大模型落地的必经之路 | GPTQ加速LLM落地,让Transformer起飞!
作者 | 小书童 编辑 | 集智书童
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
点击进入→自动驾驶之心【大模型】技术交流群
本文只做学术分享,如有侵权,联系删文

生成预训练Transformer模型,也称为GPT或OPT,通过在复杂语言建模任务中取得突破性性能而脱颖而出,但也因其庞大的规模而需要极高的计算和存储成本。具体而言,由于它们的巨大规模,即使对于大型高精度的GPT模型的推理,也可能需要多个性能卓越的GPU,这限制了这些模型的可用性。虽然目前有一些工作正在通过模型压缩来减轻这种压力,但现有的压缩技术的适用性和性能受到GPT模型的规模和复杂性的限制。
在本文中,作者解决了这一挑战,并提出了GPTQ,这是一种基于近似二阶信息的新的一次性权重量化方法,既高度准确又高效。具体而言,GPTQ可以在大约4个小时内对具有1750亿参数的GPT模型进行量化,将每个权重的位宽降至3或4位,相对于未压缩基准几乎没有精度下降。
作者的方法相对于以前提出的一次性量化方法,提高了压缩效益的一倍多,保持了准确性,首次允许在单个GPU内执行一个拥有1750亿参数的生成推理模型。此外,作者还展示了作者的方法在极端量化情境下仍然可以提供合理的准确性,即将权重量化为2-Bit甚至3-Bit。
作者通过实验证明,这些改进可以用于在使用高端GPU(NVIDIA A100)时实现与FP16相比的端到端推理加速,速度提高约3.25倍,而在使用更具成本效益的GPU(NVIDIA A6000)时速度提高了4.5倍。
代码:https://github.com/IST-DASLab/gptq
1、简介
来自Transformer家族的预训练生成模型,通常被称为GPT或OPT,已经在复杂语言建模任务中取得了突破性的性能,引起了广泛的学术和实际兴趣。它们的一个主要障碍是计算和存储成本,这些成本在已知模型中排名最高。例如,性能最好的模型变种,例如GPT3-175B,具有约1750亿参数,需要数十到数百个GPU年进行训练。甚至在作者本文中,对预训练模型进行推理的更简单任务也非常具有挑战性:例如,以紧凑的FP16格式存储时,GPT3-175B的参数占用326GB的内存。这超出了甚至最高端的单个GPU的容量,因此推理必须使用更复杂和昂贵的设置,如多GPU部署。
尽管消除这些开销的标准方法是模型压缩,但令人惊讶的是,关于压缩这些模型进行推理的知识非常有限。一个原因是更复杂的低位宽量化或模型修剪方法通常需要模型重新训练,对于具有数十亿参数的模型来说非常昂贵。或者,不需要重新训练的后训练方法会非常吸引人。不幸的是,这些方法的更精确变体复杂且难以扩展到数十亿的参数。
迄今为止,仅应用了基本变体的四舍五入量化在GPT-175B的规模下;尽管这对于低压缩目标(例如8-Bit权重)效果良好,但在更高的压缩率下无法保持准确性。因此,一次性后训练量化到更高压缩率是否普遍可行仍然不清楚。
贡献
在本文中,作者提出了一种新的后训练量化方法,称为GPTQ,它足够高效,可以在最多几个小时内在具有数千亿参数的模型上执行,并足够精确,可以将这些模型压缩到每个参数3或4位,而几乎不会丧失准确性。举个例子,GPTQ可以在大约4个小时内量化最大的公开可用模型OPT-175B和BLOOM-176B,而且困惑度几乎没有显著增加,而困惑度是一个非常苛刻的准确性度量标准。
此外,作者还展示了作者的模型在极端量化范围内可以提供稳健的结果,其中模型被量化为每个组件2-Bit,甚至3-Bit。在实际方面,作者开发了一个执行工具,可以使作者有效地运行生成任务的压缩模型。
具体来说,作者能够首次在单个NVIDIA A100 GPU上运行压缩的OPT-175B模型,或者仅使用两个更经济的NVIDIA A6000 GPU。作者还实现了专门的GPU核心,可以利用压缩以更快地加载内存,从而在使用A100 GPU时加速约3.25倍,使用A6000 GPU时加速约4.5倍。
据作者所知,作者是第一个展示具有数千亿参数的极其准确的语言模型可以被量化为3-4-Bit/组件的研究:以前的后训练方法只能在8位下保持准确,而以前的基于训练的技术只能处理小数目级别较小的模型。这种高度的压缩可能看起来很自然,因为这些网络是过度参数化的;然而,正如作者在结果的详细分析中讨论的那样,压缩在语言建模(困惑度)、位宽和原始模型大小之间引起了非平凡的权衡。
作者希望作者的工作将激发这一领域的进一步研究,并成为使这些模型可供更广泛受众使用的进一步步骤。就限制而言,作者的方法目前不提供实际的乘法速度提升,因为主流架构上没有混合精度操作数(例如FP16 x INT4)的硬件支持。此外,作者目前的结果不包括激活量化,因为在作者的目标情境中,它们不是一个重要的瓶颈;然而,可以使用其他技术来支持它。
2、相关工作
量化方法大致可以分为两类:训练期间的量化和后期量化方法。前者通常在广泛的重新训练和/或微调期间对模型进行量化,使用一些近似的微分机制来执行舍入操作。相比之下,后期(“一次性”)方法使用适度的资源,通常是几千个数据样本和几小时的计算时间,对预训练模型进行量化。对于大规模模型,完整的模型训练甚至微调可能代价高昂,因此作者在这里重点关注后期量化方法。
2.1 PTQ量化
大多数后期量化方法主要关注视觉模型。通常,准确的方法通过对个别层或连续层的小块进行量化。AdaRound方法通过退火惩罚项计算依赖于数据的舍入,鼓励权重朝着与量化水平对应的格点移动。BitSplit使用残差误差的平方误差目标逐位构建量化值,而AdaQuant执行基于直通估计的直接优化。BRECQ将Fisher信息引入目标中,并联合优化单个残差块内的层。
最后,Optimal Brain Quantization(OBQ)将经典的Optimal Brain Surgeon(OBS)二阶权重剪枝框架推广到量化。OBQ按照量化误差的顺序逐个量化权重,总是调整剩余的权重。尽管这些方法可以在几个GPU小时内为高达约1亿参数的模型产生良好的结果,但将它们扩展到数量级更大的网络是具有挑战性的。
2.2 大模型量化
随着最近开源发布的像BLOOM或OPT-175B这样的语言模型,研究人员已经开始开发用于推理的压缩这些庞大网络的经济方法。虽然所有现有的作品,如ZeroQuant,LLM.int8()和nuQmm,都会仔细选择量化粒度,例如基于向量,但它们最终只是将权重舍入到最近的量化水平,以维持非常大模型的可接受运行时间。
ZeroQuant进一步提出了类似于AdaQuant的分层知识蒸馏,但它只能应用于最大的模型,参数仅有13亿。在这一规模下,ZeroQuant已经需要约3小时的计算;而GPTQ可以在约4小时内量化比ZeroQuant大100倍的模型。LLM.int8()观察到在几个特征维度上的激活异常值会破坏更大模型的量化,提出通过保持这些维度的较高精度来解决这个问题。最后,nuQmm开发了一种基于二进制编码的量化方案的高效GPU核心。
与这一研究方向相比,作者展示了在大规模模型中可以高效实现更为复杂和准确的量化器。具体而言,相对于以前的技术,GPTQ在保持类似准确性的情况下,将压缩量更多地提高了一倍以上。
3、 背景方法
3.1 逐层量化
从高层次来看,作者的方法遵循了最先进的后期量化方法的结构,通过逐层进行量化,为每一层解决相应的重构问题。具体而言,让表示与线性层对应的权重,让表示通过网络运行的一小组个数据点对应的层输入。然后,目标是找到一个量化权重矩阵,以最小化相对于全精度层输出的平方误差。从形式上来看,这可以重新表述为
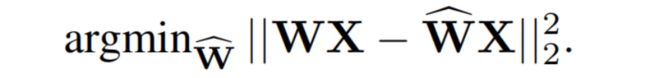
此外,作者假设在过程之前,的量化网格是固定的,而各个权重可以自由移动。
3.2 Optimal Brain Quantization
作者的方法基于最近提出的Optimal Brain Quantization(OBQ)方法,用于解决上面定义的逐层量化问题,作者对其进行了一系列重大修改,使其能够扩展到大型语言模型,提供了超过三个数量级的计算速度提升。为了帮助理解,作者首先简要总结一下原始的OBQ方法。
OBQ方法从以下观察开始,即方程(1)可以写成W的每一行的平方误差之和。然后,OBQ独立处理每一行w,逐个量化一个权重,同时始终更新所有尚未量化的权重,以弥补量化单个权重所带来的误差。由于对应的目标是二次的,其Hessian矩阵为,其中表示剩余全精度权重的集合,下一个要量化的贪婪最优权重,作者用表示,以及所有中权重的最优更新,作者用δ表示,由以下公式给出,其中将舍入到量化网格上的最近值:
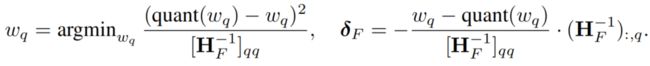
OBQ使用这两个方程来迭代地量化权重,直到的所有权重都被量化。这可以高效地完成,避免昂贵的的完全重新计算,通过一步高斯消元直接在逆中去除的第行和列,这是在量化后必要的。换句话说,更新后的逆矩阵由以下公式给出:

这种方法带有矢量化的实现,可以同时处理W的多行。最终,该算法可以在中等大小的模型上达到合理的运行时间:例如,它可以在单个GPU上的大约1小时内完全量化ResNet-50模型(2500万参数),这与其他实现最先进准确性的后期量化方法大致相符。然而,OBQ对于矩阵的运行时间具有立方输入依赖性,这意味着将其应用于数十亿参数的模型是非常昂贵的。
步骤1:任意顺序的洞察
如前所述,OBQ以贪婪的方式量化权重,即它总是选择当前产生的额外量化误差最小的权重。有趣的是,作者发现,虽然这种相当自然的策略确实似乎表现得非常好,但它相对于以任意顺序量化权重的改进通常较小,特别是在大型、参数众多的层上。很可能是因为具有大个体误差的量化权重数量稍微较低,但这些权重在过程的末尾被量化时,只有很少的其他未量化权重可以用来进行补偿调整。正如作者将在下面讨论的,这一洞察认为在大型模型上,任何固定的量化顺序可能表现良好,具有有趣的影响。

原始的OBQ方法独立地量化的行,按照相应的误差定义的特定顺序。相比之下,作者将目标定为以相同的顺序量化所有行的权重,并将显示,这通常产生了最终平方误差与原始解决方案相似的结果。因此,所有行的未量化权重和类似的对于所有行始终相同(有关示例,请参见图2)。更详细地说,后者是由于仅依赖于层输入,对于所有行来说是相同的,而不依赖于任何权重。
因此,作者必须执行由方程(3)给出的的更新仅次,每列一次,而不是次,每个权重一次。这将总体运行时间从减少到,即减少了倍。对于较大的模型,这个差异相当大。然而,在这个算法实际应用于非常大的模型之前,需要解决两个额外的主要问题。
步骤2:延迟批量更新
首先,直接实现先前描述的方案在实践中不会很快,因为该算法的计算与内存访问比率相对较低。例如,方程(3)需要使用每个条目的一些FLOPs来更新可能巨大的矩阵的所有元素。这样的操作无法充分利用现代GPU的大规模计算能力,并且将受到明显较低的内存带宽的限制。
幸运的是,这个问题可以通过以下观察来解决:列的最终舍入决策仅受到在此列上执行的更新的影响,因此此时对稍后的列的更新是无关紧要的。这使得可以“延迟批量”一起更新,从而实现更好的GPU利用率。
具体而言,作者一次将算法应用于B = 128列,使更新限制在这些列和的相应块中(另请参见图2)。只有在完全处理了一个块后,作者才使用下面给出的方程的多权重版本对整个和矩阵进行全局更新,其中表示索引集,表示具有相应行和列的逆矩阵已被删除:

尽管这种策略不减少理论计算量,但它有效地解决了内存吞吐量瓶颈。这为在实践中实现非常大型模型提供了一个数量级的加速,使其成为作者算法的关键组成部分。
步骤3:Cholesky重新制定
作者必须解决的最后一个技术问题是数值不准确性,尤其是在现有模型的规模上,特别是与前一步讨论的块更新结合使用时,数值不准确性可能成为一个主要问题。具体来说,矩阵可能变得不定,作者注意到这可能会导致算法以错误的方向积极更新剩余的权重,从而导致相应层的量化出现任意糟糕的结果。
在实践中,作者观察到,这种情况发生的概率随着模型的规模增大而增加:具体来说,在超过几十亿参数的模型上,至少会有几层几乎肯定会发生。主要问题似乎是重复应用方程(5),这些方程通过附加的矩阵求逆特别累积各种数值误差。对于较小的模型,应用阻尼,即将小常数λ(作者总是选择平均对角线值的1%)添加到的对角线元素似乎足以避免数值问题。但对于更大的模型,需要更强大和通用的方法。
为了解决这个问题,作者首先注意到,从那里所需要的唯一信息,其中表示在量化权重时未量化的权重集,就是第行,或者更精确地说,从对角线开始的这一行中的元素。因此,作者可以使用更稳定的数值方法预先计算所有这些行,而不会显著增加内存消耗。
事实上,通过(3)对作者的对称的行移除基本上对应于进行Cholesky分解,除了后者将第q行除以$([H^{−1}{Fq}]{qq}) 1/2 这一微小差异。因此,作者可以利用最先进的核心来预先计算作者需要的所有来自H^{−1}$的信息。结合轻微的阻尼,得到的方法足够健壮,可以在巨大的模型上执行而没有问题。作为额外的奖励,使用经过优化的Cholesky核心还会产生进一步的加速。接下来,作者详细介绍算法的Cholesky版本所需的所有小改动。
完整算法

最后,作者在算法1中呈现了GPTQ的完整伪代码,包括上面讨论的优化。
5 实验
基准线
作者的主要基准线,标记为RTN,包括将所有权重四舍五入到与GPTQ使用的完全相同的非对称每行网格上的最近的量化值,这意味着它与的最先进的权重量化完全相符。
目前,这是所有关于非常大型语言模型量化的作品的首选方法:它的运行时间在具有数十亿参数的网络上有很好的可扩展性,因为它只是执行直接的四舍五入。正如作者将在下面进一步讨论的,更准确的方法,如AdaRound或BRECQ,目前对于具有数十亿参数的模型来说速度太慢,这是本工作的主要焦点。然而,作者还展示了,对于小型模型,GPTQ与这些方法竞争力相当,同时也适用于像OPT-175B这样的大型模型。
量化小型模型
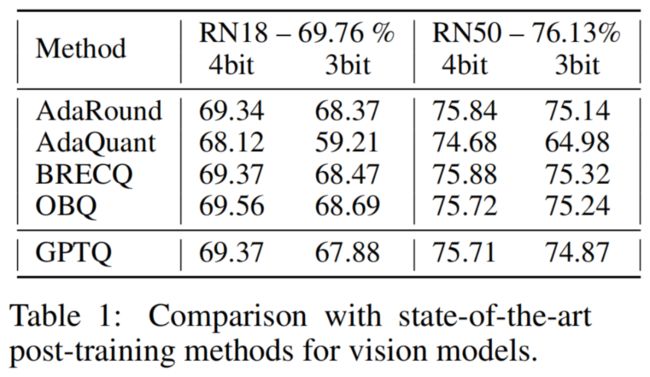
作为第一次消融研究,作者将GPTQ的性能与最先进的后训练量化(PTQ)方法在ResNet18和ResNet50上进行比较,这是标准的PTQ基准测试。如表1所示,GPTQ在4位时表现不俗,比最准确的方法稍差。与之前的PTQ方法相比,它明显优于最快的AdaQuant。此外,作者将与两种较小的语言模型上的完全贪婪OBQ方法进行比较:BERT-base和OPT-125M。

结果见附录表8。在4-Bit的情况下,两种方法的性能相似,而在3位的情况下,令人惊讶的是GPTQ表现稍好。作者怀疑这是因为OBQ使用的一些附加启发式方法,如早期异常值舍入,可能需要进行仔细的调整,以实现在非视觉模型上的最佳性能。总体而言,对于小型模型,GPTQ似乎与最先进的后训练方法相竞争,而只需不到1分钟而不是约1小时。这使得能够扩展到更大的模型。
运行时间
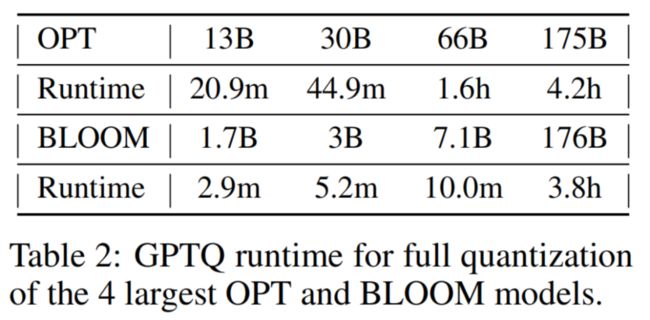
接下来,作者通过GPTQ测量了完整模型的量化时间(在单个NVIDIA A100 GPU上);结果见表2。如表所示,GPTQ在几分钟内量化了10-30亿参数的模型,而175B的模型则需要几个小时。
作为参考,基于直通法的ZeroQuant-LKD在相同硬件上报告了1.3B模型的3小时运行时间,线性外推到175B模型将需要数百小时(数周)。自适应舍入的方法通常使用更多的SGD步骤,因此更昂贵。
语言生成

作者开始了对整个OPT和BLOOM模型系列进行3-Bit和4-Bit的压缩的大规模研究。然后,作者评估这些模型在包括WikiText2在内的几个语言任务上的性能,见图1以及表3和表4,Penn Treebank(PTB)和C4。


作者专注于这些基于困惑度的任务,因为已知它们对模型量化特别敏感。在OPT模型上,GPTQ明显优于RTN,差距明显。例如,在175B模型的4-Bit时,GPTQ仅损失0.03的困惑度,而RTN下降了2.2分,表现比10倍小的全精度13B模型差。在3-Bit时,RTN完全崩溃,而GPTQ仍然可以维持合理的困惑度,尤其是对于较大的模型。
BLOOM显示了类似的模式:方法之间的差距通常略小一些,这表明这个模型系列可能更容易进行量化。一个有趣的趋势(也见图1)是,通常较大的模型(与OPT-66B2的例外情况)似乎更容易进行量化。这对于实际应用来说是个好消息,因为这些情况下压缩也是最必要的。
极端量化


最后,分组还使得在极端量化情况下,即每个组件平均2位左右的性能变得可能。表7显示了在不同组大小下,将最大的模型量化到2位时在Wikitext2上的结果。在约2.2位(组大小128;使用FP16的刻度和每组2-Bit的零点)时,困惑度的增加已经不到1.5点,而在约2.6位(组大小32)时下降到0.6-0.7,仅略差于3-Bit,对于实际的Kernel实现可能会很有趣。

此外,如果作者将组大小减小到8,作者可以应用3-Bit量化,这在OPT-175B上可以达到9.20的Wikitext2 PPL,下降不到1点。虽然与上面的2-Bit相比,平均来看这会导致更差的压缩,但这种模式可以在诸如FPGA之类的自定义硬件上高效实现。总之,这些结果是向着极低于平均3-Bit每个值的高精度一次性压缩非常大的语言模型迈出的鼓舞人心的第一步。
参考
[1]. GPTQ: ACCURATE POST-TRAINING QUANTIZATION FOR GENERATIVE PRE-TRAINED TRANSFORMERS.
① 全网独家视频课程
BEV感知、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、点云3D目标检测、目标跟踪、Occupancy、cuda与TensorRT模型部署、协同感知、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)
 视频官网:www.zdjszx.com
视频官网:www.zdjszx.com
② 国内首个自动驾驶学习社区
近2000人的交流社区,涉及30+自动驾驶技术栈学习路线,想要了解更多自动驾驶感知(2D检测、分割、2D/3D车道线、BEV感知、3D目标检测、Occupancy、多传感器融合、多传感器标定、目标跟踪、光流估计)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频,期待交流!

③【自动驾驶之心】技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多模态感知、Occupancy、多传感器融合、transformer、大模型、点云处理、端到端自动驾驶、SLAM、光流估计、深度估计、轨迹预测、高精地图、NeRF、规划控制、模型部署落地、自动驾驶仿真测试、产品经理、硬件配置、AI求职交流等方向。扫码添加汽车人助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

④【自动驾驶之心】平台矩阵,欢迎联系我们!
