超轻量网络学习笔记
预备知识
参数数量和理论计算量
1. 参数数量(params):关系到模型大小,单位通常是M,通常参数用float32表示,所以模型大小是参数数量的4倍
计算公式:
- Kh × Kw × Cin × Cout (Conv卷积网络)
- Cin × Cout (FC全连接网络)
2. 理论计算量(FLOPs):是 floating point operations 的缩写(注意 s 小写,区别于FLOPS每秒浮点运算次数,衡量硬件的指标),指浮点运算数,可以用来衡量算法/模型的复杂度,这关系到算法速度,大模型的单位通常为G,小模型单位通常为M;通常只考虑乘加操作的数量,而且只考虑Conv和FC等参数层的计算量,忽略BN和PReLU等,一般情况下,Conv和FC层也会忽略仅纯加操作的计算量,如bias偏置加和shoutcut残差加等,目前技术有BN和CNN可以不加bias。
计算公式:
- Kh × Kw × Cin × Cout × H × W = params × H × W (Conv卷积网络)
- Cin x Cout (FC全连接网络)
计算量 = 输出的feature map * 当前层filter 即(H × W × Cout) × (K × K × Cin)
推荐一个实用的计算工具(pytorch):torchstat
下载链接:https://github.com/Swall0w/torchstat
可以用来计算pytorch构建的网络的参数,空间大小,MAdd,FLOPs等指标,简单好用。
比如:我想知道alexnet的网络的一些参数。
只需要:
from torchstat import stat
import torchvision.models as models
model = model.alexnet()
stat(model, (3, 224, 224))
一、Squeeze Net | 轻量级深层神经网络
简介:SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5MB model size. 论文的题目直接表达了论文的成果,实现了与AlexNet相同的精度,但只用了1/50的参数量。且模型的参数量最少可以压缩到0.5M,这是AlexNet的1/510的参数量。SqueezeNet提出了Fire Module模块实现了参数优化。
发布时间:2016年2月
论文地址:http://arxiv.org/abs/1602.07360
代码链接(Caffe):https://github.com/DeepScale/SqueezeNet
代码链接(Keras):https://github.com/rcmalli/keras-squeezenet
解析博客:
https://www.jianshu.com/p/fdd7d7353c55
https://mp.weixin.qq.com/s
SqueezeNet网络结构:
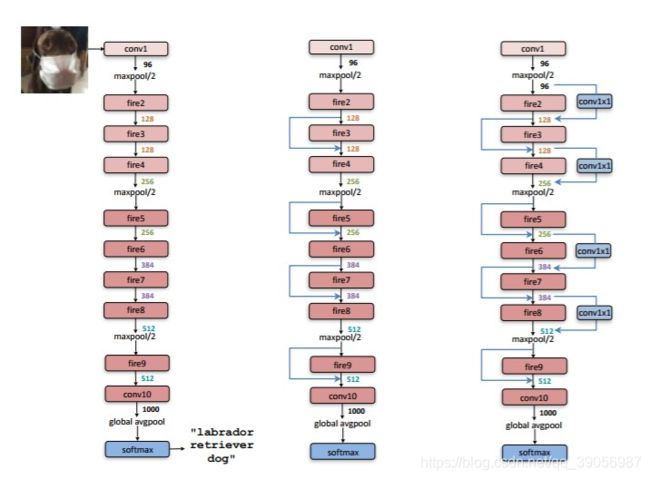
其核心结构Fire Module的组合形成。左图是SqueezeNet的整体结构,中图和有图是将ResNet网络中的shortcut引入构建的网络,所以只是一种提升策略与SqueezeNet无关,本文不讲。
Frie Module结构组成:

- squeeze layer:使用1x1卷积核进行降维;
- expand layer:使用1x1和3x3卷积核的组合进行特征提取和升维;
- Fire Module中有三个可调超参数:S1x1(squeeze layer中1x1卷积核个数),e1x1(expand
layer中1x1卷积核个数),e3x3(expand layer中3x3卷积核个数) - 使用Fire Module过程中,令S1x1
- 将pooling下采样操作延后,可以给卷积层提供更大的激活图,更大的激活图保留了更多的信息,可以提高分类准确率。
SqueezeNet网络中各个层的滤波器参数具体如下:
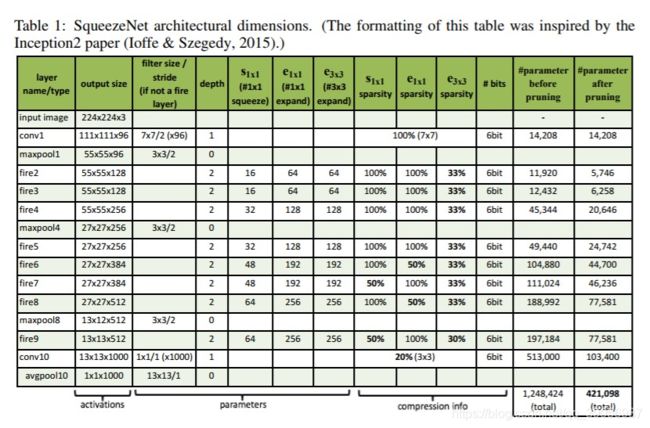
上图解释:例如 fire2 这个模块在剪枝前的参数是11920,这个参数是怎么计算的?
- fire2 之前的maxpool1层的输出是 55x55x96
,之后接着Squeeze层有16个1x1x96的卷积filter,注意这里是多通道卷积,为了避免与二维卷积混淆,在卷积尺寸末尾写上了通道数。这一层的输出尺寸为55x55x16。 - 之后将输出分别送到expand层中的1x1x16(64个)和3x3x16(64个)进行处理,这里不对16个通道进行切分(就是说和MobileNet里面的深度可分离卷积不一样,就是普通卷积),为了得到大小相同的输出,对3x3x16的卷积进行尺寸为1的zero
padding。分别得到了 55x55x64 和 55x55x64 的大小相同的特征图。 - 将这两个特征图concat到一起得到55x55x128大小的特征图,加上bias参数,这样总参数为:
(1x1x96+1) x 16 + (1x1x16+1) x 64 + (3x3x16+1) x 64 = (1552+1088+9280)=11920
Fire Module流程:
- Fire Module中先通过squeeze层的1x1卷积来降维和降低参数;
- 之后expand层用不同尺寸的卷积核来提取特征同时进行升维。这里的3x3的卷积核参数较多,远大于1x1卷积的参数,所以作者对3x3x16卷积又进行了卷积操作和降维操作以减少参数量。
- 从网络整体来看,特征图尺寸不断减小,通道数不断增加,最后使用平均池化将输出维度转换为1x1x1000完成分类任务。
实验结果:

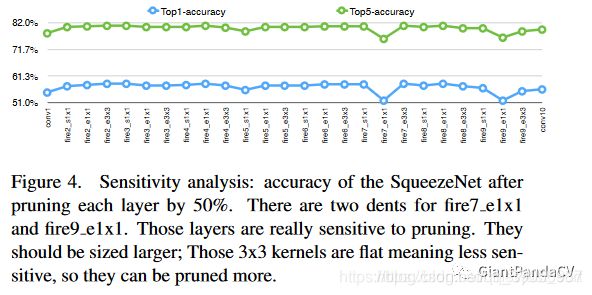
SqueezeNet++:
从Figure4中发现fire7_e1x1和fire9_e1x1在精度上有折痕,所以增加了fire7_e1x1和fire9_e1x1中通道数量,并把这个模型叫做SqueezeNet++
。
二、MobileNet系列
简介:高效的卷积神经网络在移动视觉中的应用
在介绍MobileNet系列之间,先了解一个概念:深度可分离卷积

深度卷积:将卷积核拆分成为但单通道形式,在不改变输入特征图像的深度的情况下,对每一通道进行卷积操作,这样就得到了和输入特征图通道数一致的输出特征图。
逐点卷积:就是1×1卷积。主要作用就是对特征图进行升维和降维
博客解析:
- MobileNet,从V1到V3
- MobileNet系列
2.1 MobileNet V1
发布时间:2017年
创新点:提出了深度可分离卷积,深度可分离卷积将传统的卷积分两步进行,分别是depthwise和pointwise。首先按照通道进行计算按位相乘的计算,此时通道数不改变;然后依然得到将第一步的结果,使用1*1的卷积核进行传统的卷积运算,此时通道数可以进行改变。

计算量的前后对比:
Kh × Kw × Cin × Cout × H × W
变成了 Kh × Kw × Cin × H × W + 1 × 1 × Cin × Cout × H × W
通过深度可分离卷积,当卷积核大小为3时,深度可分离卷积比传统卷积少8到9倍的计算量。
MobileNet V1模型结构:
该网络有28层,除去了pool层,使用stride来进行降采样:

亮点:
- 更多的ReLU,增加了模型的非线性变化,增强了模型的泛化能力;

- v1中使用了ReLU6作为激活函数,这个激活函数在float16/int8的嵌入式设备中效果很好,能较好地保持网络的鲁棒性;
- v1还给出了2个超参,宽度乘子α和分辨率乘子β,通过这两个超参,可以进一步缩减模型,文章中也给出了具体的试验结果。
2.2 MobileNet V2
发布时间:2018年
主要改进点:引入了Inverted Residuals(倒残差模块)和Linear Bottlenecks
V1存在的问题:深度卷积部分的卷积核比较容易训废掉:训完之后发现深度卷积训出来的卷积核有不少是空的,这是因为ReLU导致的,简单来说,就是当低维信息映射到高维,经过ReLU后再映射回低维时,若映射到的维度相对较高,则信息变换回去的损失较小;若映射到的维度相对较低,则信息变换回去后损失很大。
Linear bottleneck:
这个模块是为了解决一开始提出的那个低维-高维-低维的问题,即将最后一层的ReLU替换成线性激活函数,而其他层的激活函数依然是ReLU6。

Inverted Residuals:
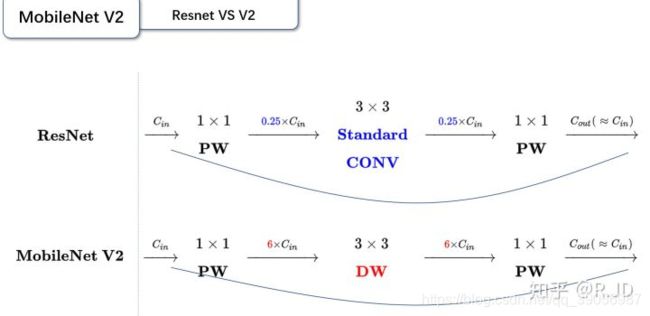
对比一下残差模块和倒残差模块的区别:
残差模块:输入首先经过1x1的卷积进行压缩,然后使用3x3的卷积进行特征提取,最后在用1*1的卷积把通道数变换回去。整个过程是“压缩-卷积-扩张”。这样做的目的是减少3x3模块的计算量,提高残差模块的计算效率。
倒残差模块:输入首先经过1x1的卷积进行通道扩张,然后使用3x3的depthwise卷积,最后使用1x1的pointwise卷积将通道数压缩回去。整个过程是“扩张-卷积-压缩”。为什么这么做呢?因为depthwise卷积不能改变通道数,因此特征提取受限于输入的通道数,所以将通道数先提升上去。文中的扩展因子为6。
将两个模块进行结合,MobileNet v2结构如下图所示。
- 当stride=1时,输入首先经过1x1的卷积进行通道数的扩张,此时激活函数为ReLU6;然后经过3x3的depthwise卷积,激活函数是ReLU6;接着经过1x1的pointwise卷积,将通道数压缩回去,激活函数是linear;最后使用shortcut,将两者进行相加;
- 而当stride=2时,由于input和output的特征图的尺寸不一致,所以就没有shortcut(Add)了.

MobileNet V2网络结构:
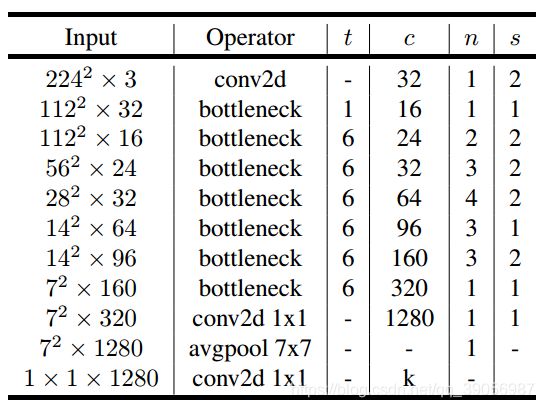
t为扩张系数,c为输出通道数,n为该层重复的次数,s为步长。v2的网络比v1网络深了很多,v2有54层。
2.3 MoblieNet V3
发布时间:2019年
论文地址:https://arxiv.org/abs/1905.02244?context=cs
代码地址:
- https://github.com/xiaolai-sqlai/mobilenetv3
- https://github.com/kuan-wang/pytorch-mobilenet-v3
- https://github.com/leaderj1001/MobileNetV3-Pytorch
概述:结合了v1的深度可分离卷积、v2的Inverted Residuals和Linear Bottleneck、SE模块,利用NAS(神经结构搜索)来搜索网络的配置和参数。
V3两大改进创新点:
一、网络结构改进:
- 对V2耗费最大的输入层和输出层进行改进。在输出层上,将平均池化层提前了,在使用1x1卷积进行扩张后,就紧接池化层-激活函数,最后使用1x1的卷积进行输出,不损失任何精度的情况下,速度提高了15%,耗时减少了10ms。在输入层上,使用ReLU或者switch激活函数,将原来通道数缩减至16层(原来32层),准确率不变,又节省了3ms。

- 在嵌入式设备上,sigmoid是很耗费计算资源的,作者提出了h-switch作为激活函数,随着网络加深,非线性函数的成本会随之减少,在较深的层使用h-switch才能获得更大的优势。
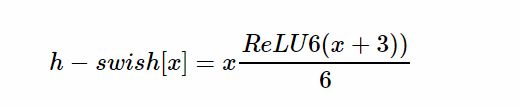
- 在v2的block上引入SE模块,SE模块是一种轻量级的通道注意力模块。在depthwise之后,经过池化层,然后第一个fc层,通道数缩小4倍,再经过第二个fc层,通道数变换回去(扩大4倍),然后与depthwise进行按位相加。

二、互补搜索:
在网络结构搜索中,作者结合两种技术:资源受限的NAS(platform-aware NAS)与NetAdapt,前者用于在计算和参数量受限的前提下搜索网络的各个模块,所以称之为模块级的搜索(Block-wise Search) ,NetAdapt执行局部搜索,用于对各个模块确定之后网络层的微调。
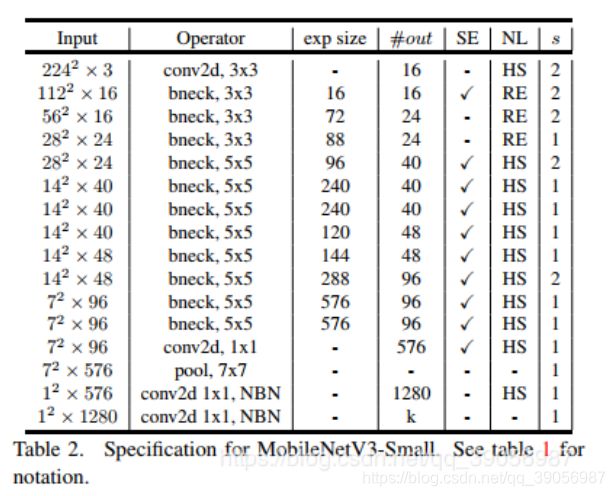
MobilenetV3网络结构:
两个版本,large和small,都是由NAS进行搜索出来的:

2.4 MobileNet系列总结:
- MobileNetV1 模型引入的深度可分离卷积(depthwise separable convolutions);
- MobileNetV2 模型引入的具有线性瓶颈的倒残差结构(the inverted residual with linear bottleneck),去掉了Residual Block最后的ReLU;
- MobileNetV3 模型引入的基于squeeze and excitation结构的轻量级注意力模型,使用NAS互补搜索,使用h-swish函数作为提升了精度,同时对V2网络的输入输出层做了改进。
三、ShuffleNet系列
简介:一个轻量级的卷积神经网络,专用于计算力受限的移动设备。
3.1 ShuffleNet V1
发布时间:2017年
论文地址:https://arxiv.org/abs/1707.01083v1
解析博客:
- 旷世科技 2017 ShuffleNetV1
- shuffleNet v1 v2笔记
主要思想:逐点组卷积(pointwise group convolution)和通道混洗(channel shuffle)
通道混洗:
通过reshape变换将通道打乱,流程为:
- 对一个卷积层分为g组,每组有n个通道
- reshape成(g, n)
- 再转置为(n, g)
- Flatten操作,分为g组作为下一层的输入。
- 通道Shuffle操作是可微的,模型可以保持end-to-end训练。
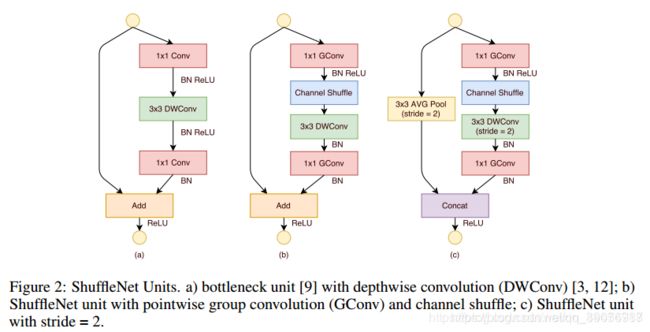
混洗单元:
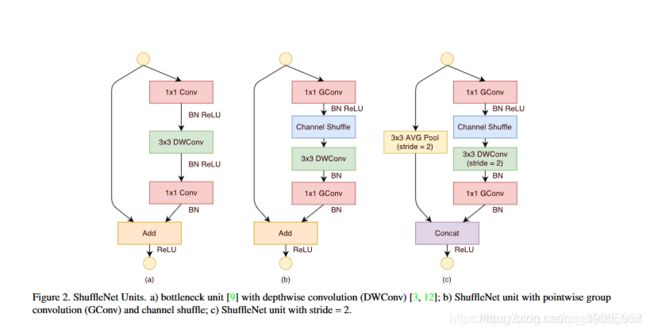
图片解析:
- (a)是一个resnext模块,由一个深度可分离卷积和两个1x1的逐点卷积,配合BN层和ReLu激活函数构成基本单元;
- (b)是一个ShuffleNet Unit,主分支最后的1x1卷积改成了1x1组卷积,为了适配和恒等映射做通道融合,配合BN层和ReLu激活函数构成基本单元;
- (c)是做了下采样的ShuffleNet Unit,改修了两个地方,一是在分支加了步长为2的3x3平均池化,二是原本做元素相加(add)的操作转为了通道级联(Concat),扩大了通道数。
ShuffleNet v1网络结构:

整个架构分为三个阶段:
- 每个阶段的第一个block的步长为2,下一阶段的通道数翻倍;
- 每个阶段内除了步长,其他超参数不变;
- 每个ShuffleNet Unit的bottleneck通道数为输出的1/4;
在ShuffleNet Unit中,参数g控制逐点卷积的连接稀疏性(即分组数),对于给定的限制下,越大的g会有越多的输出通道,这帮助我们编码信息。定制模型需要满足指定的预算,我们可以简单的使用放缩因子s控制通道数,ShuffleNet s×即表示通道数缩放到s倍。
逐点卷积的重要性:
比较相同复杂度下组数从1到8的ShuffleNet模型,通过放缩因子s来控制网络宽度,扩展为3种:
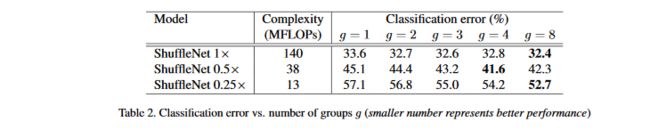
结论:
- 有组卷积的一致比没有组卷积的效果好;
- 对于一些模型(0.5x),随机g增大,性能也会有所下降;
- 在小型的0.25x模型中,组数越大性能越好,这表示对于小模型更宽的特征映射更有效。
通道混洗的重要性:
Shuffle操作是为了实现多个组之间信息交流,下表表现了有无Shuffle操作的性能差异:

结论:
- 三个不同复杂度下带shuffle的都表现出更好的性能;
- 当组更大(arch2, g=8)时,具有shuffle操作性能提升较多,这也表现出了Shuffle的重要性。
ShuffleNet V1总结:
针对现多数有效模型采用的逐点卷积存在的问题,提出了逐点组卷积和通道混洗的处理方法,并在此基础上提出了一个ShuffleNet Unit,后续对该单元做了一系列的实验验证,证明了ShuffleNet的结构有效性。
3.2 ShuffleNet V2
发布时间:2018年7月
论文地址:https://arxiv.org/abs/1807.11164
解析博客:
- shuffleNet v1 v2笔记
- 轻量级神经网络:ShuffleNetV1到ShuffleNetV2
背景分析:
作者认为FLOPs是一种间接的测量指标,是一个近似值,并不是我们真正关心的。我们需要的是直接的指标,比如速度和延迟。
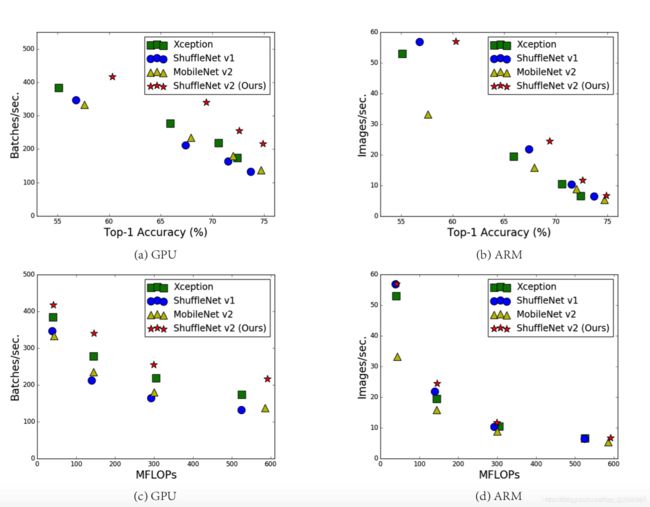
上图中,相同的FLOPs的模型,速度上却差别很大。由此作者提出了第一个观点:使用FLOP作为计算复杂度的唯一指标是不充分的。
理由:
- FLOPs没有考虑几个对速度有相当大影响的重要因素:MAC(内存访问成本)和并行度; MAC(内存访问成本),计算机在进行计算时候要加载到缓存中,然后再计算,这个加载过程是需要时间的。其中,分组卷积(group convolution)是对MAC消耗比较多的操作。
在相同的FLOPs下,具有高并行度的模型可能比具有低并行度的另一个模型快得多。如果网络的并行度较高,那么速度就会有显著的提升。
2. 计算平台的不同。 有些平台会对操作进行优化,比如cudnn加强了对3x3conv的优化。
提出了两个效率对比准则:
- 使用直接度量方式速度代替FLOPs;
- 要在实际目标计算平台上计算,不然结果不具有代表性。
设计指南:
分别在GPU(GTX 1080Ti)和CPU(晓龙810)上对比了ShuffleNetV1,MobileNetV2的运行时间进行了测试。
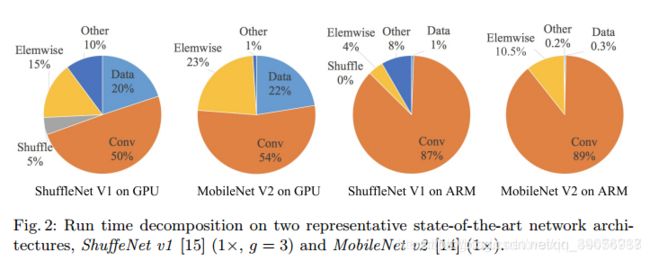
结论:
- 整个运行时被分解用于不同的操作,处理器在运算的时候,不光只是进行卷积运算,也在进行其他的运算,特别是在GPU上,卷积运算只占了运算时间的一般左右;
- 单纯的将卷积操作认为是FLOPs操作是不准确的,虽然这部分消耗时间最多,但其他包括数据IO,数据混洗和逐元素操作(AddTensor,ReLU等)也占用了相当多的时间。
作者从几个不同的方面对运行时间(或速度)进行了详细分析,并为高效的网络架构设计提出了提出四个高效的网络设计指南:
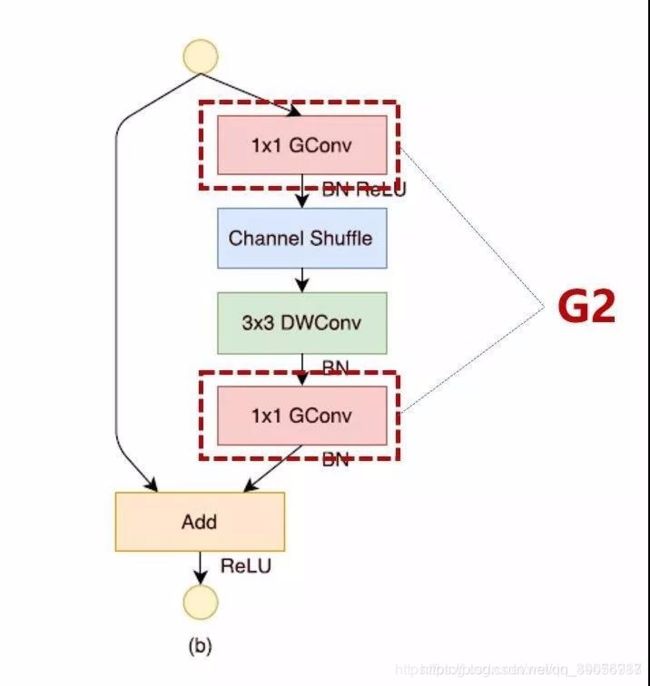
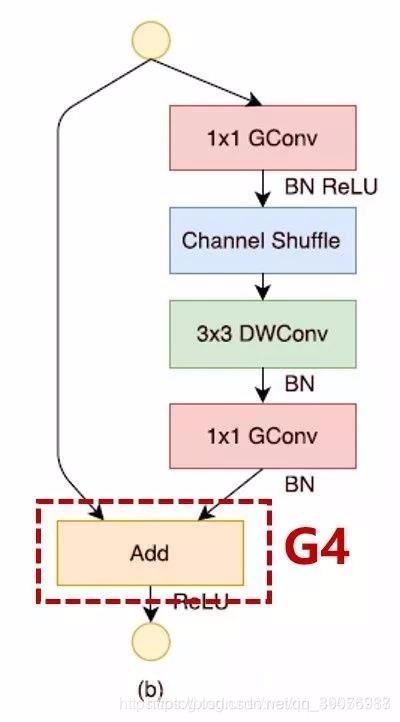
- G1. 当输入输出具有相同channel时,内存消耗最小;
- G2. 过多的分组卷积操作会增大MAC,从而使模型速度变慢;
- G3. 模型中的分支数量越少,模型速度越快;
- G4. element-wise操作导致速度的消耗,远比FLOPs上体现的多,应该减少Element-wise操作。
*注:要理解请看ShuffleNet V2开头的博客链接;
基于上面四条准则,回顾v1结构图,对v1违反了以上四个准则的地方进行修改:
V1存在的问题:

-
问题1. 逐点组卷积增加了MAC违背了G2;
-
问题2. 瓶颈结构违背了G1,使用太多分组也违背了G3;
-
问题3. Add操作是元素级加法操作违反了G4。
解决思路:
保持大量且同样宽的通道,即没有密集卷积也没有太多分组。
引进了:channel split

a.b是V1,c.d是V2
改进点:
- 在每个单元开始,通过Channel split将C特征通道的输入分成两支,分别带有C-C_和C_个通道,按照准则G3,一个分支的结构仍然保持不变,另一个分支由三个卷积构成,为了满足G1,令输入通道和输出通道数相同。将两个1X1组卷积改为普通点卷积,因为Channel Split分割操作已经产生了两个组;
- 卷积之后,把两个分支拼接起来(Concat),从而通道数不变(G1),没有了Add操作(element-wise),然后进行V1相同的Channel Shuffle操作来保证两个分支间能进行信息交流;
- 保留depthwise convolution,重复堆叠上述结构构建网络,称之为ShuffleNet V2.

与之前的结果对比:

四、ThunderNet 两阶段实时检测网络
简介:ThunderNet是旷视和国防科技大学合作提出的目标检测模型,目标是在计算力受限的平台进行实时目标检测。需要关注的地方主要就是提出的两个特征增强模块CEM和SAM,其设计理念和应用的方法都非常值得借鉴。
发布时间:2019年3月
论文地址:https://arxiv.org/pdf/1903.11752.pdf
代码地址:https://github.com/ouyanghuiyu/Thundernet_Pytorch
解析博客:两阶段实时检测网络ThunderNet
backbone:
基于ShuffleNetv2改进得到的SNet。与ShuffleNet区别在于将ShuffleNet中的3x3可分离卷积替换成了5x5的可分离卷积。图片的输入尺寸改为320x320
SNet设计思想:
考虑三个因素:
- 迁移学习:目标检测需要的backbone一般都是在ImageNet上与训练得到的,但是目标检测的backbone和分类器所需要提取的特征是不一致的,简单地将分类模型迁移学习到目标检测中不是最佳选择。
- 感受野: CNN中感受野是非常重要的参数,CNN只能获取到感受野以内的信息,所以更大的感受野通常可以获取更多地语义信息,可以更好地编码长距离关系。
- 浅层和深层的特征: 浅层的feature map分辨率比较大,获取到的是描述空间细节的底层特征。深层的feature map分辨率比较小,但是保存的是更具有鉴别性的高级语义特征。
先前的轻量级模型存在的缺点:
- ShuffleNetV1的感受野只有121个像素,ShuffleNetv2的感受野只有320个像素,感受野比较小。
- ShuffleNetv2和MobileNetv2都缺少浅层的特征。
- Xception由于对计算量的限制导致高级语义信息不足。
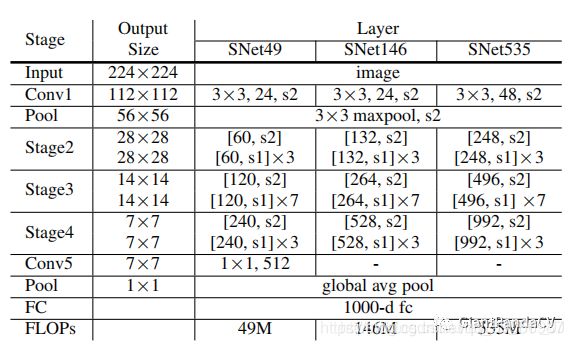
SNet49(speed)、SNet146(trade off)、SNet535(accuracy):
- 将ShuffleNetv2中的所有3x3的深度可分离卷积替换为5x5的深度可分离卷积,两者实际运行速度相差不多,但是有效扩大了有效感受野(参考之前文章目标检测和感受野的总结和思考)
- SNet146和SNet535中去掉了Conv5,并且加宽了浅层网络,进而生成更多的底层特征。
- SNet49将Conv5中的通道个数改为512,也加宽了浅层网络。通过这样操作是为了平衡浅层网络和深层网络。
Detection:

ThunderNet沿用了Light-Head R-CNN的大部分设置,并针对计算量做了部分改进:
- 将RPN中原有256维的3x3卷积替换为5x5的dwconv+1x1conv;
- 设置五个scale{32,64,128,256,512}和5个比例{1:2,3:4,1:1,4:3,2:1};
- 提出PSRoI align来取代RoI warping, 减少RoI个数等。
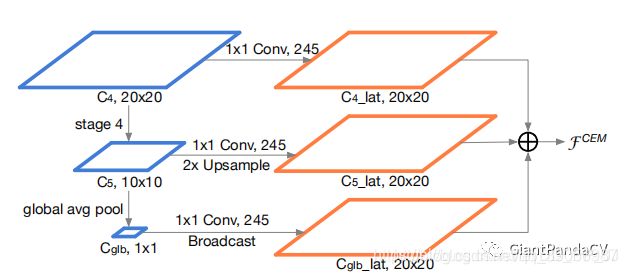
CEM:
针对于Light-Head R-CNN中的Global Convolutional Network(增加感受野机制)的计算量问题提出的,融合多尺度局部信息和全局信息来获取更有鉴别性的特征。
解析:
C4来自backbone的Stage3,C5来自backbone的Stage4。具体操作过程上图很明显,构造了一个多尺度的特征金字塔,然后三个层相加,完成特征的优化。
SAM:
利用RPN得到的feature map,然后用一个Attention机制对特征进行优化;
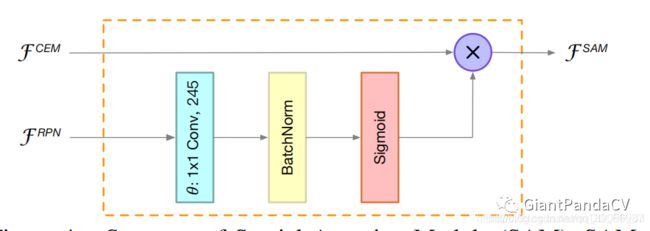
解析:
这个部分设计实际上是比较好的结合了两阶段模型的RPN网络。RPN网络是用来提出proposal的,在RPN中,我们期望背景区域特征不被关注,而更多地关注前景物体特征。
RPN有较强的判别前景和背景的能力,所以这里的就用RPN的特征来指导原有特征,实际上是一个Spatial Attention,通过1x1卷积、BN、Sigmoid得到加权的特征图,引导网络学习到正确的前景背景特征分布。
这个模块也是非常精妙的结合了RPN以及空间Attention机制,非常insight,有效地对轻量级网络特征进行了优化,弥补了轻量网络特征比较弱的缺点。
实验结果:
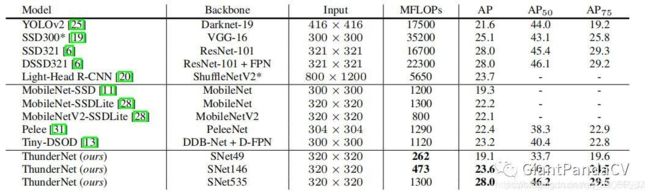
在COCO数据集上的结果,可以看出效果依然非常出众。SNet49的ThunderNet在与MobileNet-SSD相近的精度下,速度快了5倍;SNet146的ThunderNet与one-stage相比,有更高的精度;SNet535的ThunderNet精度在和大型的一阶段网络(SSD,DSSD)一致的情况下,计算量显著降低。
总结:
主要提出了两个重要的模块:CEM 和SAM,CEM总的来说是融合了一个小型的FPN+通道注意力机制,以非常少的计算代价提高了模型的感受野,优化了backbone的特征。SAM总的来说是用RPN的特征加强原有特征,本质上是一种空间注意力机制,这种方法或许可以扩展到所有的多阶段检测器中。
结语:
ThunderNet成功超越了很多一阶段的方法,也让我们改变了传统两阶段网络计算量大但精度高的印象。虽然很多论文中都用到了空间注意力机制和通道注意力机制,ThunderNet中通过自己独到的想法,比较完美地融合了这两个部分,有理有据,非常有力。
本文大部分内容只是总结了论文中的主要知识点,如果想近一步了解,可参考文中提到的解析博客,或者去读原论文。