爬虫与反爬虫的攻防对抗
一、爬虫的简介
1 概念
爬虫最早源于搜索引擎,它是一种按照一定的规则,自动从互联网上抓取信息的程序,又被称为爬虫,网络机器人等。按爬虫功能可以分为网络爬虫和接口爬虫,按授权情况可以分为合法爬虫和恶意爬虫。恶意爬虫主要以获取对方本不愿意被大量获取的网页数据为主要目的,可能给相关服务器性能造成极大损耗。如今数据资源越来越珍贵,利用爬虫技术爬取有价值的数据,成为很多公司弥补自身先天数据短板、提高自身估值的不二选择。
网页爬虫:根据网页上的超链接进行遍历爬取
接口爬虫:通过构造特定API接口请求数据获得大量网页数据信息
2 发展现状
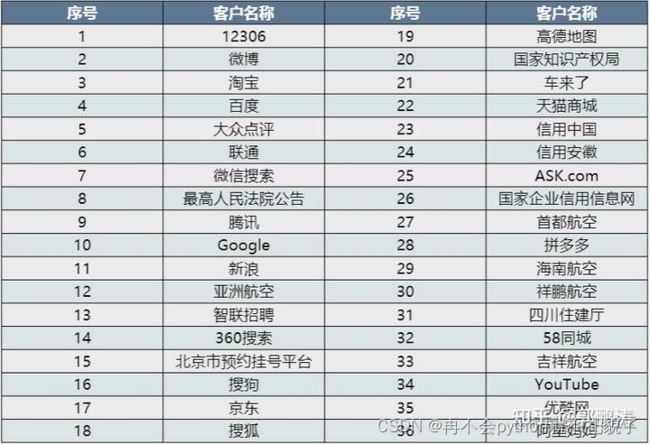
爬虫流量目标行业分布:

其中,出行类中的12306票务信息被各类抢票软件疯狂地爬取,高峰时刻每天的访问量达到千亿次。
在社交类中,通过网络爬虫技术可以指挥一帮网络机器人关注某人的微博、公众号等,进行点赞、关注或者留言,制造大量的僵尸粉。
在电商类中,比如在“比价平台”“聚合电商”和“返利平台”等平台上,当用户搜索一个商品时,这类聚合平台会自动把各个电商的商品都放在你面前供你选择,同样利用的是爬虫技术。
可以从下面的数据中看到,爬虫的“重灾区”在前面说到的12306、微博、淘宝等大型平台,就连最高人民法院旗下的“中国裁判文书网”也难逃爬虫侵扰,以至于用户怨声载道。
3 攻防技术分析
事实上,最早的爬虫起源于搜索引擎。搜索引擎是善意的爬虫,可以检索你的一切信息,并提供给其他用户访问。为此他们还专门定义了robots.txt文件,作为君子协定,这是一个双赢的局面。
然而事情很快被一些人破坏了。爬虫很快就变的不再“君子”了。
爬虫与发爬虫,一方为了拿到数据,另一方为了防止爬虫拿到数据,就催生了攻防技术的不断发展。
目前业内爬虫技术方面,总体分为三大类,最早的就是通过修改headers攻击静态网页,包括多线程,代理ip,伪造cookie和购买多账号等常见手段,对应的反爬虫技术出现了限制IP和ua,限制登录,限制频率等。
后来防守方出现了验证码,很长一段时间爬虫处于劣势,随着机器视觉的发展和打码平台的出现,这种防控也很容易被绕过,黑产进入了模拟用户行为的阶段。
再后来,防守方又出现了动态加载技术,通过简单爬虫是看不到被保护信息的,爬虫就利用了selenium和phantomjs工具,这两个本来是网页自动化测试工具,被用来爬虫,一般爬虫到了这个段位,反爬虫就很难再有有效措施识别爬虫。
技术层面,越原始的,成本越低,性能也非常好,目前是通用的网络爬虫;而高段位的,一般成本高,性能差,一般称为聚焦网络爬虫。

从上面图上可以看到,爬虫与反爬虫,是一场无休止之战。因此要想防住爬虫,就要从根源入手。
二、反爬虫的难点
目前阶段,反爬虫的难点在于技术和业务两个方面。
技术上,一个是现有的常见反爬手段都已被成熟的技术工具攻破,另一个就是黑产已经形成了完整的产业链,分工明确,而且从业人员数量庞大。

业务上,业务安全本质上不是非黑即白的问题,而是要找到划分的边界,如果误杀率过高,可能对运营指标产生影响。

三、解决方案
一般来说,通过验证码来反爬,其核心原理是爬虫通过网页抓取数据,当某一用户访问次数过多后,系统就会怀疑你是否是真实用户,也就是说会让请求跳转到验证码页面,只有输入正确的验证码才能继续访问网站,而验证码诞生之初的目的就是为了区分人和机器的区别,自然也就能拦截爬虫。
但随着AI 技术的深入,这样的反爬技术也很容易被破解,这个时候就需要我们比对方更智能、更聪明。
因此,要想防住爬虫,就要从根源入手。
1 方案架构
首先我们要知道爬虫平台间的数据如何传输,才能在此基础建立安全可信的通信链路,其次,在保证安全可信的通信链路基础上,需要考虑是否支持多种风险的快速判断,是否可以进行回溯及服务监控;最后,在与爬虫的对抗层面,需要考虑是否能够进行快速的对抗调整,并将相应的人机验证工具作为支撑。
也因此,我们就可以在持续不断的攻防对抗间思考出一套反爬体系建设方案 。
在客户端,我们对app、web源码进行防护,防止漏洞利用、逆向破解、接口暴露等。同时,在客户端集成设备指纹,对每一台设备形成全球唯一的设备编码,识别黑产作弊机器。并在此基础上集成滑动验证码,能够直接有效阻挡机器的访问行为。
通信链路上集成安全SDK,保护传输数据安全,识别伪造数据、非法请求。
实时风险决策平台,其实可以认为是一种防护规则配置平台,通过针对不同行业业务及事件的需求,编制不同的安全规则及策略。
整体工作流程如图所示,业务请求经过业务系统转发到实时决策引擎,决策引擎将判断结果返回给业务系统,业务系统自行决定处置措施。

多环节防控,降低误杀率的同时,保证防控效果。
2 方案优势
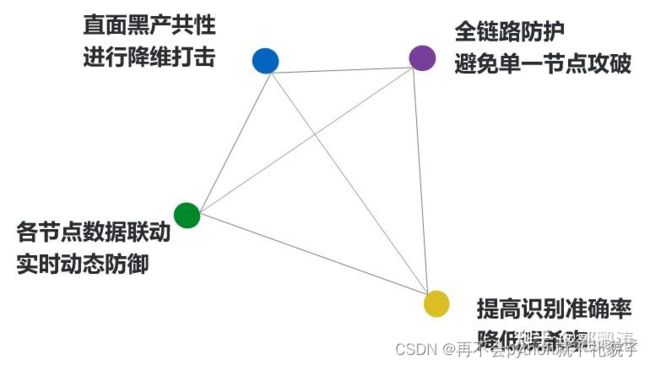
1.就是抛开传统只限于代码层面的对抗,针对装备手段,从设备层面入手,对黑产降维打击
2.实施了全链路防护,避免单一节点被攻破
3.各个环节数据共享,能够进行实时态势感知,动态防御
4.最前端的验证码拦截明显的机器行为,实时决策拦截灰度爬虫行为,最终实现黑灰产的高精度识别,在提高风控效果的同时,保证较低误杀率。
四、反爬需要所有人共同努力
爬虫贡献了互联网 50% 的流量,它对于互联网的繁荣功不可没。但该技术同时也因“用途”而充满争议。爬虫是一项见不得“阳光”的技术,它广泛运用,却少有人愿意承认在使用它。因为它常常被用作非法收集信息的工具,站上数据隐私、数据安全的对立面。
不难看出,爬虫技术本无罪,有罪的是那些拿爬虫来作恶的人。一起努力,抵抗“恶意爬虫”!
关于Python的技术储备
在这里给大家分享一些免费的课程供大家学习,下面是课程里面的截图,扫描最下方的二维码就能全部领取。
1.Python所有方向的学习路线
2.学习软件
工欲善其事必先利其器。学习Python常用的开发软件都在这里了,给大家节省了很多时间。

3.学习资料

4.实战资料
实践是检验真理的唯一标准。这里的压缩包可以让你再闲暇之余帮你提升你的个人能力。

5.视频课程

好啦今天的分享就到这里结束了,快乐的时光总是短暂呢,想学习更多课程的小伙伴不要着急,有更多惊喜哦~