【题解】CSP-J2021第二轮题解
CSP-J2021第二轮题解
T1.分糖果 ⊗ \otimes ⊗
简化题目:给定 l , r l,r l,r,求 max i = l r ( i m o d n ) \max_{i=l}^{r}(i\bmod n) maxi=lr(imodn)。
分类讨论,根据 ⌊ i n ⌋ \lfloor\frac{i}{n}\rfloor ⌊ni⌋ 将整数分组,若 l l l 与 r r r 在同一组中,那么答案为 r m o d n r\bmod n rmodn;否则,答案为 n − 1 n-1 n−1。具体见下图。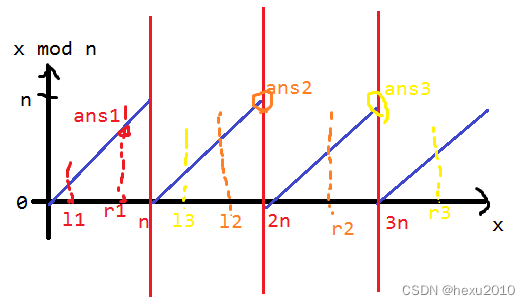
T2.插入排序 ⊗ \otimes ⊗
这是一道插入排序的好题,从插入排序的基本思想上出,确实是“更好地理解插入排序”。
插入排序的思想:设原序列为 a i a_i ai,则插入排序函数 f ( 1 ∼ n ) f(1\sim n) f(1∼n) 的实现方法就是先处理好 f ( 1 ∼ n − 1 ) f(1\sim n-1) f(1∼n−1) 的部分,在将 a n a_n an 放到合适的位置。过程如下:
a = {[1],4,2,8,5,7} ⇒ \Rarr ⇒ a = {[1,4],2,8,5,7} ⇒ \Rarr ⇒ a = {[1,2,4],8,5,7} ⇒ \Rarr ⇒
a = {[1,2,4,8],5,7} ⇒ \Rarr ⇒ a = {[1,2,4,5,8],7} ⇒ \Rarr ⇒ a = {[1,2,4,5,7,8]}
故其为 O ( n 2 ) O(n^2) O(n2) 的算法。我们还要结合题目中给的代码分析一下排序的性质:
for (int i = 1; i <= n; i++)
for (int j = i; j >= 2; j--)
if (a[j] < a[j-1]) {
int t = a[j-1];
a[j-1] = a[j];
a[j] = t;
}
这份代码的排序方式:1.从小到大排列。2.碰到相同的数时,原序列中位置靠前的在前面。
一些基本的东西终于讲完了,现在针对这道题讲一下啊。首先根据排序方式的第二点,可以得出整道题我们要将一个数的位置和值绑在一起,即一个形如 ( a i , i ) (a_i,i) (ai,i) 的 pair 。根据 pair 的优先级,在比较整个 pair 时会先比较 a i a_i ai 的值,再比较 i i i 的值。接下来,在针对操作讲一下。从复杂度的角度来看, n ⩽ 5000 , Q ⩽ 200000 n\leqslant5000,Q\leqslant200000 n⩽5000,Q⩽200000,每个操作所给的时间并不多。但是,做题的时候,要注意——**看题!**题目中说,操作 1 1 1 的个数不超过 5000,说明操作一的复杂度可以放宽来, O ( n ) O(n) O(n) 刚刚好。由此还可以得知操作二的复杂度就是 O ( 1 ) O(1) O(1)。假如没有操作一,这题非常简单,有了操作一之后,维护 p [ i ] p[i] p[i] 表示原序列第 x x x 个数现在所处位置即可。
接下来,这道题的精华就出来了——考虑操作一给结果带来的变化。根据插入排序的思想,每一个数都慢慢向前面“漂”过去,整个序列的排序是随着每个数位置的确定而确定。所以,操作一的 O ( n ) O(n) O(n) 做法就是让被修改的数找到它的位置。过程中,每一次交换都让两个的 p p p 值互换。但令人惊奇的是,操作二 O ( n ) O(n) O(n) 竟然能过……
T3.网络连接 ⊗ \otimes ⊗
大模拟。关于大模拟的题目,洛谷日报有一期专门讲了,还是挺不错的。
网上虽然有用 sscanf 的方法,但是我不太会,考场上也不一定想得到,这里主要讲一下分类讨论和模块化的思想。
模块化能让你的代码少出错,好调试。这里,我们如果编写了一个函数 check \text{check} check,那么主函数的代码将会非常简短,非常好编写,重心全部落在 check \text{check} check 函数怎么写了。题目中给定的要求是形式为 a.b.c.d:e, 0 ⩽ a , b , c , d ⩽ 255 0\leqslant a,b,c,d\leqslant255 0⩽a,b,c,d⩽255, 0 ⩽ e ⩽ 65535 0\leqslant e\leqslant 65535 0⩽e⩽65535。那么,只需要判断两个:1.形式是否合法。2.数字是否符合要求。判断形式是否合法,主要是判断 . 的个数和 : 的个数以及它们的顺序。这里讲几个容易漏的点:注意形如 .9.63.198:8080 和 89..22.198:8080 等,也就是符号的位置不对。判断数字是否符合要求比较简单,不要漏了前导 0 就好了。
这题细节真的是很多,考场上如果不用 sscanf 真的很难 AC,来试一试你能拿多少分吧!
T4.小熊的果篮 ⊗ \otimes ⊗
这题主要考察 STL 的运用,还看一点运气。我考试的时候换了好几个方法,结果都没出来。正解是用两个 set,分别记录苹果和橘子的位置。每一次先选择位置最靠前的(min(*st[0].begin(), *st[1].begin())),然后在另一边二分出下一个块的位置。这里主要是因为苹果块和橘子块是互相交织的,所以苹果的位置中第一个大于当前橘子位置的那个位置就是下一个块的开头。其他的话,还有一个小技巧,就是在操作之前提前放入 INF,方便判断苹果和橘子是不是没了,最后记得把剩余的水果都输出一下,具体见代码。
代码
T1
#include T2
#include T3
#include T4
#include 后记
我整理了一下 CSP-J2019 ∼ 2021 \text{CSP-J2019}\sim\text{2021} CSP-J2019∼2021 的题目难度(以洛谷为主):
| 年份 \large 年份 年份 | T1 \large\text{T1} T1 | T2 \large\text{T2} T2 | T3 \large\text{T3} T3 | T4 \large\text{T4} T4 |
|---|---|---|---|---|
| 2019 \text{2019} 2019 | 入门 \textbf{\textcolor{#FFFFFF}{\colorbox{#FE4C61}{入门}}} 入门 | 普及- \textbf{\textcolor{#FFFFFF}{\colorbox{#F39C11}{普及-}}} 普及- | 普及 \textbf{\textcolor{#FFFFFF}{\colorbox{#52C41A}{普及}}} 普及 | 普及 \textbf{\textcolor{#FFFFFF}{\colorbox{#52C41A}{普及}}} 普及 |
| 2020 \text{2020} 2020 | 入门 \textbf{\textcolor{#FFFFFF}{\colorbox{#FE4C61}{入门}}} 入门 | 普及- \textbf{\textcolor{#FFFFFF}{\colorbox{#F39C11}{普及-}}} 普及- | 普及 \textbf{\textcolor{#FFFFFF}{\colorbox{#FFC116}{普及}}} 普及 | 普及 \textbf{\textcolor{#FFFFFF}{\colorbox{#52C41A}{普及}}} 普及 |
| 2021 \text{2021} 2021 | 入门 \textbf{\textcolor{#FFFFFF}{\colorbox{#FE4C61}{入门}}} 入门 | 普及- \textbf{\textcolor{#FFFFFF}{\colorbox{#F39C11}{普及-}}} 普及- | 普及 \textbf{\textcolor{#FFFFFF}{\colorbox{#FFC116}{普及}}} 普及 | 普及 \textbf{\textcolor{#FFFFFF}{\colorbox{#FFC116}{普及}}} 普及 |
可以发现题目是越来越简单了,但是越简单的题目越是要得分,这样子才有机会拿到省一。