Auto-Tuning with Reinforcement Learning for Permissioned Blockchain Systems
文章目录
- 摘要
- 一、介绍
- 二、相关工作
-
- 2.1 总账结构
- 2.2 织物优化
- 三、系统结构
- 四、作为DRL问题的自动调谐
-
- 4.1 参数和性能
- 4.2 问题的转化
- 4.3 RL用于自动调参
- 4.4 PB-MADDPG用于自动调参
- 五、重要参数识别
- 六、实验
-
- 6.1设置
- 6.2 执行时间分解
- 6.3调整效果和效率比较
- 6.4参数数量的影响
- 6.5适应性
- 6.6奖励函数的评估
- 6.7容错性的评估
- 6.8总结
- 七、讨论
摘要
在一个允许的区块链中,性能决定了它的发展,而发展很大程度上受其参数的影响。然而,由于分布式参数带来的困难,关于自动调优以获得更好性能的研究已经有些停滞;因此,很难提出有效的自动调整优化方案。为了缓解这一问题,我们首先探索了Hyperledger Fabric(一种许可的区块链)中参数和性能之间的关系,并提出了Athena,一种基于Fabric的自动调整系统,可以自动提供参数配置以实现最佳性能,从而为我们的研究奠定了坚实的基础。Athena的关键是设计一种新的许可的区块链多代理深度确定性策略梯度(PB-MADDPG ),实现Fabric中不同类型节点的异构参数调整优化。此外,我们选择对加速推荐影响最大的参数。在对Fabric(一个典型的许可区块链系统,有12个对等点和7个订购点)的应用中,Athena比默认配置的吞吐量提高了470.45%,延迟减少了75.66%。与最先进的调优方案(CDBTune、Qtune和ResTune)相比,我们的方法在吞吐量和延迟方面具有竞争力。
一、介绍
由于图灵完全智能契约,许可区块链已经发展成为分布式交易管理系统,可以处理数据库可以执行的几乎所有交易[1,2]。由于区块链的安全性和透明性,许可区块链越来越多地被公司和政府部门用来替换或补充他们的数据库服务[3]。然而,交易[4–6]包括大量的加密签名计算、网络通信和信任验证,这限制了许可区块链的性能和进一步发展[7–9]。一个典型的例子是Hyperledger Fabric(以下简称“Fabric”),这是第一个开源的允许企业应用场景的区块链平台[6]。Fabric中的交易在整个网络中完全复制,并在涉及相同任务的所有节点上重放。现有的研究[13]表明,不能像在传统分布式数据库中那样通过简单地堆叠硬件来有效地提高Fabric的性能。因此,创新的优化方法是必要的。
最近的研究[1]表明,区块链与分布式数据库相当,因为它们与分布式交易管理系统相似。目前,在区块链有一种采用数据库特性的趋势(例如,FastFabric[29],Fabric++[16]),反之亦然[19,20]。例如,Sharma等人[16]仅将一个参数(即MaxMessageCount)从16调整到32,结构的吞吐量增加了近70%。但是,Fabric有数百个可配置的参数。因此,通过调整结构参数观察到的性能提升仅仅是冰山一角。尽管如此,大量的参数使得根据规则进行手动调整既没有效率也没有效果。即使对于专家来说,配置问题的复杂性也是难以承受的。自动调优被认为是分布式数据库中可行的解决方案,已经成为一种强大的优化方法。现有的分布式数据库自动调优方案分为三类:基于搜索的方法(例如Bestconfig [31])、基于传统机器学习的方法(例如OtterTune [26]、ResTune [15])和深度强化学习(DRL)方法(例如CDBTune [30]、Qtune [28])。然而,直接借用分布式数据库的自动调整方法来优化Fabric是复杂的,原因有三。
首先,Fabric的吞吐量计算方法不同于分布式数据库。在分布式数据库系统中,对于系统中的单个状态,一个交易只执行一次[1],现有的自动调优方案只需要记录来自任何节点的一个响应来计算吞吐量。相比之下,Fabric通过在多个并行节点上模拟单个交易来实现信任,执行过程涉及集群中的每个参与节点。因此,结构方案需要从执行交易的所有节点收集混合响应[6]。因此,用户很难使用数据库基准测试套件来测量Fabric。
第二,数据库领域中称为动态配置调谐器的最新研究方法根据工作负载的变化调整参数[21–24]。这项研究强调了数据库调优中工作负载变化的重要性。因此,这些调谐器中的大多数首先实时收集工作负载信息,然后预测最佳配置。最后,他们在集群中分配一些节点来重新配置最优参数,以确保系统在参数重新配置过程中的可用性。然而,这种动态配置调谐器不能满足结构调整的需要,因为它们利用了结构性能不太敏感的工作负载。例如,尽管分布式数据库(即H-STORE)中的两个工作负载应用程序(即YCSB和Smallbank)的性能相差近6.6倍,但它们在Fabric中的评估仅在10%以内波动[2]。
这种差异是由织物独特的工作机理造成的。具体来说,与分布式数据库直接将工作负载复制到其存储层的执行模式不同,Fabric需要额外的共识和验证过程来确保交易的可靠性,最终在性能调优中涉及这两个过程。此外,与执行阶段相比,共识和验证阶段要耗时得多。文献[1]指出,在非饱和工作负载的情况下,花费在共识和验证阶段的时间是花费在执行阶段的时间的几倍,在饱和工作负载的情况下甚至更多。Fabric的这一特性削弱了工作负载变化对系统的影响,使它们逐渐被忽略。因此,Fabric的调优不仅应该集中在执行交易的签署者对等节点上,还应该集中在参与共识和验证阶段的所有节点(即对等节点、订购者)上。同时,节点中的参数控制着一致性和有效性的执行过程,这对Fabric的性能有着不可忽视的影响。
第三,用于分布式数据库的自动调优方法需要昂贵的学习周期,这又需要大量的时间来在搜索空间中寻找参数和性能的最佳配对,以进行性能优化。由于参数的连续性和相关性,参数空间的大小随着参数的增加呈指数增长。分布式数据库的最佳方案可以通过选择重要的参数来克服这个问题[23,26,27],如实验结果所证实的。为了提高Fabric的性能,需要尽可能地考虑对等体、订购者和其他类型组件的所有参数。然而,由于没有先验知识来指导织物调优中重要参数的选择,因此迫切需要一种织物重要参数的选择方法来减少调优的训练时间。
在本文中,我们提出了一个新的自动调整Fabric参数的方案,即Athena(一个自动调整Fabric超分类网络的框架)。该方案使用集中训练和分散执行来建立预测最佳配置的DRL模型。它可以推荐一组显著提高结构性能的配置,以获得更高的吞吐量和更低的延迟。即使智能合同(链码)、工作负载或网络结构发生变化,性能也能保持竞争优势。具体来说,Athena观测所有节点的状态信息和性能指标,保证了对Fabric性能测量的有效性,解决了现有数据库方法无法准确测量Fabric真实性能的问题。同时,Athena对Fabric中不同类型的节点进行异构配置,充分利用每个节点的Fabric性能,解决分布式Fabric网络中的协同优化问题。
此外,我们量化参数的重要性,以减少自动调谐器必须调整的参数数量,减轻模型训练期间巨大搜索空间的负担,并提高系统效率。最后,我们将Athena应用于最流行的许可区块链系统,即Fabric。我们的结果表明,与12个对等点和7个订购者的默认设置相比,使用Athena推荐的配置集,Fabric的吞吐量提高了470.45%,延迟降低了75.66%。我们的主要贡献如下:据我们所知,这是第一次为织物的最佳性能提出自动调节系统。
我们提出了一种集中训练和分散执行的方法来实现结构的异构调优。
我们设计了一个高效的奖励函数,大大缩短了培训时间。
我们分析收集的数据,过滤出最重要的配置参数,从而显著提高自动调整效率。
最后,我们使用两种官方工作负载(小型银行和简单银行)进行了广泛的实验研究。(Athena的调优结果始终优于其他竞争对手。(b)识别与性能相关的重要参数,当调整前20个参数时,性能相当于调整C1下的所有参数(即3个订购者,4个同行),训练时间减少48.79%。
本文的其余部分如下。第2节描述相关工作,第3节显示系统架构,第4节将自动调谐作为DRL问题处理,第5节确定重要参数,第6节描述实验,第7节描述讨论。最后,第8节给出了结论。.
二、相关工作
2.1 总账结构
Hyperledger Fabric是在Linux Foundation下建立的企业级许可区块链框架[6]。在Fabric中,交易流遵循三个阶段,即执行、订购和验证。我们使用图1中的例子简单介绍这些阶段。在执行交易之前,客户端首先在认证机构(CA)中注册,以获得加入结构网络的合法身份。执行阶段:交易复制完成后,客户端根据背书策略发送给所有背书者节点。对等方通过调用链码(智能契约)和生成读/写集来模拟交易的执行。然后,背书者将响应(具有所有签名的读/写集合)发送回客户端。客户端收集响应并将它们发送给订购服务。排序阶段:排序服务的领导节点对收到的交易进行排序,并使用一致协议(例如,Raft)创建一个块。然后,订购服务的领导节点将这些块传递给对等方。验证阶段:对等方对接收到的块中的交易执行两个验证(认可策略和可序列化性),将交易提交到分类帐,最后向客户端发送通知。

因此,Fabric涉及客户端、对等体、链码和订购者来完成交易。执行一个交易所花费的时间是由各个节点的性能以及它们之间的通信决定的。协作执行交易的多个节点的类型使得该过程更加困难。为了应对这些挑战,本研究致力于织物参数的自动调整以改善其性能。
2.2 织物优化
很少注意参数的优化。
在这方面,Thakkar等人[7]进行了一项重要研究,他们通过实验分析讨论了五种配置对性能的影响,并提供了一些指南。此外,他们进行了近1000次实验。然而,手动调整的低效率消除了它的优点。一些研究[16,29]主要使用块大小作为实验比较项目,但未能全面分析参数对性能的影响。朱等[43]提出在微观结构层次上表征织物的参数,这与我们所关心的参数影响层次不同。Chacko等人[17]提出了一种新的工具,即HyperLedgerLab,来分析Fabric的不同参数对交易失败率的影响。这种方法关注小规模参数(例如,块大小)以减少交易失败。它不能挖掘许可的区块链参数的巨大潜力来提高性能。针对Fabric的其他优化方法包括Gorenflo等人[29]提出的FastFabric,该方法在验证阶段实现并行和加密的信息缓存方法。然而,这种方案仅限于实验室,不能应用于工业生产。例如,散列表存储在存储器中;一旦停机或节点离线,数据很容易丢失。[16,18,33]引用了数据库在区块链性能优化和功能转换中的众多原理和方法。然而,所有这些优化方法都需要修改织物的成分,并且存在许多关于织物安全性的隐藏的不确定性。我们的方法不改变Fabric的源代码,因此与前述优化(例如FastFabric)正交。
2.3数据库调优现有的数据库调优方法可以分为四大类[28]。(1)基于规则的方法。这些为用户提供了调整参数的专家方法经验,适合快速指导,是典型的解决方案,如[32]。然而,这种方案需要对系统的内部机制有深刻的理解,并且耗时。因此,本研究不研究该方案。(2)基于搜索的方法。通过搜索和调整参数空间来执行调谐。Bestconfig [31]是将高维参数空间划分为子空间的典型解决方案。此外,它使用基于搜索的方法来连续检索最优参数,并且在现实中,它可能会忽略最优配置。因此,本研究也不考虑这种方法。(3)传统的基于机器学习的方法。这些使用传统的机器学习技术[10,11,14,15,26]通过从历史数据中学习经验来调整数据库。
它们主要使用基于学习的算法(例如贝叶斯优化)进行参数调整。但是,这种算法需要大量高质量的历史数据,这些数据很难获得。因此,不选择这种方法。ResTune [15]是该领域最流行的方法,主要面向资源,用于优化各种目标(例如,CPU利用率)。这与我们关注吞吐量和延迟的方法不同。OtterTune [26]是另一个典型的解决方案。值得注意的是,消除了与性能无关的参数,从而提高了调谐效率。因此,在对结构参数的重要性进行排序时,将遵循这种方法。(4)基于DRL的方法。基于DRL的解决方案是目前最流行的数据库调优方案。CDBTune [30]和Qtune [28]是能够有效适应工作负载和硬件环境变化的典型解决方案。然而,现有的方法是基于单个代理的,这丢失了一些关于参数和性能之间关系的信息。
尽管在解决复杂的数据库自动调优问题上已经取得了一些成就,但是仍然不可能处理许可区块链的新体系结构。因为有权限的区块链需要将整个交易复制到不同的节点上重复执行,所以性能会受到多个节点的共同影响。因此,Fabric的自动调整成为多节点协作的新问题,现有的方法尚未考虑这一问题[26,30,31]。
三、系统结构
图2显示了Athena的工作流程概述。Athena按如下方式处理调优请求:用户向控制器发出请求,控制器自动部署环境基于默认配置并初始化多代理。
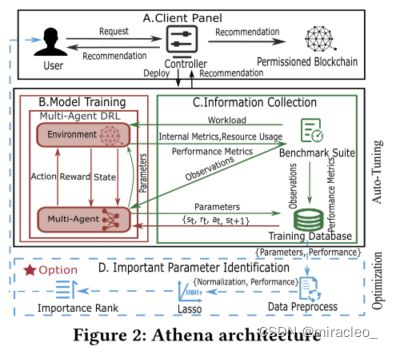
然后,控制器激活基准测试套件,收集资源使用情况和内部指标,并计算性能指标(吞吐量和延迟)。然后将收集的数据和参数存储在训练数据库中。资源使用和内部度量,统称为观察,被处理并提供给多代理以重新配置环境。该过程在每次使用来自前一过程的处理数据配置的环境中不断重复,直到达到设定的阈值。通过采样存储在训练数据库中的数据,Athena训练多智能体DRL模型,并调整输出配置参数策略。重复信息收集和模型训练的两步过程,直到性能指标符合并稳定下来。因此,生成最佳参数并推荐给控制器。
之后,用户决定是否在实际场景中使用推荐的配置。此外,作为一个选项,Athena使用最小绝对收缩和选择算子(LASSO) [37]来加权参数并建立参数的重要子集,这可以减少总的训练时间,同时为下一次调优保持有希望的高性能。
客户端面板(Client Panel):客户端面板由控制器启用,它可以接收用户的调优请求,然后协调和控制整个Athena系统的运行。该面板包括(1)网络架构,诸如用户正在调整到的目标(例如,四个对等体和五个订购者)的结构架构配置;(2)链码,在概念上类似于智能合约,其定义了需要在区块链中记录的数据和计算逻辑的类型;(3)工作负载,即当Caliper(区块链性能基准框架)[36]执行测试时发送到区块链的数据,因为链码和工作负载总是成对出现(我们将使用链码名称来指代两者,例如,Smallbank代表链码Smallbank及其工作负载);(4)所选参数,即用户选择调整的每个节点上的配置参数;(5)奖励系数,这是我们设计的奖励函数所要求的。在接收到由训练模型返回的推荐配置参数之后,用户可以将它们发送到控制器,以在光纤网络的实例中进行部署。
信息收集:信息收集与训练模型一起执行,收集的数据用于训练DRL模型和识别重要参数。
Caliper和Prometheus(一种状态监控系统)[38]被用作收集信息的基准套件。Caliper评估性能,生成一组性能指标,如吞吐量、延迟和结构的资源使用情况(即流量、平均CPU和节点的内存利用率)。在Caliper完成其操作后,Prometheus提取每个节点的内部度量。为了训练DRL模型,索引包括代理类型、执行次数、参数、吞吐量、延迟以及所有节点的内部度量和资源使用情况。为了识别重要的参数,我们存储推荐的参数值,以及每次在基准套件测试后获得的性能指标(吞吐量和延迟),并形成一个数据对。
模型训练:织物的自动调整旨在确定连续空间中参数和性能的最佳配对,这是一个NP-hard问题。强化学习具有很强的决策能力,在初始阶段可以从有限的样本中学习[30]。它是解决连续空间调谐问题的关键技术。由于参与交易的节点类型不同,每种类型的节点对性能的贡献也不同。据此,我们设计了一种新的多智能体DRL算法,可以针对不同类型的节点实现参数的异构调整。第4.2节介绍了DRL组件的定义。第4.4节详细解释了提出的算法。
重要参数识别:图2 (D)展示了如何应用LASSO [37]来寻找影响性能的重要参数。我们首先从训练数据库中获得参数-性能对。在应用套索模型之前,我们需要归一化样本数据。据我们所知,当要素连续且数量级大致相同时,LASSO可以提供高质量的结果。在数据标准化之后,处理过的参数-性能配对被发送到LASSO模型。然后,我们使用增量方法对影响性能的参数进行排序,从而降低织物性能特征的维数并减少训练时间。第5节描述了精确的优化方法。
四、作为DRL问题的自动调谐
本节首先定义了织物中参数和性能之间的关系,并将自动调谐公式化为DRL模型。此外,本节描述了传统的强化学习解决方案在解决多智能体协作问题时的缺点。最后,这一节介绍了我们的多代理DRL模型的自动调整结构。
4.1 参数和性能

描述参数对织物性能的影响是具有挑战性的。第一步也是关键的一步是确定参数与织物性能之间的关系模型。在这项研究中,我们使用延迟和吞吐量作为性能指标。在[39]中,交易延迟被定义为“交易确认时间减去交易提交时间”,实质上是背书延迟、广播延迟、订购延迟和提交延迟的总和[7]。从数学上讲,交易延迟可以表示如下:latency=Tc-Ts,其中tc是确认时间,Ts是提交时间。交易延迟也可以表示为:latency=Tel+Tbl+Tol+Tcl,其中Tel是背书策略时延,Tbl是广播时延,Tol是排队时延,Tcl是提交等待时间,然而,Fabric的EOV体系结构很大程度上受到了传统数据库系统的乐观并发控制机制的启发。因此,在可以并发执行多个交易的Fabric的多版本并发控制机制下,我们使用平均延迟作为我们的性能度量,其定义为:
![]()
其中,k表示成功交易的总数,latency_i表示 ith 交易的延迟时间。另一个性能指标是吞吐量,计算方法如下:
![]()
其中,k代表成功交易的总数,Tlc是全球时间中的最后提交时间,Tfs是第一次提交时间。
通过定义延迟和吞吐量,我们发现影响Fabric性能的关键因素是交易在不同阶段所花费的时间。其中,背书延迟和提交延迟由对等体消耗,订购延迟由订购者消耗,广播延迟由与对等体和订购者的通信消耗。具体来说,如前所述,这些节点和网络的性能由其节点上的参数控制。由于性能度量、各种组件和组件参数之间不确定的渐进关系,我们将pi定义为组件类型的节点的ith参数。每个参数都有其极限值。因此,我们将每个参数的限值定义如下:

其中,li是参数的下限值,ui是参数的上限值。表1给出了具体的数值。然后我们将参数和性能指标(即吞吐量和时延)之间的映射关系定义为f,性能指标可以表示为
![]()
,其中p_Pi是对等节点的ith参数,p_Oi是订购者节点的ith参数,p_Ni是网络通信的ith参数。最后,性能优化问题的目的是在(1)下计算
![]()
节点类型、参数类型以及节点对吞吐量和延迟的影响都是不同的。据此,我们将织物参数自动调整问题转化为多智能体协作问题。
4.2 问题的转化
强化学习(RL)是一个学习框架,它通过指导代理如何在环境中采取行动来最大化回报。与监督学习不同,RL在建模的初始阶段不需要大量的标记数据[25,30]。
通过试错,代理可以反复优化行为选择策略。同时,通过一种探索和开发机制,平衡未探索空间和已有知识,避免陷入局部最优。近年来,自动调谐已经取得了很好的效果[28,30]。因此,我们尝试用DRL方法来解决织物的调谐问题。
环境。环境是我们的调优目标(Fabric的一个实例)。如图1所示,包括对等体、订购者、CA、客户端和链码在内的五种类型的节点与网络(通信协议,即Gossip和gRPC)一起构成了Fabric网络架构。节点的实际组合和数量取决于特定的业务需求(例如,四个对等体、五个订购者、两个链码和两个ca)。注意,图1中的퐶푙푖푒푛푡表示基准测试套件,它发送交易测试,然后Fabric执行交易。
代理人。智能体是一种算法,用于根据状态和奖励调整输出策略,这就是我们的DRL模型。
对等体和订购者占用了执行交易的大部分时间,Fabric上的所有参数都是在对等体和订购者上配置的,所以我们为它们设计了代理。对于网络来说,虽然它的参数是在对等体和有序体中配置的,但是在Fabric中相同或不同类型的节点之间必须进行交叉通信,导致通信和性能之间的关系非常复杂。为了捕获和分析这种关系,我们将网络相关参数从对等体和订购者中分离出来,并专门为网络设计一个单独的代理。相应地,我们总共设计了三个代理。
4.2.3状态。Fabric的状态空间由不同类型的代理观察到的交易中参与节点的所有观察(内部度量和资源使用)组成。我们采用了Fabric [34]和Caliper [36]的官方文件来定义织物的状态。两层定义了对等体和订购者的状态空间、维护索引数据的内部度量(例如,푑푒푙푖푣푒푟_푏푙표푐푘푠_푠푒푛푡,指示由交付服务发送的块数),以及占用的物理资源(例如,平均CPU利用率)。对等状态下有30个内部指标和2个物理资源指标(节点的平均CPU和内存利用率)。订购者在状态中有30个内部指标和2个物理资源状态信息(节点的平均CPU和内存利用率)。我们选择了37个内部度量(Gossip和gRPC,即10个来自订购者,27个来自对等者)和来自对等者和订购者的4个物理资源状态信息元素(即网络的资源消耗状态:流量输入和流量输出)作为网络状态。
4.2.4行动。如前所述,我们将结构网络中每个节点的参数作为一个动作。我们的目标是覆盖尽可能多的参数,以便对参数和性能之间的关系进行彻底和系统的分析,无疑排除了一些与性能没有明显关系的参数,例如listenAddress,该对等体将侦听的本地网络接口的地址。最后,如表1所示,我们选择了51个参数作为我们的操作:12个用于对等点,10个用于订购者,29个用于网络。
4.2.5奖励。定义奖励函数在强化学习中至关重要,它决定了强化学习模型的实际效果。量化和高度稀疏是大多数实际场景中设计奖励时遇到的两个主要问题。直观上,直接用优化目标作为奖励是有效的;但是,我们无法对测量的性能结果进行定量分析。相应地,我们考虑了前一次的性能变化和初始时间的性能变化。基于以上所述,我们使用r,T,和L分别代表会爆、吞吐量和延迟。
我们将T0和L0分别定义为调整前的吞吐量和延迟。Tt和Lt、Tt-1和Lt-1分别是时间t和t-1的性能指标。我们使用等式。(2)和(3)分别计算δT和δL。吞吐量和延迟的增长率由δT和δL表示,不仅考虑了初始值和当前值之间的变化,还考虑了当前测量值和上一次测量值之间的变化。由于延迟和吞吐量是两个相反的指标,所以这两个优化指标的方向应该是一致的。因此,当我们计算时延的δL时,我们在它的方程前面加上一个负号,它与δT的格式相同。因此,当我们的RL模型计算回报时,增加吞吐量或减少延迟将给出正反馈。
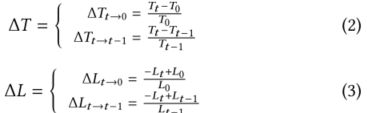
由于许可的区块链和分布式数据库之间的相似性,我们试图使用[30]中的方案,并在数据库领域中获得稳健的结果,以形成我们的奖励函数;然而,该方案并不合适。这主要是因为它的报酬函数是线性的。因此,尽管每个调整参数都提高了性能,但在多代理领域获得的回报是微不足道的。经验上,我们发现模型很难收敛。因此,我们使用指数奖励函数来更加关注性能的变化。
一旦业绩变化显著改善,回报令人满意,模型收敛快。我们使用等式。(4)和(5)通过吞吐量和等待时间计算回报。指数回报函数不仅可以更好地捕捉性能变化,而且对这种变化更敏感。此外,在所有系统中,由于各种直接和间接的原因,同一任务的多次运行的性能会有所不同。因此,我们使用 η \eta η作为衡量绩效变化的影响因素。当用户使用我们的方案时,当奖励值显著变化时,性能指标的改善是最小的,因此,需要降低 η \eta η。当报酬和绩效指标的值变化很小时, η \eta η需要增加。

如等式所示。(6)、在计算最终回报时,我们同时考虑吞吐量和延迟。所以我们把它们乘以一个系数,求和,计算出每个代理人的报酬。CT和CL的系数需要用户调整,总和将为1。
4.3 RL用于自动调参
传统的单主体逆向物流可以分为两类,即基于价值的逆向物流和基于政策的逆向物流。q学习和深度q网络(DQN)是基于价值的强化学习中最经典的算法。如果将这些应用于多智能体系统,每个智能体必须将其他智能体视为环境,这使得模型难以收敛[41]。在多智能体系统中,如果其他智能体被视为环境,这意味着环境会由于其他智能体的不断优化而变得动态和不断变化。所以这是一个动态的马尔可夫决策过程,与马尔可夫决策过程的静态不变性(概率和报酬不变)相反。另一种方法涉及政策梯度算法。如果算法直接应用于多代理系统,价值函数依赖于其他代理的策略。代理数量的增加导致计算出的政策梯度和实际梯度的方向之间存在很大差异,使得模型即使在反向优化的情况下也很难收敛[41]。深度确定性策略梯度(DDPG)在自动调优数据库问题上取得了良好的性能[28,30]。它使用重放缓冲器来消除输入体验中的相关性,并利用目标网络方法来稳定训练过程。尽管如此,它仍然受到单个代理所面临的上述问题的限制。换句话说,单智能体RL方法不能直接用于多智能体协作系统的参数调整和优化。因此,在接下来的段落中,我们将描述使用多代理DRL来优化结构。
4.4 PB-MADDPG用于自动调参
多智能体深度确定性策略梯度(MADDPG) [41]是一种针对多智能体的DRL方法,它将DDPG算法与协作式多智能体学习架构相结合。图3 (A)说明了MADDPG框架。每个代理有两个网络:行动者网络휇和批评家网络q。行动者网络根据代理获得的状态计算要执行的动作,而批评家网络评估行动者网络计算的动作以提高行动者网络的性能。在训练阶段,演员网络仅从自身获取观察信息,而评论家网络获取其他代理的动作和观察等信息。在执行阶段,不涉及评论家网络,每个代理只需要一个演员网络。MADDPG使用集体行为值函数来训练代理考虑参与交易的所有节点的参数对结构性能的影响,这可以由多智能体系统的不稳定环境减轻。同时,每个代理只需要基于局部观测做出独立的决策,就可以调整网络中不同类型节点的不同参数,实现多代理的分布式控制。此外,MADDPG具有DDPG的所有优点,可以直接输出具体动作来处理参数的高维性和连续性问题。
但是,MADDPG算法要求为每个节点设置一个代理。每个代理对应一个演员和一个评论家。在过程中有许多代理,有许多模型对培训不友好。值得注意的是,MADDPG算法在训练评论家时需要所有代理的状态和动作信息作为输入。由于Fabric是可扩展的,输入维度将随着用户的增加而快速显著地增加,这对模型训练来说是灾难性的。因此,我们进一步扩展了MADDPG并实现了一个算法,即许可区块链MADDPG (PB-MADDPG ),它符合织物的实际情况。图3 (B)展示了PB-MADDPG的框架。我们设计了一个两部分优化。首先,由于相同类型的节点在Fabric中扮演相似的角色,我们为每种类型设置一个代理。我们将参与节点分为三组:对等节点、订购节点和网络节点。相同类型的节点具有相同的配置,从而减少了训练模型的数量并加速了整体训练。第二,受[40]的启发,我们在原有的MADDPG架构中增加了一个调度器,进一步抽象所有代理的观测值,并根据它们的类型分别计算被观测节点状态的平均值。例如,当我们计算抽象时,有四个对等点和三个订购者。因此,我们收集四个对等体的状态,并计算平均值来构建一个32维的数组。此外,我们同时收集三个订购者的状态,并计算平均值,以构建一个32维的数组。在收集了所有对等点和订购者的网络状态来计算平均值之后,我们构建了一个41维的数组。然后,我们将这三个数组作为抽象组合成一个新的数组。因此,每个抽象的数组长度是恒定的(105维)。

形式上,我们根据内部指标将ith节点的状态定义为Smi,根据物理资源占用情况将ith节点的状态表示为Spi。ith节点的观测值是
![]()
我们假设在结构网络中有 α \alpha α对等方和 β \beta β订购方。进一步,我们将对等体的状态空间定义为
![]()
,和订购者的状态空间为

请注意,网络的状态是从对等方和订购方获得的。因此,网络的状态空间是

然后,我们将结构的状态空间定义为
![]()
接下来,我们通过同级代理定义观察到的节点的抽象为
![]()
其中o_ip表示ith对等节点的观察集。然后,我们将订购者和网络代理观察到的节点抽象定义为

最后,我们将所有代理的观察抽象定义为
![]()
如图3 (B)所示,我们在演员和评论家架构下使用分散执行和集中训练方法。在执行阶段,每个参与者可以根据状态(Ap、Ao或An)本身采取适当的a行动。因此,不需要其他代理的状态或动作。当每个评论家在训练阶段计算Q值时,调度器将发送所有代理的动作和抽象。评论家根据估计Q值和实际Q值进行训练,演员根据评论家反馈的估计Q值更新策略。每个评论家的输入确保特定维度将保持不受影响,尽管增加了代理,避免了状态空间的爆炸并提高了收敛效率。接下来,我们提出了PB-MADDPG算法,它解决了织物的参数调整问题。算法1给出了PB-MADDPG算法的伪代码,其详细描述如下。(1)首先,我们为每个节点类型的代理初始化演员和评论家的在线和目标网络。然后我们开始如图3 (B)所示,我们在演员和评论家架构下使用分散执行和集中训练方法。在执行阶段,每个参与者可以根据状态(퐴푝、퐴표或퐴푛)本身采取适当的푎行动。因此,不需要其他代理的状态或动作。当每个评论家在训练阶段计算Q值时,调度器将发送所有代理的动作和抽象。评论家根据估计Q值和实际Q值进行训练,演员根据评论家反馈的估计Q值更新策略。每个评论家的输入确保特定维度将保持不受影响,尽管增加了代理,避免了状态空间的爆炸并提高了收敛效率。
接下来,我们提出了PB-MADDPG算法,它解决了织物的参数调整问题。算法1给出了PB-MADDPG算法的伪代码,其详细描述如下。
(1)首先,我们为每个节点类型的代理初始化演员和评论家的在线和目标网络。然后我们开始用于探测动作的随机过程N,部署结构网络,接收收集的结构初始状态s并计算抽象a(第1-3行)。
(2)接下来,我们执行 max-episode-length迭代,每个代理根据其策略( μ θ n ( A i ) \mu_{\theta_{n}}(A_i) μθn(Ai),其中 μ θ n \mu_{\theta_{n}} μθn是演员策略, A i A_i Ai是代理的观察的摘要) 和探索噪声Nt选择动作(ai,parameters)。在每个节点分配新的动作之后,整个结构网络将被重新部署(第4-5行)。然后,我们使用基准套件(Caliper)测试织物在奖励r方面的性能,奖励是使用公式计算的。(2-6).请注意,我们的目标是最高的整体性能;所以,每个代理人的报酬是一样的。同时,部署基准测试套件来收集状态s’并计算Fabric中每个节点的抽象A′。当前状态A、已执行动作a、奖励r和新状态A’,然后作为元组(A,a,r,A’)存储在体验重放缓冲器(experience replay
buffer )D中因此,在执行阶段,代理可以根据当前状态A’输出推荐的配置a。所有节点都重新配置了输出配置,基准测试套件执行测试、收集状态并计算所有节点的A’。之后,我们将状态A’更新为A,并在下一次迭代开始时将其用作状态A(第6-8行)。
(3)在执行整个过程之后,每个代理将执行以下步骤来更新其演员和评论家网络。首先,每个节点的代理从经验重放缓冲区D中随机选择一小批S样本然后,我们将Q-function的目标值设定为 y j y^j yj,其中 r i j r_i^j rij是ith代理商从jth样本中获得的报酬, γ \gamma γ是贴现因子(discount factor)。
![]()
是一个集中的行动价值函数,它采取所有代理人的行动,
![]()
,除了抽象 A ′ j A'^j A′j作为输入,代理i的Q-value作为输出。 a k ′ a'_k ak′是通过把代理抽象 A k A_k Ak馈送给政策 μ ′ \mu' μ′(lines 9-11)而获得的。

通过最小化 y j y^j yj和 Q i μ ( A j , a 1 j , . . . , a N j ) Q_i^\mu(A^j,a_1^j,...,a_N^j) Qiμ(Aj,a1j,...,aNj)之间的差异来更新评论家网络的 θ \theta θ.类似地,我们基于梯度上升更新演员网络的 θ \theta θ(第14-16行)。(4)最后,我们更新演员和评论家的在线网络,之后在软更新下更新他们的目标网络参数(第17-18行)。
五、重要参数识别
在我们的架构中,我们使用LASSO作为过滤器,根据性能对参数的重要性进行排序。它被广泛应用于特征重要性的选择,并取得了突出的成果[26,37]。LASSO通过结合最小二乘法和在其基础上构建的L1正则化函数,压缩一些系数并将一些系数设置为零,获得了一个更精确的模型。根据系数,在拟合广义线性模型时筛选变量[26]。训练数据是每次训练MADDPG时获得的推荐参数值和吞吐量。研究[26,42]表明,当要素连续、数量级近似且方差相似时,LASSO可以提供高质量的结果。
因此,在使用LASSO对参数的重要性进行排序之前,我们首先对数据(值减去平均值除以标准偏差)进行归一化,以使它们具有相同的数量级。然后,我们使用LASSO回归对参数的重要性进行排序。数学上,Athena解决如下优化问题:
![]()
,其中n是训练样本数,Y是织物的吞吐量,X是织物参数的向量, θ \theta θ代表每个特征的系数, λ \lambda λ是用于调整每个参数系数稀疏强度的超参数。我们首先给LASSO一个很高的惩罚项,然后减少惩罚并记录每个新的参数。参数出现的顺序暗示了它们对性能的影响。
六、实验
本节评估Athena的表现。我们选择了各种最具代表性的Fabric静态配置调谐器和性能优化方法作为基线:Default:Fabric提供默认配置。
手动:由从事织物调优和优化四年的区块链专家进行手动调优。
FastFabric: FastFabric [29]是一种性能优化方法,实现了基于v1.4的并行和加密消息缓存等技术。我们将主要优化方法、缓存的解组块、并行验证和哈希表移植到Fabric v 2 . 4 . 3;我们在我们的硬件环境中复制了它,以便与调优方法进行比较。
Bestconfig: Bestconfig [31]是一种基于搜索的调谐器方法。
我们从Bestconfig中提取了分治采样(DDS)和递归定界搜索(RBS)算法,并将其应用于结构调整参数。
OtterTune: OtterTune [26]是一种基于贝叶斯优化的调优方法。我们使用从其他几个调优方案收集的参数和性能指标作为训练数据,来形成OtterTune的高斯过程(GP)模型。然后,我们在GP模型中使用随机梯度下降随机选择配置以找到局部最优。
CDBTune: CDBTune [30]是一种基于单代理DRL的调谐器方法。我们使用一个代理来调整所有节点的参数。
Qtune: Qtune [28]是一个支持查询的数据库调优系统,采用DRL模型。我们采用了它的工作负载级查询优化方法。它与CDBTune的不同之处在于,它利用预先训练的模型来预测内部指标。
ResTune: ResTune [15]是一种基于贝叶斯优化的调优方法。与OtterTune的主要区别是将单个GP扩展为具有多种资源类型(例如CPU)的高斯回归过程,并增加了服务级别协议(SLA)。在我们的实现中,我们优化了两个指标,即吞吐量和延迟。
雅典娜:雅典娜是我们的方法,使用多代理DRL来调整织物。
Athena-FastFabric:Athena-fast fabric使用Athena来调整fast fabric上的参数。
6.1设置
在我们所有的实验中,我们使用Fabric v2.4.3和Raft。认可策略被设置为“或”所有组件都在Docker容器中运行。此外,实验是在云服务器上运行的。每两个节点部署在一个使用32 GB内存的英特尔至强(Ice Lake)白金8369B (8个vCPU)的实例上。机器通过万兆以太网连接。操作系统是Ubuntu 18.04。我们使用Python 3和TensorFlow实现Athena的所有算法和组件,使用Python 3实现所有其他算法。
我们使用Caliper基准测试中的简单和小型银行,它们在之前的研究中被用作代表性工作负载[16,29]。Simple和Smallbank使用16个工作进程执行基准运行,并在每轮中以固定的800 txn/sec发送速率提交200000个TXs。我们在实验中考虑了高级评估方案,如[31]、[26]和[30]。我们需要注意的指标包括训练时间、吞吐量和延迟。注意,我们设置了三种主要的Fabric网络配置进行评估:C1、三个订购者和四个对等者;C2,五个订购者和八个同行;C3,七个订购者和十二个同行。实验进行三次,并记录平均值。
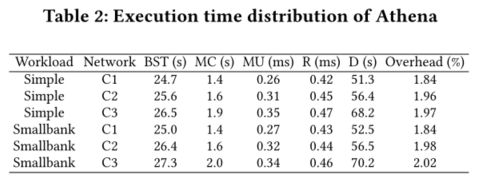
6.2 执行时间分解
本节将一个训练调整步骤分为五个阶段:1 .基准测试套件测试(BST):基准测试套件将工作负载发送到结构网络。
2.度量收集(MC):收集由Caliper计算的结构集群、吞吐量和延迟中的观察值,并将它们存储在训练数据库中。
3.模型更新(MU):用收集的训练数据更新模型参数。
4.建议®:输入观察值以输出建议的参数。
5.部署(D):根据推荐的参数部署结构网络。
如表2所示,我们在评估中使用了基于Simple和Smallbank的三种网络配置(C1、C2和C3):首先,Athena通过自动重启Fabric将部署时间减少到1.5分钟以下。但是,平均来说,部署时间仍然占整个方案的68%。任何优化方案都不可避免地要以织物的大部分参数生效为前提。其次,MU和MC仅消耗少量时间(开销,在我们的模型中,MU和MC在一个调优步骤的总时间中所占的百分比为1.8% - 2.1%),与部署结构网络和BST(执行交易)的持续时间相比,这几乎可以忽略不计。
6.3调整效果和效率比较
本节通过与Default、Manual tuning、FastFabric、Bestconfig、OtterTune、CDBTune、Qtune、ResTune和Athena-FastFabric在不同工作负载(Smallbank和Simple)和不同Fabric网络架构下的比较,评估Athena的有效性和效率。请注意,当输出吞吐量连续五次波动小于3 txn/sec时,我们认为调谐过程已经达到收敛。为了测试我们方法的可伸缩性,四个、八个和十二个对等点分别对应于C1、C2和C3。我们将订购者的数量固定为7,同时将对等点的数量从16扩展到32,如图4所示。我们的发现如下。
- Athena的调优解决方案可以很好地适应节点数量。
图4显示了第4步中对等体数量从4到32变化的结果。Athena实现了大约(379.66%、422.73%、470.45%、478.51%、536.63%、490.32%、511.63%和541.89%)和(365.24%、401.24%、434.75%、541.28%、632.95%、569.51%、619.18%和703.39%)更好的吞吐量,以及(700.89%)
- Athena与FastFabric正交。当使用Smallbank通过第4步将对等机从4变到32时,Athena可以将FastFabric吞吐量和延迟分别提高(58.42%、65.94%、68.80%、71.33%、74.23%、76.40%、89.38%和97.59%)和(54.14%、62.00%、64.41%、57.68%、52.98%、53.14%和54.91%)。与FastFabric相比,Athena基于Smallbank实现了大约(26.32%、37.05%、41.14%、44.75%、48.90%、52.00%、70.54%、82.27%)更好的吞吐量和(22.93%、33.00%、41.53%、45.69%、42.81%、38.29%、44.63%、43.60%)更好的延迟。
3)由于专家只选择了他们认为重要的四个参数进行调整,手动调整的最佳结果仅比C3的默认设置高134.85%。此外,与数据库专家不同,区块链的优化无法掌握所有参数之间关系的全貌。当我们以手动调优为基准时,Athena、Bestconfig、OtterTune、CDBTune、Qtune和ResTune的平均吞吐量和延迟超过了C3 small bank上的(100.32%、26.13%、31.36%、68.06%、75.16%和83.23%)和(59.65%、21.93%、35.38%、42.34%、44.09%和42.63%)以及(88雅典娜取得了最好的成绩。即使与最先进的方案(CDBTune、Qtune和ResTune)相比,我们的方法也有(31.62%、32.63%和32.26%;28.77%、26.95%和25.16%;29.91%、29.94%和27.10%)和(18.97%、13.99%和18.64%;17.06%、14.23%和15.21%;17.31%、15.56%和17.02%)根据Smallbank的数据,在吞吐量和延迟方面分别领先于C1、C2和C3。从不同工作负载的效果来看,Simple的所有调优结果都略好于Smallbank,但差距很小,因为Fabric对类似字节的工作负载不太敏感。
4)在对多个节点进行伸缩后,我们发现调优的时间随着节点数量的增加而增加,主要是因为节点的增加导致启动时间的增加。至于效率,Bestconfig是(C1、C2和C3)之下最好的(230分钟、343分钟和398分钟)。然而,作为一种搜索解决方案,Bestconfig很容易陷入局部最优,这从另一方面来说,意味着它的周期很短。雅典娜的性能提升是(4.59,4.73,4.84;分别比Smallbank和Simple under (C1、C2和C3)上的Bestconfig高4.59、4.64和4.72倍,以手动调优为基线。因此,即使Bestconfig的训练时间最短,其调优效果不尽如人意。与CDBTune和Qtune相比,虽然都使用RL,Athena的效率分别为(65.59%、52.15%和54.93%;41.61%、49.82%和49.95%)更好,因为模型选择更简单。
此外,Athena的指数奖励函数比线性奖励函数更有效,并显著增加了对吞吐量和延迟变化的关注。此外,它还可以缩短培训时间。为了能够进行公平的比较,我们在计算OtterTune和ResTune的训练时间时添加了收集数据的时间,这些时间分别占(30.32%,28.96%,23.44%;36.81%、23.07%和23.84%)比雅典娜(C1、C2和C3)在小银行的培训时间长。Athena的效率总是优于其他算法。专家只能进行手动调优,因此不能像其他方案一样精确记录和计算所花费的时间,图中不会显示。
雅典娜可以产生很好的优化效果。一方面,多代理DRL可以更好地捕捉不同类型节点的性能和参数之间的关系。此外,所提出的指数奖励函数对性能变化更加敏感,并且加快了模型的训练速度。这两个方面的结果使得Athena比基线更加有效和高效。

6.4参数数量的影响
为了在后续实验中更好地展示有限数量的参数对性能的影响,我们首先使用LASSO [37]通过利用在用Smallbank调优实例C1期间收集的数据来对参数的重要性进行排序。为了清楚起见,我们只显示了这些结果中最有影响的十个参数。
图5显示了回归模型中各种参数的权重向量。同时,前三个都是网络相关的,第四个是订购者相关的。影响性能的前十个参数中有三个与网络有关,两个与订购者有关,五个与对等方有关。
此外,从所有参数的排序结果来看,以往对织物性能调优的研究主要集中在块大小参数上;我们发现了与块规则相关的四个参数,即PreferredMaxBytes、AbsoluteMaxBytes(排名34)、BatchTimeout(排名36)和MaxMessageCount(排名37)。
根据我们的实验,这些排名都没有之前研究中的排名高,甚至PreferredMaxBytes排名第四,也只是一般。本质上,许多与性能相关的参数在现有研究中尚未确定。
为了更好地评估性能调优,我们分析了影响性能的前五个参数的原因。
CORE _ PEER _ GOSSIP _ STATE _ BLOCBUFFERSIZE是最关键的参数,反映了重排序缓冲区的大小。我们认为此参数排名较高,因为增加块数据的缓存空间有助于对等方提高拉取块的效率,从而帮助他们快速验证,从而提高吞吐量。第二个是PUBLISHCERTPERIOD时间启动证书包含在实时消息中。这确保了对等体中证书的可用性,并极大地影响了对等体之间块信息的连续传输。接下来是CORE _ PEER _ GOSSIP _ propagate iterations,表示一条消息被推送给远程对等体的次数。一条消息并行推送给更多的对等体,可以更好地利用Fabric并行执行的优势,提高吞吐量。第四个是PreferredMaxBytes,批处理中序列化消息允许的首选最大字节数。此参数是结构切片中触发的第一个规则。增加块的字节数可以在块中包含更多的交易,减少对等体从排序方提取块的频率,从而提高性能。
CORE _ PEER _ KEEPALIVE _ min interv AL是第五个重要参数,是客户机pings之间允许的最小时间间隔。
此参数控制客户端和对等方之间的ping频率。如果这个时间太短,客户端频繁发送pings,导致对等端和客户端断开连接,导致对等端失去联系。
根据LASSO的排序结果,我们每次多使用十个参数进行调谐。图6显示了在Smallbank的工作负载下,基于C1的Athena、Bestconfig、OtterTune、CDBTune、Qtune和ResTune的调优结果。当我们调整20个参数时,所有参数的吞吐量分别达到(99.64%、83.00%、93.00%、95.30%、94.00%和83.00%)。潜伏期比对照组所有参数分别增加了1.93%、4.30%、5.60%、6.10%、5.80%和9.20%。性能相当于调整所有参数。然而,好处是明显的。
与调整所有参数相比,训练时间分别减少了48.20%、32.30%、41.20%、39.40%、40.20%和48.79%。
因此,我们认为,训练时间可以显着减少,如果重要的参数被确定。


6.5适应性
本节验证Athena对不同网络配置的适应性。由于结构是可扩展的,用户可以根据业务需求加入网络。因此,这种可扩展性自然要求调优模型具有良好的适应性。我们对两个实例进行了实验(基于小型银行的工作负载,在C1和C3)。首先,我们使用C1到C3 (C1→C3)实例的推荐参数。然后,我们评估了实例C1和C3默认参数、C1→C3、C1调优(雅典娜调优于C1)和C3调优(雅典娜调优于C3)的性能。如图7所示,Athena推荐的配置具有适应性。将C1推荐的配置应用于实例C3,与默认C3相比,吞吐量提高了350.4%,是重新调整后吞吐量的95.6%。
6.6奖励函数的评估
本节评估雅典娜的奖励功能。为了验证我们的指数奖励函数(RF-Athena)的优越性,我们将其与CDBTune的线性奖励函数(RFCDBTune)进行了比较。如图8所示,我们使用三种配置,即C1、C2和C3,链码是Smallbank,而它固定在퐶푇 =퐶퐿=0.5.我们发现,在两种配置下,无论是吞吐量、延迟还是训练时间,RF-Athena都优于RF-CDBTune。(C1、C2、C3)发现的RF-Athena的吞吐量、延迟和训练时间分别比Smallbank下的RF-CDBTune好26.08%、29.94%和28.84%、42.93%、37.96%和37.17%、51.85%、50.00%和45.93%。一方面,导致这种结果的原因是指数奖励函数可以根据性能变化按比例增减奖励值,从而使模型更好地收敛。另一方面,当线性奖励函数面对多主体RL模型时,所获得的奖励值最小,显著增加了模型收敛的时间。综上所述,与线性奖励函数,我们提出的指数奖励函数在调整允许区块链的参数时可以获得更好的性能和更快的收敛速度。
η \eta η是方程中的一个重要参数。(4)和(5)。它的贡献是解决由于光纤网络架构或其他外部原因造成的性能反馈差异。为了评估휂的影响,我们将C1、C2和C3上的 η \eta η从1变到19(链码是Smallbank),而CT= CL = 0.5是固定的。图9显示了结果。我们发现(C1、C2和C3)的 η \eta η的最佳性能值分别为(10、13和16)。实现最佳性能的所有 η \eta η值都在10以上。 η \eta η值需要更大,因为参数调整空间主要由许多参数产生。需要增加 η \eta η值以增加其对性能变化的敏感性。在这项研究中, η \eta η值被用作超参数,以帮助用户更好地优化自动调谐效果。
我们设计了吞吐量和延迟权重参数CT和CL ,以权衡等式中的两个优化目标。(6).为了观察两者对优化性能的影响,我们基于[30]将CT= CL = 0.5的性能设置为基准。我们用C1的例子做实验;连锁代码是小银行。图10显示了结果。我们观察两个优化目标的变化率。随着CT的增加,吞吐量变化率增加,相应的延迟变化率也增加。这是因为增加CT会增加吞吐量变化对回报的贡献。但是,它会减少延迟的贡献。
通常,在调整这三个参数时,管理员首先根据要求确定CT和CL 。在高吞吐量的要求下,增加CT,或降低CL 以获得低延迟。在确定CT和CL 之后,管理员最初将휂定义为10,并根据奖励值调整 η \eta η。如果报酬波动显著,降低 η \eta η;如果奖励小,增加 η \eta η.
6.7容错性的评估
本节评估两种类型的崩溃:(1)订购者崩溃:Fabric的共识算法是Raft,具有崩溃容错性。我们发现,中断领先或非领先订单对性能的影响有限。这是因为,在订餐服务中,主导订餐者执行订餐流程,其他节点只是备份操作。在首节点崩溃后,非领导排序者在短时间内选出新的领导。(2)对等体崩溃:虽然其他节点可以补偿组织内对等体的崩溃,但这会增加其他节点上的背书工作,从而显著影响性能。为了评估Athena对具有对等崩溃的集群的影响,我们在步骤1中将它们从1变化到6,并将其他参数固定为Smallbank的C3的默认值。
如图11所示,Athena获得了最好的结果,其中Athena调优的吞吐量和延迟分别为(355.29%、346.35%、473.33%、548.81%、601.13%和721.13%)和(71.63%、73.62%、74.08%、78.71%、77.17%和77.28%),优于默认崩溃。比较表明,Athena能够在崩溃状态下促进光纤网络的持续使用和卓越性能。
6.8总结
从这些测试中,我们发现了以下情况。
(1)我们的Athena的开销是最小的,每次调优过程只需要花费1.8% - 2.1%。
(2) Athena实现了最佳的调优性能。在C1旗下的Smallbank上,( Athena、Bestconfig、OtterTune、CDBTune、Qtune和ResTune)的吞吐量和延迟分别提高了(100.32%、26.13%、31.36%、68.06%、75.16%和83.23%)和(59.65%、21.93%、35.38%、52.34%、54.09%和52.63%)以及(89.78%、24
(3)在C1下,调整20个参数的吞吐量相当于调整所有参数效果的99.64%。延迟只能增加1.93%,几乎可以忽略不计,调优时间减少48.79%。
(4)尽管网络发生了变化(C1→C3),Athena推荐的配置与默认配置相比可以实现350.4%的吞吐量提升。
(5)通过(C1、C2和C3)确定的Athena指数报酬函数的吞吐量、延迟和训练时间分别比Smallbank下的线性报酬函数好26.08%、29.94%和28.84%、42.93%、37.96%和37.17%、51.85%、50.00%和45.93%。
(6)容错方面,Athena调优的吞吐量和延迟分别为(355.29%、346.35%、473.33%、548.81%、601.13%和721.13%)和(71.63%、73.62%、74.08%、78.71%、77.17%和77.28%),优于默认崩溃。
七、讨论
本节讨论了关于在生产中使用Athena的一些细节,旨在阐明一些具体要点。
目标用户:Athena的目标用户是由现实世界中的参与组织选出的管理员,他有权访问所有服务器并修改结构配置。选举管理员的原因如下:(1)确保每个节点的参数调优结果的一致性。(2)所有组织都给管理员权限,可以防止节点之间的数据泄露。优化完成后,每个组织根据管理员的建议配置其节点配置。建议所有节点的参数被设置为相同,因为实验表明节点中的一些参数是不同的,使得系统不可用。配置完成后,每个组织可以禁用管理员的访问权限,以确保生产环境数据的安全性。

操作流程:在生产中,Athena采用上述的集中调优和分布式部署。管理员使用示例工作负载来优化Fabric,以生成用于实际工作负载的建议。此外,组织用户可能加入或退出,硬件环境可能发生变化,或者业务场景发生变化。作为一个选项,管理员可以使用在之前的调整过程中收集的数据,通过LASSO对参数进行排序。管理员可以选择结构的重要参数来重新调整所有节点,并将其他参数保留在其默认配置中。
可用平台:总的来说,Athena已经适应了Fabric 1.4.x - 2.4.x的所有版本。目前,我们正在积极推动Athena适应其他类型的许可区块链(如FISCO BCOS)。
八、结论
在本文中,我们提出了Athena,这是一种基于结构的自动调整系统,它可以自动提供参数以获得最佳性能,并且只需要控制器具有管理权限,就可以在训练阶段修改配置并重启结构。
首先,我们在理论层面上引入参数与性能之间的关系,将织物参数调整问题转化为多智能体协调问题。其次,我们提出了一种新的PD-MADDPG算法来有效地解决这个问题。此外,我们选择对提高调谐效率贡献最大的参数。
最后,我们通过实验验证了Athena的建议比默认配置有效得多。相比之下,我们的方法优于其他三个最先进的解决方案。因此,我们是最早研究自动调优以优化区块链性能的公司之一。
在今后的研究中,我们将更好地平衡节点数量和代理之间的关系,以解决更复杂的异构硬件配置问题。同时,我们计划将我们的方法扩展到其他区块链系统。