SEnet注意力机制(逐行代码注释讲解)
目录
⒈结构图
⒉机制流程讲解
⒊源码(pytorch框架实现)及逐行解释
⒋测试结果
⒈结构图
左边是我自绘的,右下角是官方论文的。
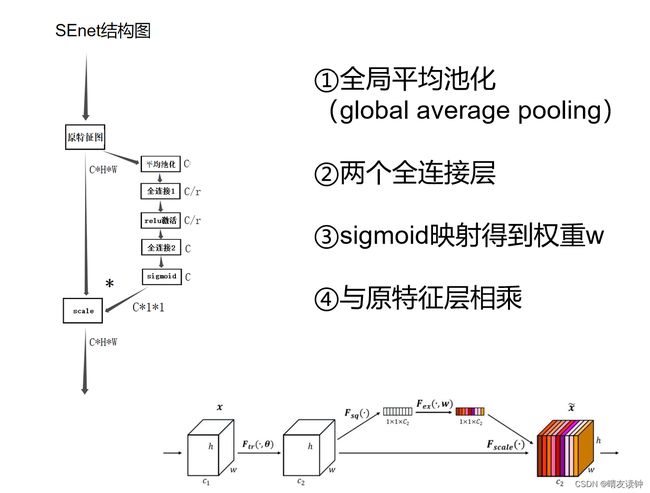
⒉机制流程讲解
通道注意力机制的思想是,对于输入进来的特征层,我们在每一个通道学习不同的权重,这些权重与不同通道的特征相关,决定了每个通道在任务中的重要性。
对于SENet而言,它会对输入特征层进行这些操作:
①首先对输入特征层做了global average pooling,也就是全局平均池化,全局平均池化将对当前特征层取平均值,显然,高、宽分别为H、W的特征层经过平均池化操作后会得到一个实数,这个实数就是所有输入特征层的平均值;另外,平均池化并不影响通道数,因此,输入为C*H*W的特征经过平均池化后,H和W两个维度被压缩,就将得到只剩下C(也就是通道数)这一个维度的特征层。
②然后,对于平均池化输出的矩阵,进行两次全连接,第一次全连接和第二次是不完全相同的,区别在于:第一次全连接的通道数不完整,而是取原通道数的1/r,也就是这边的C/r,第二次则是用正常的通道数进行全连接。
这样做的目的是——能够减少通道个数从而降低计算量,并在一定程度上防止网络模型过拟合。(我在学习SEnet的结构时,看到第一次全连接减少通道数这个操作时,就有联想到神经网络的另一个trick,叫做dropout,dropout是一种正则化技巧,通过随机让神经网络中的部分神经元暂时失活,从而减少模型的过拟合风险,当时我以为SEnet的第一个全连接层就是运用了这个trick,但后来查阅资料时发现不是这样,dropout是随机减少全连接层中的部分神经元,而SEnet在这里是固定减少特征图的通道数,只能说有些异曲同工之妙吧),刚刚是在分享我学习过程遇到的小问题,现在说回正题,全连接1只取原通道数的1/r以此来减少计算量与防止过拟合,但是全连接2又用回原通道数——这样做是为了输出与原特征层相同的通道数,以便后续的最重要的reweight操作,也就是通过乘法逐通道加权到原先的输入特征层上。
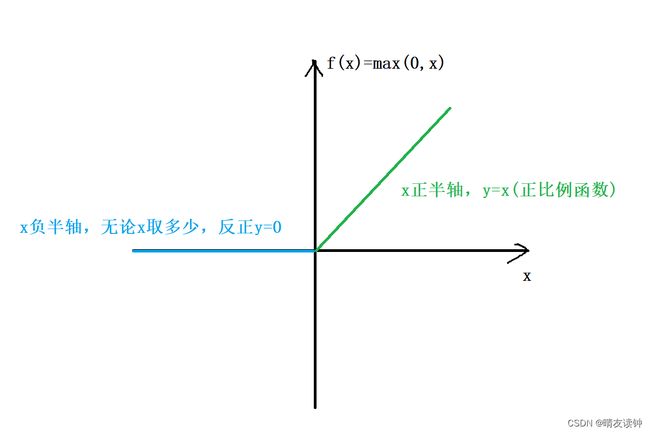
值得注意的是,两个全连接层不是简单的直接相连,而是在全连接1后面经过一个relu激活函数,这是全连接层中很常规的操作,用来对一个全连接层的输出结果进行非线性变换,如果不这样做,所有的全连接层都只是普通的线性组合,这样训练出来的模型无法理解复杂的非线性数据和特征,可想而知这样的模型的检测效果肯定是很差的。
relu激活函数的公式其实很简单:f(x) = max(0, x),在x大于等于零时是线性函数,但当输入为负数时,输出为零,在负数部分截断了线性部分,将其映射到了一个确定的点上,从而实现了非线性变换。
自绘烂图,将就看。
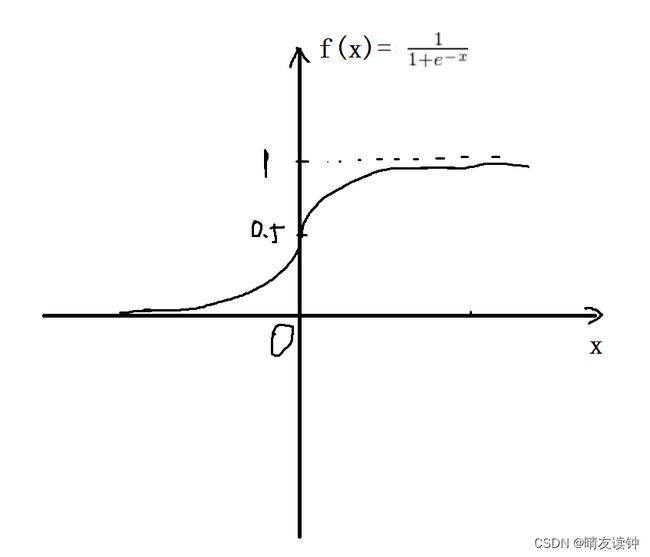
③再然后,需要对全连接2的输出结果映射到sigmoid函数中,sigmoid是很经典的激活函数,它的值域是0到1,画一下函数图像(显然x=0时函数值等于0.5)……然后,它的定义域是整个实数集,值域是0到1,也就是说,全连接2的输出结果映射到sigmoid函数中后,就将得到一组0到1之间的值(因此称此操作为归一化),也就是所谓的不同通道的权重。
公式:
自绘烂图,我真的尽力画了/(ㄒoㄒ)/~~
最后最后,将这组通道权重与原输入2特征层通过乘法逐通道加权,就实现了“增强重要的通道,抑制不重要的通道”,也就是所谓的通道注意力机制
⒊源码(pytorch框架实现)及逐行解释
import torch
from torch import nn
from torchsummary import summary
class SEAttention(nn.Module):
def __init__(self, inputs, ratio=4):
super(SEAttention, self).__init__() # 调用父类构造方法
_, c, _, _ = inputs.size()# NCHW
self.avgpool = nn.AdaptiveAvgPool2d(1)
self.linear1 = nn.Linear(c, c // ratio, bias=False)
self.relu = nn.ReLU(inplace=True)
self.linear2 = nn.Linear(c // ratio, c, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, inputs):
n, c, _, _ = inputs.size()
x = self.avgpool(inputs).view(n, c)#nchw,池化加reshape压缩维度
x = self.linear1(x)
x = self.relu(x)
x = self.linear2(x)
x = self.sigmoid(x)
x = x.view(n, c, 1, 1) #reshape还原维度
return inputs * x
#这边是测试代码,用summary类总结网络模型层
inputs = torch.randn(32, 512, 26, 26) # NCHW
my_model = SEAttention(inputs)
outputs = my_model(inputs)
summary(my_model.cuda(), input_size=(512, 26, 26))解释:
①依赖包为torch,以及torch里的nn模块(导入这个纯粹是省得还要用torch.nn去调用nn的类或方法),summary类是用来测试的,需要提前下载,命令为->pip install torchsummary
②从整体来看,我们运用封装思想将整个模块封装为类,且这个类继承于nn.Moudule这个类,这个类共两部分,
__init__函数用来对实例化对象进行初始化,在python中这个函数属于类的魔术方法。
#代码逐行解释:
def __init__(self, inputs, ratio=4):#self必须写,inputs接收输入张量,ratio是通道衰减因子
super(SEAttention, self).__init__() # super关键字调用父类(即nn.Moudule类)的构造方法
_, c, _, _ = inputs.size()#获取张量的形状(即NCHW),该模块只关注参数C,其余用占位符忽略
self.avgpool = nn.AdaptiveAvgPool2d(1)#nn模块的自适应二维平均池化,参数1等同于全局平均池化
self.linear1 = nn.Linear(c, c // ratio, bias=False)#nn模块的全连接,这里输入c,输出c//ratio,bias是偏置参数,网络层是否有偏置,默认存在,若bias=False,则该网络层无偏置,图层不会学习附加偏差
self.relu = nn.ReLU(inplace=True)#nn模块的ReLU激活函数,inplace=True表示要用引用传递(即地址传递),估计可以减少张量的内存占用(因为值传递要拷贝一份)
self.linear2 = nn.Linear(c // ratio, c, bias=False)#同全连接1,但输入输出相反
self.sigmoid = nn.Sigmoid()#nn模块的Sigmoid函数forward函数进行前向传播,用初始化好的网络模型对输入特征层进行一系列加工。
#代码逐行解释:
def forward(self, inputs):#self必须写,inputs接收输入特征张量
n, c, _, _ = inputs.size()#获取张量形状(即NCHW),HW被忽略
x = self.avgpool(inputs).view(n, c)#nchw,池化加view方法重塑(reshape)张量形状,因为全连接层之间的张量必须是二维的(一个输入维度一个输出维度),view的参数是(n,c)表示只保留这两个维度
x = self.linear1(x)
x = self.relu(x)
x = self.linear2(x)
x = self.sigmoid(x)#上面这四行直接调用初始化好的网络层即可
x = x.view(n, c, 1, 1) #reshape还原维度,因为要和原输入特征相乘,不重塑形状不同无法相乘
return inputs * x#和原输入特征层相乘⒋测试结果
感觉summary类没有很好使。。。有些关键网络层的变换没有体现出来,这里是少了最后reshape的一层,但无伤大雅罢!
