外卖返利系统,外卖返利系统小程序,外卖系统,返利系统
咕咕驴外卖返利系统,外卖返利系统小程序,外卖系统.包含淘客公众号+淘客小程序+淘客返利机器人+淘客共享APP+外卖返利小程序.
外卖返利系统|外卖返利系统小程序,外卖系统,返利系统
外卖CPS系统之小程序源码分享
外卖券外卖省省外卖探探美团饿了么外卖联盟优惠券小程序系统软件开发源码 美团/饿了么外卖CPS联盟返利公众号小程序裂变核心源码
饿了么、美团优惠开发(外卖cps,三级裂变源码)
源码或搭建
http://y.mybei.cn
截图


功能列表
-
特价电影票
-
饿了么外卖(3个红包)
-
美团外卖
-
美团优选(1分钱买菜)
-
购物返利(淘宝,拼多多,京东)
-
话费优惠充值(92折,慢充)
-
火车票优惠
-
滴滴打车优惠
-
小程序广告收益(流量主)
-
公众号绑定
-
更多功能…
-
作者联系方式
-

-
交流交流感情也好呀~
-
代搭建,源码都可以出,好谈~
-
转介绍,代理,都行,作者不会亏待你~
步骤
- 下载以上源代码到本地
http://mtw.so/6wav8W
- 修改为你自己的微信小程序,打开 /dist/pages/ele/index.js
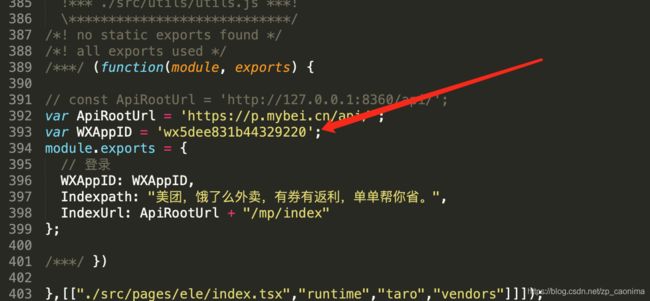
- 微信小程序->开发管理->开发设置 添加 request的域名: 地址:
https://mp.weixin.qq.com/wxamp/devprofile/get_profile?token=271531762&lang=zh_CN

- 小程序管理后台配置你的链接
后台地址: http://q.mybei.cn - 进去之后选择小程序管理->无裂变小程序管理->添加小程序->填入你自己的链接

- 微信开发者工具,导入项目,提交审核

没用的代码, 请忽略
概率论和数理统计
随机事件和概率
1.事件的关系与运算
(1) 子事件:A ⊂ B A \subset BA⊂B,若A AA发生,则B BB发生。 Notes:A AA是B BB的子事件,P ( A ) ≤ P ( B ) P(A) \le P(B)P(A)≤P(B)
(2) 相等事件:A = B A = BA=B,即A ⊂ B A \subset BA⊂B,且B ⊂ A B \subset AB⊂A 。
(3) 和事件:A ⋃ B A\bigcup BA⋃B(或A + B A + BA+B),A AA与B BB中至少有一个发生。 推广:若A 1 , A 2 , … … A_{1},A_{2},……A
1
,A
2
,……是互不相容的事件序列,则P ( A 1 ⋂ A 2 ) = P ( A 1 ) + P ( A 2 ) + … … P(A_{1}\bigcap A_{2})=P(A_{1})+P(A_{2})+……P(A
1
⋂A
2
)=P(A
1
)+P(A
2
)+……
(4) 差事件:A − B A - BA−B,A AA发生但B BB不发生。
(5) 积事件:A ⋂ B A\bigcap BA⋂B(或A B {AB}AB),A AA与B BB同时发生。
(6) 互斥事件(互不相容):A ⋂ B A\bigcap BA⋂B=∅ \varnothing∅。
(7) 互逆事件(对立事件):A ⋂ B = ∅ , A ⋃ B = Ω , A = B ˉ , B = A ˉ A\bigcap B=\varnothing ,A\bigcup B=\Omega ,A=\bar{B},B=\bar{A}A⋂B=∅,A⋃B=Ω,A=
B
ˉ
,B=
A
ˉ
(8)P ( Ω ) = 1 P(\Omega)=1P(Ω)=1
2.运算律
(1) 交换律:A ⋃ B = B ⋃ A , A ⋂ B = B ⋂ A A\bigcup B=B\bigcup A,A\bigcap B=B\bigcap AA⋃B=B⋃A,A⋂B=B⋂A
(2) 结合律:( A ⋃ B ) ⋃ C = A ⋃ ( B ⋃ C ) (A\bigcup B)\bigcup C=A\bigcup (B\bigcup C)(A⋃B)⋃C=A⋃(B⋃C)
(3) 分配律:( A ⋂ B ) ⋂ C = A ⋂ ( B ⋂ C ) (A\bigcap B)\bigcap C=A\bigcap (B\bigcap C)(A⋂B)⋂C=A⋂(B⋂C)
3.德⋅ \centerdot⋅摩根律
A ⋃ B ‾ = A ˉ ⋂ B ˉ \overline{A\bigcup B}=\bar{A}\bigcap \bar{B}
A⋃B
A
ˉ
⋂
B
ˉ
A ⋂ B ‾ = A ˉ ⋃ B ˉ \overline{A\bigcap B}=\bar{A}\bigcup \bar{B}
A⋂B
A
ˉ
⋃
B
ˉ
4.完全事件组
A 1 A 2 ⋯ A n {{A}{1}}{{A}{2}}\cdots {{A}{n}}A
1
A
2
⋯A
n
两两互斥,且和事件为必然事件,即A i ∩ A j = ∅ , i ≠ j , ⋃ i = 1 n = Ω . {A{i}} \cap A_{j}=\varnothing, i \neq j, \bigcup_{i=1}^{n}=\Omega\ .A
i
∩A
j
=∅,i
=j,⋃
i=1
n
=Ω .
5.概率的基本公式
(1)条件概率:
P ( B ∣ A ) = P ( A ⋂ B ) P ( A ) P(B|A)=\frac{P(A\bigcap B)}{P(A)}P(B∣A)=
P(A)
P(A⋂B)
,表示A AA发生的条件下,B BB发生的概率。
(2)全概率公式:
P ( A ) = ∑ i = 1 n P ( A ∣ B i ) P ( B i ) , B i B j = ∅ , i ≠ j , ⋃ n i = 1 B i = Ω P(A)=\sum\limits_{i=1}^{n}{P(A|{{B}{i}})P({{B}{i}}),{{B}{i}}{{B}{j}}}=\varnothing ,i\ne j,\underset{i=1}{\overset{n}{\mathop{\bigcup }}},{{B}_{i}}=\OmegaP(A)=
i=1
∑
n
P(A∣B
i
)P(B
i
),B
i
B
j
=∅,i
=j,
i=1
⋃
n
B
i
=Ω 如何推出? 条件概率变形,P ( A ⋂ B ) = P ( B ∣ A ) P ( A ) P(A\bigcap B)=P(B|A)P(A)P(A⋂B)=P(B∣A)P(A)
(3) Bayes公式:
P ( B j ∣ A ) = P ( A ∣ B j ) P ( B j ) ∑ i = 1 n P ( A ∣ B i ) P ( B i ) , j = 1 , 2 , ⋯ , n P({{B}{j}}|A)=\frac{P(A|{{B}{j}})P({{B}{j}})}{\sum\limits{i=1}^{n}{P(A|{{B}{i}})P({{B}{i}})}},j=1,2,\cdots ,nP(B
j
∣A)=
i=1
∑
n
P(A∣B
i
)P(B
i
)
P(A∣B
j
)P(B
j
)
,j=1,2,⋯,n
注:上述公式中事件B i {{B}{i}}B
i
的个数可为可列个。
(4)乘法公式:
P ( A 1 A 2 ) = P ( A 1 ) P ( A 2 ∣ A 1 ) = P ( A 2 ) P ( A 1 ∣ A 2 ) P({{A}{1}}{{A}{2}})=P({{A}{1}})P({{A}{2}}|{{A}{1}})=P({{A}{2}})P({{A}{1}}|{{A}{2}})P(A
1
A
2
)=P(A
1
)P(A
2
∣A
1
)=P(A
2
)P(A
1
∣A
2
)
P ( A 1 A 2 ⋯ A n ) = P ( A 1 ) P ( A 2 ∣ A 1 ) P ( A 3 ∣ A 1 A 2 ) ⋯ P ( A n ∣ A 1 A 2 ⋯ A n − 1 ) P({{A}{1}}{{A}{2}}\cdots {{A}{n}})=P({{A}{1}})P({{A}{2}}|{{A}{1}})P({{A}{3}}|{{A}{1}}{{A}{2}})\cdots P({{A}{n}}|{{A}{1}}{{A}{2}}\cdots {{A}{n-1}})P(A
1
A
2
⋯A
n
)=P(A
1
)P(A
2
∣A
1
)P(A
3
∣A
1
A
2
)⋯P(A
n
∣A
1
A
2
⋯A
n−1
)
6.事件的独立性
(1)A AA与B BB相互独立⇔ P ( A B ) = P ( A ) P ( B ) \Leftrightarrow P(AB)=P(A)P(B)⇔P(AB)=P(A)P(B)
(2)A AA,B BB,C CC两两独立
⇔ P ( A B ) = P ( A ) P ( B ) \Leftrightarrow P(AB)=P(A)P(B)⇔P(AB)=P(A)P(B);P ( B C ) = P ( B ) P ( C ) P(BC)=P(B)P©P(BC)=P(B)P© ;P ( A C ) = P ( A ) P ( C ) P(AC)=P(A)P©P(AC)=P(A)P©;
(3)A AA,B BB,C CC相互独立
⇔ P ( A B ) = P ( A ) P ( B ) \Leftrightarrow P(AB)=P(A)P(B)⇔P(AB)=P(A)P(B); P ( B C ) = P ( B ) P ( C ) P(BC)=P(B)P©P(BC)=P(B)P© ;
P ( A C ) = P ( A ) P ( C ) P(AC)=P(A)P©P(AC)=P(A)P© ; P ( A B C ) = P ( A ) P ( B ) P ( C ) P(ABC)=P(A)P(B)P©P(ABC)=P(A)P(B)P©
7.独立重复试验
将某试验独立重复n nn次,若每次实验中事件A发生的概率为p pp,则n nn次试验中A AA发生k kk次的概率为:
P ( X = k ) = C n k p k ( 1 − p ) n − k P(X=k)=C_{n}{k}{{p}{k}}{{(1-p)}^{n-k}}P(X=k)=C
n
k
p
k
(1−p)
n−k
8.重要公式与结论
( 1 ) P ( A ˉ ) = 1 − P ( A ) (1)P(\bar{A})=1-P(A)(1)P(
A
ˉ
)=1−P(A)
( 2 ) P ( A ⋃ B ) = P ( A ) + P ( B ) − P ( A B ) (2)P(A\bigcup B)=P(A)+P(B)-P(AB)(2)P(A⋃B)=P(A)+P(B)−P(AB)
P ( A ⋃ B ⋃ C ) = P ( A ) + P ( B ) + P ( C ) − P ( A B ) − P ( B C ) − P ( A C ) + P ( A B C ) P(A\bigcup B\bigcup C)=P(A)+P(B)+P©-P(AB)-P(BC)-P(AC)+P(ABC)P(A⋃B⋃C)=P(A)+P(B)+P©−P(AB)−P(BC)−P(AC)+P(ABC)
( 3 ) P ( A − B ) = P ( A ) − P ( A B ) (3)P(A-B)=P(A)-P(AB)(3)P(A−B)=P(A)−P(AB)
( 4 ) P ( A B ˉ ) = P ( A ) − P ( A B ) , P ( A ) = P ( A B ) + P ( A B ˉ ) , (4)P(A\bar{B})=P(A)-P(AB),P(A)=P(AB)+P(A\bar{B}),(4)P(A
B
ˉ
)=P(A)−P(AB),P(A)=P(AB)+P(A
B
ˉ
),
P ( A ⋃ B ) = P ( A ) + P ( A ˉ B ) = P ( A B ) + P ( A B ˉ ) + P ( A ˉ B ) P(A\bigcup B)=P(A)+P(\bar{A}B)=P(AB)+P(A\bar{B})+P(\bar{A}B)P(A⋃B)=P(A)+P(
A
ˉ
B)=P(AB)+P(A
B
ˉ
)+P(
A
ˉ
B)
(5)条件概率P ( ⋅ ∣ B ) P(\centerdot |B)P(⋅∣B)满足概率的所有性质,
例如:. P ( A ˉ 1 ∣ B ) = 1 − P ( A 1 ∣ B ) P({{\bar{A}}{1}}|B)=1-P({{A}{1}}|B)P(
A
ˉ
1
∣B)=1−P(A
1
∣B)
P ( A 1 ⋃ A 2 ∣ B ) = P ( A 1 ∣ B ) + P ( A 2 ∣ B ) − P ( A 1 A 2 ∣ B ) P({{A}{1}}\bigcup {{A}{2}}|B)=P({{A}{1}}|B)+P({{A}{2}}|B)-P({{A}{1}}{{A}{2}}|B)P(A
1
⋃A
2
∣B)=P(A
1
∣B)+P(A
2
∣B)−P(A
1
A
2
∣B)
P ( A 1 A 2 ∣ B ) = P ( A 1 ∣ B ) P ( A 2 ∣ A 1 B ) P({{A}{1}}{{A}{2}}|B)=P({{A}{1}}|B)P({{A}{2}}|{{A}{1}}B)P(A
1
A
2
∣B)=P(A
1
∣B)P(A
2
∣A
1
B)
(6)若A 1 , A 2 , ⋯ , A n {{A}{1}},{{A}{2}},\cdots ,{{A}{n}}A
1
,A
2
,⋯,A
n
相互独立,则P ( ⋂ i = 1 n A i ) = ∏ i = 1 n P ( A i ) , P(\bigcap\limits_{i=1}{n}{{{A}_{i}}})=\prod\limits_{i=1}{n}{P({{A}{i}})},P(
i=1
⋂
n
A
i
)=
i=1
∏
n
P(A
i
),
P ( ⋃ i = 1 n A i ) = ∏ i = 1 n ( 1 − P ( A i ) ) P(\bigcup\limits{i=1}{n}{{{A}_{i}}})=\prod\limits_{i=1}{n}{(1-P({{A}{i}}))}P(
i=1
⋃
n
A
i
)=
i=1
∏
n
(1−P(A
i
))
(7)互斥、互逆与独立性之间的关系:
A AA与B BB互逆⇒ \Rightarrow⇒ A AA与B BB互斥,但反之不成立,A AA与B BB互斥(或互逆)且均非零概率事件$\Rightarrow $A AA与B BB不独立.
(8)若A 1 , A 2 , ⋯ , A m , B 1 , B 2 , ⋯ , B n {{A}{1}},{{A}{2}},\cdots ,{{A}{m}},{{B}{1}},{{B}{2}},\cdots ,{{B}{n}}A
1
,A
2
,⋯,A
m
,B
1
,B
2
,⋯,B
n
相互独立,则f ( A 1 , A 2 , ⋯ , A m ) f({{A}{1}},{{A}{2}},\cdots ,{{A}{m}})f(A
1
,A
2
,⋯,A
m
)与g ( B 1 , B 2 , ⋯ , B n ) g({{B}{1}},{{B}{2}},\cdots ,{{B}_{n}})g(B
1
,B
2
,⋯,B
n
)也相互独立,其中f ( ⋅ ) , g ( ⋅ ) f(\centerdot ),g(\centerdot )f(⋅),g(⋅)分别表示对相应事件做任意事件运算后所得的事件,另外,概率为1(或0)的事件与任何事件相互独立.
随机变量及其概率分布
1.随机变量及概率分布
取值带有随机性的变量,严格地说是定义在样本空间上,取值于实数的函数称为随机变量,概率分布通常指分布函数或分布律
2.分布函数的概念与性质
定义: F ( x ) = P ( X ≤ x ) , − ∞ < x < + ∞ F(x) = P(X \leq x), - \infty < x < + \inftyF(x)=P(X≤x),−∞ 性质:(1)0 ≤ F ( x ) ≤ 1 0 \leq F(x) \leq 10≤F(x)≤1 (2) F ( x ) F(x)F(x)单调不减 (3) 右连续F ( x + 0 ) = F ( x ) F(x + 0) = F(x)F(x+0)=F(x) (4) F ( − ∞ ) = 0 , F ( + ∞ ) = 1 F( - \infty) = 0,F( + \infty) = 1F(−∞)=0,F(+∞)=1 3.离散型随机变量的概率分布 P ( X = x i ) = p i , i = 1 , 2 , ⋯ , n , ⋯ p i ≥ 0 , ∑ i = 1 ∞ p i = 1 P(X = x_{i}) = p_{i},i = 1,2,\cdots,n,\cdots\quad\quad p_{i} \geq 0,\sum_{i =1}^{\infty}p_{i} = 1P(X=x 4.连续型随机变量的概率密度 概率密度f ( x ) f(x)f(x);非负可积,且: (1)f ( x ) ≥ 0 , f(x) \geq 0,f(x)≥0, (2)∫ − ∞ + ∞ f ( x ) d x = 1 \int_{- \infty}^{+\infty}{f(x){dx} = 1}∫ (3)x xx为f ( x ) f(x)f(x)的连续点,则: f ( x ) = F ′ ( x ) f(x) = F’(x)f(x)=F (1) 0-1分布:P ( X = k ) = p k ( 1 − p ) 1 − k , k = 0 , 1 P(X = k) = p^{k}{(1 - p)}^{1 - k},k = 0,1P(X=k)=p (2) 二项分布:B ( n , p ) B(n,p)B(n,p): P ( X = k ) = C n k p k ( 1 − p ) n − k , k = 0 , 1 , ⋯ , n P(X = k) = C_{n}{k}p{k}{(1 - p)}^{n - k},k =0,1,\cdots,nP(X=k)=C (3) Poisson分布:p ( λ ) p(\lambda)p(λ): P ( X = k ) = λ k k ! e − λ , λ > 0 , k = 0 , 1 , 2 ⋯ P(X = k) = \frac{\lambda{k}}{k!}e{-\lambda},\lambda > 0,k = 0,1,2\cdotsP(X=k)= (4) 均匀分布U ( a , b ) U(a,b)U(a,b):f ( x ) = { 1 b − a , a < x < b 0 , f(x) = { b−a (5) 正态分布:N ( μ , σ 2 ) : N(\mu,\sigma^{2}):N(μ,σ (x−μ) ,σ>0,∞ (6)指数分布:E ( λ ) : f ( x ) = { λ e − λ x , x > 0 , λ > 0 0 , E(\lambda):f(x) ={ λe (7)几何分布:G ( p ) : P ( X = k ) = ( 1 − p ) k − 1 p , 0 < p < 1 , k = 1 , 2 , ⋯ . G§(X = k) = {(1 - p)}^{k - 1}p,0 < p < 1,k = 1,2,\cdots.G§(X=k)=(1−p) (8)超几何分布: H ( N , M , n ) : P ( X = k ) = C M k C N − M n − k C N n , k = 0 , 1 , ⋯ , m i n ( n , M ) H(N,M,n)(X = k) = \frac{C_{M}^{k}C_{N - M}^{n -k}}{C_{N}^{n}},k =0,1,\cdots,min(n,M)H(N,M,n)(X=k)= C 6.随机变量函数的概率分布 (1)离散型:P ( X = x 1 ) = p i , Y = g ( X ) P(X = x_{1}) = p_{i},Y = g(X)P(X=x 则: P ( Y = y j ) = ∑ g ( x i ) = y i P ( X = x i ) P(Y = y_{j}) = \sum_{g(x_{i}) = y_{i}}^{}{P(X = x_{i})}P(Y=y (2)连续型:X ~ f X ( x ) , Y = g ( x ) X\tilde{\ }f_{X}(x),Y = g(x)X ~ 则:F y ( y ) = P ( Y ≤ y ) = P ( g ( X ) ≤ y ) = ∫ g ( x ) ≤ y f x ( x ) d x F_{y}(y) = P(Y \leq y) = P(g(X) \leq y) = \int_{g(x) \leq y}^{}{f_{x}(x)dx}F 7.重要公式与结论 (1) X ∼ N ( 0 , 1 ) ⇒ φ ( 0 ) = 1 2 π , Φ ( 0 ) = 1 2 , X\sim N(0,1) \Rightarrow \varphi(0) = \frac{1}{\sqrt{2\pi}},\Phi(0) =\frac{1}{2},X∼N(0,1)⇒φ(0)= 1 (2) X ∼ N ( μ , σ 2 ) ⇒ X − μ σ ∼ N ( 0 , 1 ) , P ( X ≤ a ) = Φ ( a − μ σ ) X\sim N\left( \mu,\sigma^{2} \right) \Rightarrow \frac{X -\mu}{\sigma}\sim N\left( 0,1 \right),P(X \leq a) = \Phi(\frac{a -\mu}{\sigma})X∼N(μ,σ (3) X ∼ E ( λ ) ⇒ P ( X > s + t ∣ X > s ) = P ( X > t ) X\sim E(\lambda) \Rightarrow P(X > s + t|X > s) = P(X > t)X∼E(λ)⇒P(X>s+t∣X>s)=P(X>t) (4) X ∼ G ( p ) ⇒ P ( X = m + k ∣ X > m ) = P ( X = k ) X\sim G§ \Rightarrow P(X = m + k|X > m) = P(X = k)X∼G§⇒P(X=m+k∣X>m)=P(X=k) (5) 离散型随机变量的分布函数为阶梯间断函数;连续型随机变量的分布函数为连续函数,但不一定为处处可导函数。 (6) 存在既非离散也非连续型随机变量。 多维随机变量及其分布 由两个随机变量构成的随机向量( X , Y ) (X,Y)(X,Y), 联合分布为F ( x , y ) = P ( X ≤ x , Y ≤ y ) F(x,y) = P(X \leq x,Y \leq y)F(x,y)=P(X≤x,Y≤y) 2.二维离散型随机变量的分布 (1) 联合概率分布律 P { X = x i , Y = y j } = p i j ; i , j = 1 , 2 , ⋯ P{ X = x_{i},Y = y_{j}} = p_{{ij}};i,j =1,2,\cdotsP{X=x (2) 边缘分布律 p i ⋅ = ∑ j = 1 ∞ p i j , i = 1 , 2 , ⋯ p_{i \cdot} = \sum_{j = 1}^{\infty}p_{{ij}},i =1,2,\cdotsp (3) 条件分布律 P { X = x i ∣ Y = y j } = p i j p ⋅ j P{ X = x_{i}|Y = y_{j}} = \frac{p_{{ij}}}{p_{\cdot j}}P{X=x p P { Y = y j ∣ X = x i } = p i j p i ⋅ P{ Y = y_{j}|X = x_{i}} = \frac{p_{{ij}}}{p_{i \cdot}}P{Y=y p (1) 联合概率密度f ( x , y ) : f(x,y):f(x,y): f ( x , y ) ≥ 0 f(x,y) \geq 0f(x,y)≥0 (3) 边缘概率密度: f X ( x ) = ∫ − ∞ + ∞ f ( x , y ) d y f_{X}\left( x \right) = \int_{- \infty}^{+ \infty}{f\left( x,y \right){dy}}f (4) 条件概率密度:f X ∣ Y ( x | y ) = f ( x , y ) f Y ( y ) f_{X|Y}\left( x \middle| y \right) = \frac{f\left( x,y \right)}{f_{Y}\left( y \right)}f 4.常见二维随机变量的联合分布 (1) 二维均匀分布:( x , y ) ∼ U ( D ) (x,y) \sim U(D)(x,y)∼U(D) ,f ( x , y ) = { 1 S ( D ) , ( x , y ) ∈ D 0 , 其 他 f(x,y) = (2) 二维正态分布:( X , Y ) ∼ N ( μ 1 , μ 2 , σ 1 2 , σ 2 2 , ρ ) (X,Y)\sim N(\mu_{1},\mu_{2},\sigma_{1}{2},\sigma_{2}{2},\rho)(X,Y)∼N(μ f ( x , y ) = 1 2 π σ 1 σ 2 1 − ρ 2 . exp { − 1 2 ( 1 − ρ 2 ) [ ( x − μ 1 ) 2 σ 1 2 − 2 ρ ( x − μ 1 ) ( y − μ 2 ) σ 1 σ 2 + ( y − μ 2 ) 2 σ 2 2 ] } f(x,y) = \frac{1}{2\pi\sigma_{1}\sigma_{2}\sqrt{1 - \rho^{2}}}.\exp\left{ \frac{- 1}{2(1 - \rho^{2})}\lbrack\frac{{(x - \mu_{1})}{2}}{\sigma_{1}{2}} - 2\rho\frac{(x - \mu_{1})(y - \mu_{2})}{\sigma_{1}\sigma_{2}} + \frac{{(y - \mu_{2})}{2}}{\sigma_{2}{2}}\rbrack \right}f(x,y)= 1−ρ 1 (x−μ (x−μ (y−μ 5.随机变量的独立性和相关性 X XX和Y YY的相互独立:⇔ F ( x , y ) = F X ( x ) F Y ( y ) \Leftrightarrow F\left( x,y \right) = F_{X}\left( x \right)F_{Y}\left( y \right)⇔F(x,y)=F ⇔ p i j = p i ⋅ ⋅ p ⋅ j \Leftrightarrow p_{{ij}} = p_{i \cdot} \cdot p_{\cdot j}⇔p X XX和Y YY的相关性: 相关系数ρ X Y = 0 \rho_{{XY}} = 0ρ 6.两个随机变量简单函数的概率分布 离散型: P ( X = x i , Y = y i ) = p i j , Z = g ( X , Y ) P\left( X = x_{i},Y = y_{i} \right) = p_{{ij}},Z = g\left( X,Y \right)P(X=x P ( Z = z k ) = P { g ( X , Y ) = z k } = ∑ g ( x i , y i ) = z k P ( X = x i , Y = y j ) P(Z = z_{k}) = P\left{ g\left( X,Y \right) = z_{k} \right} = \sum_{g\left( x_{i},y_{i} \right) = z_{k}}^{}{P\left( X = x_{i},Y = y_{j} \right)}P(Z=z 连续型: ( X , Y ) ∼ f ( x , y ) , Z = g ( X , Y ) \left( X,Y \right) \sim f\left( x,y \right),Z = g\left( X,Y \right)(X,Y)∼f(x,y),Z=g(X,Y) F z ( z ) = P { g ( X , Y ) ≤ z } = ∬ g ( x , y ) ≤ z f ( x , y ) d x d y F_{z}\left( z \right) = P\left{ g\left( X,Y \right) \leq z \right} = \iint_{g(x,y) \leq z}^{}{f(x,y)dxdy}F 7.重要公式与结论 (1) 边缘密度公式: f X ( x ) = ∫ − ∞ + ∞ f ( x , y ) d y , f_{X}(x) = \int_{- \infty}^{+ \infty}{f(x,y)dy,}f (2) P { ( X , Y ) ∈ D } = ∬ D f ( x , y ) d x d y P\left{ \left( X,Y \right) \in D \right} = \iint_{D}^{}{f\left( x,y \right){dxdy}}P{(X,Y)∈D}=∬ (3) 若( X , Y ) (X,Y)(X,Y)服从二维正态分布N ( μ 1 , μ 2 , σ 1 2 , σ 2 2 , ρ ) N(\mu_{1},\mu_{2},\sigma_{1}{2},\sigma_{2}{2},\rho)N(μ X ∼ N ( μ 1 , σ 1 2 ) , Y ∼ N ( μ 2 , σ 2 2 ) . X\sim N\left( \mu_{1},\sigma_{1}^{2} \right),Y\sim N(\mu_{2},\sigma_{2}^{2}).X∼N(μ σ σ C 1 X + C 2 Y ~ N ( C 1 μ 1 + C 2 μ 2 , C 1 2 σ 1 2 C 2 2 σ 2 2 ) . C_{1}X + C_{2}Y\tilde{\ }N(C_{1}\mu_{1} + C_{2}\mu_{2},C_{1}{2}\sigma_{1}{2} C_{2}{2}\sigma_{2}{2}).C ~ (5) 若X XX与Y YY相互独立,f ( x ) f\left( x \right)f(x)和g ( x ) g\left( x \right)g(x)为连续函数, 则f ( X ) f\left( X \right)f(X)和g ( Y ) g(Y)g(Y)也相互独立。 (1) 对于函数Y = g ( x ) Y = g(x)Y=g(x) X XX为离散型:P { X = x i } = p i , E ( Y ) = ∑ i g ( x i ) p i P{ X = x_{i}} = p_{i},E(Y) = \sum_{i}^{}{g(x_{i})p_{i}}P{X=x X XX为连续型:X ∼ f ( x ) , E ( Y ) = ∫ − ∞ + ∞ g ( x ) f ( x ) d x X\sim f(x),E(Y) = \int_{- \infty}^{+ \infty}{g(x)f(x)dx}X∼f(x),E(Y)=∫ (2) Z = g ( X , Y ) Z = g(X,Y)Z=g(X,Y) X , Y ) ∼ P { X = x i , Y = y j } = p i j \left( X,Y \right)\sim P{ X = x_{i},Y = y_{j}} = p_{{ij}}(X,Y)∼P{X=x 7.协方差 C o v ( X , Y ) = E [ ( X − E ( X ) ( Y − E ( Y ) ) ] Cov(X,Y) = E\left\lbrack (X - E(X)(Y - E(Y)) \right\rbrackCov(X,Y)=E[(X−E(X)(Y−E(Y))] 8.相关系数 D(X) D(Y) Cov(X,Y) 性质: (1) C o v ( X , Y ) = C o v ( Y , X ) \ Cov(X,Y) = Cov(Y,X) Cov(X,Y)=Cov(Y,X) (2) C o v ( a X , b Y ) = a b C o v ( Y , X ) \ Cov(aX,bY) = abCov(Y,X) Cov(aX,bY)=abCov(Y,X) (3) C o v ( X 1 + X 2 , Y ) = C o v ( X 1 , Y ) + C o v ( X 2 , Y ) \ Cov(X_{1} + X_{2},Y) = Cov(X_{1},Y) + Cov(X_{2},Y) Cov(X (4) ∣ ρ ( X , Y ) ∣ ≤ 1 \ \left| \rho\left( X,Y \right) \right| \leq 1 ∣ρ(X,Y)∣≤1 (5) ρ ( X , Y ) = 1 ⇔ P ( Y = a X + b ) = 1 \ \rho\left( X,Y \right) = 1 \Leftrightarrow P\left( Y = aX + b \right) = 1 ρ(X,Y)=1⇔P(Y=aX+b)=1 ,其中a > 0 a > 0a>0 ρ ( X , Y ) = − 1 ⇔ P ( Y = a X + b ) = 1 \rho\left( X,Y \right) = - 1 \Leftrightarrow P\left( Y = aX + b \right) = 1ρ(X,Y)=−1⇔P(Y=aX+b)=1 9.重要公式与结论 (1) D ( X ) = E ( X 2 ) − E 2 ( X ) \ D(X) = E(X^{2}) - E^{2}(X) D(X)=E(X (2) C o v ( X , Y ) = E ( X Y ) − E ( X ) E ( Y ) \ Cov(X,Y) = E(XY) - E(X)E(Y) Cov(X,Y)=E(XY)−E(X)E(Y) (3) ∣ ρ ( X , Y ) ∣ ≤ 1 , \left| \rho\left( X,Y \right) \right| \leq 1,∣ρ(X,Y)∣≤1,且 ρ ( X , Y ) = 1 ⇔ P ( Y = a X + b ) = 1 \rho\left( X,Y \right) = 1 \Leftrightarrow P\left( Y = aX + b \right) = 1ρ(X,Y)=1⇔P(Y=aX+b)=1,其中a > 0 a > 0a>0 ρ ( X , Y ) = − 1 ⇔ P ( Y = a X + b ) = 1 \rho\left( X,Y \right) = - 1 \Leftrightarrow P\left( Y = aX + b \right) = 1ρ(X,Y)=−1⇔P(Y=aX+b)=1,其中a < 0 a < 0a<0 (4) 下面5个条件互为充要条件: ρ ( X , Y ) = 0 \rho(X,Y) = 0ρ(X,Y)=0 ⇔ C o v ( X , Y ) = 0 \Leftrightarrow Cov(X,Y) = 0⇔Cov(X,Y)=0 ⇔ E ( X , Y ) = E ( X ) E ( Y ) \Leftrightarrow E(X,Y) = E(X)E(Y)⇔E(X,Y)=E(X)E(Y) ⇔ D ( X + Y ) = D ( X ) + D ( Y ) \Leftrightarrow D(X + Y) = D(X) + D(Y)⇔D(X+Y)=D(X)+D(Y) ⇔ D ( X − Y ) = D ( X ) + D ( Y ) \Leftrightarrow D(X - Y) = D(X) + D(Y)⇔D(X−Y)=D(X)+D(Y) 注:X XX与Y YY独立为上述5个条件中任何一个成立的充分条件,但非必要条件。 数理统计的基本概念 总体:研究对象的全体,它是一个随机变量,用X XX表示。 个体:组成总体的每个基本元素。 简单随机样本:来自总体X XX的n nn个相互独立且与总体同分布的随机变量X 1 , X 2 ⋯ , X n X_{1},X_{2}\cdots,X_{n}X 统计量:设X 1 , X 2 ⋯ , X n , X_{1},X_{2}\cdots,X_{n},X n n−1 n n 2.分布 χ 2 \chi^{2}χ t tt分布:T = X Y / n ∼ t ( n ) T = \frac{X}{\sqrt{Y/n}}\sim t(n)T= X F FF分布:F = X / n 1 Y / n 2 ∼ F ( n 1 , n 2 ) F = \frac{X/n_{1}}{Y/n_{2}}\sim F(n_{1},n_{2})F= X/n 分位数:若P ( X ≤ x α ) = α , P(X \leq x_{\alpha}) = \alpha,P(X≤x 3.正态总体的常用样本分布 (1) 设X 1 , X 2 ⋯ , X n X_{1},X_{2}\cdots,X_{n}X n−1 X ‾ ∼ N ( μ , σ 2 n ) \overline{X}\sim N\left( \mu,\frac{\sigma^{2}}{n} \right){\ \ } σ X (n−1)S σ 1 1 X 4.重要公式与结论 (1) 对于χ 2 ∼ χ 2 ( n ) \chi{2}\sim\chi{2}(n)χ (2) 对于T ∼ t ( n ) T\sim t(n)T∼t(n),有E ( T ) = 0 , D ( T ) = n n − 2 ( n > 2 ) E(T) = 0,D(T) = \frac{n}{n - 2}(n > 2)E(T)=0,D(T)= (3) 对于F ~ F ( m , n ) F\tilde{\ }F(m,n)F ~ (1) 子事件:A ⊂ B A \subset BA⊂B,若A AA发生,则B BB发生。 Notes:A AA是B BB的子事件,P ( A ) ≤ P ( B ) P(A) \le P(B)P(A)≤P(B) (2) 相等事件:A = B A = BA=B,即A ⊂ B A \subset BA⊂B,且B ⊂ A B \subset AB⊂A 。 (3) 和事件:A ⋃ B A\bigcup BA⋃B(或A + B A + BA+B),A AA与B BB中至少有一个发生。 推广:若A 1 , A 2 , … … A_{1},A_{2},……A (4) 差事件:A − B A - BA−B,A AA发生但B BB不发生。 (5) 积事件:A ⋂ B A\bigcap BA⋂B(或A B {AB}AB),A AA与B BB同时发生。 (6) 互斥事件(互不相容):A ⋂ B A\bigcap BA⋂B=∅ \varnothing∅。 (7) 互逆事件(对立事件):A ⋂ B = ∅ , A ⋃ B = Ω , A = B ˉ , B = A ˉ A\bigcap B=\varnothing ,A\bigcup B=\Omega ,A=\bar{B},B=\bar{A}A⋂B=∅,A⋃B=Ω,A= (8)P ( Ω ) = 1 P(\Omega)=1P(Ω)=1 A 4.完全事件组 A 1 A 2 ⋯ A n {{A}{1}}{{A}{2}}\cdots {{A}{n}}A 将某试验独立重复n nn次,若每次实验中事件A发生的概率为p pp,则n nn次试验中A AA发生k kk次的概率为: 8.重要公式与结论 1 随机变量及其概率分布 取值带有随机性的变量,严格地说是定义在样本空间上,取值于实数的函数称为随机变量,概率分布通常指分布函数或分布律 2.分布函数的概念与性质 定义: F ( x ) = P ( X ≤ x ) , − ∞ < x < + ∞ F(x) = P(X \leq x), - \infty < x < + \inftyF(x)=P(X≤x),−∞ 性质:(1)0 ≤ F ( x ) ≤ 1 0 \leq F(x) \leq 10≤F(x)≤1 (2) F ( x ) F(x)F(x)单调不减 (3) 右连续F ( x + 0 ) = F ( x ) F(x + 0) = F(x)F(x+0)=F(x) (4) F ( − ∞ ) = 0 , F ( + ∞ ) = 1 F( - \infty) = 0,F( + \infty) = 1F(−∞)=0,F(+∞)=1 3.离散型随机变量的概率分布 P ( X = x i ) = p i , i = 1 , 2 , ⋯ , n , ⋯ p i ≥ 0 , ∑ i = 1 ∞ p i = 1 P(X = x_{i}) = p_{i},i = 1,2,\cdots,n,\cdots\quad\quad p_{i} \geq 0,\sum_{i =1}^{\infty}p_{i} = 1P(X=x 4.连续型随机变量的概率密度 概率密度f ( x ) f(x)f(x);非负可积,且: (1)f ( x ) ≥ 0 , f(x) \geq 0,f(x)≥0, (2)∫ − ∞ + ∞ f ( x ) d x = 1 \int_{- \infty}^{+\infty}{f(x){dx} = 1}∫ (3)x xx为f ( x ) f(x)f(x)的连续点,则: f ( x ) = F ′ ( x ) f(x) = F’(x)f(x)=F (1) 0-1分布:P ( X = k ) = p k ( 1 − p ) 1 − k , k = 0 , 1 P(X = k) = p^{k}{(1 - p)}^{1 - k},k = 0,1P(X=k)=p (2) 二项分布:B ( n , p ) B(n,p)B(n,p): P ( X = k ) = C n k p k ( 1 − p ) n − k , k = 0 , 1 , ⋯ , n P(X = k) = C_{n}{k}p{k}{(1 - p)}^{n - k},k =0,1,\cdots,nP(X=k)=C (3) Poisson分布:p ( λ ) p(\lambda)p(λ): P ( X = k ) = λ k k ! e − λ , λ > 0 , k = 0 , 1 , 2 ⋯ P(X = k) = \frac{\lambda{k}}{k!}e{-\lambda},\lambda > 0,k = 0,1,2\cdotsP(X=k)= (4) 均匀分布U ( a , b ) U(a,b)U(a,b):f ( x ) = { 1 b − a , a < x < b 0 , f(x) = { b−a (5) 正态分布:N ( μ , σ 2 ) : N(\mu,\sigma^{2}):N(μ,σ (x−μ) ,σ>0,∞ (6)指数分布:E ( λ ) : f ( x ) = { λ e − λ x , x > 0 , λ > 0 0 , E(\lambda):f(x) ={ λe (7)几何分布:G ( p ) : P ( X = k ) = ( 1 − p ) k − 1 p , 0 < p < 1 , k = 1 , 2 , ⋯ . G§(X = k) = {(1 - p)}^{k - 1}p,0 < p < 1,k = 1,2,\cdots.G§(X=k)=(1−p) (8)超几何分布: H ( N , M , n ) : P ( X = k ) = C M k C N − M n − k C N n , k = 0 , 1 , ⋯ , m i n ( n , M ) H(N,M,n)(X = k) = \frac{C_{M}^{k}C_{N - M}^{n -k}}{C_{N}^{n}},k =0,1,\cdots,min(n,M)H(N,M,n)(X=k)= C 6.随机变量函数的概率分布 (1)离散型:P ( X = x 1 ) = p i , Y = g ( X ) P(X = x_{1}) = p_{i},Y = g(X)P(X=x 则: P ( Y = y j ) = ∑ g ( x i ) = y i P ( X = x i ) P(Y = y_{j}) = \sum_{g(x_{i}) = y_{i}}^{}{P(X = x_{i})}P(Y=y (2)连续型:X ~ f X ( x ) , Y = g ( x ) X\tilde{\ }f_{X}(x),Y = g(x)X ~ 则:F y ( y ) = P ( Y ≤ y ) = P ( g ( X ) ≤ y ) = ∫ g ( x ) ≤ y f x ( x ) d x F_{y}(y) = P(Y \leq y) = P(g(X) \leq y) = \int_{g(x) \leq y}^{}{f_{x}(x)dx}F 7.重要公式与结论 (1) X ∼ N ( 0 , 1 ) ⇒ φ ( 0 ) = 1 2 π , Φ ( 0 ) = 1 2 , X\sim N(0,1) \Rightarrow \varphi(0) = \frac{1}{\sqrt{2\pi}},\Phi(0) =\frac{1}{2},X∼N(0,1)⇒φ(0)= 1 (2) X ∼ N ( μ , σ 2 ) ⇒ X − μ σ ∼ N ( 0 , 1 ) , P ( X ≤ a ) = Φ ( a − μ σ ) X\sim N\left( \mu,\sigma^{2} \right) \Rightarrow \frac{X -\mu}{\sigma}\sim N\left( 0,1 \right),P(X \leq a) = \Phi(\frac{a -\mu}{\sigma})X∼N(μ,σ (3) X ∼ E ( λ ) ⇒ P ( X > s + t ∣ X > s ) = P ( X > t ) X\sim E(\lambda) \Rightarrow P(X > s + t|X > s) = P(X > t)X∼E(λ)⇒P(X>s+t∣X>s)=P(X>t) (4) X ∼ G ( p ) ⇒ P ( X = m + k ∣ X > m ) = P ( X = k ) X\sim G§ \Rightarrow P(X = m + k|X > m) = P(X = k)X∼G§⇒P(X=m+k∣X>m)=P(X=k) (5) 离散型随机变量的分布函数为阶梯间断函数;连续型随机变量的分布函数为连续函数,但不一定为处处可导函数。 (6) 存在既非离散也非连续型随机变量。 多维随机变量及其分布 由两个随机变量构成的随机向量( X , Y ) (X,Y)(X,Y), 联合分布为F ( x , y ) = P ( X ≤ x , Y ≤ y ) F(x,y) = P(X \leq x,Y \leq y)F(x,y)=P(X≤x,Y≤y) 2.二维离散型随机变量的分布 (1) 联合概率分布律 P { X = x i , Y = y j } = p i j ; i , j = 1 , 2 , ⋯ P{ X = x_{i},Y = y_{j}} = p_{{ij}};i,j =1,2,\cdotsP{X=x (2) 边缘分布律 p i ⋅ = ∑ j = 1 ∞ p i j , i = 1 , 2 , ⋯ p_{i \cdot} = \sum_{j = 1}^{\infty}p_{{ij}},i =1,2,\cdotsp (3) 条件分布律 P { X = x i ∣ Y = y j } = p i j p ⋅ j P{ X = x_{i}|Y = y_{j}} = \frac{p_{{ij}}}{p_{\cdot j}}P{X=x p P { Y = y j ∣ X = x i } = p i j p i ⋅ P{ Y = y_{j}|X = x_{i}} = \frac{p_{{ij}}}{p_{i \cdot}}P{Y=y p (1) 联合概率密度f ( x , y ) : f(x,y):f(x,y): f ( x , y ) ≥ 0 f(x,y) \geq 0f(x,y)≥0 (3) 边缘概率密度: f X ( x ) = ∫ − ∞ + ∞ f ( x , y ) d y f_{X}\left( x \right) = \int_{- \infty}^{+ \infty}{f\left( x,y \right){dy}}f (4) 条件概率密度:f X ∣ Y ( x | y ) = f ( x , y ) f Y ( y ) f_{X|Y}\left( x \middle| y \right) = \frac{f\left( x,y \right)}{f_{Y}\left( y \right)}f 4.常见二维随机变量的联合分布 (1) 二维均匀分布:( x , y ) ∼ U ( D ) (x,y) \sim U(D)(x,y)∼U(D) ,f ( x , y ) = { 1 S ( D ) , ( x , y ) ∈ D 0 , 其 他 f(x,y) = (2) 二维正态分布:( X , Y ) ∼ N ( μ 1 , μ 2 , σ 1 2 , σ 2 2 , ρ ) (X,Y)\sim N(\mu_{1},\mu_{2},\sigma_{1}{2},\sigma_{2}{2},\rho)(X,Y)∼N(μ f ( x , y ) = 1 2 π σ 1 σ 2 1 − ρ 2 . exp { − 1 2 ( 1 − ρ 2 ) [ ( x − μ 1 ) 2 σ 1 2 − 2 ρ ( x − μ 1 ) ( y − μ 2 ) σ 1 σ 2 + ( y − μ 2 ) 2 σ 2 2 ] } f(x,y) = \frac{1}{2\pi\sigma_{1}\sigma_{2}\sqrt{1 - \rho^{2}}}.\exp\left{ \frac{- 1}{2(1 - \rho^{2})}\lbrack\frac{{(x - \mu_{1})}{2}}{\sigma_{1}{2}} - 2\rho\frac{(x - \mu_{1})(y - \mu_{2})}{\sigma_{1}\sigma_{2}} + \frac{{(y - \mu_{2})}{2}}{\sigma_{2}{2}}\rbrack \right}f(x,y)= 1−ρ 1 (x−μ (x−μ (y−μ 5.随机变量的独立性和相关性 X XX和Y YY的相互独立:⇔ F ( x , y ) = F X ( x ) F Y ( y ) \Leftrightarrow F\left( x,y \right) = F_{X}\left( x \right)F_{Y}\left( y \right)⇔F(x,y)=F ⇔ p i j = p i ⋅ ⋅ p ⋅ j \Leftrightarrow p_{{ij}} = p_{i \cdot} \cdot p_{\cdot j}⇔p X XX和Y YY的相关性: 相关系数ρ X Y = 0 \rho_{{XY}} = 0ρ 6.两个随机变量简单函数的概率分布 离散型: P ( X = x i , Y = y i ) = p i j , Z = g ( X , Y ) P\left( X = x_{i},Y = y_{i} \right) = p_{{ij}},Z = g\left( X,Y \right)P(X=x P ( Z = z k ) = P { g ( X , Y ) = z k } = ∑ g ( x i , y i ) = z k P ( X = x i , Y = y j ) P(Z = z_{k}) = P\left{ g\left( X,Y \right) = z_{k} \right} = \sum_{g\left( x_{i},y_{i} \right) = z_{k}}^{}{P\left( X = x_{i},Y = y_{j} \right)}P(Z=z 连续型: ( X , Y ) ∼ f ( x , y ) , Z = g ( X , Y ) \left( X,Y \right) \sim f\left( x,y \right),Z = g\left( X,Y \right)(X,Y)∼f(x,y),Z=g(X,Y) F z ( z ) = P { g ( X , Y ) ≤ z } = ∬ g ( x , y ) ≤ z f ( x , y ) d x d y F_{z}\left( z \right) = P\left{ g\left( X,Y \right) \leq z \right} = \iint_{g(x,y) \leq z}^{}{f(x,y)dxdy}F 7.重要公式与结论 (1) 边缘密度公式: f X ( x ) = ∫ − ∞ + ∞ f ( x , y ) d y , f_{X}(x) = \int_{- \infty}^{+ \infty}{f(x,y)dy,}f (2) P { ( X , Y ) ∈ D } = ∬ D f ( x , y ) d x d y P\left{ \left( X,Y \right) \in D \right} = \iint_{D}^{}{f\left( x,y \right){dxdy}}P{(X,Y)∈D}=∬ (3) 若( X , Y ) (X,Y)(X,Y)服从二维正态分布N ( μ 1 , μ 2 , σ 1 2 , σ 2 2 , ρ ) N(\mu_{1},\mu_{2},\sigma_{1}{2},\sigma_{2}{2},\rho)N(μ X ∼ N ( μ 1 , σ 1 2 ) , Y ∼ N ( μ 2 , σ 2 2 ) . X\sim N\left( \mu_{1},\sigma_{1}^{2} \right),Y\sim N(\mu_{2},\sigma_{2}^{2}).X∼N(μ σ σ C 1 X + C 2 Y ~ N ( C 1 μ 1 + C 2 μ 2 , C 1 2 σ 1 2 C 2 2 σ 2 2 ) . C_{1}X + C_{2}Y\tilde{\ }N(C_{1}\mu_{1} + C_{2}\mu_{2},C_{1}{2}\sigma_{1}{2} C_{2}{2}\sigma_{2}{2}).C ~ (5) 若X XX与Y YY相互独立,f ( x ) f\left( x \right)f(x)和g ( x ) g\left( x \right)g(x)为连续函数, 则f ( X ) f\left( X \right)f(X)和g ( Y ) g(Y)g(Y)也相互独立。 (1) 对于函数Y = g ( x ) Y = g(x)Y=g(x) X XX为离散型:P { X = x i } = p i , E ( Y ) = ∑ i g ( x i ) p i P{ X = x_{i}} = p_{i},E(Y) = \sum_{i}^{}{g(x_{i})p_{i}}P{X=x X XX为连续型:X ∼ f ( x ) , E ( Y ) = ∫ − ∞ + ∞ g ( x ) f ( x ) d x X\sim f(x),E(Y) = \int_{- \infty}^{+ \infty}{g(x)f(x)dx}X∼f(x),E(Y)=∫ (2) Z = g ( X , Y ) Z = g(X,Y)Z=g(X,Y) X , Y ) ∼ P { X = x i , Y = y j } = p i j \left( X,Y \right)\sim P{ X = x_{i},Y = y_{j}} = p_{{ij}}(X,Y)∼P{X=x 7.协方差 C o v ( X , Y ) = E [ ( X − E ( X ) ( Y − E ( Y ) ) ] Cov(X,Y) = E\left\lbrack (X - E(X)(Y - E(Y)) \right\rbrackCov(X,Y)=E[(X−E(X)(Y−E(Y))] 8.相关系数 D(X) D(Y) Cov(X,Y) 性质: (1) C o v ( X , Y ) = C o v ( Y , X ) \ Cov(X,Y) = Cov(Y,X) Cov(X,Y)=Cov(Y,X) (2) C o v ( a X , b Y ) = a b C o v ( Y , X ) \ Cov(aX,bY) = abCov(Y,X) Cov(aX,bY)=abCov(Y,X) (3) C o v ( X 1 + X 2 , Y ) = C o v ( X 1 , Y ) + C o v ( X 2 , Y ) \ Cov(X_{1} + X_{2},Y) = Cov(X_{1},Y) + Cov(X_{2},Y) Cov(X (4) ∣ ρ ( X , Y ) ∣ ≤ 1 \ \left| \rho\left( X,Y \right) \right| \leq 1 ∣ρ(X,Y)∣≤1 (5) ρ ( X , Y ) = 1 ⇔ P ( Y = a X + b ) = 1 \ \rho\left( X,Y \right) = 1 \Leftrightarrow P\left( Y = aX + b \right) = 1 ρ(X,Y)=1⇔P(Y=aX+b)=1 ,其中a > 0 a > 0a>0 ρ ( X , Y ) = − 1 ⇔ P ( Y = a X + b ) = 1 \rho\left( X,Y \right) = - 1 \Leftrightarrow P\left( Y = aX + b \right) = 1ρ(X,Y)=−1⇔P(Y=aX+b)=1 9.重要公式与结论 (1) D ( X ) = E ( X 2 ) − E 2 ( X ) \ D(X) = E(X^{2}) - E^{2}(X) D(X)=E(X (2) C o v ( X , Y ) = E ( X Y ) − E ( X ) E ( Y ) \ Cov(X,Y) = E(XY) - E(X)E(Y) Cov(X,Y)=E(XY)−E(X)E(Y) (3) ∣ ρ ( X , Y ) ∣ ≤ 1 , \left| \rho\left( X,Y \right) \right| \leq 1,∣ρ(X,Y)∣≤1,且 ρ ( X , Y ) = 1 ⇔ P ( Y = a X + b ) = 1 \rho\left( X,Y \right) = 1 \Leftrightarrow P\left( Y = aX + b \right) = 1ρ(X,Y)=1⇔P(Y=aX+b)=1,其中a > 0 a > 0a>0 ρ ( X , Y ) = − 1 ⇔ P ( Y = a X + b ) = 1 \rho\left( X,Y \right) = - 1 \Leftrightarrow P\left( Y = aX + b \right) = 1ρ(X,Y)=−1⇔P(Y=aX+b)=1,其中a < 0 a < 0a<0 (4) 下面5个条件互为充要条件: ρ ( X , Y ) = 0 \rho(X,Y) = 0ρ(X,Y)=0 ⇔ C o v ( X , Y ) = 0 \Leftrightarrow Cov(X,Y) = 0⇔Cov(X,Y)=0 ⇔ E ( X , Y ) = E ( X ) E ( Y ) \Leftrightarrow E(X,Y) = E(X)E(Y)⇔E(X,Y)=E(X)E(Y) ⇔ D ( X + Y ) = D ( X ) + D ( Y ) \Leftrightarrow D(X + Y) = D(X) + D(Y)⇔D(X+Y)=D(X)+D(Y) ⇔ D ( X − Y ) = D ( X ) + D ( Y ) \Leftrightarrow D(X - Y) = D(X) + D(Y)⇔D(X−Y)=D(X)+D(Y) 注:X XX与Y YY独立为上述5个条件中任何一个成立的充分条件,但非必要条件。 数理统计的基本概念 总体:研究对象的全体,它是一个随机变量,用X XX表示。 个体:组成总体的每个基本元素。 简单随机样本:来自总体X XX的n nn个相互独立且与总体同分布的随机变量X 1 , X 2 ⋯ , X n X_{1},X_{2}\cdots,X_{n}X 统计量:设X 1 , X 2 ⋯ , X n , X_{1},X_{2}\cdots,X_{n},X n n−1 n n 2.分布 χ 2 \chi^{2}χ t tt分布:T = X Y / n ∼ t ( n ) T = \frac{X}{\sqrt{Y/n}}\sim t(n)T= X F FF分布:F = X / n 1 Y / n 2 ∼ F ( n 1 , n 2 ) F = \frac{X/n_{1}}{Y/n_{2}}\sim F(n_{1},n_{2})F= X/n 分位数:若P ( X ≤ x α ) = α , P(X \leq x_{\alpha}) = \alpha,P(X≤x 3.正态总体的常用样本分布 (1) 设X 1 , X 2 ⋯ , X n X_{1},X_{2}\cdots,X_{n}X n−1 X ‾ ∼ N ( μ , σ 2 n ) \overline{X}\sim N\left( \mu,\frac{\sigma^{2}}{n} \right){\ \ } σ X (n−1)S σ 1 1 X 4.重要公式与结论 (1) 对于χ 2 ∼ χ 2 ( n ) \chi{2}\sim\chi{2}(n)χ (2) 对于T ∼ t ( n ) T\sim t(n)T∼t(n),有E ( T ) = 0 , D ( T ) = n n − 2 ( n > 2 ) E(T) = 0,D(T) = \frac{n}{n - 2}(n > 2)E(T)=0,D(T)= (3) 对于F ~ F ( m , n ) F\tilde{\ }F(m,n)F ~
i
)=p
i
,i=1,2,⋯,n,⋯p
i
≥0,∑
i=1
∞
p
i
=1
−∞
+∞
f(x)dx=1
′
(x)分布函数F ( x ) = ∫ − ∞ x f ( t ) d t F(x) = \int_{- \infty}^{x}{f(t){dt}}F(x)=∫
−∞
x
f(t)dt
5.常见分布
k
(1−p)
1−k
,k=0,1
n
k
p
k
(1−p)
n−k
,k=0,1,⋯,n
k!
λ
k
e
−λ
,λ>0,k=0,1,2⋯
1b−a,a
1
,a
2
): φ ( x ) = 1 2 π σ e − ( x − μ ) 2 2 σ 2 , σ > 0 , ∞ < x < + ∞ \varphi(x) =\frac{1}{\sqrt{2\pi}\sigma}e^{- \frac{{(x - \mu)}{2}}{2\sigma{2}}},\sigma > 0,\infty < x < + \inftyφ(x)=
2π
σ
1
e
−
2σ
2
2
λe−λx,x>0,λ>00,
λe−λx,x>0,λ>00,
E(λ):f(x)={
−λx
,x>0,λ>0
0,
k−1
p,0
C
N
n
M
k
C
N−M
n−k
,k=0,1,⋯,min(n,M)
1
)=p
i
,Y=g(X)
j
)=∑
g(x
i
)=y
i
P(X=x
i
)
f
X
(x),Y=g(x)
y
(y)=P(Y≤y)=P(g(X)≤y)=∫
g(x)≤y
f
x
(x)dx, f Y ( y ) = F Y ′ ( y ) f_{Y}(y) = F’_{Y}(y)f
Y
(y)=F
Y
′
(y)
2π
,Φ(0)=
2
1
, Φ ( − a ) = P ( X ≤ − a ) = 1 − Φ ( a ) \Phi( - a) = P(X \leq - a) = 1 - \Phi(a)Φ(−a)=P(X≤−a)=1−Φ(a)
2
)⇒
σ
X−μ
∼N(0,1),P(X≤a)=Φ(
σ
a−μ
)
1.二维随机变量及其联合分布
i
,Y=y
j
}=p
ij
;i,j=1,2,⋯
i⋅
=∑
j=1
∞
p
ij
,i=1,2,⋯ p ⋅ j = ∑ i ∞ p i j , j = 1 , 2 , ⋯ p_{\cdot j} = \sum_{i}^{\infty}p_{{ij}},j = 1,2,\cdotsp
⋅j
=∑
i
∞
p
ij
,j=1,2,⋯
i
∣Y=y
j
}=
p
⋅j
ij
j
∣X=x
i
}=
p
i⋅
ij
∫ − ∞ + ∞ ∫ − ∞ + ∞ f ( x , y ) d x d y = 1 \int_{- \infty}^{+ \infty}{\int_{- \infty}^{+ \infty}{f(x,y)dxdy}} = 1∫
−∞
+∞
∫
−∞
+∞
f(x,y)dxdy=1
(2) 分布函数:F ( x , y ) = ∫ − ∞ x ∫ − ∞ y f ( u , v ) d u d v F(x,y) = \int_{- \infty}^{x}{\int_{- \infty}^{y}{f(u,v)dudv}}F(x,y)=∫
−∞
x
∫
−∞
y
f(u,v)dudv
X
(x)=∫
−∞
+∞
f(x,y)dy f Y ( y ) = ∫ − ∞ + ∞ f ( x , y ) d x f_{Y}(y) = \int_{- \infty}^{+ \infty}{f(x,y)dx}f
Y
(y)=∫
−∞
+∞
f(x,y)dx
X∣Y
(x∣y)=
f
Y
(y)
f(x,y)
f Y ∣ X ( y ∣ x ) = f ( x , y ) f X ( x ) f_{Y|X}(y|x) = \frac{f(x,y)}{f_{X}(x)}f
Y∣X
(y∣x)=
f
X
(x)
f(x,y)
{1S(D),(x,y)∈D0,其他
{1S(D),(x,y)∈D0,其他
f(x,y)={
S(D)
1
,(x,y)∈D
0,其他
1
,μ
2
,σ
1
2
,σ
2
2
,ρ),( X , Y ) ∼ N ( μ 1 , μ 2 , σ 1 2 , σ 2 2 , ρ ) (X,Y)\sim N(\mu_{1},\mu_{2},\sigma_{1}{2},\sigma_{2}{2},\rho)(X,Y)∼N(μ
1
,μ
2
,σ
1
2
,σ
2
2
,ρ)
2πσ
1
σ
2
2
.exp{
2(1−ρ
2
)
−1
[
σ
1
2
1
)
2
−2ρ
σ
1
σ
2
1
)(y−μ
2
)
+
σ
2
2
2
)
2
]}
X
(x)F
Y
(y):
ij
=p
i⋅
⋅p
⋅j
(离散型)
⇔ f ( x , y ) = f X ( x ) f Y ( y ) \Leftrightarrow f\left( x,y \right) = f_{X}\left( x \right)f_{Y}\left( y \right)⇔f(x,y)=f
X
(x)f
Y
(y)(连续型)
XY
=0时,称X XX和Y YY不相关,
否则称X XX和Y YY相关
i
,Y=y
i
)=p
ij
,Z=g(X,Y) 则:
k
)=P{g(X,Y)=z
k
}=∑
g(x
i
,y
i
)=z
k
P(X=x
i
,Y=y
j
)
则:
z
(z)=P{g(X,Y)≤z}=∬
g(x,y)≤z
f(x,y)dxdy,f z ( z ) = F z ′ ( z ) f_{z}(z) = F’_{z}(z)f
z
(z)=F
z
′
(z)
X
(x)=∫
−∞
+∞
f(x,y)dy,
f Y ( y ) = ∫ − ∞ + ∞ f ( x , y ) d x f_{Y}(y) = \int_{- \infty}^{+ \infty}{f(x,y)dx}f
Y
(y)=∫
−∞
+∞
f(x,y)dx
D
f(x,y)dxdy
1
,μ
2
,σ
1
2
,σ
2
2
,ρ)
则有:
1
,σ
1
2
),Y∼N(μ
2
,σ
2
2
).
X XX与Y YY相互独立⇔ ρ = 0 \Leftrightarrow \rho = 0⇔ρ=0,即X XX与Y YY不相关。
C 1 X + C 2 Y ∼ N ( C 1 μ 1 + C 2 μ 2 , C 1 2 σ 1 2 + C 2 2 σ 2 2 + 2 C 1 C 2 σ 1 σ 2 ρ ) C_{1}X + C_{2}Y\sim N(C_{1}\mu_{1} + C_{2}\mu_{2},C_{1}{2}\sigma_{1}{2} + C_{2}{2}\sigma_{2}{2} + 2C_{1}C_{2}\sigma_{1}\sigma_{2}\rho)C
1
X+C
2
Y∼N(C
1
μ
1
+C
2
μ
2
,C
1
2
σ
1
2
+C
2
2
σ
2
2
+2C
1
C
2
σ
1
σ
2
ρ)
X {\ X} X关于Y = y Y=yY=y的条件分布为: N ( μ 1 + ρ σ 1 σ 2 ( y − μ 2 ) , σ 1 2 ( 1 − ρ 2 ) ) N(\mu_{1} + \rho\frac{\sigma_{1}}{\sigma_{2}}(y - \mu_{2}),\sigma_{1}^{2}(1 - \rho^{2}))N(μ
1
+ρ
σ
2
1
(y−μ
2
),σ
1
2
(1−ρ
2
))
Y YY关于X = x X = xX=x的条件分布为: N ( μ 2 + ρ σ 2 σ 1 ( x − μ 1 ) , σ 2 2 ( 1 − ρ 2 ) ) N(\mu_{2} + \rho\frac{\sigma_{2}}{\sigma_{1}}(x - \mu_{1}),\sigma_{2}^{2}(1 - \rho^{2}))N(μ
2
+ρ
σ
1
2
(x−μ
1
),σ
2
2
(1−ρ
2
))
(4) 若X XX与Y YY独立,且分别服从N ( μ 1 , σ 1 2 ) , N ( μ 1 , σ 2 2 ) , N(\mu_{1},\sigma_{1}{2}),N(\mu_{1},\sigma_{2}{2}),N(μ
1
,σ
1
2
),N(μ
1
,σ
2
2
),
则:( X , Y ) ∼ N ( μ 1 , μ 2 , σ 1 2 , σ 2 2 , 0 ) , \left( X,Y \right)\sim N(\mu_{1},\mu_{2},\sigma_{1}{2},\sigma_{2}{2},0),(X,Y)∼N(μ
1
,μ
2
,σ
1
2
,σ
2
2
,0),
1
X+C
2
Y
N(C
1
μ
1
+C
2
μ
2
,C
1
2
σ
1
2
C
2
2
σ
2
2
).
6.随机变量函数的数学期望
i
}=p
i
,E(Y)=∑
i
g(x
i
)p
i
;
−∞
+∞
g(x)f(x)dx
i
,Y=y
j
}=p
ij
; E ( Z ) = ∑ i ∑ j g ( x i , y j ) p i j E(Z) = \sum_{i}{}{\sum_{j}{}{g(x_{i},y_{j})p_{{ij}}}}E(Z)=∑
i
∑
j
g(x
i
,y
j
)p
ij
( X , Y ) ∼ f ( x , y ) \left( X,Y \right)\sim f(x,y)(X,Y)∼f(x,y);E ( Z ) = ∫ − ∞ + ∞ ∫ − ∞ + ∞ g ( x , y ) f ( x , y ) d x d y E(Z) = \int_{- \infty}^{+ \infty}{\int_{- \infty}^{+ \infty}{g(x,y)f(x,y)dxdy}}E(Z)=∫
−∞
+∞
∫
−∞
+∞
g(x,y)f(x,y)dxdyρ X Y = C o v ( X , Y ) D ( X ) D ( Y ) \rho_{{XY}} = \frac{Cov(X,Y)}{\sqrt{D(X)}\sqrt{D(Y)}}ρ
XY
,k kk阶原点矩 E ( X k ) E(X^{k})E(X
k
);
k kk阶中心矩 E { [ X − E ( X ) ] k } E\left{ {\lbrack X - E(X)\rbrack}^{k} \right}E{[X−E(X)]
k
}
1
+X
2
,Y)=Cov(X
1
,Y)+Cov(X
2
,Y)
,其中a < 0 a < 0a<0
2
)−E
2
(X)
1.基本概念
1
,X
2
⋯,X
n
,称为容量为n nn的简单随机样本,简称样本。
1
,X
2
⋯,X
n
,是来自总体X XX的一个样本,g ( X 1 , X 2 ⋯ , X n ) g(X_{1},X_{2}\cdots,X_{n})g(X
1
,X
2
⋯,X
n
))是样本的连续函数,且g ( ) g()g()中不含任何未知参数,则称g ( X 1 , X 2 ⋯ , X n ) g(X_{1},X_{2}\cdots,X_{n})g(X
1
,X
2
⋯,X
n
)为统计量。样本均值:X ‾ = 1 n ∑ i = 1 n X i \overline{X} = \frac{1}{n}\sum_{i = 1}^{n}X_{i}
X
1
∑
i=1
n
X
i
样本方差:S 2 = 1 n − 1 ∑ i = 1 n ( X i − X ‾ ) 2 S^{2} = \frac{1}{n - 1}\sum_{i = 1}^{n}{(X_{i} - \overline{X})}^{2}S
2
1
∑
i=1
n
(X
i
−
X
)
2样本矩:样本k kk阶原点矩:A k = 1 n ∑ i = 1 n X i k , k = 1 , 2 , ⋯ A_{k} = \frac{1}{n}\sum_{i = 1}{n}X_{i}{k},k = 1,2,\cdotsA
k
1
∑
i=1
n
X
i
k
,k=1,2,⋯样本k kk阶中心矩:B k = 1 n ∑ i = 1 n ( X i − X ‾ ) k , k = 1 , 2 , ⋯ B_{k} = \frac{1}{n}\sum_{i = 1}^{n}{(X_{i} - \overline{X})}^{k},k = 1,2,\cdotsB
k
1
∑
i=1
n
(X
i
−
X
)
k
,k=1,2,⋯
2
分布:χ 2 = X 1 2 + X 2 2 + ⋯ + X n 2 ∼ χ 2 ( n ) \chi^{2} = X_{1}^{2} + X_{2}^{2} + \cdots + X_{n}{2}\sim\chi{2}(n)χ
2
=X
1
2
+X
2
2
+⋯+X
n
2
∼χ
2
(n),其中X 1 , X 2 ⋯ , X n , X_{1},X_{2}\cdots,X_{n},X
1
,X
2
⋯,X
n
,相互独立,且同服从N ( 0 , 1 ) N(0,1)N(0,1)
Y/n
∼t(n) ,其中X ∼ N ( 0 , 1 ) , Y ∼ χ 2 ( n ) , X\sim N\left( 0,1 \right),Y\sim\chi^{2}(n),X∼N(0,1),Y∼χ
2
(n),且X XX,Y YY 相互独立。
Y/n
2
1
∼F(n
1
,n
2
),其中X ∼ χ 2 ( n 1 ) , Y ∼ χ 2 ( n 2 ) , X\sim\chi^{2}\left( n_{1} \right),Y\sim\chi^{2}(n_{2}),X∼χ
2
(n
1
),Y∼χ
2
(n
2
),且X XX,Y YY相互独立。
α
)=α,则称x α x_{\alpha}x
α
为X XX的α \alphaα分位数
1
,X
2
⋯,X
n
为来自正态总体N ( μ , σ 2 ) N(\mu,\sigma^{2})N(μ,σ
2
)的样本,X ‾ = 1 n ∑ i = 1 n X i , S 2 = 1 n − 1 ∑ i = 1 n ( X i − X ‾ ) 2 , \overline{X} = \frac{1}{n}\sum_{i = 1}{n}X_{i},S{2} = \frac{1}{n - 1}\sum_{i = 1}^{n}{{(X_{i} - \overline{X})}^{2},}
Xn
1
∑
i=1
n
X
i
,S
2
1
∑
i=1
n
(X
i
−
X
)
2
,则:
X
∼N(μ,
n
σ
2
) 或者X ‾ − μ σ n ∼ N ( 0 , 1 ) \frac{\overline{X} - \mu}{\frac{\sigma}{\sqrt{n}}}\sim N(0,1)
n
−μ
∼N(0,1)
( n − 1 ) S 2 σ 2 = 1 σ 2 ∑ i = 1 n ( X i − X ‾ ) 2 ∼ χ 2 ( n − 1 ) \frac{(n - 1)S{2}}{\sigma{2}} = \frac{1}{\sigma^{2}}\sum_{i = 1}^{n}{{(X_{i} - \overline{X})}{2}\sim\chi{2}(n - 1)}
σ
2
2
2
∑
i=1
n
(X
i
−
X
)
2
∼χ
2
(n−1)
1 σ 2 ∑ i = 1 n ( X i − μ ) 2 ∼ χ 2 ( n ) \frac{1}{\sigma^{2}}\sum_{i = 1}^{n}{{(X_{i} - \mu)}{2}\sim\chi{2}(n)}
σ
2
∑
i=1
n
(X
i
−μ)
2
∼χ
2
(n)
4) X ‾ − μ S / n ∼ t ( n − 1 ) {\ \ }\frac{\overline{X} - \mu}{S/\sqrt{n}}\sim t(n - 1)
S/
n
−μ
∼t(n−1)
2
∼χ
2
(n),有E ( χ 2 ( n ) ) = n , D ( χ 2 ( n ) ) = 2 n ; E(\chi^{2}(n)) = n,D(\chi^{2}(n)) = 2n;E(χ
2
(n))=n,D(χ
2
(n))=2n;
n−2
n
(n>2);
F(m,n),有 1 F ∼ F ( n , m ) , F a / 2 ( m , n ) = 1 F 1 − a / 2 ( n , m ) ; \frac{1}{F}\sim F(n,m),F_{a/2}(m,n) = \frac{1}{F_{1 - a/2}(n,m)};
F
1
∼F(n,m),F
a/2
(m,n)=
F
1−a/2
(n,m)
1
;
(4) 对于任意总体X XX,有 E ( X ‾ ) = E ( X ) , E ( S 2 ) = D ( X ) , D ( X ‾ ) = D ( X ) n E(\overline{X}) = E(X),E(S^{2}) = D(X),D(\overline{X}) = \frac{D(X)}{n}E(
X
)=E(X),E(S
2
)=D(X),D(
X
)=
n
D(X)
概率论和数理统计
随机事件和概率
1.事件的关系与运算
1
,A
2
,……是互不相容的事件序列,则P ( A 1 ⋂ A 2 ) = P ( A 1 ) + P ( A 2 ) + … … P(A_{1}\bigcap A_{2})=P(A_{1})+P(A_{2})+……P(A
1
⋂A
2
)=P(A
1
)+P(A
2
)+……
B
ˉ
,B=
A
ˉ
2.运算律
(1) 交换律:A ⋃ B = B ⋃ A , A ⋂ B = B ⋂ A A\bigcup B=B\bigcup A,A\bigcap B=B\bigcap AA⋃B=B⋃A,A⋂B=B⋂A
(2) 结合律:( A ⋃ B ) ⋃ C = A ⋃ ( B ⋃ C ) (A\bigcup B)\bigcup C=A\bigcup (B\bigcup C)(A⋃B)⋃C=A⋃(B⋃C)
(3) 分配律:( A ⋂ B ) ⋂ C = A ⋂ ( B ⋂ C ) (A\bigcap B)\bigcap C=A\bigcap (B\bigcap C)(A⋂B)⋂C=A⋂(B⋂C)
3.德⋅ \centerdot⋅摩根律A ⋃ B ‾ = A ˉ ⋂ B ˉ \overline{A\bigcup B}=\bar{A}\bigcap \bar{B}
A⋃B
A
ˉ
⋂
B
ˉ
A ⋂ B ‾ = A ˉ ⋃ B ˉ \overline{A\bigcap B}=\bar{A}\bigcup \bar{B}
A⋂B
ˉ
⋃
B
ˉ
1
A
2
⋯A
n
两两互斥,且和事件为必然事件,即A i ∩ A j = ∅ , i ≠ j , ⋃ i = 1 n = Ω . {A{i}} \cap A_{j}=\varnothing, i \neq j, \bigcup_{i=1}^{n}=\Omega\ .A
i
∩A
j
=∅,i
=j,⋃
i=1
n
=Ω .
5.概率的基本公式
(1)条件概率:
P ( B ∣ A ) = P ( A ⋂ B ) P ( A ) P(B|A)=\frac{P(A\bigcap B)}{P(A)}P(B∣A)=
P(A)
P(A⋂B)
,表示A AA发生的条件下,B BB发生的概率。
(2)全概率公式:
P ( A ) = ∑ i = 1 n P ( A ∣ B i ) P ( B i ) , B i B j = ∅ , i ≠ j , ⋃ n i = 1 B i = Ω P(A)=\sum\limits_{i=1}^{n}{P(A|{{B}{i}})P({{B}{i}}),{{B}{i}}{{B}{j}}}=\varnothing ,i\ne j,\underset{i=1}{\overset{n}{\mathop{\bigcup }}},{{B}_{i}}=\OmegaP(A)=
i=1
∑
n
P(A∣B
i
)P(B
i
),B
i
B
j
=∅,i
=j,
i=1
⋃
n
B
i
=Ω 如何推出? 条件概率变形,P ( A ⋂ B ) = P ( B ∣ A ) P ( A ) P(A\bigcap B)=P(B|A)P(A)P(A⋂B)=P(B∣A)P(A)
(3) Bayes公式:
P ( B j ∣ A ) = P ( A ∣ B j ) P ( B j ) ∑ i = 1 n P ( A ∣ B i ) P ( B i ) , j = 1 , 2 , ⋯ , n P({{B}{j}}|A)=\frac{P(A|{{B}{j}})P({{B}{j}})}{\sum\limits{i=1}^{n}{P(A|{{B}{i}})P({{B}{i}})}},j=1,2,\cdots ,nP(B
j
∣A)=
i=1
∑
n
P(A∣B
i
)P(B
i
)
P(A∣B
j
)P(B
j
)
,j=1,2,⋯,n
注:上述公式中事件B i {{B}{i}}B
i
的个数可为可列个。
(4)乘法公式:
P ( A 1 A 2 ) = P ( A 1 ) P ( A 2 ∣ A 1 ) = P ( A 2 ) P ( A 1 ∣ A 2 ) P({{A}{1}}{{A}{2}})=P({{A}{1}})P({{A}{2}}|{{A}{1}})=P({{A}{2}})P({{A}{1}}|{{A}{2}})P(A
1
A
2
)=P(A
1
)P(A
2
∣A
1
)=P(A
2
)P(A
1
∣A
2
)
P ( A 1 A 2 ⋯ A n ) = P ( A 1 ) P ( A 2 ∣ A 1 ) P ( A 3 ∣ A 1 A 2 ) ⋯ P ( A n ∣ A 1 A 2 ⋯ A n − 1 ) P({{A}{1}}{{A}{2}}\cdots {{A}{n}})=P({{A}{1}})P({{A}{2}}|{{A}{1}})P({{A}{3}}|{{A}{1}}{{A}{2}})\cdots P({{A}{n}}|{{A}{1}}{{A}{2}}\cdots {{A}{n-1}})P(A
1
A
2
⋯A
n
)=P(A
1
)P(A
2
∣A
1
)P(A
3
∣A
1
A
2
)⋯P(A
n
∣A
1
A
2
⋯A
n−1
)
6.事件的独立性
(1)A AA与B BB相互独立⇔ P ( A B ) = P ( A ) P ( B ) \Leftrightarrow P(AB)=P(A)P(B)⇔P(AB)=P(A)P(B)
(2)A AA,B BB,C CC两两独立
⇔ P ( A B ) = P ( A ) P ( B ) \Leftrightarrow P(AB)=P(A)P(B)⇔P(AB)=P(A)P(B);P ( B C ) = P ( B ) P ( C ) P(BC)=P(B)P©P(BC)=P(B)P© ;P ( A C ) = P ( A ) P ( C ) P(AC)=P(A)P©P(AC)=P(A)P©;
(3)A AA,B BB,C CC相互独立
⇔ P ( A B ) = P ( A ) P ( B ) \Leftrightarrow P(AB)=P(A)P(B)⇔P(AB)=P(A)P(B); P ( B C ) = P ( B ) P ( C ) P(BC)=P(B)P©P(BC)=P(B)P© ;
P ( A C ) = P ( A ) P ( C ) P(AC)=P(A)P©P(AC)=P(A)P© ; P ( A B C ) = P ( A ) P ( B ) P ( C ) P(ABC)=P(A)P(B)P©P(ABC)=P(A)P(B)P©
7.独立重复试验
P ( X = k ) = C n k p k ( 1 − p ) n − k P(X=k)=C_{n}{k}{{p}{k}}{{(1-p)}^{n-k}}P(X=k)=C
n
k
p
k
(1−p)
n−k
( 1 ) P ( A ˉ ) = 1 − P ( A ) (1)P(\bar{A})=1-P(A)(1)P(
A
ˉ
)=1−P(A)
( 2 ) P ( A ⋃ B ) = P ( A ) + P ( B ) − P ( A B ) (2)P(A\bigcup B)=P(A)+P(B)-P(AB)(2)P(A⋃B)=P(A)+P(B)−P(AB)
P ( A ⋃ B ⋃ C ) = P ( A ) + P ( B ) + P ( C ) − P ( A B ) − P ( B C ) − P ( A C ) + P ( A B C ) P(A\bigcup B\bigcup C)=P(A)+P(B)+P©-P(AB)-P(BC)-P(AC)+P(ABC)P(A⋃B⋃C)=P(A)+P(B)+P©−P(AB)−P(BC)−P(AC)+P(ABC)
( 3 ) P ( A − B ) = P ( A ) − P ( A B ) (3)P(A-B)=P(A)-P(AB)(3)P(A−B)=P(A)−P(AB)
( 4 ) P ( A B ˉ ) = P ( A ) − P ( A B ) , P ( A ) = P ( A B ) + P ( A B ˉ ) , (4)P(A\bar{B})=P(A)-P(AB),P(A)=P(AB)+P(A\bar{B}),(4)P(A
B
ˉ
)=P(A)−P(AB),P(A)=P(AB)+P(A
B
ˉ
),
P ( A ⋃ B ) = P ( A ) + P ( A ˉ B ) = P ( A B ) + P ( A B ˉ ) + P ( A ˉ B ) P(A\bigcup B)=P(A)+P(\bar{A}B)=P(AB)+P(A\bar{B})+P(\bar{A}B)P(A⋃B)=P(A)+P(
A
ˉ
B)=P(AB)+P(A
B
ˉ
)+P(
A
ˉ
B)
(5)条件概率P ( ⋅ ∣ B ) P(\centerdot |B)P(⋅∣B)满足概率的所有性质,
例如:. P ( A ˉ 1 ∣ B ) = 1 − P ( A 1 ∣ B ) P({{\bar{A}}{1}}|B)=1-P({{A}{1}}|B)P(
A
ˉ
∣B)=1−P(A
1
∣B)
P ( A 1 ⋃ A 2 ∣ B ) = P ( A 1 ∣ B ) + P ( A 2 ∣ B ) − P ( A 1 A 2 ∣ B ) P({{A}{1}}\bigcup {{A}{2}}|B)=P({{A}{1}}|B)+P({{A}{2}}|B)-P({{A}{1}}{{A}{2}}|B)P(A
1
⋃A
2
∣B)=P(A
1
∣B)+P(A
2
∣B)−P(A
1
A
2
∣B)
P ( A 1 A 2 ∣ B ) = P ( A 1 ∣ B ) P ( A 2 ∣ A 1 B ) P({{A}{1}}{{A}{2}}|B)=P({{A}{1}}|B)P({{A}{2}}|{{A}{1}}B)P(A
1
A
2
∣B)=P(A
1
∣B)P(A
2
∣A
1
B)
(6)若A 1 , A 2 , ⋯ , A n {{A}{1}},{{A}{2}},\cdots ,{{A}{n}}A
1
,A
2
,⋯,A
n
相互独立,则P ( ⋂ i = 1 n A i ) = ∏ i = 1 n P ( A i ) , P(\bigcap\limits_{i=1}{n}{{{A}_{i}}})=\prod\limits_{i=1}{n}{P({{A}{i}})},P(
i=1
⋂
n
A
i
)=
i=1
∏
n
P(A
i
),
P ( ⋃ i = 1 n A i ) = ∏ i = 1 n ( 1 − P ( A i ) ) P(\bigcup\limits{i=1}{n}{{{A}_{i}}})=\prod\limits_{i=1}{n}{(1-P({{A}{i}}))}P(
i=1
⋃
n
A
i
)=
i=1
∏
n
(1−P(A
i
))
(7)互斥、互逆与独立性之间的关系:
A AA与B BB互逆⇒ \Rightarrow⇒ A AA与B BB互斥,但反之不成立,A AA与B BB互斥(或互逆)且均非零概率事件$\Rightarrow $A AA与B BB不独立.
(8)若A 1 , A 2 , ⋯ , A m , B 1 , B 2 , ⋯ , B n {{A}{1}},{{A}{2}},\cdots ,{{A}{m}},{{B}{1}},{{B}{2}},\cdots ,{{B}{n}}A
1
,A
2
,⋯,A
m
,B
1
,B
2
,⋯,B
n
相互独立,则f ( A 1 , A 2 , ⋯ , A m ) f({{A}{1}},{{A}{2}},\cdots ,{{A}{m}})f(A
1
,A
2
,⋯,A
m
)与g ( B 1 , B 2 , ⋯ , B n ) g({{B}{1}},{{B}{2}},\cdots ,{{B}_{n}})g(B
1
,B
2
,⋯,B
n
)也相互独立,其中f ( ⋅ ) , g ( ⋅ ) f(\centerdot ),g(\centerdot )f(⋅),g(⋅)分别表示对相应事件做任意事件运算后所得的事件,另外,概率为1(或0)的事件与任何事件相互独立.
1.随机变量及概率分布
i
)=p
i
,i=1,2,⋯,n,⋯p
i
≥0,∑
i=1
∞
p
i
=1
−∞
+∞
f(x)dx=1
′
(x)分布函数F ( x ) = ∫ − ∞ x f ( t ) d t F(x) = \int_{- \infty}^{x}{f(t){dt}}F(x)=∫
−∞
x
f(t)dt
5.常见分布
k
(1−p)
1−k
,k=0,1
n
k
p
k
(1−p)
n−k
,k=0,1,⋯,n
k!
λ
k
e
−λ
,λ>0,k=0,1,2⋯
1b−a,a
1
,a
2
): φ ( x ) = 1 2 π σ e − ( x − μ ) 2 2 σ 2 , σ > 0 , ∞ < x < + ∞ \varphi(x) =\frac{1}{\sqrt{2\pi}\sigma}e^{- \frac{{(x - \mu)}{2}}{2\sigma{2}}},\sigma > 0,\infty < x < + \inftyφ(x)=
2π
σ
1
e
−
2σ
2
2
λe−λx,x>0,λ>00,
λe−λx,x>0,λ>00,
E(λ):f(x)={
−λx
,x>0,λ>0
0,
k−1
p,0
C
N
n
M
k
C
N−M
n−k
,k=0,1,⋯,min(n,M)
1
)=p
i
,Y=g(X)
j
)=∑
g(x
i
)=y
i
P(X=x
i
)
f
X
(x),Y=g(x)
y
(y)=P(Y≤y)=P(g(X)≤y)=∫
g(x)≤y
f
x
(x)dx, f Y ( y ) = F Y ′ ( y ) f_{Y}(y) = F’_{Y}(y)f
Y
(y)=F
Y
′
(y)
2π
,Φ(0)=
2
1
, Φ ( − a ) = P ( X ≤ − a ) = 1 − Φ ( a ) \Phi( - a) = P(X \leq - a) = 1 - \Phi(a)Φ(−a)=P(X≤−a)=1−Φ(a)
2
)⇒
σ
X−μ
∼N(0,1),P(X≤a)=Φ(
σ
a−μ
)
1.二维随机变量及其联合分布
i
,Y=y
j
}=p
ij
;i,j=1,2,⋯
i⋅
=∑
j=1
∞
p
ij
,i=1,2,⋯ p ⋅ j = ∑ i ∞ p i j , j = 1 , 2 , ⋯ p_{\cdot j} = \sum_{i}^{\infty}p_{{ij}},j = 1,2,\cdotsp
⋅j
=∑
i
∞
p
ij
,j=1,2,⋯
i
∣Y=y
j
}=
p
⋅j
ij
j
∣X=x
i
}=
p
i⋅
ij
∫ − ∞ + ∞ ∫ − ∞ + ∞ f ( x , y ) d x d y = 1 \int_{- \infty}^{+ \infty}{\int_{- \infty}^{+ \infty}{f(x,y)dxdy}} = 1∫
−∞
+∞
∫
−∞
+∞
f(x,y)dxdy=1
(2) 分布函数:F ( x , y ) = ∫ − ∞ x ∫ − ∞ y f ( u , v ) d u d v F(x,y) = \int_{- \infty}^{x}{\int_{- \infty}^{y}{f(u,v)dudv}}F(x,y)=∫
−∞
x
∫
−∞
y
f(u,v)dudv
X
(x)=∫
−∞
+∞
f(x,y)dy f Y ( y ) = ∫ − ∞ + ∞ f ( x , y ) d x f_{Y}(y) = \int_{- \infty}^{+ \infty}{f(x,y)dx}f
Y
(y)=∫
−∞
+∞
f(x,y)dx
X∣Y
(x∣y)=
f
Y
(y)
f(x,y)
f Y ∣ X ( y ∣ x ) = f ( x , y ) f X ( x ) f_{Y|X}(y|x) = \frac{f(x,y)}{f_{X}(x)}f
Y∣X
(y∣x)=
f
X
(x)
f(x,y)
{1S(D),(x,y)∈D0,其他
{1S(D),(x,y)∈D0,其他
f(x,y)={
S(D)
1
,(x,y)∈D
0,其他
1
,μ
2
,σ
1
2
,σ
2
2
,ρ),( X , Y ) ∼ N ( μ 1 , μ 2 , σ 1 2 , σ 2 2 , ρ ) (X,Y)\sim N(\mu_{1},\mu_{2},\sigma_{1}{2},\sigma_{2}{2},\rho)(X,Y)∼N(μ
1
,μ
2
,σ
1
2
,σ
2
2
,ρ)
2πσ
1
σ
2
2
.exp{
2(1−ρ
2
)
−1
[
σ
1
2
1
)
2
−2ρ
σ
1
σ
2
1
)(y−μ
2
)
+
σ
2
2
2
)
2
]}
X
(x)F
Y
(y):
ij
=p
i⋅
⋅p
⋅j
(离散型)
⇔ f ( x , y ) = f X ( x ) f Y ( y ) \Leftrightarrow f\left( x,y \right) = f_{X}\left( x \right)f_{Y}\left( y \right)⇔f(x,y)=f
X
(x)f
Y
(y)(连续型)
XY
=0时,称X XX和Y YY不相关,
否则称X XX和Y YY相关
i
,Y=y
i
)=p
ij
,Z=g(X,Y) 则:
k
)=P{g(X,Y)=z
k
}=∑
g(x
i
,y
i
)=z
k
P(X=x
i
,Y=y
j
)
则:
z
(z)=P{g(X,Y)≤z}=∬
g(x,y)≤z
f(x,y)dxdy,f z ( z ) = F z ′ ( z ) f_{z}(z) = F’_{z}(z)f
z
(z)=F
z
′
(z)
X
(x)=∫
−∞
+∞
f(x,y)dy,
f Y ( y ) = ∫ − ∞ + ∞ f ( x , y ) d x f_{Y}(y) = \int_{- \infty}^{+ \infty}{f(x,y)dx}f
Y
(y)=∫
−∞
+∞
f(x,y)dx
D
f(x,y)dxdy
1
,μ
2
,σ
1
2
,σ
2
2
,ρ)
则有:
1
,σ
1
2
),Y∼N(μ
2
,σ
2
2
).
X XX与Y YY相互独立⇔ ρ = 0 \Leftrightarrow \rho = 0⇔ρ=0,即X XX与Y YY不相关。
C 1 X + C 2 Y ∼ N ( C 1 μ 1 + C 2 μ 2 , C 1 2 σ 1 2 + C 2 2 σ 2 2 + 2 C 1 C 2 σ 1 σ 2 ρ ) C_{1}X + C_{2}Y\sim N(C_{1}\mu_{1} + C_{2}\mu_{2},C_{1}{2}\sigma_{1}{2} + C_{2}{2}\sigma_{2}{2} + 2C_{1}C_{2}\sigma_{1}\sigma_{2}\rho)C
1
X+C
2
Y∼N(C
1
μ
1
+C
2
μ
2
,C
1
2
σ
1
2
+C
2
2
σ
2
2
+2C
1
C
2
σ
1
σ
2
ρ)
X {\ X} X关于Y = y Y=yY=y的条件分布为: N ( μ 1 + ρ σ 1 σ 2 ( y − μ 2 ) , σ 1 2 ( 1 − ρ 2 ) ) N(\mu_{1} + \rho\frac{\sigma_{1}}{\sigma_{2}}(y - \mu_{2}),\sigma_{1}^{2}(1 - \rho^{2}))N(μ
1
+ρ
σ
2
1
(y−μ
2
),σ
1
2
(1−ρ
2
))
Y YY关于X = x X = xX=x的条件分布为: N ( μ 2 + ρ σ 2 σ 1 ( x − μ 1 ) , σ 2 2 ( 1 − ρ 2 ) ) N(\mu_{2} + \rho\frac{\sigma_{2}}{\sigma_{1}}(x - \mu_{1}),\sigma_{2}^{2}(1 - \rho^{2}))N(μ
2
+ρ
σ
1
2
(x−μ
1
),σ
2
2
(1−ρ
2
))
(4) 若X XX与Y YY独立,且分别服从N ( μ 1 , σ 1 2 ) , N ( μ 1 , σ 2 2 ) , N(\mu_{1},\sigma_{1}{2}),N(\mu_{1},\sigma_{2}{2}),N(μ
1
,σ
1
2
),N(μ
1
,σ
2
2
),
则:( X , Y ) ∼ N ( μ 1 , μ 2 , σ 1 2 , σ 2 2 , 0 ) , \left( X,Y \right)\sim N(\mu_{1},\mu_{2},\sigma_{1}{2},\sigma_{2}{2},0),(X,Y)∼N(μ
1
,μ
2
,σ
1
2
,σ
2
2
,0),
1
X+C
2
Y
N(C
1
μ
1
+C
2
μ
2
,C
1
2
σ
1
2
C
2
2
σ
2
2
).
6.随机变量函数的数学期望
i
}=p
i
,E(Y)=∑
i
g(x
i
)p
i
;
−∞
+∞
g(x)f(x)dx
i
,Y=y
j
}=p
ij
; E ( Z ) = ∑ i ∑ j g ( x i , y j ) p i j E(Z) = \sum_{i}{}{\sum_{j}{}{g(x_{i},y_{j})p_{{ij}}}}E(Z)=∑
i
∑
j
g(x
i
,y
j
)p
ij
( X , Y ) ∼ f ( x , y ) \left( X,Y \right)\sim f(x,y)(X,Y)∼f(x,y);E ( Z ) = ∫ − ∞ + ∞ ∫ − ∞ + ∞ g ( x , y ) f ( x , y ) d x d y E(Z) = \int_{- \infty}^{+ \infty}{\int_{- \infty}^{+ \infty}{g(x,y)f(x,y)dxdy}}E(Z)=∫
−∞
+∞
∫
−∞
+∞
g(x,y)f(x,y)dxdyρ X Y = C o v ( X , Y ) D ( X ) D ( Y ) \rho_{{XY}} = \frac{Cov(X,Y)}{\sqrt{D(X)}\sqrt{D(Y)}}ρ
XY
,k kk阶原点矩 E ( X k ) E(X^{k})E(X
k
);
k kk阶中心矩 E { [ X − E ( X ) ] k } E\left{ {\lbrack X - E(X)\rbrack}^{k} \right}E{[X−E(X)]
k
}
1
+X
2
,Y)=Cov(X
1
,Y)+Cov(X
2
,Y)
,其中a < 0 a < 0a<0
2
)−E
2
(X)
1.基本概念
1
,X
2
⋯,X
n
,称为容量为n nn的简单随机样本,简称样本。
1
,X
2
⋯,X
n
,是来自总体X XX的一个样本,g ( X 1 , X 2 ⋯ , X n ) g(X_{1},X_{2}\cdots,X_{n})g(X
1
,X
2
⋯,X
n
))是样本的连续函数,且g ( ) g()g()中不含任何未知参数,则称g ( X 1 , X 2 ⋯ , X n ) g(X_{1},X_{2}\cdots,X_{n})g(X
1
,X
2
⋯,X
n
)为统计量。样本均值:X ‾ = 1 n ∑ i = 1 n X i \overline{X} = \frac{1}{n}\sum_{i = 1}^{n}X_{i}
X
1
∑
i=1
n
X
i
样本方差:S 2 = 1 n − 1 ∑ i = 1 n ( X i − X ‾ ) 2 S^{2} = \frac{1}{n - 1}\sum_{i = 1}^{n}{(X_{i} - \overline{X})}^{2}S
2
1
∑
i=1
n
(X
i
−
X
)
2样本矩:样本k kk阶原点矩:A k = 1 n ∑ i = 1 n X i k , k = 1 , 2 , ⋯ A_{k} = \frac{1}{n}\sum_{i = 1}{n}X_{i}{k},k = 1,2,\cdotsA
k
1
∑
i=1
n
X
i
k
,k=1,2,⋯样本k kk阶中心矩:B k = 1 n ∑ i = 1 n ( X i − X ‾ ) k , k = 1 , 2 , ⋯ B_{k} = \frac{1}{n}\sum_{i = 1}^{n}{(X_{i} - \overline{X})}^{k},k = 1,2,\cdotsB
k
1
∑
i=1
n
(X
i
−
X
)
k
,k=1,2,⋯
2
分布:χ 2 = X 1 2 + X 2 2 + ⋯ + X n 2 ∼ χ 2 ( n ) \chi^{2} = X_{1}^{2} + X_{2}^{2} + \cdots + X_{n}{2}\sim\chi{2}(n)χ
2
=X
1
2
+X
2
2
+⋯+X
n
2
∼χ
2
(n),其中X 1 , X 2 ⋯ , X n , X_{1},X_{2}\cdots,X_{n},X
1
,X
2
⋯,X
n
,相互独立,且同服从N ( 0 , 1 ) N(0,1)N(0,1)
Y/n
∼t(n) ,其中X ∼ N ( 0 , 1 ) , Y ∼ χ 2 ( n ) , X\sim N\left( 0,1 \right),Y\sim\chi^{2}(n),X∼N(0,1),Y∼χ
2
(n),且X XX,Y YY 相互独立。
Y/n
2
1
∼F(n
1
,n
2
),其中X ∼ χ 2 ( n 1 ) , Y ∼ χ 2 ( n 2 ) , X\sim\chi^{2}\left( n_{1} \right),Y\sim\chi^{2}(n_{2}),X∼χ
2
(n
1
),Y∼χ
2
(n
2
),且X XX,Y YY相互独立。
α
)=α,则称x α x_{\alpha}x
α
为X XX的α \alphaα分位数
1
,X
2
⋯,X
n
为来自正态总体N ( μ , σ 2 ) N(\mu,\sigma^{2})N(μ,σ
2
)的样本,X ‾ = 1 n ∑ i = 1 n X i , S 2 = 1 n − 1 ∑ i = 1 n ( X i − X ‾ ) 2 , \overline{X} = \frac{1}{n}\sum_{i = 1}{n}X_{i},S{2} = \frac{1}{n - 1}\sum_{i = 1}^{n}{{(X_{i} - \overline{X})}^{2},}
Xn
1
∑
i=1
n
X
i
,S
2
1
∑
i=1
n
(X
i
−
X
)
2
,则:
X
∼N(μ,
n
σ
2
) 或者X ‾ − μ σ n ∼ N ( 0 , 1 ) \frac{\overline{X} - \mu}{\frac{\sigma}{\sqrt{n}}}\sim N(0,1)
n
−μ
∼N(0,1)
( n − 1 ) S 2 σ 2 = 1 σ 2 ∑ i = 1 n ( X i − X ‾ ) 2 ∼ χ 2 ( n − 1 ) \frac{(n - 1)S{2}}{\sigma{2}} = \frac{1}{\sigma^{2}}\sum_{i = 1}^{n}{{(X_{i} - \overline{X})}{2}\sim\chi{2}(n - 1)}
σ
2
2
2
∑
i=1
n
(X
i
−
X
)
2
∼χ
2
(n−1)
1 σ 2 ∑ i = 1 n ( X i − μ ) 2 ∼ χ 2 ( n ) \frac{1}{\sigma^{2}}\sum_{i = 1}^{n}{{(X_{i} - \mu)}{2}\sim\chi{2}(n)}
σ
2
∑
i=1
n
(X
i
−μ)
2
∼χ
2
(n)
4) X ‾ − μ S / n ∼ t ( n − 1 ) {\ \ }\frac{\overline{X} - \mu}{S/\sqrt{n}}\sim t(n - 1)
S/
n
−μ
∼t(n−1)
2
∼χ
2
(n),有E ( χ 2 ( n ) ) = n , D ( χ 2 ( n ) ) = 2 n ; E(\chi^{2}(n)) = n,D(\chi^{2}(n)) = 2n;E(χ
2
(n))=n,D(χ
2
(n))=2n;
n−2
n
(n>2);
F(m,n),有 1 F ∼ F ( n , m ) , F a / 2 ( m , n ) = 1 F 1 − a / 2 ( n , m ) ; \frac{1}{F}\sim F(n,m),F_{a/2}(m,n) = \frac{1}{F_{1 - a/2}(n,m)};
F
1
∼F(n,m),F
a/2
(m,n)=
F
1−a/2
(n,m)
1
;
(4) 对于任意总体X XX,有 E ( X ‾ ) = E ( X ) , E ( S 2 ) = D ( X ) , D ( X ‾ ) = D ( X ) n E(\overline{X}) = E(X),E(S^{2}) = D(X),D(\overline{X}) = \frac{D(X)}{n}E(
X
)=E(X),E(S
2
)=D(X),D(
X
)=
n
D(X)