javaEE 初阶 — 线程安全的集合类
文章目录
- 1. 多线程环境使用 ArrayList
- 多线程使用队列
- 3. 多线程环境使用哈希表
-
- 3.1 Hashtable
- 3.2 ConcurrentHashMap
- 4. 相关面试题
1. 多线程环境使用 ArrayList
java 标准库里的大部分集合类都是 “线程不安全” 的。
多个线程使用同一个集合类对象,很有可能会出问题。
Vector,Stack,HashTable,是线程安全的(不建议用),其他的集合类不是线程安全的。
1、自己加锁,自己使用 synchronized 或者 ReentrantLock
2、Collections.synchronizedList 这里会提供一些 ArrayList 相关的方法,同时是带锁的。
3、使用 CopyOnWriteArrayList
简称为 COW ,也叫做 “写时拷贝” 。
如果针对这个 ArrayList 进行读操作,不作任何额外的工作。
如果进行写操作,则拷贝一份新的 ArrayList ,针对新的进行修改,修改过程中如果有读操作,就继续旧的这份数据。
当修改完毕了,使用新的替换旧的(本质上就是一个引用之间的赋值,原子的)
这种方案的优点是 不需要加锁;缺点是 要求这个 ArrayList 不能太大
只适用于数组比较小的情况。
多线程使用队列
\
3. 多线程环境使用哈希表
HashMap 是线程不安全的,HashTable 是线程安全的(内部给关键方法加上了synchronized)
但是更推荐的是:ConcurrentHashMap ,这是更优化的线程安全哈希表。
3.1 Hashtable
Hashtable 的做法是直接在方法上加 synchronized ,等于是给 this 加锁。
只要操作哈希表上的任意元素,都会产生加锁,也就都会发生锁冲突。
但是实际上仔细思考不难发现,其实基于哈希表的结构特点有些元素在进行并发操作的时候,
是不会产生线程安全问题的,也就不需要使用锁控制。
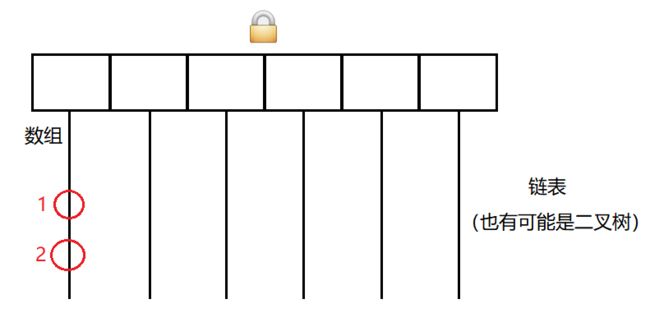
此时元素 1 和 2 在同一个链表上。
如果线程A修改元素 1 ,线程 B 修改元素 2 ,是否有线程安全问题?(修改可能包含 增删改)
这个情况是需要加锁的,比如这两个元素相邻,此时并发的插入或者删除,就要修改这两个结点相邻的结点的 next 的指向。
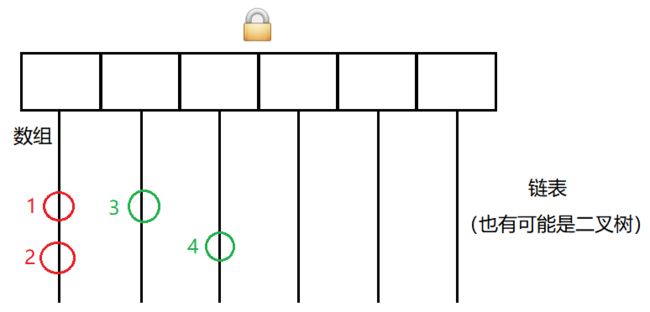
如果线程 A 修改元素 3 ,线程 B 修改元素 4 是否有线程安全问题呢?
这个情况是不需要加锁的,这时就相当于多个线程修改不同的变量。
HashMap 锁冲突概率太大了,任何两个元素都会有锁冲突,即使是处在不同的链表上。
(这是不用 HashMap 的最主要原因)
3.2 ConcurrentHashMap
ConcurrentHashMap 进行了哪些优化?比 Hashtable 好在哪里?和 Hashtable 之间的区别是什么?
1、最大的优化之处:ConcurrentHashMap 相比于 Hashtable 大大缩小了锁冲突的概率
可以理解为把一把大锁转换成了多把小锁。
ConcurrentHashMap 的做法是每个链表有各自的锁,而不是大家共用一个锁。
具体来说就是使用每个链表得头结点作为锁对象。
(两个线程针对同一个锁对象加锁,才会有阻塞等待,针对不同对象,没有锁竞争)
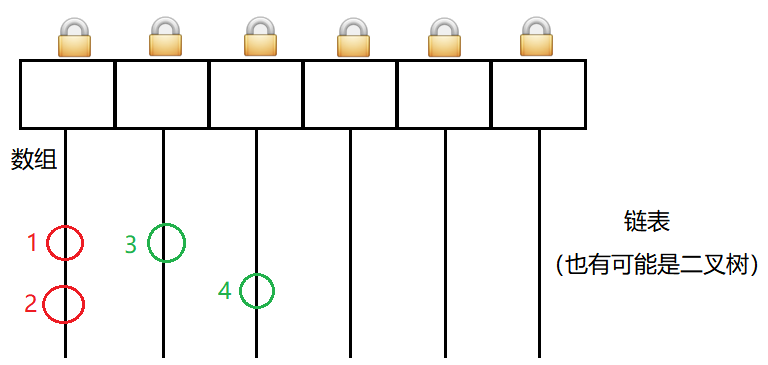
此时锁的粒度变小了。
针对 1 2 这个情况,是针对同一把锁进行加锁。会有锁竞争,会保证线程安全。
针对 3 4 这个情况,是针对于不同的锁进行加锁。不会有锁竞争,没有阻塞等待,程序就会更快。
(这是相对的快,但是不回比加锁快)
2、ConcurrentHashMap 做了一个激进的操作
针对读操作,不加锁,只针对写操作加锁。
读和读之间没有冲突,读和写之间也没有冲突,写和写之间有冲突。
很多场景下,读写之间不加锁控制,可能会读到一个写了一半的结果,如果写操作不是原子的,此时读就可能会读到写了一半的锁,相当于是脏读了。
3、ConcurrentHashMap 内部充分的使用了 CAS ,通过这个也来进一步的消减加锁操作的数目
比如维护元素个数。
4、针对扩容,采取了 化整为零 的方式
HashMap 或者 HashTable 扩容:
创建一个更大的数组空间,把旧的数组上的链表上的每个元素搬运到新的数组上。(删除 + 插入)
这个扩容操作会在某次 put 的时候进行触发。
如果元素的个数特别多,就会导致这样的搬运操作比较耗时。
就会出现某次 put 的时候比平时的 put 卡好多倍。
ConcurrentHashMap 中采取的扩容方式是每次搬运一小部分元素的方式。
创建新的数组,旧的数组也保留。
每次 put 操作,都会往新数组上添加,同时进行一部分的搬运(把一部分旧的元素搬运到新数组上)
每次 get 的时候,则是旧数组和新数组都查询。
每次 remove 的时候,只是把元素删了就行了。
经过一段时间后,所有的元素都搬运好了,最终再释放旧数组。
4. 相关面试题
1、ConcurrentHashMap的读是否要加锁,为什么?
读操作没有加锁,目的是为了进一步降低锁冲突的概率。
为了保证读到刚修改的数据,搭配了volatile 关键字。
2、介绍下 ConcurrentHashMap的锁分段技术?
这个是 Java1.7 中采取的技术。Java1.8 中已经不再使用了。
简单的说就是把若干个哈希桶分成一个"段" (Segment),针对每个段分别加锁。
目的也是为了降低锁竞争的概率,当两个线程访问的数据恰好在同一个段上的时候,才触发锁竞争。

3、ConcurrentHashMap在jdk1.8做了哪些优化?
取消了分段锁,直接给每个哈希桶(每个链表)分配了一个锁(就是以每个链表的头结点对象作为锁对
象)。
将原来 数组 + 链表 的实现方式改进成 数组 + 链表 / 红黑树 的方式。
当链表较长的时候(大于等于8 个元素)就转换成红黑树。
4、Hashtable和HashMap、ConcurrentHashMap 之间的区别?
HashMap:
线程不安全,key 允许为 null。
Hashtable:
线程安全,使用 synchronized 锁 Hashtable 对象,效率较低,key 不允许为 null。
ConcurrentHashMap:
线程安全,使用 synchronized 锁每个链表头结点,锁冲突概率低,充分利用CAS 机制。优化了扩容方式,key 不允许为 null。