hive01--hive的安装及配置
hive是基于Hadoop集群的,所以在安装hive之前需要先安装hadoop。如果hadoop没有安装的请参考:hadoop01--Hadoop伪分布式集群搭建_码到成龚的博客-CSDN博客
hive不像hadoop,Kafka,zookeeper那样需要搭建集群,我们只需要在两个安装即可。
需要的软件:
1,apache-hive-2.3.3-bin.tar-----链接:https://pan.baidu.com/s/1gYnzYg-QjOnWpmuiIRMMUQ?pwd=n8p6 提取码:n8p6
2,mysql-5.7.36-1.el7.x86_64.rpm-bundle----链接:https://pan.baidu.com/s/1N3C13GyvXTDUMOs19V3LWg?pwd=2ph7 提取码:2ph7
hive有三种运行模式:内嵌模式,本地模式和远程模式。
目录
一,内嵌模式的安装及运行hive
1,安装hive
2,关联hadoop
3,创建数仓目录
4,初始化元数据信息
5,启动hive cli
6,不能多用户同时访问
二,本地模式的安装及运行hive
1,配置MySQL
1)下载MySQL
2)安装MySQL
2,配置hive
1)上传驱动包
2)修改hive-site.xml文件
3,初始化元数据
三,远程模式的安装及运行hive
1,修改hive.site.xlm文件,安装hive客户端
2,启动metastore server
3,客户端访问hive
4,测试hive远程访问
一,内嵌模式的安装及运行hive
内嵌模式是hive入门的最简单的方法,是hive的默认启动模式,使用hive内嵌的derby数据库存储元数据,并将数据存储与本地磁盘上。内嵌模式常用于测试,不适合开发环境。
1,安装hive
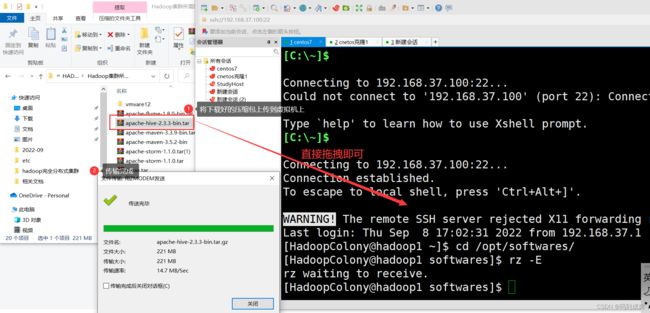
如上像以上的步骤那样拖拽后,文件始终没有动静,那估计是因为虚拟机上没有下载lrzsz程序,使用yum下载即可:yum install -y lrzsz。之后就可以直接使用拖拽来上传我们的文件到虚拟机上
当然,使用xftp这些文件传输软件也是可以的,看个人喜欢。接下来我们解压hive压缩包到modules目录下:
[HadoopColony@hadoop1 softwares]$ tar -zxf apache-hive-2.3.3-bin.tar.gz -C /opt/modules/
[HadoopColony@hadoop1 softwares]$ cd ../modules/
[HadoopColony@hadoop1 modules]$ ls
apache-flume-1.8.0-bin hadoop-2.8.2 kafka_2.11-2.0.0
apache-hive-2.3.3-bin jdk1.8.0_144 zookeeper-3.4.10
[HadoopColony@hadoop1 modules]$ 
如上解压成功后,我们去修改/etc/profile文件,来让我们的hive命令可以在任意目录下执行
[HadoopColony@hadoop1 modules]$ sudo vim /etc/profile
[HadoopColony@hadoop1 modules]$ sudo tail -3 /etc/profile
[HadoopColony@hadoop1 apache-hive-2.3.3-bin]$ tail -4 /etc/profile
export PATH=$PATH:$FLUME_HOME/bin
#加入hive的安装路径
export HIVE_HOME=/opt/modules/apache-hive-2.3.3-bin
export PATH=$PATH:$HIVE_HOME/bin
之后我们使用hive --version,如果成功输出当前hive的版本信息,则说明hive环境变量配置成功
 2,关联hadoop
2,关联hadoop
前面我们也知道了hive是依赖与Hadoop的,因此我们需要在hive中指定Hadoop的安装目录。
首先我们需要将我们hive/conf目录下的hive-env.sh.template 模板文件进行复制成 hive-env.sh文件,如下:
[HadoopColony@hadoop1 conf]$ cp hive-env.sh.template hive-env.sh
[HadoopColony@hadoop1 conf]$ ls
beeline-log4j2.properties.template hive-log4j2.properties.template
hive-default.xml.template ivysettings.xml
hive-env.sh llap-cli-log4j2.properties.template
hive-env.sh.template llap-daemon-log4j2.properties.template
hive-exec-log4j2.properties.template parquet-logging.properties
之后我们再去修改hive-env.sh文件,将我们的hadoop安装路径写进去。
[HadoopColony@hadoop1 conf]$ vim hive-env.sh
[HadoopColony@hadoop1 conf]$ tail -3 hive-env.sh
#指定hive依赖的Hadoop的安装目录
export HADOOP_HOME=/opt/modules/hadoop-2.8.2
3,创建数仓目录
我们需要在hdfs中创建两个目录,并设置同组用户具有可写权限,便于同组其他用户进行访问,如下:
[HadoopColony@hadoop1 ~]$ hadoop fs -mkdir /tmp #用于hive任务在hdfs中的缓存目录
[HadoopColony@hadoop1 ~]$ hadoop fs -mkdir -p /user/hive/warehouse #hive数据仓库目录,存储hive创建的数据库
[HadoopColony@hadoop1 ~]$ hadoop fs -chmod g+w /tmp
[HadoopColony@hadoop1 ~]$ hadoop fs -chmod g+w /user/hive/warehouse

4,初始化元数据信息
从hive2.1开始,需要运行schematool命令对hive数据库的元数据进行初始化。默认hive使用内嵌的derby数据库来存储元数据信息。命令如下:
[HadoopColony@hadoop1 ~]$ schematool -dbType derby -initSchema
.
.
.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Metastore connection URL: jdbc:derby:;databaseName=metastore_db;create=true
Metastore Connection Driver : org.apache.derby.jdbc.EmbeddedDriver
Metastore connection User: APP
Starting metastore schema initialization to 2.3.0
Initialization script hive-schema-2.3.0.derby.sql
Initialization script completed
schemaTool completed
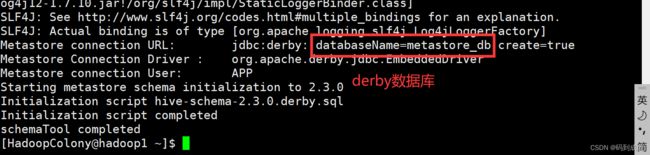
因为我们执行初始化命令的目录在我们的家目录下,因此我们的数据库就存储在了我们的家目录下:

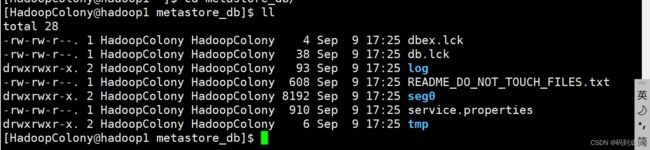
接下来我们可以查看metastore_db中生成的初始化文件列表:
5,启动hive cli
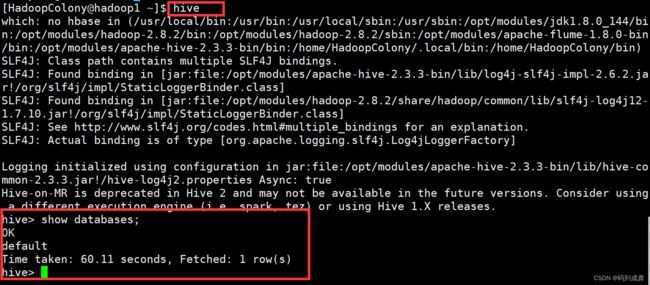
[HadoopColony@hadoop1 metastore_db]$ hive
我们在启动的时候需要注意一点,就是我们必须在初始化命令的执行目录下执行hive命令,不然即使是打开了hive的命令行也不能执行查询等操作,会报如“FAILED: SemanticException org.apache.hadoop.hive.ql.metadata.HiveException: java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient
”的错误。
如下是打开并执行成功的hive cil命令行,我们使用show databases查看数据库列表:
接着就是我们所熟悉的sql语句了,比方创建表格,插入数据等。
6,不能多用户同时访问
使用内嵌模式来运行hive有应该很大的缺点,那就是不支持多个会话同时对数据进行操作。

如下,我们一开始打开的会话里面的hive命令行自动退出。
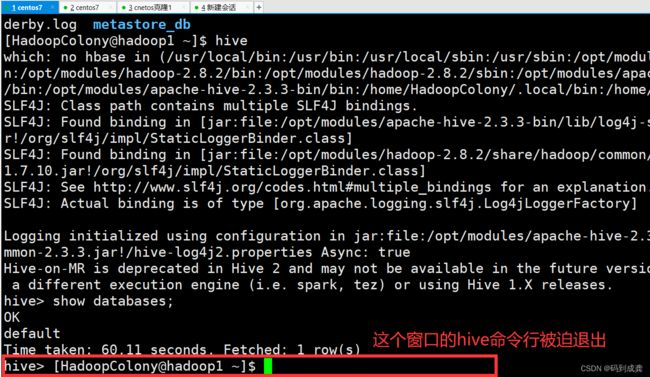
现在我们接着以另外一种模式来运行hive:本地模式。
二,本地模式的安装及运行hive
本地模式的安装与内嵌模式的不同在于需要修改配置文件,设置我们的mysql数据的连接信息。
1,配置MySQL
1)下载MySQL
[HadoopColony@hadoop1 apache-hive-2.3.3-bin]$ rpm -qa|grep mariadb #检查当前系统是否安装过Mysql
mariadb-libs-5.5.44-2.el7.centos.x86_64
[HadoopColony@hadoop1 apache-hive-2.3.3-bin]$ sudo rpm -e --nodeps mariadb-libs #卸载mariadb
[sudo] password for HadoopColony:
[HadoopColony@hadoop1 apache-hive-2.3.3-bin]$
MySQL :: Download MySQL Community Server (Archived Versions)https://downloads.mysql.com/archives/community/
[HadoopColony@hadoop1 softwares]$ cat /etc/redhat-release #查看虚拟机上的内核版本
CentOS Linux release 7.2.1511 (Core)
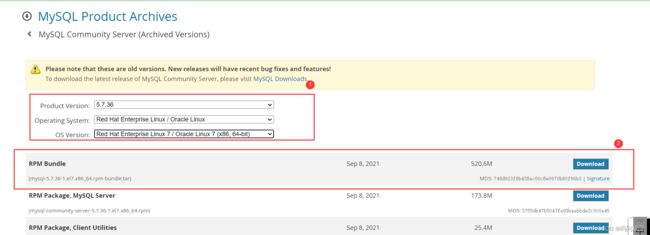
下载后的文件如下图:
 2)安装MySQL
2)安装MySQL

之后解压到我们的/opt/modules目录下:
[HadoopColony@hadoop1 softwares]$ tar xf mysql-5.7.36-1.el7.x86_64.rpm-bundle.tar -C /opt/modules/
[HadoopColony@hadoop1 softwares]$ cd ../modules/
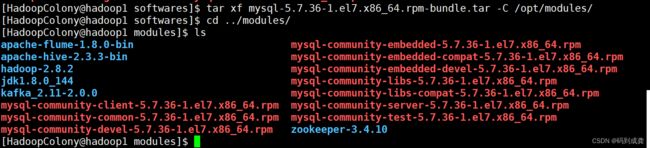 如上,我们可以看到就算是经过了解压的操作,但是压缩包里面依旧有.rpm结尾的文件,这个时候我们就需要对其进行安装:
如上,我们可以看到就算是经过了解压的操作,但是压缩包里面依旧有.rpm结尾的文件,这个时候我们就需要对其进行安装:
[HadoopColony@hadoop1 modules]$ sudo yum install -y libaio
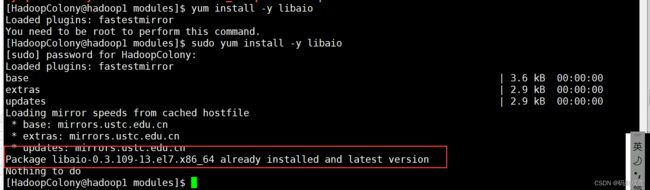
[HadoopColony@hadoop1 modules]$ sudo rpm -ivh --nodeps mysql-community-common-5.7.36-1.el7.x86_64.rpm
[HadoopColony@hadoop1 modules]$ sudo rpm -ivh --nodeps mysql-community-libs-5.7.36-1.el7.x86_64.rpm
[HadoopColony@hadoop1 modules]$ sudo rpm -ivh --nodeps mysql-community-libs-compat-5.7.36-1.el7.x86_64.rpm
[HadoopColony@hadoop1 modules]$ sudo rpm -ivh --nodeps mysql-community-client-5.7.36-1.el7.x86_64.rpm
[HadoopColony@hadoop1 modules]$ sudo rpm -ivh --nodeps mysql-community-server-5.7.36-1.el7.x86_64.rpm
[HadoopColony@hadoop1 modules]$ 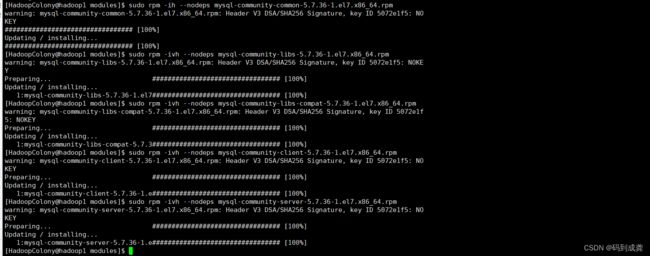 rpm全称 RPM Package Manager 缩写,由红帽开发用于软件包的安装升级卸载与查询.
rpm全称 RPM Package Manager 缩写,由红帽开发用于软件包的安装升级卸载与查询.

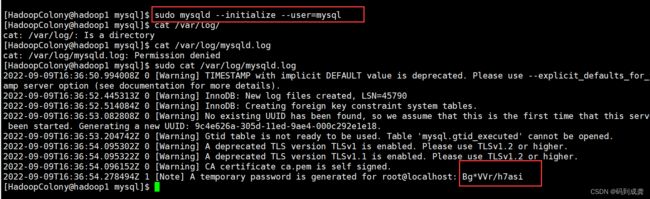
[HadoopColony@hadoop1 mysql]$ sudo mysqld --initialize --user=mysql #重置mysql
[HadoopColony@hadoop1 mysql]$ cat /var/log/mysqld.log #查看生成的密码
...
2022-09-09T16:36:54.278494Z 1 [Note] A temporary password is generated for root@localhost: Bg*VVr/h7asi
[HadoopColony@hadoop1 mysql]$ systemctl start mysqld
[HadoopColony@hadoop1 mysql]$ mysql -uroot -p
Enter password:
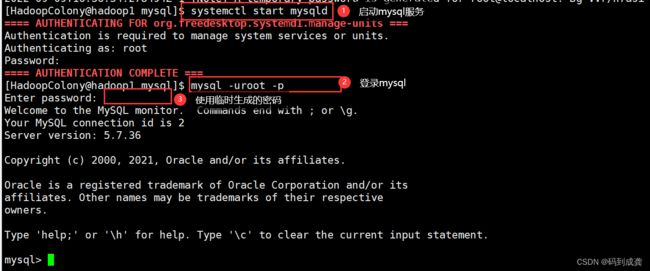
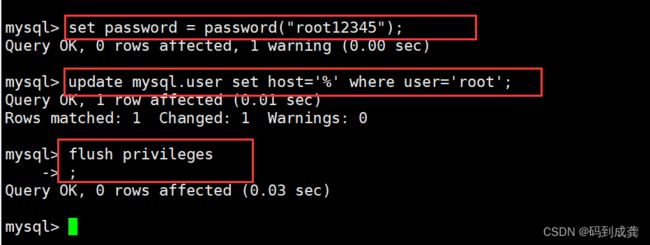
mysql> set password = password("root12345");
Query OK, 0 rows affected, 1 warning (0.00 sec)
mysql> update mysql.user set host='%' where user='root';
mysql> flush privileges;
因为我们下载的mysql是5.×版本的,是不支持中文字符数据的写入的,因此我们需要修改配置文件的字符集和校对集,在windows系统下,MySQL的配置文件是my.ini,但是在linux系统下,MySQL的配置文件叫my.cnf
[HadoopColony@hadoop1 mysql]$ sudo vim /etc/my.cnf
#添加如下内容
[client]
default-character-set=utf8
[mysqld]
character-ser-server=utf8
collation-server=utf8_general_ci
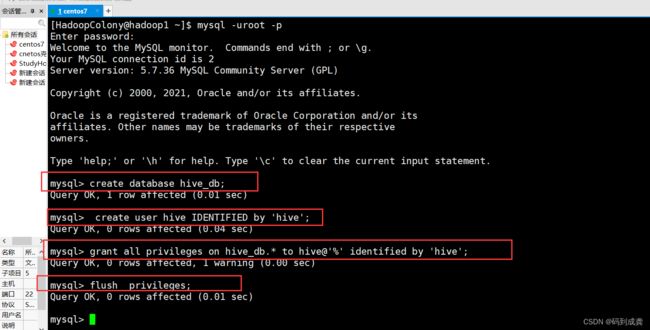
最后我们我们使用mysql创建hive_db数据库及hive用户。
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> create database hive_db; #创建hive_db数据库,用来存储hive元数据信息
Query OK, 1 row affected (0.16 sec)
mysql> create user hive IDENTIFIED by 'hive'; #创建hive用户,并使用hive作为密码
Query OK, 0 rows affected (0.12 sec)
mysql> grant all privileges on hive_db.* to hive@'%' identified by 'hive'; #赋予全局外部访问权限
Query OK, 0 rows affected (0.06 sec)
mysql> flush privileges; #刷新权限
Query OK, 0 rows affected (0.01 sec)
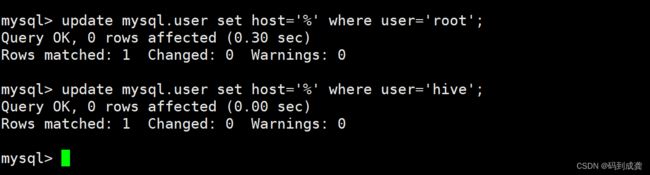
mysql> update mysql.user set host='%' where user='root';
Query OK, 0 rows affected (0.30 sec)
Rows matched: 1 Changed: 0 Warnings: 0
mysql> update mysql.user set host='%' where user='hive';
Query OK, 0 rows affected (0.00 sec)
Rows matched: 1 Changed: 0 Warnings: 0
2,配置hive
接着我们开始配置hive,这个时候就需要用到Java连接MySQL的驱动包,因此我们需要将其上传到hive的安装目录的lib目录下($HIVE_HOME/bin):
1)上传驱动包
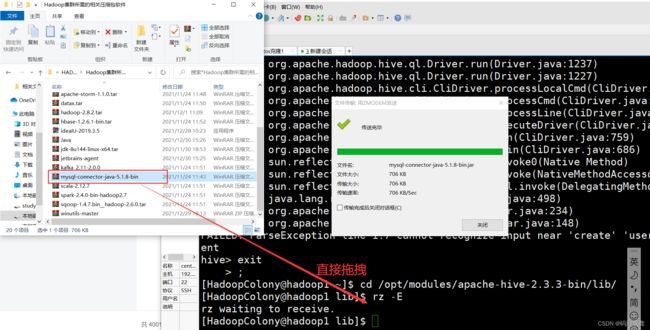
如下,我们可以看到在lib目录下有我们的驱动包了。
2)修改hive-site.xml文件
首先我们需要到hive的安装目录的conf目录下,然后找到hive-default.xml.template文件并将其复制并为hive-site.xml文件,之后再对其进行修改:
因为hive的hive-default.xml.template文件比较多,有好几百行,我们可以使用 ":" +“$’+回车,直接跳到文章的末尾。 或者是直接将文件的配置都删除掉去,然后加入如下的配置属性【单行删除:esc→按两次d;多行删除:esc→:开始的行号,结束的行号(例如删除第3行到第六行→:3,6)不要忘记前面的冒号。】
如下就是我的hive-site.xml文件的全部内容(我是先将里面的内容清空再写入自己的配置属性)
javax.jdo.option.ConnectionDriverName
com.mysql.jdbc.Driver
javax.jdo.option.ConnectionURL
jdbc:mysql://localhost:3306/hive_db?createDatabaseIfNotExist=true
javax.jdo.option.ConnectionUserName
hive
javax.jdo.option.ConnectionPassword
hive
hive.metastore.warehouse.dir
/opt/modules/apache-hive-2.3.3-bin/warehouse
hive.exec.local.scratchdir
/tmp/hive
hive.exec.scratchdir
/tmp/hive
hive.downloaded.resources.dir
/tmp/hive
hive.querylog.location
/tmp/hive
hive.server2.logging.operation.log.location
/tmp/hive
【值得一提的是如果我们没有配置日志的存储位置,那么我们hive的日志存储,默认存储目录在/tmp/系统用户名下,建议还是配置一下按照我发的copy然后将一些路径改成自己的就行。】
【需要注意的是,我们的hive-site.xml文件必不可少,hive启动时将读取该文件中的配置属性并覆盖我们hive的默认配置文件hive-default.xml.template中的相同属性】
3,初始化元数据
与使用内嵌模式运行hive类似,我们使用本地模式启动hive依旧需要初始化元数据,但这一次我们初始化得到的就不是默认的derby数据库了,而是我们mysql数据库。
之后我们执行以下的命令,初始化hive在mysql中的元数据信息
[HadoopColony@hadoop1 lib]$ rm -f log4j-slf4j-impl-2.4.1.jar #删除冲突的日志文件
[HadoopColony@hadoop1 conf]$ schematool -dbType mysql -initSchema
...
Initialization script hive-schema-2.3.0.mysql.sql
Initialization script completed
schemaTool completed

如上显示后表示我们的初始化完成且成功。接着我们再去登录hive_db数据库查看是否生成存放元数据的表,如下表示没有任何数据表:
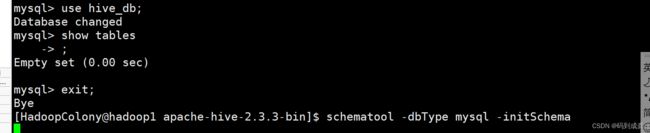
我们可以看到在初始化之前数据库里面是没有数据表的,初始化才有数据表。
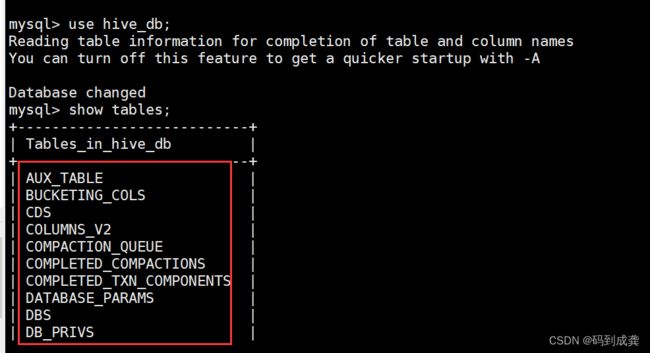
接下来我们需要先开启hadoop集群【一定要先开启Hadoop集群】,然后才是打开hive命令行。
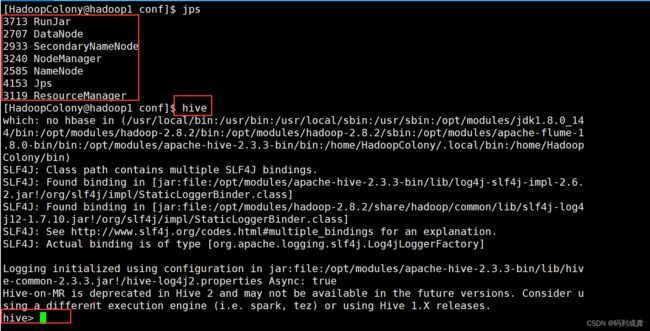 如上操作之后我们的hive的本地模式就配置完成了,与内嵌模式相比,本地模式最主要的不同在于本地模式支持同时多个会话对数据进行操作,而内嵌模式不支持。
如上操作之后我们的hive的本地模式就配置完成了,与内嵌模式相比,本地模式最主要的不同在于本地模式支持同时多个会话对数据进行操作,而内嵌模式不支持。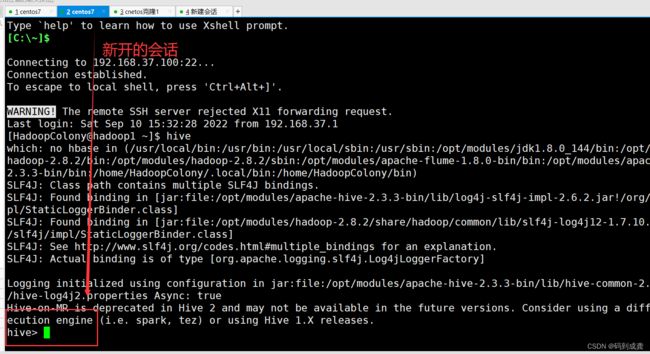
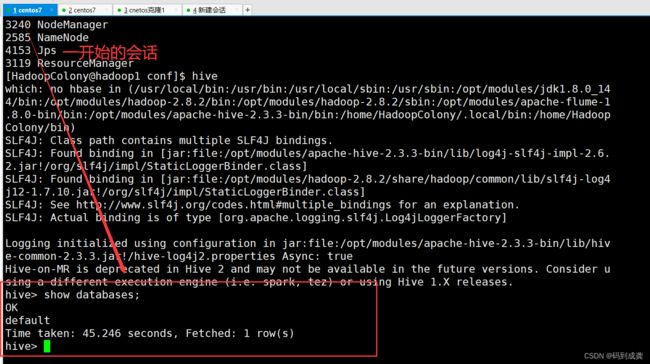 从上面我们就可以发现本地模式支持同时多个会话对数据进行操作。
从上面我们就可以发现本地模式支持同时多个会话对数据进行操作。
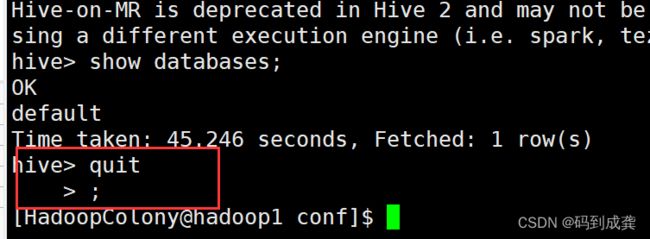
如果我们要退出hive的话可以使用quit;命令
三,远程模式的安装及运行hive
远程模式分为服务端和客户端两部分,服务端的配置与本地模式的配置相同,客户端需要单独配置,因为我之前在配置本地模式的时候一直是将hadoop集群的主节点hadoop1来进行配置的,因此我的hadoop1节点就作为了hive的服务端,之后我们再找一个节点来作为客服端即可,这里就拿hadoop2节点作为hive的客户端。然后我们需要在本地模式的基础上继续进行远程模式的配置。
1,修改hive.site.xlm文件,安装hive客户端
首先先将我们之前在服务端安装的hive文件复制到节点hadoop2上
[HadoopColony@hadoop1 modules]$ scp -r apache-hive-2.3.3-bin/ HadoopColony@hadoop2:/opt/modules/ #将hive的安装文件复制到hadoop2节点上
接着我们就需要去将hive-site.xml中的配置都清空,然后再添加如下的配置:
[HadoopColony@hadoop2 conf]$ vim hive-site.xml
加入如下内容:
hive.metastore.warehouse.dir
/opt/modules/apache-hive-2.3.3-bin/warehouse
hive.metastore.local
false
hive.metastore.uris
thrift://192.168.37.100:9083
2,启动metastore server
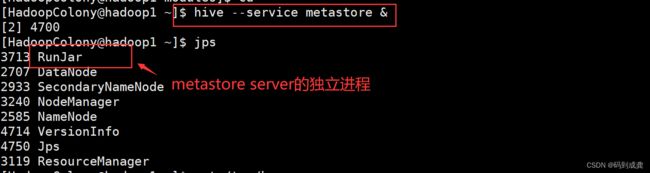
接下来我们在hadoop1节点中执行如下命令来启动我们的metastore server并使其在后台运行
[HadoopColony@hadoop1 ~]$ hive --service metastore &
[2] 4700
[HadoopColony@hadoop1 ~]$ jps
3713 RunJar
2707 DataNode
2933 SecondaryNameNode
3240 NodeManager
2585 NameNode
4714 VersionInfo
4750 Jps
3119 ResourceManager
如果我们现在去启动hive命令行模式,如下:
那么就会再多一个runjar进程,该进程为hive的服务进程(也就是hive cil的服务进程);

3,客户端访问hive
现在我们去使用客户端访问hive,客户端访问hive不像服务端那样在任意目录就可以访问,而是需要到hive的安装目录的bin目录下去执行hive操作:
[HadoopColony@hadoop2 conf]$ cd /opt/modules/apache-hive-2.3.3-bin/bin
[HadoopColony@hadoop2 bin]$ hive
...
X releases.
hive>
4,测试hive远程访问
接下来我们再在hive服务端开启hive命令行模式,并去创建一张学生表stu_tb:
hive> create database student_db; #创建student_db数据库
OK
Time taken: 0.167 seconds
hive> use student_db; #使用创建的student_db数据库
OK
Time taken: 0.029 seconds
hive> create table stu_tb(id int,name string); #在student_db数据库里面创建一张stu_tb表
OK
Time taken: 1.492 seconds
hive>
以上的操作我们都是在hive的服务端里面进行的,接下来我们到hive的客户端里面去查看是否存在student_db数据库及stu_tb表:
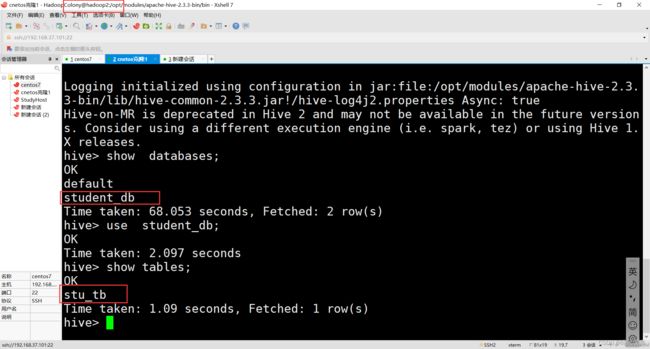
如上,我们可以看到数据库及表都能够在hive的客户端中成功查询到hive服务端创建的数据库及表,这就说明了我们的hive远程模式配置成功。