bigcache
bigcache
介绍
借用下图片,实际上,这张图还不太全,queueItem 中,entrydata的最前端 8 字节是时间戳,用来计算过期时间的。
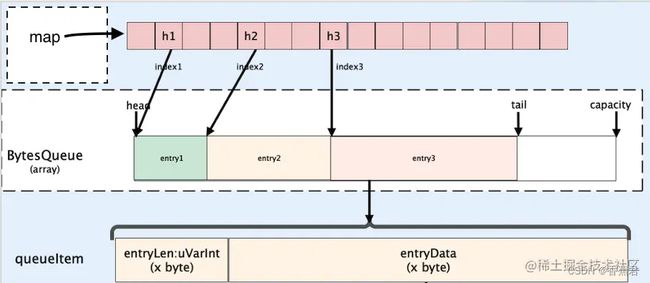
bigcache 的思想主要有以下几点:
- 大并发下,尽量减少同步带来的时间损耗
- 大缓存下,避免 GC 带来的扫描时延
除了这两点,bigcache 支持传统的一下两点缓存特点:
- 数据过期
- 最大内存上限
除此之外,也有一些缺点的。
- 内存只会有增长,不会有下降,除非使用 reset 函数,这相当于重新使用一套 cache了,不算是内存管理上的下降
- 覆盖写同名 key 有很大的内存管理问题,覆盖写只是用 map 里面删去了访问的索引,以及重置了数据段为0 值,没有修改len 段以及时间戳段
如何增加并发性能
常规内存库都是使用 map,没有 map 是不行的,因为访问不够快。但不论是普通的 map加锁, 还是sync.Map,都有并发方面的性能损耗,为了规避这个问题。
bigcache 直接用多个 map 来解决。至于落到哪个 map,就看 hash 函数怎么决定了。
如何减少 GC 压力
GC 压力是什么?
对于Go语言中的map, 垃圾回收器在 mark和scan阶段检查map中的每一个元素, 如果缓存中包含数百万的缓存对象,垃圾回收器对这些对象的无意义的检查导致不必要的时间开销。
那么如何解决这个问题呢?
Go 1.5中一个修复有关(#9477), 这个issue还是描述了包含大量对象的map的垃圾回收时的耗时问题,Go的开发者优化了垃圾回收时对于map的处理,如果map对象中的key和value不包含指针,那么垃圾回收器就会对它们进行优化:
所以如果我们的对象不包含指针,虽然也是分配在堆上,但是垃圾回收可以无视它们。
如果我们把map定义成map[int]int,就会发现gc的耗时就会将下来了。
遗憾的是,我们没办法要求用户的缓存对象只能包含int、bool这样的基本数据类型。
解决办法就是使用哈希值作为map[int]int的key。 把缓存对象序列化后放到一个预先分配的大的字节数组中,然后将它在数组中的offset作为map[int]int的value。
bigchache 怎么定时清理过期数据
go func() {
ticker := time.NewTicker(config.CleanWindow)
defer ticker.Stop()
for {
select {
case <-ctx.Done():
fmt.Println("ctx done, shutting down bigcache cleanup routine")
return
case t := <-ticker.C:
cache.cleanUp(uint64(t.Unix()))
case <-cache.close:
return
}
}
}()
- 每个 shard 都会检查
- 每个 shard 内部的entries会检查到没过期的为止
- 清理只是移动BytesQueue中的首尾指针,并不是整理内存碎片,也不会gc,也不会归还内存
- 会删除 map 中的 key,所以就访问不到这部分内存
覆盖写
if previousIndex := s.hashmap[hashedKey]; previousIndex != 0 {
if previousEntry, err := s.entries.Get(int(previousIndex)); err == nil {
resetKeyFromEntry(previousEntry)
//remove hashkey
delete(s.hashmap, hashedKey)
}
}
...
for {
if index, err := s.entries.Push(w); err == nil {
s.hashmap[hashedKey] = uint32(index)
s.lock.Unlock()
return nil
}
if s.removeOldestEntry(NoSpace) != nil {
s.lock.Unlock()
return fmt.Errorf("entry is bigger than max shard size")
}
}
- 覆盖写发生在 set 时
- 覆盖写不会移动任何BytesQueue中的指针,因此会在BytesQueue形成空洞,这个空洞只是无法访问,在过期之前,它都占用内存,也无法被重复利用
- 写入操作会只看 ByteQueue指针之外的空间是否足够,如果不够,强制移除最旧的元素,不管过不过期
如何减少覆盖写带来的内存浪费?
被覆盖写key 浪费的内存只有被过期重复利用,以及在内存不够时强制覆盖。
bigcache 内存扩展
func (q *BytesQueue) Push(data []byte) (int, error) {
neededSize := getNeededSize(len(data))
if !q.canInsertAfterTail(neededSize) {
if q.canInsertBeforeHead(neededSize) {
q.tail = leftMarginIndex
} else if q.capacity+neededSize >= q.maxCapacity && q.maxCapacity > 0 {
return -1, &queueError{"Full queue. Maximum size limit reached."}
} else {
q.allocateAdditionalMemory(neededSize)
}
}
index := q.tail
q.push(data, neededSize)
return index, nil
}
什么时候会发生内存的扩张?
当内存队列的尾巴,头部都没有空余位置,并且没有超过最大容量时扩展
扩展多大?
简单来说会扩展到原来的两倍,但如果申请的比原来的还打
使用bigcache时遇到一个问题。反复覆盖多个 key(key 的数量不是很多个位数,value 内容也不多,kb 级别),但是内存初始值非常高,而且后续随着覆盖写同名 key,内存有逐步上升。
首先贴出我的启动配置:
config := bigcache.Config{
Shards: 1,
LifeWindow: 1 * time.Second,
CleanWindow: 2 * time.Second,
MaxEntriesInWindow: 1,
MaxEntrySize: 10,
}
BigCache, initErr = bigcache.New(context.Background(), config)
for {
buf := make([]byte, 1024*1024)
err := BigCache.Set(rangeKey(), buf)
if err != nil {
fmt.Println(err)
}
time.Sleep(time.Millisecond * 100)
}
这里每次写入1MB 数据,2 秒会扫描一次清理过期数据,超过 1 秒的数据被标记为死亡。
观察到常驻内存在 60MB。
这里调整过很多参数,下面逐步说明参数意义。
Shards
shards 的目的是为了分成多个 map 管理,这样锁的粒度小一些,并发更高。但要合理设置 shards,尽量不要有多余的。因为初始化内存大小为
shards * MaxEntrySize * MaxEntriesInWindow
实际上设置为 1 一样的用,只是锁的冲突会高一点。
MaxEntriesInWindow和MaxEntrySize
只是决定初始化内存大小的参数,设置比较小的话初始化会消耗一些时间,但是再低也不会影响实际需要的内存大小,尽量开低点比较好。
CleanWindow和LifeWindow
LifeWindow是生命周期,按实际需要填写,不仅仅是有效数据遵循 lifewindow,连被覆盖的无效数据也有!!!所以这个参数一定不能为一个很大的值。
func (s *cacheShard) isExpired(oldestEntry []byte, currentTimestamp uint64) bool {
oldestTimestamp := readTimestampFromEntry(oldestEntry)
if currentTimestamp <= oldestTimestamp { // if currentTimestamp < oldestTimestamp, the result will out of uint64 limits;
return false
}
return currentTimestamp-oldestTimestamp > s.lifeWindow
}
CleanWindow是清理的窗口时间,填写的话,就会定时清理,如果不设置,那么就会在每次 set 的时候去检查清理一下,仅清理一条。
func (s *cacheShard) set(key string, hashedKey uint64, entry []byte) error {
if !s.cleanEnabled {
if oldestEntry, err := s.entries.Peek(); err == nil {
s.onEvict(oldestEntry, currentTimestamp, s.removeOldestEntry)
}
}
}
按照这个代码来看,不存在不过期的数据,因此要设置较长时间才可以。