微服务-分布式链路
这是我参与11月更文挑战的第 11 天,活动详情查看:2021最后一次更文挑战
本篇文章是近期在公司内做的分享,同步到这里希望更多的同学了解分布式链路
在过去10-15 年间,移动互联网时代大背景下,诞生了无数日活都是千万级以上的 app 产品。我们在客户端的任何一次操作,往往都需要经过后端服务的多个模块、多个基础组件、多台机器的相互协作才能完成请求的处理和响应。在这一系列的请求中,可能是串行也可能是并行,那么如何确定客户端的一次操作背后调用了哪些应用、哪些模块,经过了哪些节点,每个模块的调用先后顺序是怎样的,每个模块的性能问题如何?随着业务系统模型的日趋复杂化,分布式系统中急需一套链路追踪(Trace)系统来解决这些痛点。
分布式链路跟踪产生的背景
在单体应用时代,我们不需要花费时间去关心调用链路这个东西。但是链路跟踪不仅仅是在分布式场景下才会有,即使是单体应用,同样也会存在调用链路。例如,我们把应用中的每个服务接口作为一个链路节点,那么从请求进来到返回响应,把这个过程中历经的所有的方法接口串联起来,就能组成一条完整的链路,如下图所示:

对于单体应用而言,如果访问一个资源没有成功,那么我们可以很快的锁定是哪一台机器,然后通过查询这台机器上的日志就能定位问题。
但是在微服务体系架构下,这种方式会显得非常无力。对于一个稍具规模的应用来说,一次请求可能会跨越相当多的服务节点,在这种情况下,如果一个请求没有得到成功的响应,就不能确定到底是哪个节点出了问题。
1、applicationC 可能有多台实例
2、applicationC 返回失败可能是 C 调 D 失败导致的

因此在面对这种复杂的分布式集群来实现的服务体系来说,就需要一些可以帮助理解各个应用的线上调用行为、并可以分析远程调用的组件。
分布式链路跟踪分类
目前业界有一批非常有名的链路追踪系统,如:Twitter 的 Zipkin,Naver 的 Pinpoint,阿里的 eagleeye,大众点评的 CAT,华为 SkyWalking, Spring Cloud Sleuth(本质是 zipkin-brave),蚂蚁的 SOFATracer 。从这些产品中,我们大体可以归为两类:
狭义上的链路追踪:仅包括链路追踪数据的收集
- Spring Cloud Sleuth、 SOFATracer
广义上的链路追踪(APM 系统):包括链路追踪数据的收集、数据存储和数据展示
- Pinpoint、 SkyWalking、CAT
现代分布式链路跟踪理论
现代分布式链路追踪公认的起源是 Google 在 2010 年发表的论文《Dapper : a Large-Scale Distributed Systems Tracing Infrastructure》,但是实际上在此之前,跨服务的追踪已经有像 X-Trace、Magpie 、Pinpoint 等系统了,只不过这些系统在其发展过程的早期偏向于研究型,缺乏实际的工程系统实践论证;相比之下,在 Google 内部,从 2004 年开始,Dapper 已经陆陆续续在大规模生产环境中摸爬滚打了,因此论文一经发布,就引起了非常大的专注。前面提到的分布式链路跟踪组件产品,大多都受到了 Dapper 论文的直接影响。
Dapper 解读

这张图,涵盖了 Dapper 在分布链路的实践总结;这里不去深究 Dapper 是如何实现这样一套系统组件的(本身闭源),但是其所提出的概念、要求及目标等,为分布式链路跟踪提供了基本的方向,也使得在其发布之后的 10 年内,产生了一大批优秀的分布式链路跟踪产品,为微服务领域增加了一笔浓墨。
从 Dapper 到 OpenTracing
如果说 Dapper 是为现代分布式链路跟踪理论奠基,那么 OpenTracing 则是为分布式链路跟踪体系大楼的框定了整体模型。
无论是 Dapper 自己还是 HTrace, X-Trace,这些由公司内部场景演化而来的产品(商业化产品更甚),都逃脱不了 平台无关、厂商无关的 API 这样的问题,尽管这些系统都有着非常类似的 API,但各种语言的开发人员依然很难将他们各自的系统(使用不同的语言和技术)和特定的分布式追踪系统进行整合;这对于一些体量大、技术栈杂的公司或者云厂商来说,这无疑是不能接受的。这也从侧面反馈了一个问题,就是社区或者云服务厂商都涌现除了很多类似的产品。
OpenTracing 的出现,使得这些相互独立的分布式链路跟踪系统有了互通和兼容的可能性。
OpenTracing
OpenTracing 通过提供平台无关、厂商无关的 API,使得开发人员能够方便的(或更换)追踪系统的实现。
这段话可能比较抽象,并不能直观的知道它具体是什么;下面通过一个例子简单描述下 OpenTracing 所能解决的问题的两个场景。
场景
使用不同链路产品的系统交互
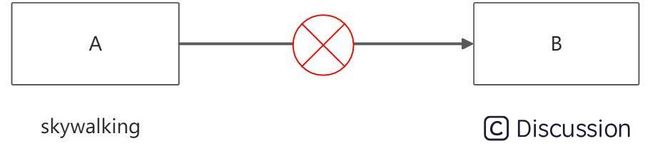
A-B 个系统,分别使用了 skywalking 和 pinpoint 两种不同的链路组件埋点,由于skywalking 和 pinpoint 透传协议不同,所以链路数据从 A 到 B 之后,由于 B 解析不了,从而链路断了。
应用的链路系统切换

A -B -C- D 4 个系统之前使用的 pinpoint 进行链路埋点的,由于需要切换云厂商,需要切换的 zipkin上去,怎么兼容?
通过这两个小 case 可以看到,不同链路跟踪系统由于在模型或 API 上存储差异,当分布式系统种存在多套埋点组件或者想切换时,就非常麻烦,甚至不可用。
回到 OpenTracing 的介绍,这里就比较好理解 通过提供平台无关、厂商无关的 API,使得开发人员能够方便的(或更换)追踪系统的实现 这句话的涵义了。
OpenTracing
除了平台、厂商无关,OpenTracing 实际上也是语言无关的。
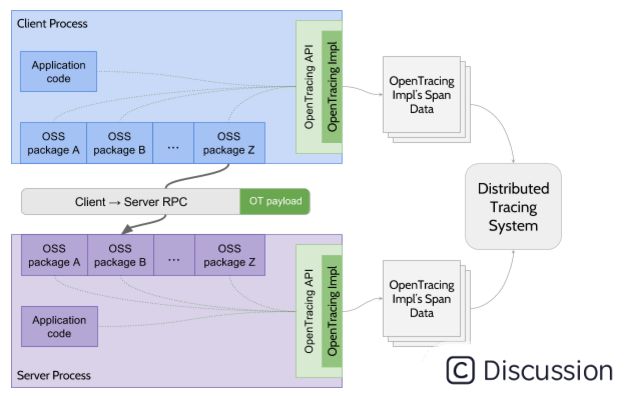
应用程序代码和 OSS 包针对抽象的 OpenTracing API 编程,描述请求在每个进程内的路径以及进程之间的传播。OpenTracing 实现控制跟踪跨度数据的缓冲和编码,它们还控制进程到进程跟踪上下文信息的语义。因此,应用程序代码可以描述和传播跟踪,而无需对 OpenTracing 实现做出任何假设。
平台、厂商无关,换句更容易理解的说法就是,不绑定到具体的实现上去,可以在不同的场景下适配不同的实现;这是不是和 slf4j 的门面模式有点类似?OpenTracing 在 API 的设计理念上,确实是和 slf4j 的差不多,除了 API 之外,OpenTracing 还在模型上也统一了,详见:https://opentracing.io/docs/overview/(PS:吴晟翻译版本相较于官方有延迟,中文翻译版上次更新是 2018 年,不过整体差异不是很大)
这里不单独把 OpenTracing 拎出来介绍,可以直接阅读官方文档即可。
这里整理下 OpenTracing 中的数据模型, API 部分只是规定类型 Trace Span 等需要提供哪些标准接口,例如 Trace 需要提供 create span 能力, span 需要提供 close 接口等,这里略过不展开细说。
数据模型
trace
OpenTracing 中的 Traces 是由其 spans 隐式定义的,一个 Trace 可以被认为是一组 span 组成的有向无环图(DAG),spans 之间的边界关系称为 References。
``` [Span A] ←←←(the root span)
|
+------+------+
| |[Span B] [Span C] ←←←(Span C is a ChildOf Span A)
| |[Span D] +---+-------+
| |
[Span E] [Span F] >>> [Span G] >>> [Span H]
↑
↑
↑
(Span G `FollowsFrom` Span F)```
span
name:
- 名字,比如一个方法名
- 开始时间
- 结束时间
一组 Tags
- 例如 web mvc 返回的 http code。http.code: 200
一组 Logs
- 例如 web mvc 在 xx 时间点返回的 http code。http.code: 200
SpanContext
- SpanContext 前面提到,是被用作组织跨进程透传数据的
References
- span 之间的因果关系,一般通过 spanContext 维护,而不是通过 span
SpanContext
SpanContext 中需要包括当前 span 的 tracerId,spanId,parentId,采样标记以及一些 Baggage(行李,也是 k-v),通常情况下 Baggage 会存放一些需要透传给下游链路的信息,Baggage 又可以细分为两种 bizBaggage 和 sysBaggage。sysBaggage 中常见的如全链路压测标,bizBaggage 中存放鉴权信息(内部服务之间的调用只需要检测 bizBaggage 中的鉴权信息是否存在即可,鉴权在流量入口处完成校验)。
Opentracing 的不足
opentracing 目前 span 之间的关系有两种:
- child-of
- follow-from

B 和 C child-of A、D child-of B、E child-of C
C follow-from B
这里有一种场景是没有被 cover 到的,即如何处理 fork-join 这种分治的模型,分治框架下的每个任务都是独立的线程,相互不依赖,他们执行的结果合并作为最终的结果,这种情况下,child-of 和 follow-from 都是无法描述的,OT 里面关于这个 issue 已经躺了 2 年了,一直没有动静。
蚂蚁分布式链路组件 SOFATracer
通过 SOFATracer 的实现,来细剖一下,一个分布式链路组件埋点需要关注的点。
全局唯一的 tracerId
链路的唯一标识是 tracerId,tracerId 会随着 SpanContext 传递到任何一个请求所经过的服务节点。在 Dapper 的文章中有提到过,初始节点相较于其他节点来说,耗时会略长,主要原因是这里有一些时间消耗在创建 tracerId 上面。那么对于一个成熟的链路组件,tracerId 的生成需要秉承两个基本原则:
- 低开销
- 避免冲突(即不重复)
| / | IP | Timestamp | Sequence | PID | | -- | -------- | ------------- | -------- | ------ | | 长度 | 32 bit | 64 bit | 16 bit | 32 bit | | 举例 | 0ad1348f | 1403169275002 | 1003 | 56696 |
上图是 SOFATracer tracerId 的生成规则,这里 IP 和 PID 是可以直接 cache 的,所以耗时主要在获取当前时间戳和产生随机串。
无感接入
这里所提到的无感接入指的是业务逻辑层面的无感,不需要修改任何业务代码逻辑。目前主流的链路跟踪产品基本上全部都做到了无感接入,主要有两个方式:
- agent 植入
- starter 依赖引入
SOFATracer 使用的是通过引入 tracer-sofa-boot-starter 实现无感接入埋点。
可插拔
链路追踪系统提供可选的插件或者开关以选择对于需要埋点的组件进行埋点,比如当我的系统只提供 web mvc 服务时,就不需要带入任何和 dubbo 相关的埋点插件依赖。
SOFATracer 提供的所有可选插件:https://github.com/sofastack/sofa-tracer/tree/master/sofa-tracer-plugins
数据上报
- 打印到磁盘
- 上报 zipkin
- 上报 jaeger(待merge)
- 上报 skywalking(待merge)
上报时机

以上面这个调用过程为例:
- CS(client send)时,作为流量出口,此时会产生一个 span-1,
- SR(server receive)时, Server 接收到请求,作为流量入口,此时也产生一个 span-2
- SS(server send)时,表示当时 server 端的逻辑已经全部处理完成,此时 SR 产生的 span-2 生命周期结束,需要 close 掉
- CR(client receive)时,表示当次请求完成,CS-1 产生的 span 生命周期结束,需要 close 掉
此时产生两个 span-1 is parent of span-2 , span-2 child of span-1(Child-Of 关系),时许图如下

上报流程

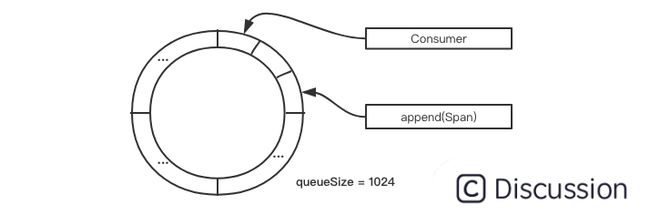
基于 Disruptor 的无锁日志落盘
这部分逻辑借鉴了 log4j2 的落盘实现,主要就是借助 disruptor 实现的。大致逻辑:当 span#finish 方法执行时,触发 SofaTracer 的 report 行为;report 最终会将当前 span 数据放入 Disruptor 队列中去,发布一个 SofaTracerSpanEvent 事件。Disruptor 的消费者 EventHandler 实现类 Consumer 会监听当前队列事件,然后在回调函数 onEvent 中将 span 数据刷新到磁盘中。
上报 zipkin
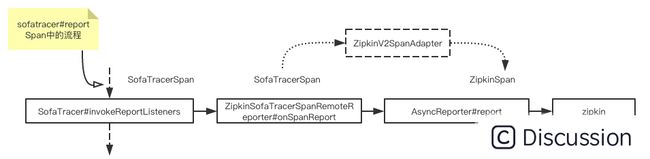
模型兼容,直接 report 到 zipkin 即可
上报 jaeger
下图是Jaeger中数据上报的部分图示,图中CommandQueue中存放的是刷新或添加指令,生产者是采样器和flush定时器,消费者是队列处理器。采样器判断一个span需要上报后向CommandQueue中添加一个AppendCommand,flush定时器根据设置的flushInterval不断向队列中添加FlushCommand,队列处理器不断从commandQueue中读取指令判断是AppendCommand还是FlushCommand,如果数刷新指令把当前byteBuffer中的数据发送到接受端,如果是添加指令把这个span添加到byteBuffer中暂存。
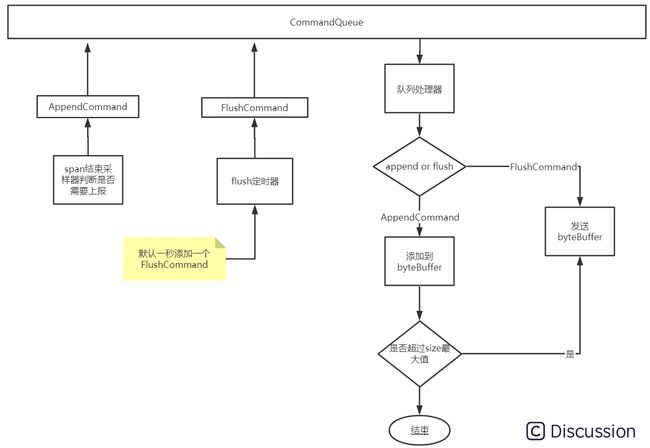
Jaeger 支持两种协议上报,HTTP 和 UDP;sofaTracer上报Jaeger中使用UdpSender发送Span数据到Jaeger Agent中,使用HttpSender直接发送数据到jaeger-collector中
上报 skywakling
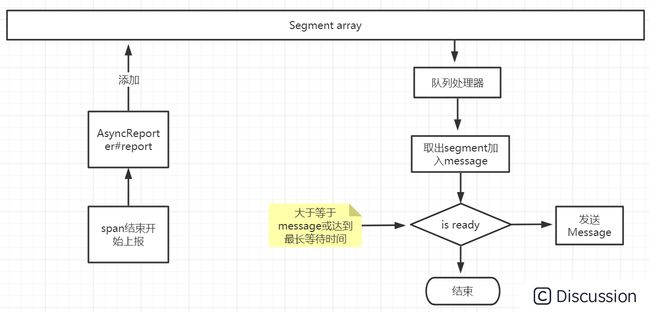
目前社区还在进行中,相比于 zipkin 和 jaeger,上报 skywakling 相对复杂些,主要在于 skywakling 内部使用了 segment 来描述节点,而非 opentracing 的 span。
使用 http 上报 Json 格式的 segment 数据到后端,上报时以 message 为单位,多个 segment 组合成一个message。流程如下图,span结束后将转换好的segment加入到segment缓冲数组中,另一个线程不断到数组中刷新数据到message,当 message 的大小达到最大值或等待发送的时间达到设定值就发送一次数据。message 最大默认为 2MB。
采样
对于分布式系统中的所有链路不必要全部收集,实际上只需要收集其中一小部分就足够了。这样可以降低损耗。采样在 Dapper 中就有提到:
每个请求都会利用到大量服务器高吞吐量的线上服务,这是对有效跟踪最主要的需求之一。这种情况需要生成大量的跟踪数据,并且他们对性能的影响是最敏感的。延迟和吞吐量带来的损失在把采样率调整到小于1/16之后就能全部在实验误差范围内。
在实践中,我们发现即便采样率调整到 1⁄1024 仍然是有足够量的跟踪数据用来跟踪大量的服务。保持链路跟踪系统的性能损耗基线在一个非常低的水平是很重要的,因为它为那些应用提供了一个宽松的环境使用完整的 Annotation API 而无惧性能损失。使用较低的采样率还有额外好处,可以让持久化到硬盘中的跟踪数据在垃圾回收机制处理之前保留更长时间,这样为链路跟踪系统的收集组件提供更多灵活性。
分布式链路跟踪系统中任何给定进程的消耗和每个进程单位时间的跟踪采样率成正比。然而,在较低的采样率和较低的传输负载下可能会导致错过重要事件,而想用较高的采样率就需要能接受的相应的性能损耗。我们在部署可变采样的过程中,参数化配置采样率时,不是使用一个统一的采样方案,而是使用一个采样期望率来标识单位时间内采样的追踪。这样一来,低流量低负载会自动提高采样率,而在高流量高负载的情况下会降低采样率,使损耗一直保持在控制之内。实际使用的采样率会随着跟踪本身记录下来,这有利于从跟踪数据里准确分析排查。
SOFATracer 在蚂蚁内部的版本中,采样策略比较单一,要么全采,要么不采,另外还提供了按组件关闭的能力;对于高并发场景下,一方面时通过允许丢弃队列数据的方式来达到降低损耗的目的,另一方面就是通过关闭链路上某些组件的埋点来降低整体的数据采集量。
SOFATracer 在采样设计上,并没有像 jaeger 那样提供一组预设可配的采样策略;SOFATracer 默认仅提供了按百分比采样的策略,然后通过对外暴露出可扩展的 SPI,让用户灵活扩展。
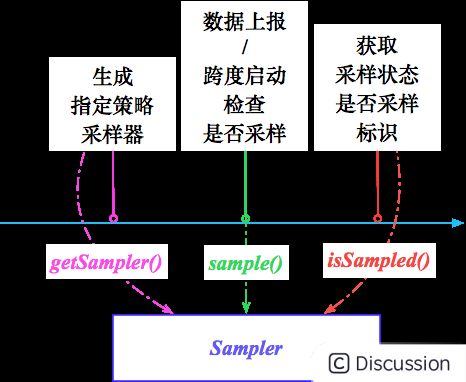
SOFATracer 基于 com.alipay.common.tracer.core.samplers.SamplerFactory 生成的采样器执行链路数据采样基本流程:
- 构建链路追踪器,通过采样器工厂 SamplerFactory 根据自定义采样规则实现类全限定名配置生成指定策略采样器 Sampler,其中基于用户扩展实现的采样模式优先级高,默认采样策略为基于固定采样率的采样计算规则;
- Reporter 数据上报 reportSpan 或者链路跨度 SofaTracerSpan 启动调用采样器 sample 方法检查链路是否需要采样,获取采样状态 SamplingStatus 是否采样标识 isSampled。
是否采样由第一个节点决定
链路透传(跨进程)
遵循 Opentracing Inject and Extract;Opentracing 的 Inject and extract 是提供了透传的数据格式类型,比如 Text Map or binary,这些被称为 Carrier formats。
除了格式之外,就是数据组织方式,这些需要被传播的数据(propagated )以 SpanContext 这个数据模型组织。
最后是透传方式,以 http 来说,就是将 SpanContext 序列化(json or hessian or 其他),然后塞到 HttpHeader 中向下游传递。
线程传递和透传
线程传递是基于单线程上下文的,线程透传指的是跨线程上下文的。
Opentracing 0.30.x 版本对于线程传递的支持
这里有必要来聊一下 Opentracing 0.30.x 版本对于线程透传的一个优秀设计。还是以这个图为例

span-1 和 span-2 其实算是个嵌套关系(这里我们基于进程内 span 关系来看);如果把这个模型理解成为一个栈的话,那么两个 span 的产生过程即为入栈的过程,如下:
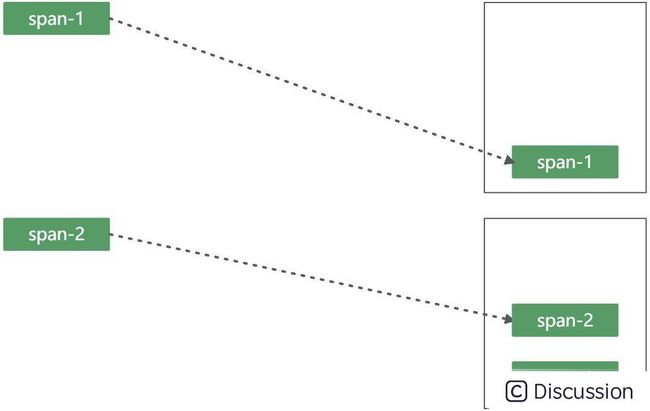
由于栈的特性是 FILO ,因此当 span-2 出栈时就意味着 spa-2 的生命周期结束了,此时会触发 Span 数据的上报。Opentracing 0.30.x 版本中提供了对上述思路的封装,用于解决 Span 在线程中传递的问题。两个核心的接口是 Scope 和 ScopeManager。
SOFATracer 中的线程传递
tracerContext 的线程传递 也是基于 ThreadLocal 来实现的,和 OT 本质上区别不大,只不过 OT 所站的视角相对来说更加全局一些。(SOFATracer 基于 Opentracing 0.22.0 版本,当时 0.30.x 版本还没有)
SOFATracer 中的线程透传
ThreadLocal 在涉及到跨线程时会丢失 tracer 上下文数据,所以在处理这种问题时就需要格外小心:
1、忘记将父线程的 tracerContext 透传到 子线程(链路丢失)
2、透传子线程之后,子线程结束时未清理 tracerContext (OOM 风险)
3、线程池中线程复用带来的 tracerContext 复用(链路污染)
SOFATracer 中的解决方式:https://www.sofastack.tech/projects/sofa-tracer/async/
性能评估
这里需要先明确下,一个分布式链路组件的接入有哪些额外的消耗:
1、tracerId 的生成,实时证明,这确实是一个比较耗时的动作,但是一般由流量入口服务产生(比如网关)。
2、span 的创建(内存产生一个新的对象)
3、透传数据的序列化和反序列化
4、数据落盘 或者 数据上报
以上 4 个点的消耗对于任何 trace 产品都无可避免,1-3 本质上各产品差异不大,主要是第 4 点上,主流的做法:
- 采样
- 压缩 gzip
- 异步批量上报(消息 or grpc)
- 允许丢失降级
数据分析
链路数据的作用这里不赘述,这里仅以 SOFATracer 中提供的一个叫统计日志的数据来说。
统计日志:每隔一定时间间隔进行统计输出的日志,目前是 60s
这个统计日志本质就是 metric 的一种形式,类似 Timer,即一段时间内的 total count;蚂蚁目前的流量监控就是依托 统计日志 来实现的。
分布式链路组件发展和思考
云原生方向,jaeger 已经被加入到 CNCF 基金会已经被证明,skywaking 也支持了 istio 的监控;这两者,都是某种角度寻求不修改应用程序(无论是 agent 还是拦截器)的方式来达到埋点的功能实现;从现在社区的整个发展方向来看,云原生所提倡的基础设施的进一步下沉,也一定意味着分布式链路跟踪系统的新一次迭代,比如基于 Service Mesh 在网络层进行拦截,通过 Sidecar 的形式来代理流量(其实现在很多服务治理的能力都前置到了 Sidecar 中去做了),从而做到真正的跨语言和非侵入。
蚂蚁从 18 年底到 20 年双十一,核心业务链路已经全部接入了 MOSN(蚂蚁自研的流量代理组件,和 envoy 职能类似),在链路埋点上,实现了 SOFATracer 的 GO 语言版本,兼容 OpenTracing 规范。MOSN 中的链路埋点实际上就是通过 sidecar 的形式来呈现的。
对于未来分布式链路的方向更多应该是关注在异构架构支持&真正的无侵入
- service mesh 下的链路
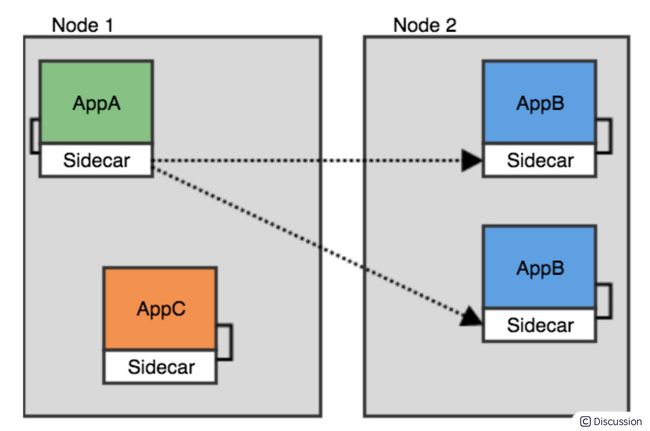
- dapr 下的链路
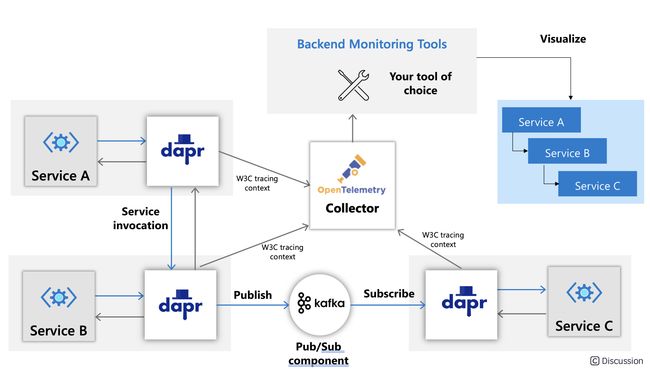
总结
本篇从分布式系统在实际运行中的问题排查和故障定位切入,引出了分布式链路跟踪产生的背景,并对现有分布式链路跟踪产品及现代分布式链路跟踪理论做个简单说明。由 Dapper 到 Opentracing,从理论到实践的不断演化,使得社区产生一批非常优秀的分布式链路跟踪产品,并作简单对比。最后以 SOFATracer 为例,基于侠义分类,分解了一个分布式链路组件所需要关注的点以及给出了 SOFATracer 的实现方式;文章最后简单聊了下分布式链路组件未来发展和思考,云原生已经不是陌生的话题,微服务到云原生,最重要的是基础设施的下沉,分布式链路作为分布式系统中重要的一环,也一定会在云原生场景下继续发挥重要的作用。
引用
分布式追踪技术综述
MagpieOnlineModellingandPerformance-aware_Syst.pdf
https://storage.googleapis.com/pub-tools-public-publication-data/pdf/36356.pdf
https://bigbully.github.io/Dapper-translation/
http://www.4k8k.xyz/article/xvshu/79866617
https://medium.com/opentracing/towards-turnkey-distributed-tracing-5f4297d1736