Maxcompute 小记1
目录
1、关于NULL值排序
2、合并小文件 手动合并
3、排除某个不想要的字段
4、bigint和string关联
5、sum() over() --级联求和
6、lag() over() --(取出前n行数据)
7、一次奇葩的数据倾斜 调优经历\
1、关于NULL值排序
①HIVE
时间类型:
SELECT id
FROM (
SELECT GETDATE() id
UNION
SELECT NULL id
UNION
SELECT TO_DATE('20211101','yyyymmdd') id
) t
ORDER BY id ASC
;
结果:
+------------+
| id |
+------------+
| NULL |
| 2021-11-01 00:00:00 |
| 2021-12-03 16:36:06 |
数值类型:
SELECT id
FROM (
SELECT 1 id
UNION
SELECT NULL id
UNION
SELECT 2 id
) t
ORDER BY id ASC
;
结果:
+------------+
| id |
+------------+
| NULL |
| 1 |
| 2 |
+------------+
字符类型:
SELECT id
FROM (
SELECT '张王' id
UNION
SELECT NULL id
UNION
SELECT '李赵' id
) t
ORDER BY id ASC
;
结果:
+----+
| id |
+----+
| NULL |
| 张王 |
| 李赵 |
+----+
②Mysql
时间类型:
select
id from
(select now() id
union
select null id
) t order by id asc;
结果:
\N
2021-12-03 16:40:44
数值类型:
select
id from
(select 1 id
union
select null id
union
select 2 id
) t order by id asc;
结果:
\N
1
2
字符类型:
SELECT id
FROM (
SELECT '张王' id
UNION
SELECT NULL id
UNION
SELECT '李赵' id
) t
ORDER BY id ASC
;
结果:
\N
张王
李赵③Oracle
在Oracle数据库数据处理的SQL语句中,当表的排序列中含有null或者''时,缺省Oracle在Order by 时缺省认为null是最大值,所以如果是ASC升序则排在最后,DESC降序则排在最前。
如果你没有对null或''做处理时,这时做降序排序时,就会发现null或''是排在最前位的;做升序排序时,会发现null或''是排在最后位的。
nulls first和nulls last是Oracle Order by支持的语法,
如果order by 中指定了表达式Nulls first,则表示null值的记录将排在最前(不管是asc 还是 desc)
如果order by 中指定了表达式Nulls last,则表示null值的记录将排在最后(不管是asc 还是 desc)
2、合并小文件 手动合并
报错:FAILED: ODPS-0420061: Invalid parameter in HTTP request - Read table timeout. Maybe too many files to open. Please try to merge files or get the data with ODPS data export service.
set odps.merge.max.filenumber.per.job=50000; --值默认为50000个;当分区数大于50000时需要调整,最大可到1000000万,大于1000000的提交多次merge
ALTER TABLE 表名[partition] MERGE SMALLFILES;
desc extended 【table_name】;
set odps.merge.cross.paths=true;
set odps.idata.useragent=SRE Merge;
set odps.merge.max.filenumber.per.job=10000000;
set odps.merge.max.filenumber.per.instance=10000;
set odps.merge.failure.handling=any;
set odps.merge.cpu.quota=75;
set odps.merge.maintain.order.flag=true;
set odps.merge.smallfile.filesize.threshold=4096;
set odps.merge.quickmerge.flag=false;
set odps.merge.maxmerged.filesize.threshold=4096;
set odps.merge.restructure.action=rename;
ALTER TABLE【table_name】[partition] MERGE SMALLFILES;
3、排除某个不想要的字段
首先需要设置一个参数:
set hive.support.quoted.identifiers=None;
然后指定要剔除哪个字段:
insert overwrite table test partition(data_date=20211121)
select `(data_date)?+.+` from dm.dm_user_add ;
剔除多个字段:
## 最好按照字段顺序来写,遇到字段未过滤的时候把字段顺序换一下试试 select `(dateline|data_date)?+.+` from dm.dm_user_add
4、bigint和string关联
在maxcompute中,两个表进行join,on条件两表的字段含义一致(都是整数),但数据类型不一致:string和bigint。join后发现如果数值过大则匹配的记录会出现问题:一条记录会匹配出多条记录(explain可以发现都转换为double)
如:190000000002778025,就会错误的匹配上*8023 ,*8025
EXPLAIN
SELECT
COUNT(DISTINCT b.id)
FROM
(SELECT cast(190000000002778025 as bigint) id
) a
JOIN
(SELECT cast('190000000002778024 ' as DOUBLE ) id ) b
ON a.id=b.id
;Job Queueing...
job0 is root job
In Job job0:
root Tasks: M1
R2 depends on: M1
J3 depends on: R2
R4 depends on: J3
R5 depends on: R4
In Task M1:
VALUES: : {}
RS: valueDestLimit: 0
dist: HASH
keys:
values:
partitions:
In Task R2:
SEL:
RS: valueDestLimit: 0
dist: BROADCAST
keys:
values:
partitions:
In Task J3:
VALUES: : {}
HASHJOIN:
Values1 INNERJOIN StreamLineRead2
keys:
0:
1:
filters:
0:EQ(TODOUBLE(190000000002778025L),1.90000000002778016E17)
1:
non-equals:
0:
1:
bigTable: Values1
SEL: 1.90000000002778016E17 id0
AGGREGATE:
UDAF: COUNT(DISTINCTid0)[Deduplicate] __agg_0
RS: order: +
nullDirection: *
optimizeOrderBy: False
valueDestLimit: 0
dist: HASH
keys:
id0
values:
id0 (double)
partitions:
id0
In Task R4:
AGGREGATE:
UDAF: COUNT(DISTINCTid0) (__agg_0_count)[Partial_1]
RS: valueDestLimit: 0
dist: HASH
keys:
values:
__agg_0_count (bigint)
partitions:
In Task R5:
AGGREGATE:
UDAF: COUNT(__agg_0_count)[Final] __agg_0
SEL: __agg_0 _c0
FS: output: Screen
schema:
_c0 (bigint)
OKa)原因:Java中精度只有15至16位,当数据超过精度就会不准——也就会出现超过精度的记录join上许多不一致的记录。
bigint和string比较时会隐式地都转换成double,java中double的精度只有15-16位(double可以精确的表示小于2^52=4503599627370496的数字)。当数字超过精度的时候就会比较不准确,出现上面描述的现象。
b)解决方法:建议将string转换为bigint~ cast(c as bigint) 后再进行比较。
5、sum() over() --级联求和
数据准备
| A,2020-01,15 A,2020-02,19 A,2020-03,12 A,2020-04,5 A,2020-05,29 B,2020-01,8 B,2020-02,6 B,2020-03,13 B,2020-04,5 B,2020-05,24 C,2020-01,16 C,2020-02,2 C,2020-03,33 C,2020-04,51 C,2020-05,54 |
建表
| create table wedw_tmp.t_sum_over( user_name string COMMENT '姓名' ,month_id string COMMENT '月份' ,sale_amt int COMMENT '销售额' ) row format delimited fields terminated by ','; |
对于每个人的一个月的销售额和累计到当前月的销售总额
| select user_name ,month_id ,sale_amt ,sum(sale_amt) over(partition by user_name order by month_id rows between unbounded preceding and current row) as all_sale_amt from wedw_tmp.t_sum_over; |
6、lag() over() --(取出前n行数据)
数据准备
| create table t_hosp( user_name string ,age int ,in_hosp date ,out_hosp date) row format delimited fields terminated by ','; xiaohong,25,2020-05-12,2020-06-03 xiaoming,30,2020-06-06,2020-06-15 xiaohong,25,2020-06-14,2020-06-19 xiaoming,30,2020-06-20,2020-07-02 user_name:用户名 age:年龄 in_hosp:住院日期 out_hosp:出院日期 |
需求:求同一个患者每次住院与上一次出院的时间间隔
第一步:
| select user_name ,age ,in_hosp ,out_hosp ,LAG(out_hosp,1,in_hosp) OVER(PARTITION BY user_name ORDER BY out_hosp asc) AS pre_out_date from t_hosp ; 其中,LAG(out_hosp,1,in_hosp) OVER(PARTITION BY user_name ORDER BY out_hosp asc) 表示根据user_name分组按照out_hosp升序取每条数据的上一条数据的out_hosp, 如果上一条数据为空,则使用默认值in_hosp来代替 |
结果:

第二步:每条数据的in_hosp与pre_out_date的差值即本次住院日期与上次出院日期的间隔
| select user_name ,age ,in_hosp ,out_hosp ,datediff(in_hosp,LAG(out_hosp,1,in_hosp) OVER(PARTITION BY user_name ORDER BY out_hosp asc)) as days from t_hosp ; |
结果:


7、一次奇葩的数据倾斜 调优经历
①背景:在为用户画像建立roalling bitmap时,进行数仓映射表数据转换;
建表:
-- SET odps.sql.type.system.odps2=TRUE;
-- create TABLE tt_sl_v_bitmap_a_d(
-- u_id INT COMMENT '用户唯一ID,新用户自增',
-- v_id INT COMMENT '车VIN唯一ID,新增VIN自增',
-- tag_id BIGINT COMMENT '标签ID',
-- tag_value STRING COMMENT '标签值'
-- ) COMMENT '车标签bitmap表'
-- PARTITIONED BY (
-- data_date STRING COMMENT '日分区'
-- ,tag_type STRING COMMENT '标签分类'
-- )
-- ;
--一部分是不编码的标签
SET odps.sql.type.system.odps2=TRUE;
INSERT OVERWRITE TABLE tt_sl_v_bitmap_a_d PARTITION(data_date=${bizdate},tag_type='code_N')
SELECT
B.u_id
,A.v_id
,cast(A.tag_id as BIGINT )
,A.tag_value_code
FROM
( SELECT *
FROM
tm_tag_userprofile_vehicle_all_d_bak t
WHERE data_date=${bizdate}
AND (tag_value_code is not NULL OR TRIM(tag_value_code)!='' or LENGTH(tag_value_code)!=0)
AND EXISTS (
SELECT 1 FROM dim_tags_detail tt
WHERE data_date=max_pt('dim_tags_detail')
AND if_coded='N'
AND theme = '100052'
AND t.tag_id=tt.tag_id
)
) A
LEFT JOIN (
SELECT *
FROM tt_sl_u_v_relationship_a_d
WHERE data_date = ${bizdate}
) B
ON A.vin = B.vin
;
--一部分是编码的标签
SET odps.sql.type.system.odps2=TRUE;
INSERT OVERWRITE TABLE tt_sl_v_bitmap_a_d PARTITION(data_date=${bizdate},tag_type='code_Y')
SELECT
C.u_id
,A.v_id
,cast(A.tag_id as BIGINT )
,B.tag_value_code
FROM
( SELECT *
FROM
tm_tag_userprofile_vehicle_all_d_bak t
WHERE data_date=${bizdate}
AND (tag_value_code is not NULL OR TRIM(tag_value_code)!='' or LENGTH(tag_value_code)!=0)
AND EXISTS (
SELECT 1 FROM dim_tags_detail tt
WHERE data_date=max_pt('dim_tags_detail')
AND if_coded='Y'
AND theme = '100052'
AND t.tag_id=tt.tag_id
)
) A
JOIN (
SELECT *
FROM tt_sl_dim_tag_category_d
WHERE data_date = ${bizdate}
) B
ON A.tag_value_code = B.tag_value
AND A.tag_id = B.tag_id
LEFT JOIN (
SELECT *
FROM tt_sl_u_v_relationship_a_d
WHERE data_date = ${bizdate}
) C
ON A.vin = C.vin
;
建表2:
-- set odps.sql.type.system.odps2=true;
-- CREATE TABLE tt_sl_v_bitmap_ulist_a_d
-- (tag_id BIGINT
-- ,tag_value STRING
-- ,userlist ARRAY
-- ,carlist ARRAY
-- )
-- PARTITIONED BY (data_date STRING , type STRING );
映射表生成逻辑:
set odps.sql.type.system.odps2=true;
INSERT OVERWRITE TABLE tt_sl_v_bitmap_ulist_a_d PARTITION (data_date=${bizdate},type='1')
SELECT tag_id
,tag_value
,collect_set(nvl(u_id,-1)) ulist
,collect_set(nvl(v_id,-1)) vlist
FROM tt_sl_v_bitmap_a_d
WHERE data_date = 20220417
GROUP BY tag_id
,tag_value
;
此时竟然出现了OOM, 按道理不会发生,实际上是有4个节点长尾了;所以进行漫长的数据倾斜治理工作
优化过程:
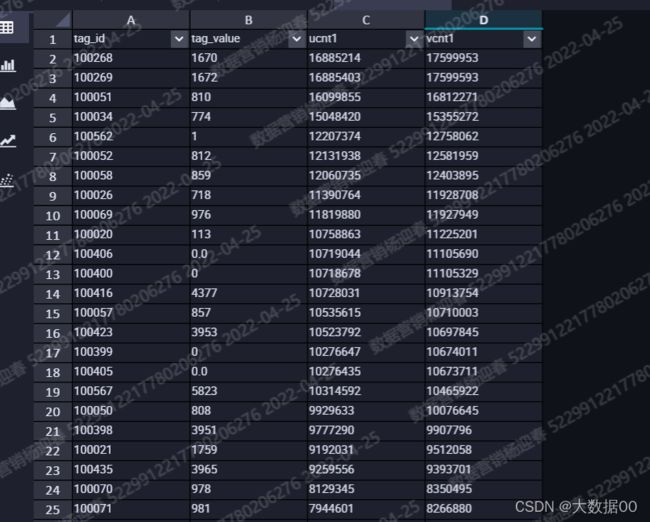
①检查key值数量
SELECT tag_id
,tag_value
,SUM(ucnt) ucnt1
,SUM(vcnt) vcnt1
FROM (
SELECT tag_id
,tag_value
,randk
,COUNT(DISTINCT u_id) ucnt
,COUNT(DISTINCT v_id) vcnt
FROM (
SELECT tag_id
,tag_value
,u_id
,v_id
,floor(RAND()*100) randk --0-100
FROM tt_sl_v_bitmap_a_d
WHERE data_date = 20220417
) t1
GROUP BY tag_id
,tag_value
,randk
) t2
GROUP BY tag_id
,tag_value
ORDER BY vcnt1 DESC
,ucnt1 DESC
;
SELECT COUNT(DISTINCT tag_id,tag_value) from tt_sl_v_bitmap_ulist_a_d;
key 大于1000万的有20个,小于1000万的有22512020
②尝试调优,两个方向A、拆分处理 B、尝试分桶增加task数量
考虑到拆分处理 只要拆分的够细,肯定可以解决,所以优先尝试了分桶
过程:
a、建分桶表
-- SET odps.sql.type.system.odps2=TRUE;
-- create TABLE tt_sl_v_bitmap_a_d(
-- u_id INT COMMENT '用户唯一ID,新用户自增',
-- v_id INT COMMENT '车VIN唯一ID,新增VIN自增',
-- tag_id BIGINT COMMENT '标签ID',
-- tag_value STRING COMMENT '标签值'
-- ) COMMENT '车标签bitmap表'
-- PARTITIONED BY (
-- data_date STRING COMMENT '日分区'
-- ,tag_type STRING COMMENT '标签分类'
-- ) CLUSTERED BY (tag_id,tag_value) INTO 1024 BUCKETS
-- ;
b、写数据
--一部分是不编码的标签
SET odps.sql.type.system.odps2=TRUE;
INSERT OVERWRITE TABLE tt_sl_v_bitmap_a_d PARTITION(data_date=${bizdate},tag_type='code_N')
SELECT
B.u_id
,A.v_id
,cast(A.tag_id as BIGINT )
,A.tag_value_code
FROM
( SELECT *
FROM
tm_tag_userprofile_vehicle_all_d_bak t
WHERE data_date=${bizdate}
AND (tag_value_code is not NULL OR TRIM(tag_value_code)!='' or LENGTH(tag_value_code)!=0)
AND EXISTS (
SELECT 1 FROM dim_tags_detail tt
WHERE data_date=max_pt('dim_tags_detail')
AND if_coded='N'
AND theme = '100052'
AND t.tag_id=tt.tag_id
)
) A
LEFT JOIN (
SELECT *
FROM tt_sl_u_v_relationship_a_d
WHERE data_date = ${bizdate}
) B
ON A.vin = B.vin
;
--一部分是编码的标签
SET odps.sql.type.system.odps2=TRUE;
INSERT OVERWRITE TABLE tt_sl_v_bitmap_a_d PARTITION(data_date=${bizdate},tag_type='code_Y')
SELECT
C.u_id
,A.v_id
,cast(A.tag_id as BIGINT )
,B.tag_value_code
FROM
( SELECT *
FROM
tm_tag_userprofile_vehicle_all_d_bak t
WHERE data_date=${bizdate}
AND (tag_value_code is not NULL OR TRIM(tag_value_code)!='' or LENGTH(tag_value_code)!=0)
AND EXISTS (
SELECT 1 FROM dim_tags_detail tt
WHERE data_date=max_pt('dim_tags_detail')
AND if_coded='Y'
AND theme = '100052'
AND t.tag_id=tt.tag_id
)
) A
JOIN (
SELECT *
FROM tt_sl_dim_tag_category_d
WHERE data_date = ${bizdate}
) B
ON A.tag_value_code = B.tag_value
AND A.tag_id = B.tag_id
LEFT JOIN (
SELECT *
FROM tt_sl_u_v_relationship_a_d
WHERE data_date = ${bizdate}
) C
ON A.vin = C.vin
;
c、写入映射表
set odps.sql.type.system.odps2=true;
set odps.sql.groupby.skewindata = TRUE ; --设置是否开启groupby防倾斜机制。
set odps.stage.mapper.split.size = 128;
set odps.sql.reducer.instances=1024;
INSERT OVERWRITE TABLE tt_sl_v_bitmap_ulist_a_d PARTITION (data_date=${bizdate},type='1')
SELECT tag_id
,tag_value
,collect_set(nvl(u_id,-1)) ulist
,collect_set(nvl(v_id,-1)) vlist
FROM tt_sl_v_bitmap_a_d
WHERE data_date = 20220417
GROUP BY tag_id
,tag_value
;
通过以上调优,这个问题竟然完美的解决了
思考:为什么增加分桶,增加reduce task数量会解决倾斜问题?
合理设置分桶,提高数据并行度,增加reducetask数量可以尝试进行调优,数据倾斜的处理办法有很多,工作中遇到并解决是一件快乐的事
Hive调优,数据工程师成神之路
大数据常见问题:数据倾斜的原理及处理方案_徐凤年不是真无敌的博客-CSDN博客_大数据 数据倾斜
holo部分:
-- DROP TABLE tt_sl_v_bitmap_a_holo_d;
-- BEGIN;
-- CREATE TABLE PUBLIC.tt_sl_v_bitmap_a_holo_d (
-- "tag_id" INT8 not null,
-- "tag_value" text,
-- "userlist" roaringbitmap,
-- "carlist" roaringbitmap,
-- PRIMARY KEY (tag_id,tag_value)
-- ) ;
-- CALL SET_TABLE_PROPERTY('PUBLIC.tt_sl_v_bitmap_a_holo_d', 'orientation', 'column');
-- CALL SET_TABLE_PROPERTY('PUBLIC.tt_sl_v_bitmap_a_holo_d', 'bitmap_columns', 'tag_id,tag_value');
-- CALL SET_TABLE_PROPERTY('PUBLIC.tt_sl_v_bitmap_a_holo_d', 'dictionary_encoding_columns', 'tag_id:auto,tag_value:auto');
-- CALL SET_TABLE_PROPERTY('PUBLIC.tt_sl_v_bitmap_a_holo_d', 'table_group', 'mdp');
-- CALL SET_TABLE_PROPERTY('PUBLIC.tt_sl_v_bitmap_a_holo_d', 'clustering_key','tag_id');
-- COMMIT;
set hg_experimental_query_batch_size = 4096;
set hg_experimental_foreign_table_executor_max_dop = 32;
INSERT INTO PUBLIC.tt_sl_v_bitmap_a_holo_d (tag_id,tag_value,userlist,carlist)
SELECT tag_id
,tag_value
,rb_build(userlist) userlist
,rb_build(carlist) carlist
FROM tt_sl_v_bitmap_ulist_a_d
ON CONFLICT (tag_id,tag_value) DO UPDATE
SET tag_id = excluded.tag_id
,tag_value = excluded.tag_value
,userlist = excluded.userlist
,carlist = excluded.carlist
;
8、日期的季度归属
select floor(substr('2023-07-04',6,2)/3.1)+1;
返回:3