(1, 1, 1, 3),
strides=(1, 1, 1, 3), padding="valid"))
应用全局平均池化层
它的工作原理非常不同:它所做的就是计算每个整个特征图的平均值(它就像使用与输入相同空间维度的池化核的平均池层)。 这个这意味着对于每个实例的每个特征图它只是输出一个数字。 虽然这是极具破坏性的(特征图中的大部分信息都丢失了),但它在输出层可能是有用的。
global_avg_pool = keras.layers.GlobalAvgPool2D()
等同于对每个特征图的行列取平均值。
global_avg_pool = keras.layers.Lambda(lambda X: tf.reduce_mean(X, axis=[1, 2]))
CNN架构
典型的CNN架构如下:
(卷积层+(可选)池化层)* N + 全连接层 * M。(N>=1;M>=0)

下面是实现一个处理Fashion MNIST数据集的简单卷积神经网络架构的示例:
导入需要的库
import matplotlib as mpl
import matplotlib.pyplot as plt
%matplotlib inline
import numpy as np
import sklearn
import pandas as pd
import os
import sys
import time
import tensorflow as tf
from tensorflow import keras
print(tf.__version__)
for model in mpl, np, pd, sklearn, tf.keras:
print(model.__name__,model.__version__)
载入数据集:
fashion_mnist = keras.datasets.fashion_mnist
(x_train_full, y_train_full), (x_test, y_test) = fashion_mnist.load_data()
x_valid, x_train = x_train_full[:5000], x_train_full[5000:]
y_valid, y_train = y_train_full[:5000], y_train_full[5000:]
print(x_valid.shape, y_valid.shape)
print(x_train.shape, y_train.shape)
print(x_test.shape, y_test.shape)
输出结果:
(5000, 28, 28) (5000,)
(55000, 28, 28) (55000,)
(10000, 28, 28) (10000,)
将数据集归一化操作
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
x_train_scaled = scaler.fit_transform(x_train.astype(np.float32).reshape(-1, 1)).reshape(-1, 28, 28, 1)
x_valid_scaled = scaler.fit_transform(x_valid.astype(np.float32).reshape(-1, 1)).reshape(-1, 28, 28, 1)
x_test_scaled = scaler.fit_transform(x_test.astype(np.float32).reshape(-1, 1)).reshape(-1, 28, 28, 1)
构建模型:
model = keras.models.Sequential([
#卷积层
keras.layers.Conv2D(64, 7, activation="relu",
padding="same",
input_shape=[28, 28, 1]),
#池化层
keras.layers.MaxPooling2D(2),
keras.layers.Conv2D(128, 3, activation="relu",
padding="same"),
keras.layers.Conv2D(128, 3, activation="relu",
padding="same"),
keras.layers.MaxPooling2D(2),
keras.layers.Conv2D(256, 3, activation="relu",
padding="same"),
keras.layers.Conv2D(256, 3, activation="relu",
padding="same"),
keras.layers.MaxPooling2D(2),
#展平成一维
keras.layers.Flatten(),
keras.layers.Dense(128, activation="relu"),
keras.layers.Dropout(0.5),
keras.layers.Dense(64, activation="relu"),
keras.layers.Dropout(0.5),
keras.layers.Dense(10, activation="softmax")
])
编译和训练模型:
model.compile(loss="sparse_categorical_crossentropy",
optimizer="sgd",
metrics=["accuracy"])
history = model.fit(x_train_scaled, y_train, epochs=10,
validation_data=(x_valid_scaled, y_valid))
接下来介绍的是经典LeNet-5构架与历年来在ILSVRC ImageNet challenge竞赛中衍生出来的经典卷积神经网络架构。
LeNet-5(1998年)
广泛应用于手写数据识别(MNIST),它的架构由下图的层组成:

AlexNet (2012年)
它和LeNet-5架构很相似,只是比LeNet-5更大更深,它直接将卷积层堆叠到其他层之上。而不是在每个卷积之上堆叠池化层。

为了减少过度拟合,它们采用了两种正则化技术。 首先,在训练期间输出层F8和F9采用了淘汰策略(dropout为50%), 其次,他们通过各种偏移随机移动训练图像,水平翻转它们,并改变照明条件来进行数据增强(正则化技术:数据扩充)
ZF Net (2013年)
它的本质就是AlexNet,只是调整了一些超参数(特征图的数量、内核大小、步幅等)
GoogLeNet(2014年)
初始化模块:表示为“3×31(S)”意味着该层使用3×3内核、步长1和“SAME”填充。
输入信号首先被复制并输入到四个不同的层。 所有卷积层都使用ReLU激活函数。 注意,第二组卷积层使用不同的核si ZES(1×1、3×3和5×5),允许它们在不同的尺度上捕获模式。 还请注意,每个图层都使用1和“SAME”填充的步长(甚至是最大池层),所以它们的输出的高度和宽度都与它们的输入相同。
简而言之,可以将整个初始化模块看成是一个超级卷积层,它总能狗输出一些用以捕捉各种尺寸复杂模式的特征图。
下图表示一个初始化模块:

下图表示GoogLeNet的CNN架构:

ResNet(2015年)
残差学习:
在训练神经网络时,目标是使它成为目标函数h(X)的模型。 如果将输入x添加到网络的输出中(即添加跳过连接),则网络将被强制模型化为f(X)=h(X)-x,而不是h(X)。 这就是所谓的残差学习。
现在让我们看看ResNet的体系结构。它的开始和结束完全像GoogleLeNet(除了没有淘汰层),而中间只是一个非常深的简单残差单元。 每个残差单元由两个具有分批归一化(BN)和ReLU激活功能的卷积层(没有池层)组成,使用内核并保留了维度空间(stride = 1,“SAME” 填充)。

Xception(2016年)
首先提到是Inception-v3是由Google提出的网络结构。是用下图的子结构去替代普通的卷积结构而构成一个完整的卷积神经网络。它的特点就是分支,可以得到不同尺度的视野域还可以提高效率。

由此引入深度可分离卷积:
传统的卷积层使用过滤器,试图同时捕获空间模式(例如椭圆形)和跨通道模式(例如嘴、鼻子、眼睛=脸),但这种可分离的卷积结构提出了空间模式和跨通道模式是可以单独分别输入的。

TensorFlow实现深度可分离网络
关于上例中处理Fashion MNIST数据集实现深度可分离的神经网络构架,只需要把keras.layers.Conv2D()改成SeparableConv2D即可。(当然这里的模型使用了与上例不同的层结构,过滤器个数也有改变)
model = keras.models.Sequential()
model.add(keras.layers.Conv2D(filters = 32, kernel_size = 3, padding = 'same',
activation = 'relu', input_shape = (28, 28, 1)))
model.add(keras.layers.SeparableConv2D(filters = 32, kernel_size = 3, padding = 'same',
activation = 'relu'))
model.add(keras.layers.MaxPool2D(pool_size = 2))
model.add(keras.layers.SeparableConv2D(filters = 64, kernel_size = 3, padding = 'same',
activation = 'relu'))
model.add(keras.layers.SeparableConv2D(filters = 64, kernel_size = 3, padding = 'same',
activation = 'relu'))
model.add(keras.layers.MaxPool2D(pool_size = 2))
model.add(keras.layers.SeparableConv2D(filters = 128, kernel_size = 3, padding = 'same',
activation = 'relu'))
model.add(keras.layers.SeparableConv2D(filters = 128, kernel_size = 3, padding = 'same',
activation = 'relu'))
model.add(keras.layers.MaxPool2D(pool_size = 2))
# 全连接层
model.add(keras.layers.Flatten())
model.add(keras.layers.Dense(128, activation="relu"))
model.add(keras.layers.Dense(10, activation="softmax"))
Xception网络结构的核心就是深度可分离卷积:

SENet(2017年)
ResNet网络结构的低层实现代码:
首先创建一个残差层:
class ResidualUnit(keras.layers.Layer):
def __init__(self, filters, strides=1, activation="relu", **kwargs):
super().__init__(**kwargs)
self.activation = keras.activations.get(activation)
self.main_layers = [ keras.layers.Conv2D(filters, 3, strides=strides,
padding="same", use_bias=False),
keras.layers.BatchNormalization(),
self.activation,
keras.layers.Conv2D(filters, 3, strides=1,
padding="same", use_bias=False),
keras.layers.BatchNormalization()]
self.skip_layers = []
if strides > 1:
self.skip_layers = [
keras.layers.Conv2D(filters, 1, strides=strides,
padding="same", use_bias=False),
keras.layers.BatchNormalization()]
def call(self, inputs):
Z = inputs
for layer in self.main_layers:
Z = layer(Z)
skip_Z = inputs
for layer in self.skip_layers:
skip_Z = layer(skip_Z)
return self.activation(Z + skip_Z)
然后就可以使用顺序模型构建ResNet-34,因为它实际上只是一个长的层序(我们可以将每个残差单元视为一个单层,现在我们有了残差单元类)。
model = keras.models.Sequential()
model.add(keras.layers.Conv2D(64, 7, strides=2, input_shape=[224, 224, 3],
padding="same", use_bias=False))
model.add(keras.layers.BatchNormalization())
model.add(keras.layers.Activation("relu"))
model.add(keras.layers.MaxPool2D(pool_size=3, strides=2, padding="same"))
prev_filters = 64
for filters in [64] * 3 + [128] * 4 + [256] * 6 + [512] * 3:
strides = 1 if filters == prev_filters else 2
model.add(ResidualUnit(filters, strides=strides))
prev_filters = filters
model.add(keras.layers.GlobalAvgPool2D())
model.add(keras.layers.Flatten())
model.add(keras.layers.Dense(10, activation="softmax"))
使用预训练的模型预测ImageNet图片
一般来说,前面所提及到的经典模型如GoogLeNet或ResNet等,这些都已经封装在keras里,只需要调用keras.applications包中使用一行代码即可 。
例如,可以加载ResNet-50模型,在Image Net上进行预训练,代码如下:
model = keras.applications.resnet50.ResNet50(weights="imagenet")
仅此而已! 这将创建一个ResNet-50模型,并下载在Image Net数据集上预先训练的权重。 要使用它,首先需要确保图像有正确的大小。 A Res Net-50模型使用224×224像素图像。所以要调整自己图片的大小:
images_resized = tf.image.resize(images, [224, 224])
每种经典模型的输入都是以特定方式进行预处理的,比如,有些会期望输入0到1,有些会期望输入-1到1。我们无需具体了解到底怎么缩放数据,只需要应用每个模型的preprocess_input()函数就可以得到对应模型的缩放方式的图片。至于为什么images_resized * 255,因为这个函数是处理像素值在0到255之间,所以我们必须将它们乘以255(因为我们早些时候将它们缩放到 0-1范围)
inputs = keras.applications.resnet50.preprocess_input(images_resized * 255)
那么现在我们就可以应用这个模型进行预测了。
Y_proba = model.predict(inputs)
和往常一样,输出Y_proba是一个矩阵,每个图像有一行,每个类有一列(在这种情况下,有1000个类)。
但如果你只想显示最上面的K预测,包括属于的类名以及每个预测类的估计概率,使用decode_predictions()函数。 对于每个图像,它返回一个包含顶部K个预测的数组, 其中,每个预测表示为包含类标识符的数组,其名称,以及相应的置信度分数:
top_K = keras.applications.resnet50.decode_predictions(Y_proba, top=3)
for image_index in range(len(images)):
print("Image #{}".format(image_index))
for class_id, name, y_proba in top_K[image_index]:
print(" {} - {:12s} {:.2f}%".format(class_id, name, y_proba * 100))
print()
这里表示输出前3个得分最高的:

使用预训练的模型来迁移学习
如果你想建立一个图像分类器,但你没有足够的训练数据,那么重用预先训练模型的下层通常是一个好主意。(这里的分类器不是用来分类ImageNet图片的)
首先下载数据集:
设置with_info=True.可以得到数据集的信息,得到数据大小和类名。
import tensorflow_datasets as tfds dataset,
info = tfds.load("tf_flowers", as_supervised=True, with_info=True)
dataset_size = info.splits["train"].num_examples # 3670
class_names = info.features["label"].names # ["dandelion", "daisy", ...]
n_classes = info.features["label"].num_classes # 5
但是,这个只生成了训练集,我们还需要分割得到测试集和验证集。Tensorflow提供了API可以在下载的时候直接分割:
分割比例如下所示:
test_split, valid_split, train_split = tfds.Split.TRAIN.subsplit([10, 15, 75])
test_set = tfds.load("tf_flowers", split=test_split, as_supervised=True)
valid_set = tfds.load("tf_flowers", split=valid_split, as_supervised=True)
train_set = tfds.load("tf_flowers", split=train_split, as_supervised=True)
假如本例重用的是Xception的网络结构,那么如前面提及的一样,需要对图片进行预处理。
定义一个预处理图片函数:
def preprocess(image, label):
resized_image = tf.image.resize(image, [224, 224])
final_image = keras.applications.xception.preprocess_input(resized_image)
return final_image, label
然后将训练集和测试集和验证集都进行图片预处理,并应用了批次和预取。
batch_size = 32
train_set = train_set.shuffle(1000) #对训练集洗牌
train_set = train_set.map(preprocess).batch(batch_size).prefetch(1)
valid_set = valid_set.map(preprocess).batch(batch_size).prefetch(1)
test_set = test_set.map(preprocess).batch(batch_size).prefetch(1)
另外,如果你想数据增强,可以使用ImageDataGenerator类来对图片旋转,平移和放缩等等操作。
然后我们可以直接加载Xception结构,我们通过设置include_top=false丢弃掉Xception模型的顶层,然后再自己添加顶层进入自己的模型:
这里使用的是函数式API构建自己的模型。
base_model = keras.applications.xception.Xception(weights="imagenet",include_top=False)
avg = keras.layers.GlobalAveragePooling2D()(base_model.output)
output = keras.layers.Dense(n_classes, activation="softmax")(avg)
model = keras.Model(inputs=base_model.input, outputs=output)
然后在训练前几个epoch中冻结预训练层使预训练层的权重不变,然后使新添加的层获得权重(前面chapter11的迁移学习应用中有提及)
for layer in base_model.layers:
layer.trainable = False
optimizer = keras.optimizers.SGD(lr=0.2, momentum=0.9, decay=0.01)
model.compile(loss="sparse_categorical_crossentropy",
optimizer=optimizer, metrics=["accuracy"])
history = model.fit(train_set, epochs=5, validation_data=valid_set)
然后解冻重用层并编译和训练:
for layer in base_model.layers:
layer.trainable = True
optimizer = keras.optimizers.SGD(lr=0.01, momentum=0.9, decay=0.001)
model.compile(loss="sparse_categorical_crossentropy",
optimizer=optimizer, metrics=["accuracy"])
history = model.fit(train_set, epochs=30, validation_data=valid_set)