SENET论文笔记注意力机制
SENet论文笔记 注意力机制
Squeeze-and-Excitation Networks 2019
Abstract
- 传统卷积都是在特征层级上通过提高空间编码质量提高表示能力
- SENet注重通道关系,自适应地调整通道方向特征图权重,显示构造通道间的相互关系
- 结合SE模块表现表现变好,计算量增加一点点。
Introduction
- 15年左右的模型用局部感受野同时融合空间和通道信息
- 之后提出的Inception结构帮助捕捉特征之间的空间相关性(融合大小感受野?)
- 之后的模型提出空间注意力
SE block基于通道之间的关系,通过显示调整卷积特征通道的相互依赖关系提升网络的表示能力。
特征重标定:让网络能学习使用全局信息来选择性提升有用的特征,并抑制没用的特征。
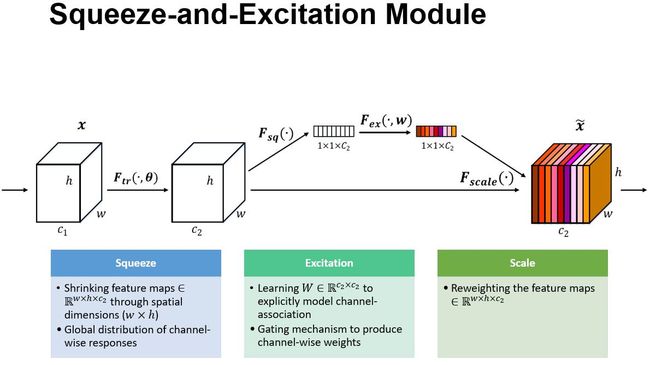
首先Ftr(transform)这一步是转换操作(原网络)将输入X映射为特征图U:
F t r : X → U , X ∈ R H ′ × W ′ × C ′ , U ∈ R H × W × C \mathbf{F}_{t r}: \mathbf{X} \rightarrow \mathbf{U}, \mathbf{X} \in \mathbb{R}^{H^{\prime} \times W^{\prime} \times C^{\prime}}, {\mathbf{U}} \in \mathbb{R}^{H \times W \times C} Ftr:X→U,X∈RH′×W′×C′,U∈RH×W×C
特征调整(重标定):特征图U首先经过squeeze操作
squeeze通过聚合特征图空间维度(GAP)产生通道 descriptor
The function of this descriptor is to produce an embedding of the global distribution of channel-wise feature responses, allowing information from the global receptive field of the network to be used by all its layers.
聚合操作和采用excitation操作(FC*2) ,产生每个通道的权重,权重scale U,获得SE block的输出。
- SEblock很容易整合到一系列结构里。
- SEblock在网络前期(前几层)共享低维度的表征。后面几层seblock变得高度具体化,即对图片中不同的类别会有不同。
- SEblock超参数少,可以直接结合到现有的模型里,只会略微增加计算量。
SQUEEZE-AND-EXCITATION BLOCKS
Ftr的公式就是下面的公式1(卷积操作,vc表示第c个卷积核,xs表示第s个输入 ,后面求和操作就是卷积计算里的相加)
u c = v c ∗ X = ∑ s = 1 C ′ v c s ∗ x s \mathbf{u}_{c}=\mathbf{v}_{c} * \mathbf{X}=\sum_{s=1}^{C^{\prime}} \mathbf{v}_{c}^{s} * \mathbf{x}^{s} uc=vc∗X=s=1∑C′vcs∗xs
Ftr得到的U就是第二个三维矩阵,C个大小为H*W的feature map(也叫tensor)。而uc表示U中第c个二维矩阵,下标c表示channel。
squeeze操作 :global average pooling,将H * W * C的输入转换成1 * 1 * C的输出,表示全局信息。
z c = F s q ( u c ) = 1 H × W ∑ i = 1 H ∑ j = 1 W u c ( i , j ) z_{c}=\mathbf{F}_{s q}\left(\mathbf{u}_{c}\right)=\frac{1}{H \times W} \sum_{i=1}^{H} \sum_{j=1}^{W} u_{c}(i, j) zc=Fsq(uc)=H×W1i=1∑Hj=1∑Wuc(i,j)
Excitation操作 :
s = F e x ( z , W ) = σ ( g ( z , W ) ) = σ ( W 2 δ ( W 1 z ) ) \mathbf{s}=\mathbf{F}_{e x}(\mathbf{z}, \mathbf{W})=\sigma(g(\mathbf{z}, \mathbf{W}))=\sigma\left(\mathbf{W}_{2} \delta\left(\mathbf{W}_{1} \mathbf{z}\right)\right) s=Fex(z,W)=σ(g(z,W))=σ(W2δ(W1z))
前面squeeze得到的结果是z,这里先用W1乘以z,就是一个全连接层操作,
W1(权重矩阵)的维度是C/r * C,z的维度是1 * 1 * C
r是一个缩放参数,经过实验得出16,这个参数的目的是为了减少channel个数从而降低计算量
所以W1z的结果就是1 * 1 * C/r;然后再经过一个ReLU层,输出的维度不变;然后再和W2相乘,和W2相乘也是一个全连接层的过程, W2(权重矩阵)的维度是C * C/r,因此输出的维度就是1 * 1*C;最后再经过sigmoid函数,得到s
s表示了U中C个feature map的权重。
**scale操作:**每个通道对应相乘
x ~ c = F scale ( u c , s c ) = s c ⋅ u c \tilde{\mathbf{x}}_{c}=\mathbf{F}_{\text {scale }}\left(\mathbf{u}_{c}, s_{c}\right)=s_{c} \cdot \mathbf{u}_{c} x~c=Fscale (uc,sc)=sc⋅uc
Instantiations
左边是融合到Inception里,直接对inception输出scale,右边是融合到残差链接相加前scale。
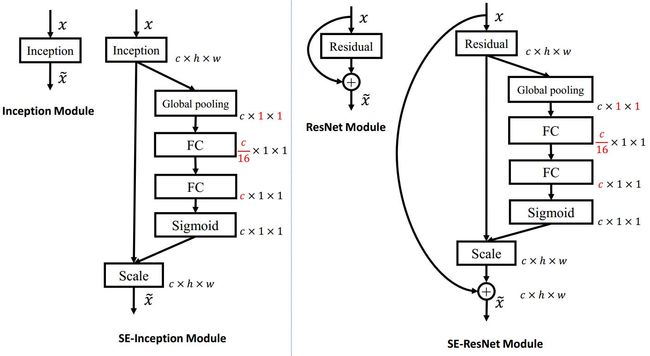
使用 global average pooling 作为 Squeeze 操作。紧接着两个 Fully Connected 层组成一个 Bottleneck 结构去建模通道间的相关性,并输出和输入特征同样数目的权重。我们首先将特征维度降低到输入的 1/16,然后经过 ReLu 激活后再通过一个 Fully Connected 层升回到原来的维度。这样做比直接用一个 Fully Connected 层的好处在于:
- 具有更多的非线性,可以更好地拟合通道间复杂的相关性;
- 极大地减少了参数量和计算量。然后通过一个 Sigmoid 的门获得 0~1 之间归一化的权重,最后通过一个 Scale 的操作来将归一化后的权重加权到每个通道的特征上。
如果对 Addition 后主支上的特征进行重标定,由于在主干上存在 0~1 的 scale 操作,在网络较深 BP 优化时就会在靠近输入层容易出现梯度消散的情况。(后面实验了SEblock放置的位置对结果的影响)
MODEL AND COMPUTATIONAL COMPLEXITY
SEblock平衡了提升和计算量。

增加的参数主要来自两个FC,两个FC层的维度都是C/r * C,那么这两个全连接层的参数量就是2*C^2/r。以ResNet为例,假设ResNet一共包含S个stage,每个Stage包含N个重复的residual block,那么整个添加了SE block的ResNet增加的参数量就是下面的公式:
2 r ∑ s = 1 S N s ⋅ C s 2 \frac{2}{r} \sum_{s=1}^{S} N_{s} \cdot C_{s}{ }^{2} r2s=1∑SNs⋅Cs2
Experiments
ImageNet测试
模型:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vvGB9oBJ-1670230634557)(C:\Users\86188\Pictures\tabel1.png)]
single-crop不同深度不同类型的SENet和准确率,GFLOPS:准确率更高,而计算复杂度上只是略有提升
original是原论文给的,re-implementation是他们自己跑的最好结果
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5Ygha2Rf-1670230634558)(https://pic1.zhimg.com/80/v2-428df581957e74127e9ebc9ce4f6f0b0_720w.jpg)]
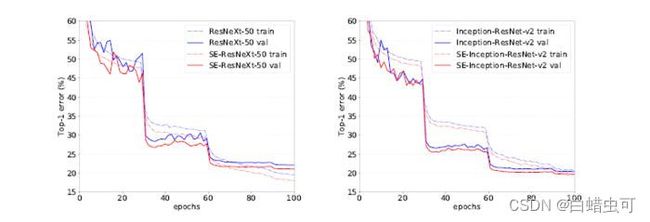
不同深度的SE-ResNet和ResNet的训练曲线图

ResNeXt和SE-ResNeXt、Inception-ResNet-v2和SE-Inception-ResNet-v2的收敛曲线
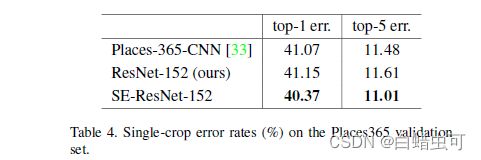
场景分类测试
数据集place365比较的结构是ResNet-152和SE-ResNet-152,可以看出SENet在ImageNet以外的数据集上仍有优势
其他测试
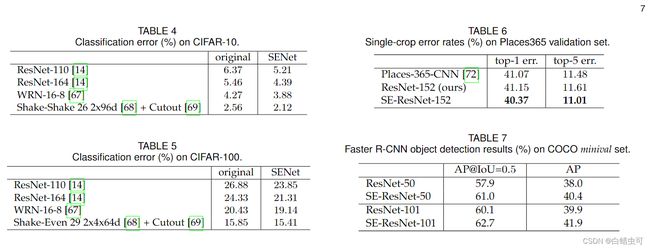

消融实验
Squeeze Operator,
用了GAP和GMP,GAP更好其他的没考虑。table11
Excitation Operator
把sigmoid换成ReLu,Tanh。table12
We see that exchanging the sigmoid for tanh slightly worsens performance, while using ReLU is dramatically worse and in fact causes the performance of SE-ResNet-50 to drop below that of the ResNet-50 baseline.
Different stages
在resnet不同stage融合SE,都能提升精度,所有都加提升最大。

Integration strategy
将SE融合位置改变:table14
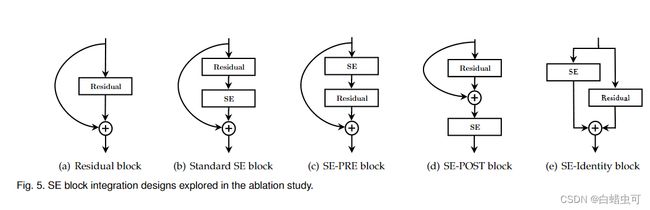
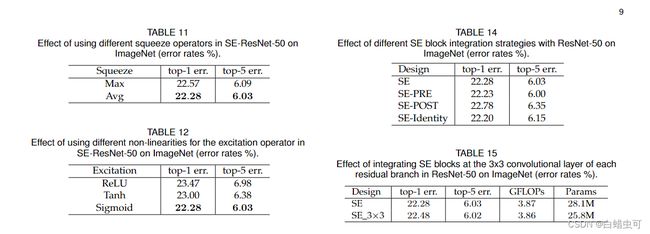
ROLE OF SE BLOCKS
Effect of Squeeze
we experiment with a variant of the SE block that adds an equal number of parameters, but does not perform global average pooling.
就是把pooling去掉换成两个c和原来输出相同的1*1卷积层,效果比SE差一点。
he SE block allows this global information to be used in a computationally parsimonious (简约的)manner
pooling删了就不能用FC
Role of Excitation
这里没删掉Excitation,探究的是scale时的权重分布。
不同层级的scale的分布:可以看出靠前的层级(SE_2_3和SE_3_4)各个分类的曲线差异不大,这说明了在较低的层级中scale的分布和输入的类别无关;
随着层级的加深,不同类别的曲线开始出现了差别(SE_4_6和SE_5_1),这说明靠后的层级的scale大小和输入的类别强相关;到了SE_5_2后几乎所有的scale都饱和,输出为1,只有一个通道为0;而最后一层SE_5_3的通道的scale基本相同。
最后两层的scale因为基本都相等,就没有什么用处了,为了节省计算量可以把它们去掉。

My Conclusion
- 动态变化的思想很重要
- 通道间相关性除了深度可分离卷积还可以用权重分配,根据类别动态调整